
Gennem årene er brugen af python til datavidenskab vokset utroligt og bliver ved med at vokse dagligt.
Data science er et stort fagområde med en masse underfelter, hvoraf dataanalyse uden tvivl er et af de vigtigste af alle disse felter, og uanset ens færdighedsniveau inden for data science, er det blevet stadig vigtigere at forstå eller har mindst et grundlæggende kendskab til det.
Indholdsfortegnelse
Hvad er dataanalyse?
Dataanalyse er rensning og transformation af en stor mængde ustrukturerede eller uorganiserede data med det formål at generere nøgleindsigt og information om disse data, som kan hjælpe med at træffe informerede beslutninger.
Der er forskellige værktøjer, der bruges til dataanalyse, Python, Microsoft Excel, Tableau, SaS osv., men i denne artikel vil vi fokusere på, hvordan dataanalyse udføres i python. Mere specifikt, hvordan det gøres med et python-bibliotek kaldet Pandaer.
Hvad er pandaer?
Pandas er et open source Python-bibliotek, der bruges til datamanipulation og skænderier. Det er hurtigt og yderst effektivt og har værktøjer til at indlæse flere slags data i hukommelsen. Det kan bruges til at omforme, mærke skive, indeksere eller endda gruppere flere former for data.
Datastrukturer i pandaer
Der er 3 datastrukturer i Pandas, nemlig;
Den bedste måde at skelne de tre af dem på er at se, at den ene indeholder flere stakke af den anden. Så en DataFrame er en stak af serier og et panel er en stak af DataFrames.
En serie er et endimensionelt array
En stak af flere serier laver en 2-dimensionel DataFrame
En stak af flere datarammer danner et 3-dimensionelt panel
Den datastruktur, vi ville arbejde mest med, er den 2-dimensionelle DataFrame, som også kan være standardmetoden til repræsentation for nogle datasæt, vi kan støde på.
Dataanalyse i Pandaer
Til denne artikel er ingen installation nødvendig. Vi ville bruge et værktøj kaldet samarbejde skabt af Google. Det er et online python-miljø til dataanalyse, maskinlæring og kunstig intelligens. Det er simpelthen en cloud-baseret Jupyter Notebook, der leveres forudinstalleret med næsten hver python-pakke, du har brug for som dataforsker.
Gå nu videre til https://colab.research.google.com/notebooks/intro.ipynb. Du bør se nedenstående.
I navigationen øverst til venstre skal du klikke på filindstillingen og klikke på “ny notesbog”. Du vil se en ny Jupyter notebook-side indlæst i din browser. Det første, vi skal gøre, er at importere pandaer til vores arbejdsmiljø. Det kan vi gøre ved at køre følgende kode;
import pandas as pd
Til denne artikel vil vi bruge et boligprisdatasæt til vores dataanalyse. Datasættet, vi ville bruge, kan findes her. Den første ting, vi ønsker at gøre, er at indlæse dette datasæt i vores miljø.
Det kan vi gøre med følgende kode i en ny celle;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
.read_csv bruges, når vi vil læse en CSV-fil, og vi har sendt en sep-egenskab for at vise, at CSV-filen er kommasepareret.
Vi skal også bemærke, at vores indlæste CSV-fil er gemt i en variabel df.
Vi behøver ikke bruge print()-funktionen i Jupyter Notebook. Vi kan bare indtaste et variabelnavn i vores celle, og Jupyter Notebook vil printe det ud for os.
Vi kan prøve det ved at skrive df i en ny celle og køre det, det vil udskrive alle data i vores datasæt som en DataFrame for os.
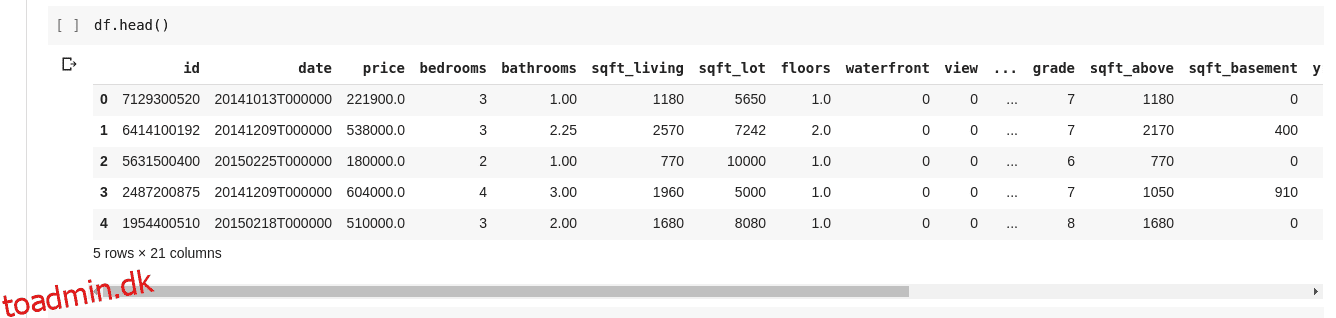
Men vi ønsker ikke altid at se alle data, til tider vil vi bare gerne se de første par data og deres kolonnenavne. Vi kan bruge funktionen df.head() til at udskrive de første fem kolonner og df.tail() til at udskrive de sidste fem. Outputtet af en af de to ville se sådan ud;
Vi vil gerne tjekke for relationer mellem disse adskillige rækker og kolonner af data. Funktionen .describe() gør præcis dette for os.
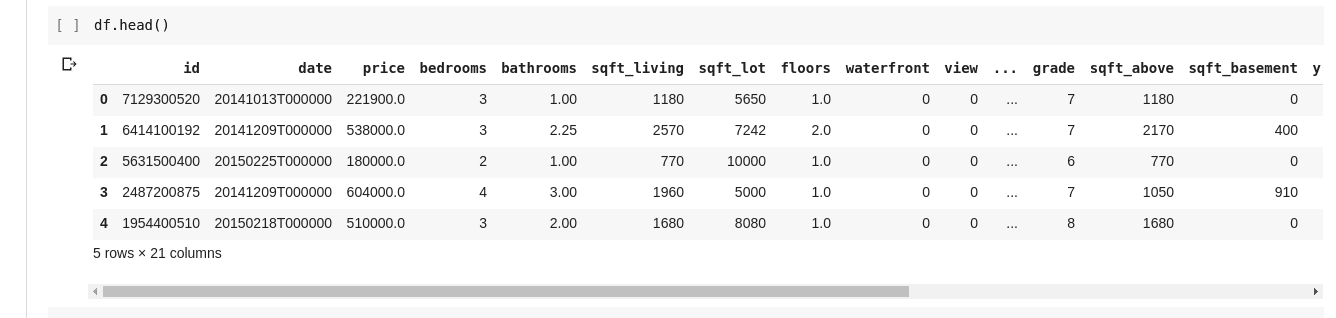
Kørsel af df.describe() giver følgende output;
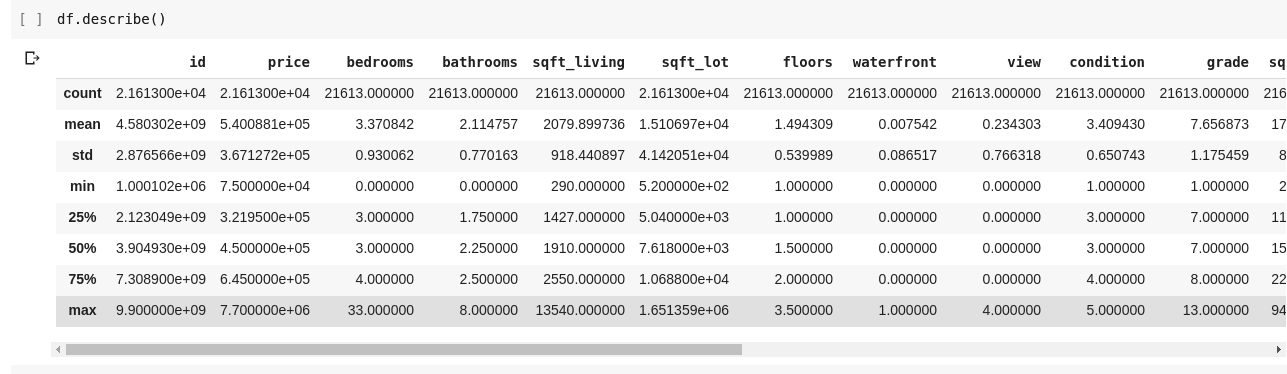
Vi kan umiddelbart se, at .describe() giver middelværdien, standardafvigelsen, minimums- og maksimumværdier og percentiler for hver eneste kolonne i DataFrame. Dette er især meget nyttigt.
Vi kan også tjekke formen på vores 2D DataFrame for at finde ud af, hvor mange rækker og kolonner den har. Det kan vi gøre ved at bruge df.shape, som returnerer en tupel i formatet (rækker, kolonner).
Vi kan også tjekke navnene på alle kolonnerne i vores DataFrame ved hjælp af df.columns.
Hvad hvis vi kun vil vælge én kolonne og returnere alle data i den? Dette gøres på en måde, der ligner at skære gennem en ordbog. Indtast følgende kode i en ny celle og kør den
df['price ']
Ovenstående kode returnerer priskolonnen, vi kan gå længere ved at gemme den i en ny variabel som sådan
price = df['price']
Nu kan vi udføre enhver anden handling, der kan udføres på en DataFrame på vores prisvariabel, da den kun er en delmængde af en faktisk DataFrame. Vi kan gøre ting som df.head(), df.shape osv..
Vi kunne også vælge flere kolonner ved at overføre en liste over kolonnenavne til df som sådan
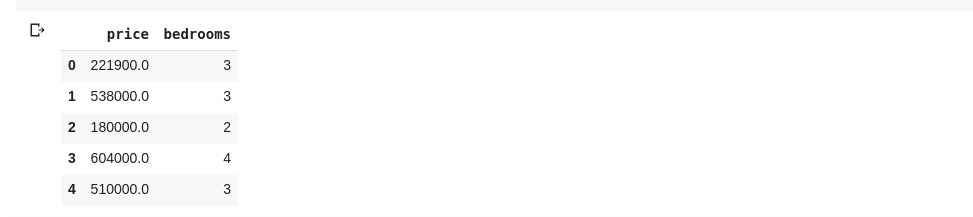
data = df[['price ', 'bedrooms']]
Ovenstående vælger kolonner med navnene ‘pris’ og ‘soveværelser’, hvis vi indtaster data.head() i en ny celle, ville vi have følgende
Ovenstående måde at opdele kolonner på returnerer alle rækkeelementerne i den kolonne, hvad nu hvis vi ønsker at returnere et undersæt af rækker og et undersæt af kolonner fra vores datasæt? Dette kan gøres ved hjælp af .iloc og er indekseret på en måde, der ligner python-lister. Så vi kan gøre sådan noget
df.iloc[50: , 3]
Hvilket returnerer den 3. kolonne fra den 50. række til slutningen. Det er ret pænt og præcis det samme som at skære lister i python.
Lad os nu lave nogle virkelig interessante ting. Vores boligprisdatasæt har en kolonne, der fortæller os prisen på et hus, og en anden kolonne fortæller os antallet af soveværelser, det pågældende hus har. Boligprisen er en løbende værdi, så det er muligt, at vi ikke har to huse, der har samme pris. Men antallet af soveværelser er noget diskret, så vi kan have flere huse med to, tre, fire soveværelser mv.
Hvad hvis vi ønsker at få alle husene med det samme antal soveværelser og finde middelprisen for hvert enkelt soveværelse? Det er relativt nemt at gøre det i pandaer, det kan gøres som sådan;
df.groupby('bedrooms ')['price '].mean()
Ovenstående grupperer først DataFrame efter datasættene med identisk soveværelsesnummer ved hjælp af df.groupby()-funktionen, derefter fortæller vi den, at den kun skal give os soveværelseskolonnen og bruge .mean()-funktionen til at finde gennemsnittet af hvert hus i datasættet .
Hvad hvis vi vil visualisere ovenstående? Vi vil gerne være i stand til at tjekke, hvordan gennemsnitsprisen for hvert enkelt soveværelsesnummer varierer? Vi skal blot kæde den forrige kode til en .plot() funktion som sådan;
df.groupby('bedrooms ')['price '].mean().plot()
Vi får et output, der ser sådan ud;
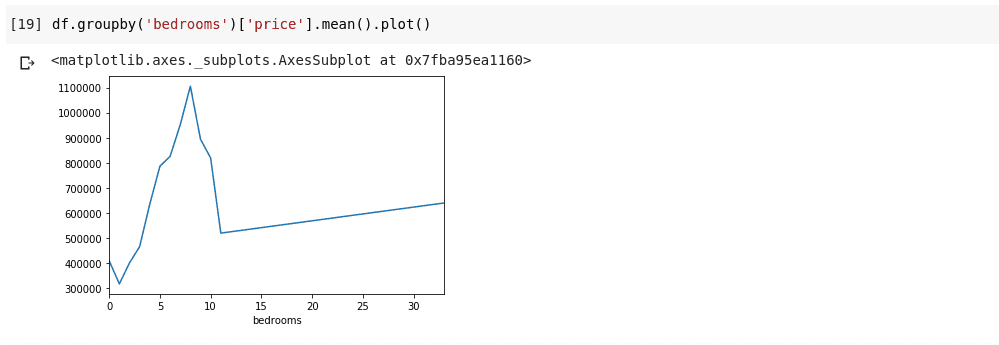
Ovenstående viser os nogle tendenser i dataene. På den vandrette akse har vi et tydeligt antal soveværelser (Bemærk, at mere end et hus kan have X antal soveværelser), På den lodrette akse har vi gennemsnittet af priserne med hensyn til det tilsvarende antal soveværelser på den vandrette akse akse. Vi kan nu umiddelbart bemærke, at huse, der har mellem 5 til 10 soveværelser, koster meget mere end huse med 3 soveværelser. Det vil også blive tydeligt, at huse med omkring 7 eller 8 soveværelser koster meget mere end huse med 15, 20 eller endda 30 værelser.
Oplysninger som ovenstående er grunden til, at dataanalyse er meget vigtig, vi er i stand til at udtrække nyttig indsigt fra dataene, som ikke umiddelbart eller helt umuligt er at bemærke uden analyse.
Manglende data
Lad os antage, at jeg tager en undersøgelse, der består af en række spørgsmål. Jeg deler et link til undersøgelsen med tusindvis af mennesker, så de kan give deres feedback. Mit ultimative mål er at køre dataanalyse på disse data, så jeg kunne få nogle vigtige indsigter fra dataene.
Nu kan meget gå galt, nogle landmålere kan føle sig utilpas med at besvare nogle af mine spørgsmål og lade det stå tomt. Mange mennesker kunne gøre det samme for flere dele af mine undersøgelsesspørgsmål. Dette betragtes måske ikke som et problem, men tænk, hvis jeg skulle indsamle numeriske data i min undersøgelse, og en del af analysen krævede, at jeg fik enten summen, middelværdien eller en anden aritmetisk operation. Flere manglende værdier ville føre til en masse unøjagtigheder i min analyse, jeg er nødt til at finde en måde at finde og erstatte disse manglende værdier med nogle værdier, der kunne være en tæt erstatning for dem.
Pandaer giver os en funktion til at finde manglende værdier i en DataFrame kaldet isnull().
Funktionen isnull() kan bruges som sådan;
df.isnull()
Dette returnerer en DataFrame af booleaner, der fortæller os, om de data, der oprindeligt var til stede der, virkelig mangler eller mangler. Outputtet ville se sådan ud;
Vi har brug for en måde at kunne erstatte alle disse manglende værdier, oftest kan valget af manglende værdier tages som nul. Til tider kan det opfattes som middelværdien af alle andre data eller måske gennemsnittet af dataene omkring dem, afhængigt af dataforskeren og brugen af de data, der analyseres.
For at udfylde alle manglende værdier i en DataFrame bruger vi funktionen .fillna() brugt som sådan;
df.fillna(0)
I ovenstående udfylder vi alle tomme data med værdi nul. Det kunne lige så godt være et hvilket som helst andet tal, som vi angiver det til at være.
Vigtigheden af data kan ikke overbetones, det hjælper os med at få svar lige fra vores data selv!. Dataanalyse siger de er den nye olie til digitale økonomier.
Alle eksemplerne i denne artikel kan findes her.
For at lære mere i dybden, tjek ud Dataanalyse med Python og Pandas online kursus.