

Generative adversarial networks (GAN’er) er en af de moderne teknologier, der tilbyder et stort potentiale i mange tilfælde, lige fra at skabe dine gamle billeder og øge din stemme til at levere forskellige applikationer i medicinske og andre industrier.
Denne avancerede teknologi kan hjælpe dig med at forme dine produkter og tjenester. Det kan også bruges til at forbedre billedkvaliteten for at bevare minder.
Mens GAN’er er en velsignelse for mange, finder nogle det bekymrende.
Men hvad er denne teknologi helt præcist?
I denne artikel vil jeg diskutere, hvad et GAN er, hvordan det virker og dets applikationer.
Så lad os dykke direkte ind!
Indholdsfortegnelse
Hvad er et generativt kontradiktorisk netværk?
Et Generative Adversarial Network (GAN) er en maskinlæringsramme bestående af to neurale netværk, der konkurrerer om at producere mere præcise forudsigelser såsom billeder, unik musik, tegninger og så videre.
GANs blev designet i 2014 af en datalog og ingeniør, Ian Goodfellow, og nogle af hans kolleger. De er unikke dybe neurale netværk, der er i stand til at generere nye data svarende til den, de trænes på. De konkurrerer i et nulsumsspil, der resulterer i, at den ene agent taber spillet, mens den anden vinder det.
Oprindeligt blev GAN’er foreslået som en generativ model for maskinlæring, hovedsageligt uovervåget læring. Men GAN’er er også nyttige til fuld-superviseret læring, semi-superviseret læring og forstærkende læring.
De to blokke i konkurrence i en GAN er:
Generatoren: Det er et foldet neuralt netværk, der kunstigt producerer output svarende til faktiske data.
Diskriminatoren: Det er et dekonvolutionelt neuralt netværk, der kan identificere de output, der er kunstigt skabt.
Nøglekoncepter
For at forstå begrebet GAN bedre, lad os hurtigt forstå nogle vigtige relaterede begreber.
Machine learning (ML)

Maskinlæring er en del af kunstig intelligens (AI), der involverer læring og opbygning af modeller, der udnytter data til at forbedre ydeevne og nøjagtighed, mens du udfører opgaver eller træffer beslutninger eller forudsigelser.
ML-algoritmer skaber modeller baseret på træningsdata, der forbedres med kontinuerlig læring. De bruges på flere områder, herunder computersyn, automatiseret beslutningstagning, e-mailfiltrering, medicin, bankvæsen, datakvalitet, cybersikkerhed, talegenkendelse, anbefalingssystemer og mere.
Diskriminerende model

I dyb læring og maskinlæring fungerer den diskriminerende model som en klassificering for at skelne mellem et sæt niveauer eller to klasser.
For eksempel at skelne mellem forskellige frugter eller dyr.
Generativ model
I generative modeller anses tilfældige prøver for at skabe nye realistiske billeder. Den lærer af virkelige billeder af nogle genstande eller levende ting for at generere sine egne realistiske, men alligevel efterlignede ideer. Disse modeller er af to typer:
Variationelle autoenkodere: De bruger indkodere og dekodere, der er separate neurale netværk. Dette virker, fordi et givet realistisk billede passerer gennem en koder for at repræsentere disse billeder som vektorer i et latent rum.
Dernæst bruges en dekoder til at tage disse fortolkninger for at producere nogle realistiske kopier af disse billeder. I starten kunne dens billedkvalitet være lav, men den forbedres, efter at dekoderen bliver fuldt funktionel, og du kan se bort fra encoderen.
Generative adversarielle netværk (GAN’er): Som diskuteret ovenfor er et GAN et dybt neuralt netværk, der er i stand til at generere nye, lignende data fra det datainput, det er forsynet med. Det kommer under uovervåget maskinlæring, som er en af de typer maskinlæring, der diskuteres nedenfor.
Superviseret læring
Ved superviseret træning trænes en maskine ved hjælp af velmærkede data. Det betyder, at nogle data allerede vil være mærket med det rigtige svar. Her får maskinen nogle data eller eksempler for at gøre det muligt for den overvågede læringsalgoritme at analysere træningsdataene og producere et nøjagtigt resultat ud fra disse mærkede data.
Uovervåget læring
Uovervåget læring involverer træning af en maskine ved hjælp af data, der hverken er mærket eller klassificeret. Det giver maskinlæringsalgoritmen mulighed for at arbejde på disse data uden vejledning. I denne type læring er maskinens opgave at kategorisere usorterede data baseret på mønstre, ligheder og forskelle uden forudgående datatræning.
Så GAN’er er forbundet med at udføre uovervåget læring i ML. Den har to modeller, der automatisk kan afdække og lære mønstrene fra inputdata. Disse to modeller er generator og diskriminator.
Lad os forstå dem lidt mere.
Dele af en GAN
Udtrykket “modstridende” er inkluderet i GAN, fordi det har to dele – generator og nævner, der konkurrerer. Dette gøres for at fange, granske og replikere datavariationer i et datasæt. Lad os få en bedre forståelse af disse to dele af et GAN.
Generator
En generator er et neuralt netværk, der er i stand til at lære og generere falske datapunkter såsom billeder og lyd, der ser realistiske ud. Det bruges i træning og bliver bedre med kontinuerlig læring.
De data, der genereres af generatoren, bruges som et negativt eksempel for den anden del – nævneren, som vi vil se næste gang. Generatoren tager en tilfældig fastlængdevektor som input for at producere en prøveudgang. Det har til formål at præsentere outputtet foran diskriminatoren, så det kan klassificere, om det er ægte eller falsk.
Generatoren er trænet med disse komponenter:
- Støjende inputvektorer
- Et generatornetværk til at transformere et tilfældigt input til dataforekomsten
- Et diskriminatornetværk til at klassificere de genererede data
- Et generatortab for at straffe generatoren, da den ikke formår at narre diskriminatoren
Generatoren fungerer som en tyv for at replikere og skabe realistiske data for at narre diskriminatoren. Det har til formål at omgå flere udførte kontroller. Selvom det kan fejle frygteligt i de indledende faser, bliver det ved med at blive bedre, indtil det genererer flere realistiske data af høj kvalitet og kan undgå testene. Når denne evne er opnået, kan du kun bruge generatoren uden at kræve en separat diskriminator.
Diskriminator

En diskriminator er også et neuralt netværk, der kan skelne mellem et falsk og ægte billede eller andre datatyper. Som en generator spiller den en afgørende rolle i træningsfasen.
Det fungerer som politiet for at fange tyven (falske data fra generatoren). Det sigter mod at opdage falske billeder og abnormiteter i en dataforekomst.
Som nævnt før lærer generatoren og bliver ved med at forbedre sig for at nå et punkt, hvor den bliver selvhjulpen til at producere billeder af høj kvalitet, der ikke kræver en diskriminator. Når data af høj kvalitet fra generatoren sendes gennem diskriminatoren, kan den ikke længere skelne mellem et ægte og falsk billede. Så du er god til at gå med kun generatoren.
Hvordan virker GAN?
I et generativt modstridende netværk (GAN) involverer tre ting:
- En generativ model til at beskrive måden data genereres på.
- En modstridende ramme, hvor en model trænes.
- Dybe neurale netværk som AI-algoritmer til træning.
GANs to neurale netværk – generator og diskriminator – bruges til at spille et modstridende spil. Generatoren tager inputdataene, såsom lydfiler, billeder osv., for at generere en lignende dataforekomst, mens diskriminatoren validerer ægtheden af den dataforekomst. Sidstnævnte vil afgøre, om den dataforekomst, den har gennemgået, er reel eller ej.
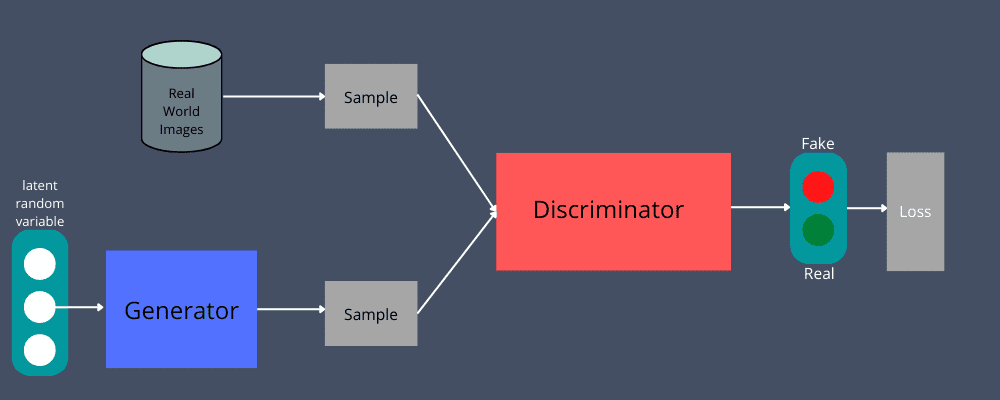
For eksempel vil du verificere, om et givet billede er ægte eller falsk. Du kan bruge håndgenererede datainput til at sende til generatoren. Det vil skabe nye, replikerede billeder som output.
Mens du gør det, sigter generatoren efter, at alle de billeder, den genererer, vil blive betragtet som autentiske, på trods af at de er falske. Den ønsker at skabe acceptable resultater for at lyve og undgå at blive fanget.
Dernæst vil dette output gå til diskriminatoren sammen med et sæt billeder fra rigtige data for at opdage, om disse billeder er autentiske eller ej. Det virker negativt på generatoren, uanset hvor hårdt den prøver at efterligne; diskriminatoren vil hjælpe med at skelne faktuelle data fra falske.
Diskriminatoren vil tage både falske og rigtige data for at returnere en sandsynlighed på 0 eller 1. Her repræsenterer 1 ægthed, mens 0 repræsenterer falsk.
Der er to feedback-loops i denne proces:
- Generatoren forbinder en feedback-loop med en diskriminator
- Diskriminatoren slutter sig til en anden feedback-loop med et sæt rigtige billeder
En GAN-uddannelse virker, fordi både generator og diskriminator er under uddannelse. Generatoren lærer kontinuerligt ved at sende falske input, mens diskriminatoren vil lære at forbedre detektion. Her er begge dynamiske.
Diskriminatoren er et foldningsnetværk, der er i stand til at kategorisere billeder, der leveres til den. Det fungerer som en binomial klassificering til at mærke billeder som falske eller ægte.
På den anden side er generatoren som et omvendt foldningsnetværk, der tager tilfældige dataprøver for at producere billeder. Men diskriminatoren verificerer data ved hjælp af downsampling-teknikker såsom max-pooling.
Begge netværk forsøger at optimere en modsatrettet og anderledes tab eller objektiv funktion i et modstridende spil. Deres tab gør dem i stand til at presse mod hinanden endnu hårdere.
Typer af GAN’er

Generative kontradiktoriske netværk er af forskellige typer baseret på implementering. Her er de vigtigste GAN-typer, der bruges aktivt:
- Betinget GAN (CGAN): Det er en dyb læringsteknik, der involverer specifikke betingede parametre for at hjælpe med at skelne mellem ægte og falske data. Den indeholder også en ekstra parameter – “y” i generatorfasen for at producere tilsvarende data. Der føjes også etiketter til dette input og føres til diskriminatoren for at gøre det muligt for den at verificere, om dataene er autentiske eller falske.
- Vanilla GAN: Det er en simpel GAN-type, hvor diskriminatoren og generatoren er enklere og flerlagede perceptroner. Dens algoritmer er enkle og optimerer den matematiske ligning ved hjælp af stokastisk gradientnedstigning.
- Deep convolutional GAN (DCGAN): Det er populært og betragtes som den mest succesrige GAN-implementering. DCGAN består af ConvNets snarere end flerlagsperceptroner. Disse ConvNets anvendes uden brug af teknikker som max-pooling eller fuldstændig forbindelse af lagene.
- Super Resolution GAN (SRGAN): Det er en GAN-implementering, der bruger et dybt neuralt netværk sammen med et modstridende netværk til at hjælpe med at producere billeder af høj kvalitet. SRGAN er især nyttig til effektivt at opskalere originale lavopløsningsbilleder, så deres detaljer forbedres, og fejl minimeres.
- Laplacian Pyramid GAN (LAPGAN): Det er en inverterbar og lineær repræsentation, der inkluderer flere båndpasbilleder, der er placeret otte mellemrum fra hinanden med lavfrekvente rester. LAPGAN bruger flere diskriminator- og generatornetværk og flere Laplacian Pyramid-niveauer.
LAPGAN bruges meget, da det producerer førsteklasses billedkvalitet. Disse billeder nedsamples først ved hvert pyramidelag og opskaleres derefter ved hvert lag, hvor ideer får noget støj, indtil de får den oprindelige størrelse.
Anvendelser af GAN’er
Generative kontradiktoriske netværk bruges på forskellige områder, såsom:
Videnskab

GAN’er kan give en nøjagtig og hurtigere måde at modellere højenergi jetformation og udføre fysikeksperimenter. Disse netværk kan også trænes til at estimere flaskehalse i udførelse af simuleringer for partikelfysik, der forbruger store ressourcer.
GAN’er kan fremskynde simulering og forbedre simuleringsfidelitet. Derudover kan GAN’er hjælpe med at studere mørkt stof ved at simulere gravitationslinser og forbedre astronomiske billeder.
Computerspil

Verden af videospil har også udnyttet GAN’er til at opskalere lavopløsnings 2-dimensionelle data, der bruges i ældre videospil. Det vil hjælpe dig med at genskabe sådanne data til 4k eller endnu højere opløsninger gennem billedtræning. Dernæst kan du nedsample dataene eller billederne for at gøre dem egnede til videospillets rigtige opløsning.
Sørg for korrekt træning til dine GAN-modeller. De kan tilbyde skarpere og klarere 2D-billeder af imponerende kvalitet sammenlignet med de oprindelige data, mens de bevarer det rigtige billedes detaljer, såsom farver.
Videospil, der har udnyttet GAN’er, inkluderer Resident Evil Remake, Final Fantasy VIII og IX og mere.
Kunst og mode
Du kan bruge GAN’er til at generere kunst, såsom at skabe billeder af individer, der aldrig har eksisteret, in-paint fotografier, producere billeder af uvirkelige modemodeller og mange flere. Det bruges også i tegninger, der genererer virtuelle skygger og skitser.
Annoncering

Brug af GAN’er til at oprette og producere dine annoncer sparer tid og ressourcer. Som det ses ovenfor, hvis du ønsker at sælge dine smykker, kan du skabe en imaginær model, der ligner et rigtigt menneske ved hjælp af GAN.
På denne måde kan du få modellen til at bære dine smykker og fremvise dem til dine kunder. Det vil spare dig for at leje en model og betale for den. Du kan endda slippe for de ekstra udgifter som at betale for transport, leje et studie, arrangere fotografer, makeupartister osv.
Dette vil hjælpe betydeligt, hvis du er en virksomhed i vækst og ikke har råd til at leje en model eller huse en infrastruktur til annonceoptagelser.
Lydsyntese
Du kan oprette lydfiler fra et sæt lydklip ved hjælp af GAN’er. Dette er også kendt som generativ lyd. Du må ikke forveksle dette med Amazon Alexa, Apple Siri eller andre AI-stemmer, hvor stemmefragmenter er syet godt sammen og produceret efter behov.
I stedet bruger generativ lyd neurale netværk til at studere en lydkildes statistiske egenskaber. Dernæst gengiver den direkte disse egenskaber i en given kontekst. Her repræsenterer modellering den måde, tale ændres på efter hvert millisekund.
Overfør læring

Avancerede overførselslæringsstudier bruger GAN’er til at tilpasse de nyeste funktioner såsom dyb forstærkningslæring. Til dette føres kildens indlejringer og den tilsigtede opgave til diskriminatoren for at bestemme konteksten. Derefter forplantes resultatet tilbage via encoderen. På denne måde bliver modellen ved med at lære.
Andre anvendelser af GAN’er omfatter:
- Diagnose af totalt eller delvist synstab ved at detektere glaukomatiske billeder
- Visualiser industrielt design, boligindretning, beklædningsgenstande, sko, tasker og meget mere
- rekonstruere retsmedicinske ansigtstræk hos en syg person
- skabe 3D-modeller af et element ud fra et billede, producere nye objekter som en 3D-punktsky, modellere bevægelsesmønstre i en video
- Vis udseendet af en person med skiftende alder
- Dataforøgelse såsom forbedring af DNN-klassifikatoren
- Indmal en manglende funktion på et kort, forbedre gadevisninger, overfør kortlægningsstile og mere
- Producere billeder, udskifte et billedsøgningssystem osv.
- Generer styreinput til et ikke-lineært dynamisk system ved at bruge en GAN-variation
- Analyser virkningerne af klimaændringer på et hus
- Skab en persons ansigt ved at tage deres stemme som input
- Skab nye molekyler til flere proteinmål inden for kræft, fibrose og inflammation
- Animer gifs fra et almindeligt billede
Der er mange flere applikationer af GAN’er inden for forskellige områder, og deres brug udvides. Der er dog også flere tilfælde af misbrug. GAN-baserede menneskelige billeder er blevet brugt til skumle brugssager, såsom at producere falske videoer og billeder.
GAN’er kan også bruges til at skabe realistiske billeder og profiler af mennesker på sociale medier, som aldrig har eksisteret på jorden. Andet vedrørende misbrug af GNA’er er oprettelsen af falsk pornografi uden samtykke fra fremhævede personer, distribution af forfalskede videoer af politiske kandidater og så videre.
Selvom GNA’er kan være en velsignelse på mange områder, kan deres misbrug også være katastrofalt. Derfor skal ordentlige retningslinjer håndhæves for dets brug.
Konklusion
GAN’er er et bemærkelsesværdigt eksempel på moderne teknologi. Det giver en unik og bedre måde at generere data på og hjælpe med funktioner som visuel diagnose, billedsyntese, forskning, dataforøgelse, kunst og videnskab og mange flere.
Du kan også være interesseret i Maskinlæringsplatforme med lav kode og ingen kode til at bygge innovative applikationer.