

Nøgle takeaways
- Sociale medieplatforme sælger brugerdata til AI-virksomheder til træning af generative AI-modeller på trods af bekymringer om privatlivets fred.
- Platforme som Meta, Reddit, Tumblr og WordPress.com er aktivt involveret i disse datalicensaftaler til AI-træning.
- Brugere kan tage nogle små skridt for at beskytte deres data, såsom at justere privatlivsindstillinger, fravælge deling og være forsigtig med, hvad de poster online.
En af de nyeste måder, hvorpå sociale medievirksomheder tjener penge på brugerdata, er gennem aftaler med AI-virksomheder. Men er der noget, almindelige brugere kan gøre for at beskytte deres data og indhold?
At bruge sociale mediedata til at træne generative AI-modeller har været et kontroversielt træk – men det ser ikke ud til at forhindre sociale medievirksomheder i at udlevere brugerdata.
Meta bruger allerede sociale mediedata til at træne de generative AI-funktioner, der blev annonceret på Meta Connect i 2023. Dette inkluderer Meta AI og funktioner som at skabe AI-genererede klistermærker på WhatsApp.
Som Mike Clark, Director of Product Management hos Meta, udtalte i en Meta Newsroom-indlæg:
“Offentligt delte opslag fra Instagram og Facebook – inklusive billeder og tekst – var en del af de data, der blev brugt til at træne de generative AI-modeller, der ligger til grund for de funktioner, vi annoncerede på Connect.”
Denne tendens ser ikke ud til at aftage i 2024. Ifølge Reutersindgik Reddit en aftale med Google om at gøre den sociale medieplatforms indhold tilgængeligt til træning af AI-modeller.
Reddits S-1 arkivering for sin børsnotering, indgivet den 22. februar 2024, bekræfter, at virksomheden er ved at udforske licensaftaler. I sagen står der:
“Reddit-data er en grundlæggende del af konstruktionen af den nuværende AI-teknologi og mange LLM’er. Vi tror på, at Reddits enorme korpus af samtaledata og viden vil fortsætte med at spille en rolle i træning og forbedring af LLM’er.”
Det specificerer, at Reddit er “i de tidlige stadier af at tillade tredjeparter at licensere adgang til at søge, analysere og vise historiske og realtidsdata fra vores platform” for at træne LLM’er.
Og selvom Meta og Reddit er nogle af de største navne på sociale medier, er de ikke de eneste platforme, der er involveret i at bruge sociale mediedata til at træne AI. Ifølge en rapport fra 404 MediaTumblr og WordPress.com forbereder sig på at sælge brugerdata til Midjourney og OpenAI.
Chancerne er, at hvis du bruger Facebook, Instagram, Reddit, Tumblr eller WordPress.com, er dit offentligt tilgængelige indhold allerede blevet brugt i uddannelsen af LLM’er.
For eksempel, hvis du bruger Washington Posts søgeværktøj for at se, hvilke websteder der var inkluderet i Googles C4-datasæt, som blev brugt som en del af Bards træning, vil du se, at Reddit.com tegner sig for 7,9 millioner tokens.

Tumblr.com står for 1,6 millioner tokens. Min egen lille hjemmeside, som bruger WordPress.com, stod for 14.000 tokens – så små personlige blogs kan være inkluderet i datasættet.
Med de igangværende aftaler mellem AI-virksomheder og sociale medievirksomheder vil licensaftaler betyde, at disse data aktivt sælges frem for blot at blive skrabet af nettet.
Men når det kommer til fremtidig behandling, hvad kan du så gøre ved det? Meta har introduceret en formular til generative AI-registrerede rettigheder der giver dig mulighed for at gøre indsigelse mod eller begrænse behandlingen af dine personlige data fra tredjeparter til træning af Metas generative AI-modeller.
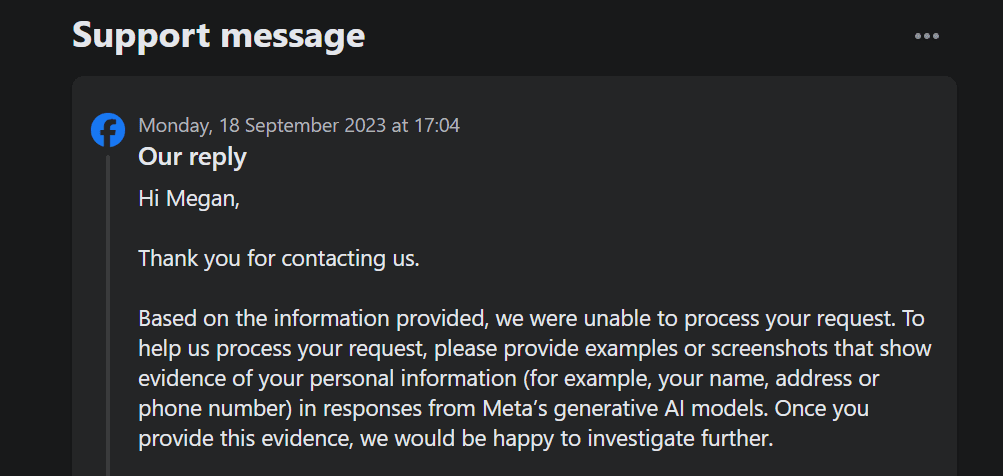
Navnlig lader denne mulighed dig ikke gøre indsigelse mod Metas egen førstepartsbehandling af dine data til træning af generativ AI. Ydermere, da jeg indsendte en billet for at gøre indsigelse mod brugen af mine personlige data ved hjælp af formularen, krævede supportbilletten, at jeg skulle bevise, at mine personlige oplysninger allerede dukkede op i Metas generative AI-resultater.
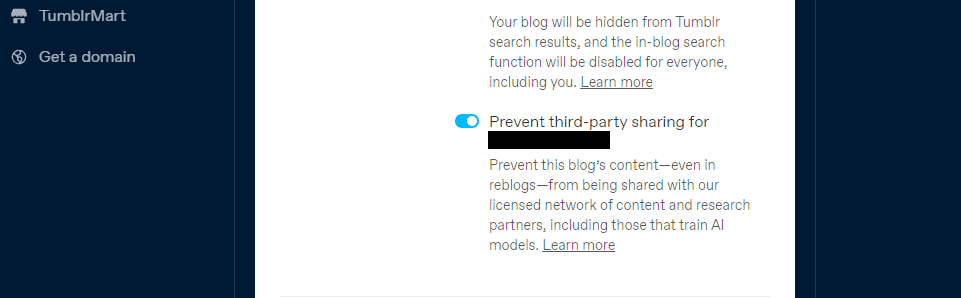
Tumblr har også introduceret en mulighed for at fravælge deling af dine offentlige blogs indhold med tredjeparter ved at bruge dine blogindstillinger. Du kan finde det i dine indstillinger ved at klikke på din blog og scrolle ned til Synlighedsindstillingerne. Vælg derefter at forhindre tredjepartsdeling af din blog.
Når det kommer til en platform som Instagram, kan du prøve at skifte din Instagram-konto til privat for at forhindre brugen af dine data. Dette garanterer ikke, at dine data ikke bliver brugt, men da dataskrabning for LLM’er ser ud til at fokusere på offentlige data, kan det være en potentiel beskyttelse.
Du kan også gøre din X (Twitter) konto privat, men endnu en gang er dette blot en potentiel beskyttelse og garanterer ikke, at dine data forbliver private.
EN fælles erklæring af forskellige nationale informationskommissærer og eksperter rundt om i verden har også foreslået nogle handlinger for enkeltpersoner, der ønsker at minimere privatlivets fredsrisiko ved dataskrabning fra AI-virksomheder. Rådgivningen omfatter:
- Læs vilkårene og privatlivspolitikken for et websted for at se, hvordan det deler dine personlige oplysninger.
- Begræns de oplysninger, du sender online, især følsomme oplysninger.
- Administrer dine privatlivsindstillinger.
- Tænk langsigtet over den information, du deler online.
- Kontakt det sociale mediefirma eller webstedet, hvis du mener, at dine data er blevet skrabet forkert. Hvis du er utilfreds med deres svar, skal du indgive en klage til din relevante databeskyttelsesmyndighed.
Du kan også slette visse oplysninger online, hvis du ikke er tryg ved, at tredjeparter har adgang til dem, selvom offentligt tilgængelige oplysninger på dine profiler måske allerede er blevet skrabet.
Desværre er der kun så meget, vi som almindelige brugere kan gøre for at beskytte vores data mod AI-virksomheder. Reel kontrol over disse oplysninger vil sandsynligvis kun komme med hjælp fra regulatorer.