

Llama 2 er en open source stor sprogmodel (LLM) udviklet af Meta. Det er en kompetent open source-storsprogmodel, uden tvivl bedre end nogle lukkede modeller som GPT-3.5 og PaLM 2. Den består af tre forudtrænede og finjusterede generative tekstmodelstørrelser, herunder 7 milliarder, 13 milliarder og 70 milliarder parametermodeller.
Du vil udforske Llama 2s samtaleevner ved at bygge en chatbot ved hjælp af Streamlit og Llama 2.
Indholdsfortegnelse
Forstå Llama 2: Funktioner og fordele
Hvor forskellig er Llama 2 fra dens forgængers store sprogmodel, Llama 1?
- Større modelstørrelse: Modellen er større med op til 70 milliarder parametre. Dette gør det muligt for den at lære mere indviklede associationer mellem ord og sætninger.
- Forbedrede samtaleevner: Forstærkende læring fra menneskelig feedback (RLHF) forbedrer samtaleapplikationsevner. Dette gør det muligt for modellen at generere menneskelignende indhold selv i indviklede interaktioner.
- Hurtigere inferens: Den introducerer en ny metode kaldet grouped-query opmærksomhed for at fremskynde inferens. Dette resulterer i dens evne til at bygge mere nyttige applikationer som chatbots og virtuelle assistenter.
- Mere effektiv: Den er mere hukommelses- og beregningseffektiv end sin forgænger.
- Open source og ikke-kommerciel licens: Det er open source. Forskere og udviklere kan bruge og ændre Llama 2 uden begrænsninger.
Llama 2 overgår markant sin forgænger på alle punkter. Disse egenskaber gør det til et potent værktøj til mange applikationer, såsom chatbots, virtuelle assistenter og naturlig sprogforståelse.
Opsætning af et strømbelyst miljø til Chatbot-udvikling
For at begynde at bygge din applikation skal du opsætte et udviklingsmiljø. Dette er for at isolere dit projekt fra de eksisterende projekter på din maskine.
Start først med at oprette et virtuelt miljø ved hjælp af Pipenv-biblioteket som følger:
pipenv shell
Derefter skal du installere de nødvendige biblioteker for at bygge chatbotten.
pipenv install streamlit replicate
Streamlit: Det er en open source-webappramme, der gør maskinlæring og datavidenskabsapplikationer hurtigt.
Repliker: Det er en cloud-platform, der giver adgang til store open source-maskinelæringsmodeller til implementering.
Få dit Llama 2 API-token fra replikat
For at få en Replicate token-nøgle skal du først registrere en konto på Repliker ved at bruge din GitHub-konto.
Når du har åbnet dashboardet, skal du navigere til knappen Udforsk og søge efter Llama 2-chat for at se llama-2–70b-chat-modellen.
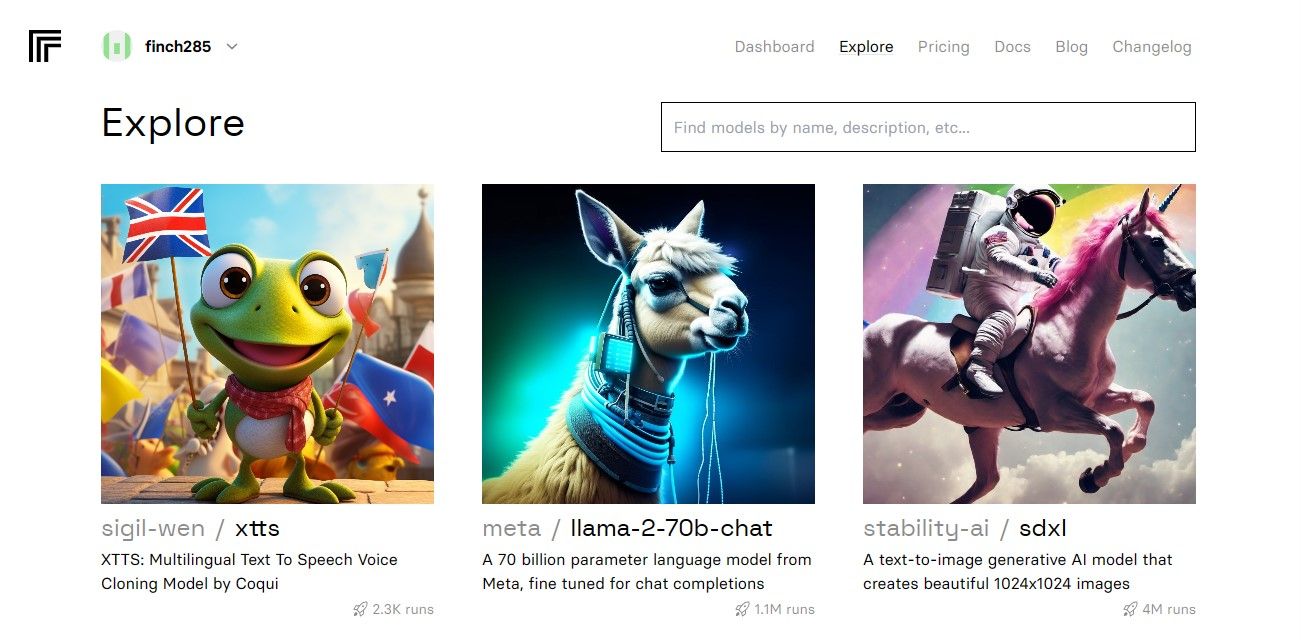
Klik på llama-2–70b-chat-modellen for at se Llama 2 API-endepunkterne. Klik på API-knappen på llama-2–70b-chat-modellens navigationslinje. Klik på Python-knappen i højre side af siden. Dette giver dig adgang til API-tokenet til Python-applikationer.
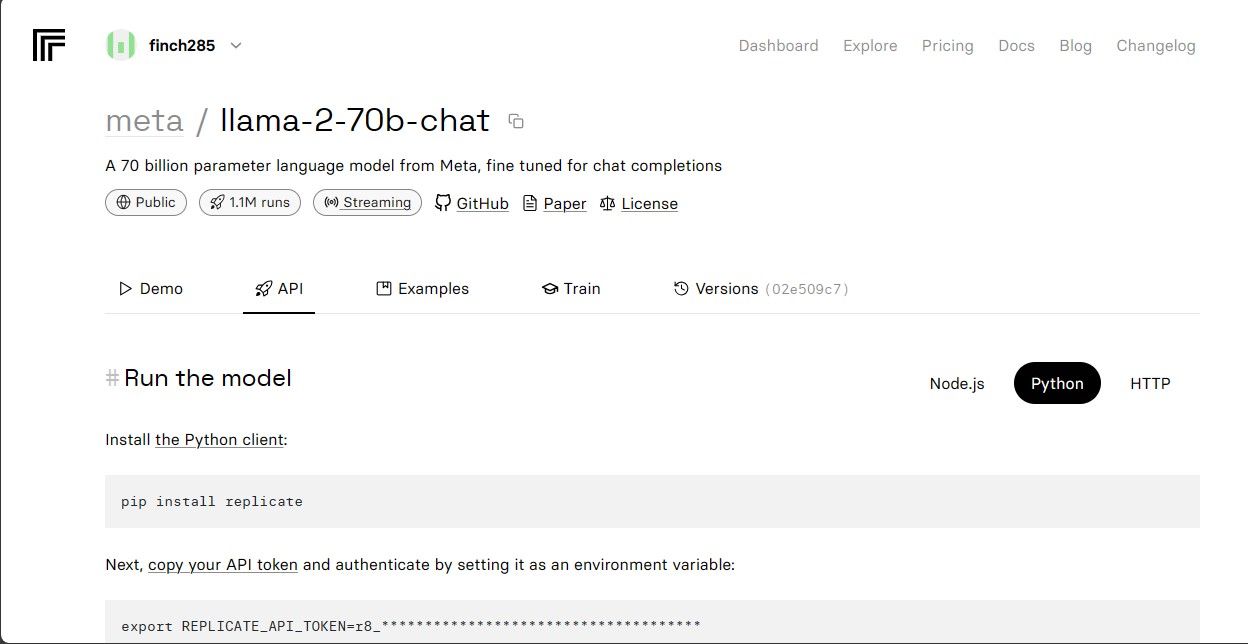
Kopier REPLICATE_API_TOKEN og gem det sikkert til fremtidig brug.
Opbygning af chatbot
Først skal du oprette en Python-fil kaldet llama_chatbot.py og en env-fil (.env). Du skriver din kode i llama_chatbot.py og gemmer dine hemmelige nøgler og API-tokens i .env-filen.
I filen llama_chatbot.py importerer du bibliotekerne som følger.
import streamlit as st
import os
import replicate
Indstil derefter de globale variabler for llama-2-70b-chat-modellen.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
Tilføj repliker-tokenet og modelslutpunkter i .env-filen i følgende format:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Indsæt dit repliker-token, og gem .env-filen.
Design af chatbot’ens samtaleflow
Opret en pre-prompt for at starte Llama 2-modellen afhængigt af, hvilken opgave du vil have den til at udføre. I dette tilfælde ønsker du, at modellen skal fungere som assistent.
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
Opsæt sidekonfigurationen for din chatbot som følger:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Skriv en funktion, der initialiserer og opsætter sessionstilstandsvariabler.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Funktionen indstiller de væsentlige variabler som chat_dialogue, pre_prompt, llm, top_p, max_seq_len og temperatur i sessionstilstanden. Den håndterer også valget af Llama 2-modellen baseret på brugerens valg.
Skriv en funktion til at gengive sidebjælkeindholdet i Streamlit-appen.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Funktionen viser headeren og indstillingsvariablerne for Llama 2 chatbot til justeringer.
Skriv den funktion, der gengiver chathistorikken, i hovedindholdsområdet i Streamlit-appen.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Funktionen itererer gennem chat_dialogen, der er gemt i sessionstilstanden, og viser hver besked med den tilsvarende rolle (bruger eller assistent).
Håndter brugerens input ved hjælp af funktionen nedenfor.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Denne funktion giver brugeren et inputfelt, hvor de kan indtaste deres beskeder og spørgsmål. Meddelelsen føjes til chat_dialogen i sessionstilstanden med brugerrollen, når brugeren indsender beskeden.
Skriv en funktion, der genererer svar fra Llama 2-modellen og viser dem i chatområdet.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Funktionen opretter en samtalehistorikstreng, der inkluderer både bruger- og assistentmeddelelser, før funktionen debounce_replicate_run kaldes for at få assistentens svar. Det ændrer løbende svaret i brugergrænsefladen for at give en chatoplevelse i realtid.
Skriv hovedfunktionen, der er ansvarlig for at gengive hele Streamlit-appen.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Det kalder alle de definerede funktioner til at konfigurere sessionstilstanden, gengive sidebjælken, chathistorik, håndtere brugerinput og generere assistentsvar i en logisk rækkefølge.
Skriv en funktion for at starte render_app-funktionen og start applikationen, når scriptet er udført.
def main():
render_app()if __name__ == "__main__":
main()
Nu skulle din ansøgning være klar til eksekvering.
Håndtering af API-anmodninger
Opret en utils.py-fil i din projektmappe og tilføj funktionen nedenfor:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Funktionen udfører en debounce-mekanisme for at forhindre hyppige og overdrevne API-forespørgsler fra en brugers input.
Importer derefter debounce response-funktionen til din llama_chatbot.py-fil som følger:
from utils import debounce_replicate_run
Kør nu applikationen:
streamlit run llama_chatbot.py
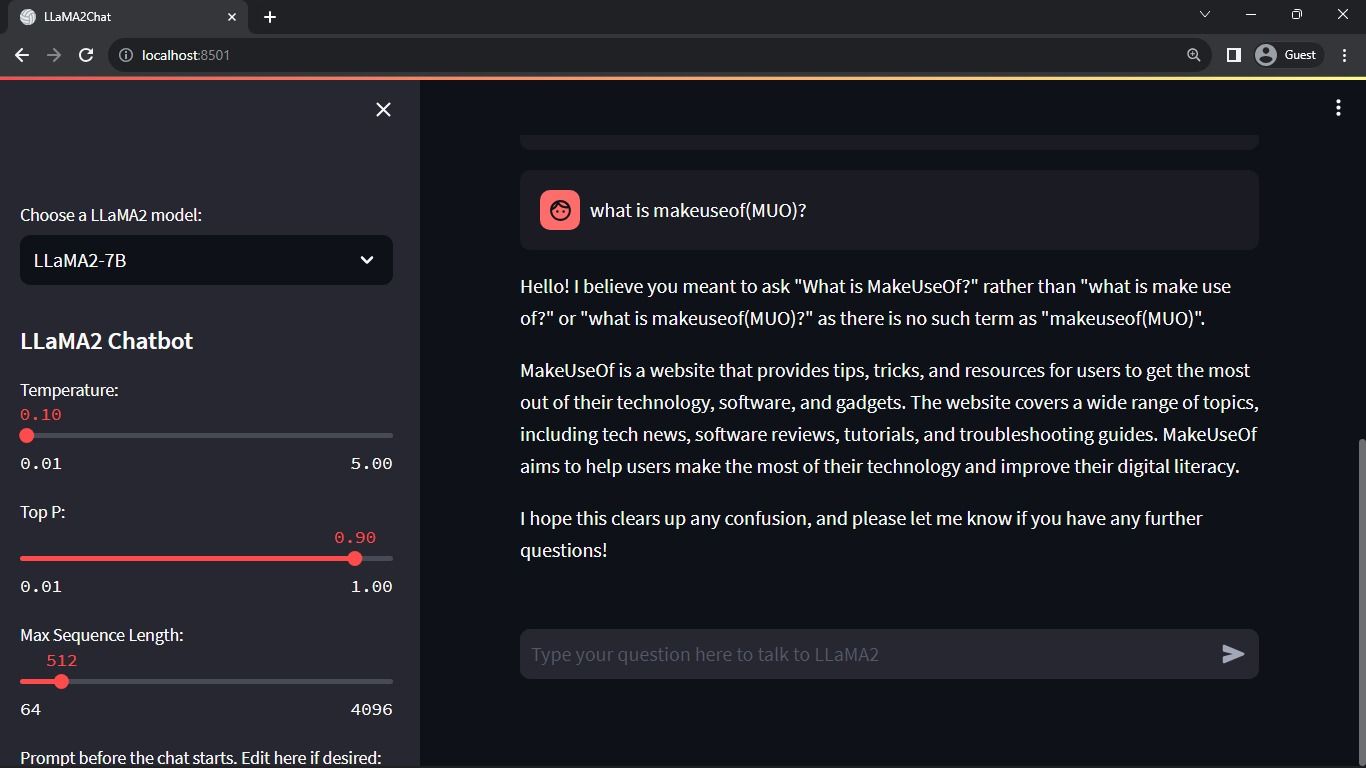
Forventet output:
Outputtet viser en samtale mellem modellen og et menneske.
Virkelige applikationer af Streamlit og Llama 2 Chatbots
Nogle eksempler fra den virkelige verden på Llama 2-applikationer inkluderer:
- Chatbots: Dets brug gælder for at skabe menneskelige respons chatbots, der kan holde samtaler i realtid om flere emner.
- Virtuelle assistenter: Dets brug gælder for at skabe virtuelle assistenter, der forstår og reagerer på menneskelige sprogforespørgsler.
- Sprogoversættelse: Dens brug gælder for sprogoversættelsesopgaver.
- Tekstopsummering: Dens brug er anvendelig til at sammenfatte store tekster til korte tekster for nem forståelse.
- Forskning: Du kan anvende Llama 2 til forskningsformål ved at besvare spørgsmål på tværs af en række emner.
Fremtiden for AI
Med lukkede modeller som GPT-3.5 og GPT-4 er det ret svært for små spillere at bygge noget af substans ved hjælp af LLM’er, da det kan være ret dyrt at få adgang til GPT-modellens API.
At åbne avancerede store sprogmodeller som Llama 2 for udviklerfællesskabet er kun begyndelsen på en ny æra af kunstig intelligens. Det vil føre til mere kreativ og innovativ implementering af modellerne i applikationer fra den virkelige verden, hvilket vil føre til et accelereret kapløb mod at opnå Artificial Super Intelligence (ASI).