
Denne artikel omtaler og uddyber nogle af de bedste pythonbiblioteker for dataforskere og maskinlæringsteamet.
Python er et ideelt sprog, der er berømt brugt i disse to felter, hovedsageligt til de biblioteker, det tilbyder.
Dette er på grund af Python-bibliotekernes applikationer som data input/output I/O og dataanalyse, blandt andre datamanipulationsoperationer, som dataforskere og maskinlæringseksperter bruger til at håndtere og udforske data.
Indholdsfortegnelse
Python-biblioteker, hvad er de?
Et Python-bibliotek er en omfattende samling af indbyggede moduler, der indeholder prækompileret kode, inklusive klasser og metoder, der fjerner behovet for udvikleren for at implementere kode fra bunden.
Betydningen af Python i datavidenskab og maskinlæring
Python har de bedste biblioteker til brug af maskinlærings- og datavidenskabseksperter.
Dens syntaks er nem, hvilket gør det effektivt at implementere komplekse maskinlæringsalgoritmer. Desuden forkorter den simple syntaks indlæringskurven og gør forståelsen lettere.
Python understøtter også hurtig prototypeudvikling og glat test af applikationer.
Pythons store fællesskab er praktisk for datavidenskabsfolk til let at søge løsninger på deres forespørgsler, når det er nødvendigt.
Hvor nyttige er Python-biblioteker?
Python-biblioteker er medvirkende til at skabe applikationer og modeller inden for maskinlæring og datavidenskab.
Disse biblioteker går langt i at hjælpe udvikleren med kodegenanvendelighed. Derfor kan du importere et relevant bibliotek, der implementerer en bestemt funktion i dit program, bortset fra at genopfinde hjulet.
Python-biblioteker, der bruges i Machine Learning og Data Science
Data Science-eksperter anbefaler forskellige Python-biblioteker, som datavidenskab-entusiaster skal være bekendt med. Afhængigt af deres relevans i applikationen anvender maskinlærings- og datavidenskabseksperterne forskellige Python-biblioteker kategoriseret i biblioteker til implementering af modeller, mining og scrapning af data, databehandling og datavisualisering.
Denne artikel identificerer nogle almindeligt anvendte Python-biblioteker i Data Science og Machine learning.
Lad os se på dem nu.
Numpy
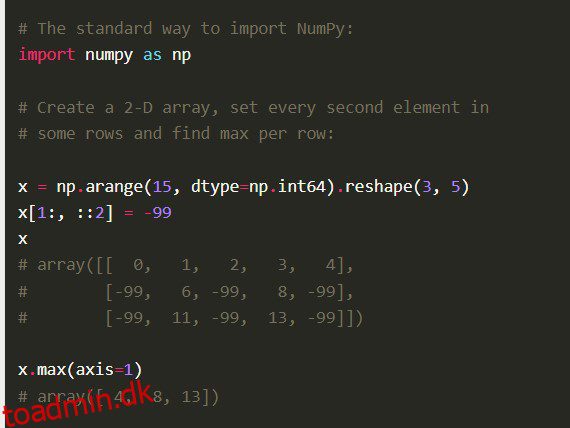
Numpy Python-biblioteket, også Numerical Python Code i sin helhed, er bygget med veloptimeret C-kode. Data Scientists foretrækker det for dets dybtgående matematiske beregninger og videnskabelige beregninger.
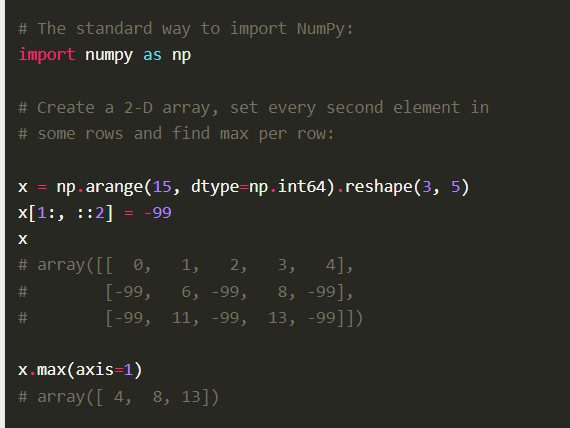
Funktioner
Numpy kommer med andre omfattende funktioner som vektorisering af matematiske operationer, indeksering og nøglekoncepter i implementering af arrays og matricer.
Pandaer
Pandas er et berømt bibliotek i Machine Learning, der leverer datastrukturer på højt niveau og talrige værktøjer til at analysere massive datasæt ubesværet og effektivt. Med meget få kommandoer kan dette bibliotek oversætte komplekse operationer med data.
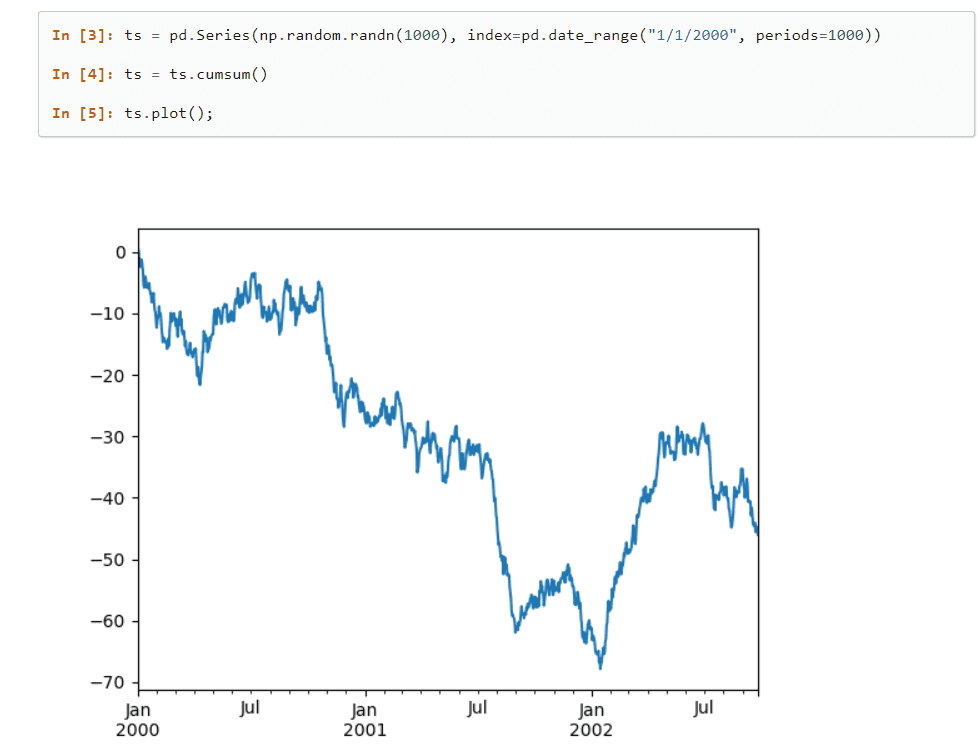
Talrige indbyggede metoder, der kan gruppere, indeksere, hente, opdele, omstrukturere data og filtrere sæt, før de indsættes i enkelt- og flerdimensionelle tabeller; udgør dette bibliotek.
Pandas biblioteks hovedfunktioner
Den er yderst effektiv på grund af sin gode dataanalysefunktionalitet og høje fleksibilitet.
Matplotlib
Matplotlib 2D grafiske Python-bibliotek kan nemt håndtere data fra adskillige kilder. De visualiseringer, det skaber, er statiske, animerede og interaktive, som brugeren kan zoome ind på, hvilket gør det effektivt til visualiseringer og oprettelse af diagrammer. Det giver også mulighed for tilpasning af layoutet og den visuelle stil.
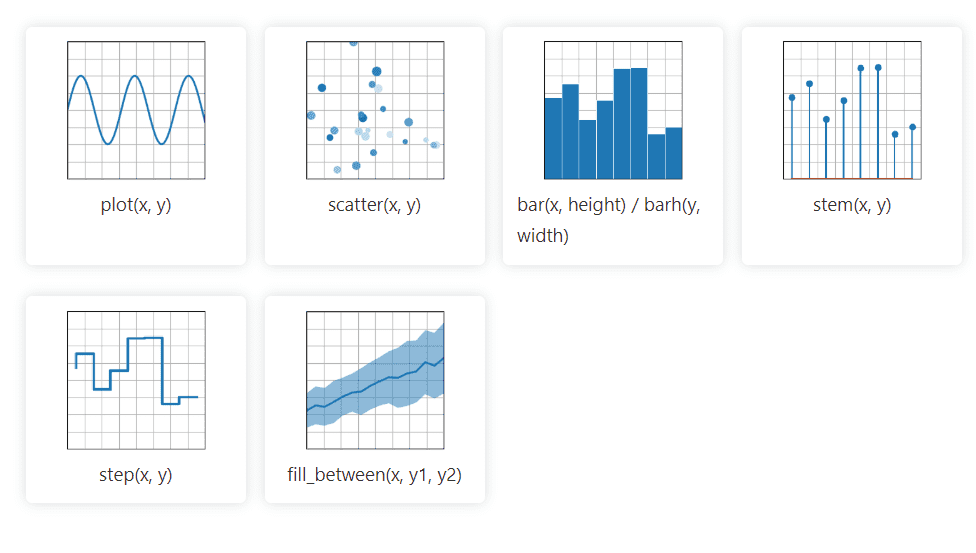
Dens dokumentation er open source og tilbyder en omfattende samling af værktøjer, der kræves til implementering.
Matplotlib importerer hjælperklasser for at implementere år, måned, dag og uge, hvilket gør det effektivt at manipulere tidsseriedata.
Scikit-lær
Hvis du overvejer et bibliotek til at hjælpe dig med at arbejde med komplekse data, bør Scikit-learn være dit ideelle bibliotek. Maskinlæringseksperter bruger i vid udstrækning Scikit-learn. Biblioteket er forbundet med andre biblioteker som NumPy, SciPy og matplotlib. Det tilbyder både overvågede og uovervågede læringsalgoritmer, der kan bruges til produktionsapplikationer.

Funktioner i Scikit-learn Python-biblioteket
Scikit-learn-biblioteket er effektivt til udtræk af funktioner fra tekst- og billeddatasæt. Desuden er det muligt at kontrollere nøjagtigheden af overvågede modeller på usete data. Dens talrige tilgængelige algoritmer muliggør datamining og andre maskinlæringsopgaver.
SciPy
SciPy (Scientific Python Code) er et maskinlæringsbibliotek, der leverer moduler anvendt til matematiske funktioner og algoritmer, som er bredt anvendelige. Dens algoritmer løser algebraiske ligninger, interpolation, optimering, statistik og integration.
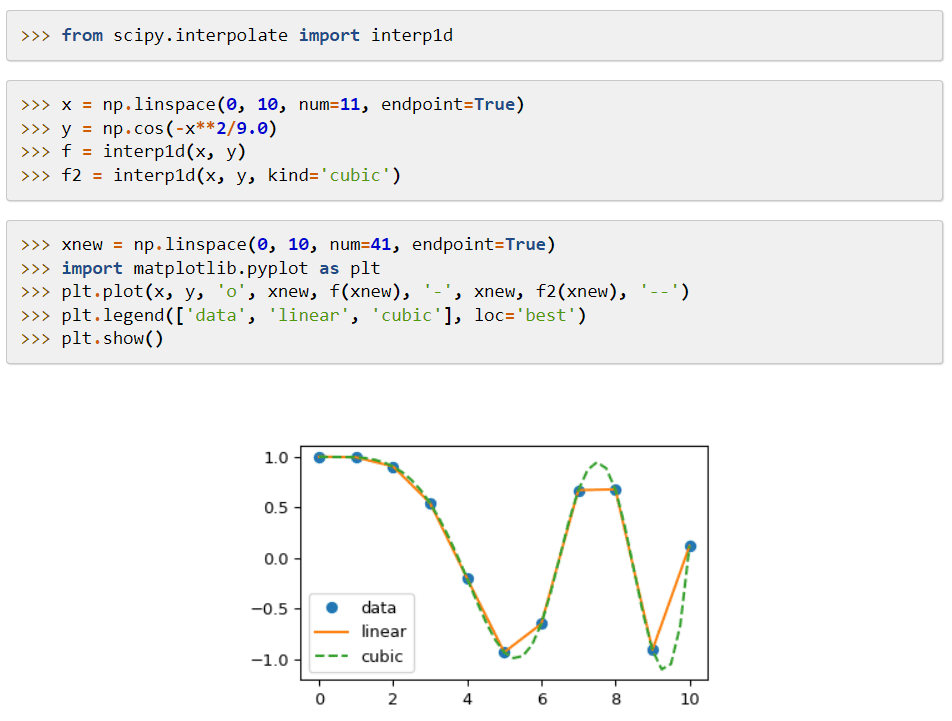
Dens hovedfunktion er dens udvidelse til NumPy, som tilføjer værktøjer til at løse de matematiske funktioner og giver datastrukturer som sparsomme matricer.
SciPy bruger kommandoer og klasser på højt niveau til at manipulere og visualisere data. Dens databehandling og prototypesystemer gør det til et endnu mere effektivt værktøj.
Desuden gør SciPys syntaks på højt niveau det nemt for programmører på ethvert erfaringsniveau at bruge.
SciPys eneste ulempe er dens eneste fokus på numeriske objekter og algoritmer; derfor ude af stand til at tilbyde nogen plottefunktion.
PyTorch
Dette mangfoldige maskinlæringsbibliotek implementerer effektivt tensorberegninger med GPU-acceleration, hvilket skaber dynamiske beregningsgrafer og automatiske gradientberegninger. Torch-biblioteket, et open source-maskinlæringsbibliotek udviklet på C, bygger PyTorch-biblioteket.

Nøglefunktioner omfatter:
Du kan bruge PyTorch til at udvikle NLP-applikationer.
Keras
Keras er et open source maskinlærings-Python-bibliotek, der bruges til at eksperimentere med dybe neurale netværk.
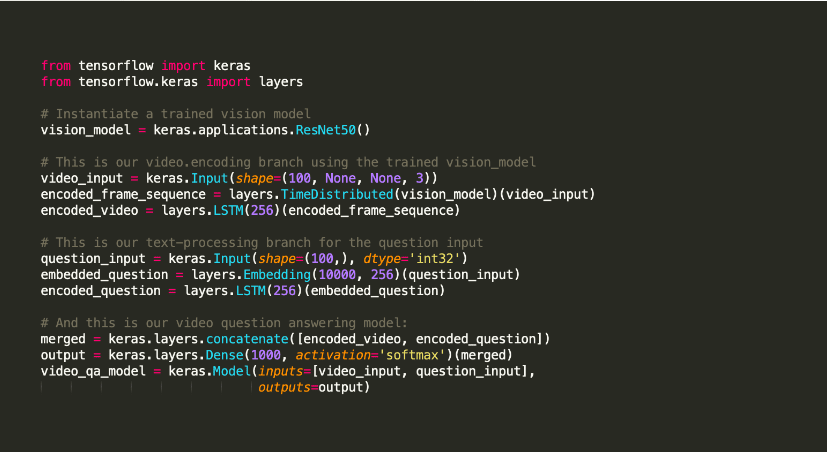
Det er berømt for at tilbyde værktøjer, der understøtter opgaver som modelkompilering og grafvisualiseringer, blandt andre. Den anvender Tensorflow til sin backend. Alternativt kan du bruge Theano eller neurale netværk som CNTK i backend. Denne backend-infrastruktur hjælper den med at skabe beregningsgrafer, der bruges til at implementere operationer.
Nøglefunktioner i biblioteket
Anvendelser af Keras inkluderer neurale netværksbyggeklodser som lag og mål, blandt andre værktøjer, der letter arbejdet med billeder og tekstdata.
Søfødt
Seaborn er et andet værdifuldt værktøj i statistisk datavisualisering.
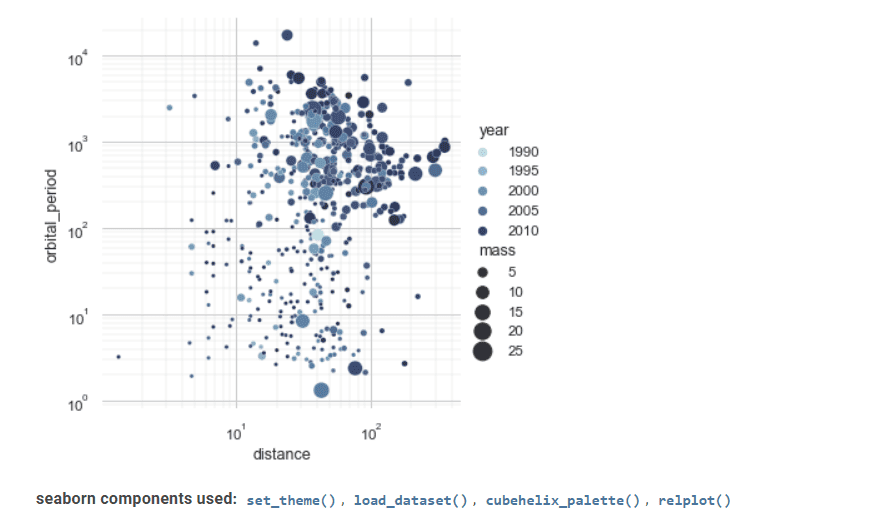
Dens avancerede grænseflade kan implementere attraktive og informative statistiske grafiktegninger.
Komplott
Plotly er et 3D webbaseret visualiseringsværktøj bygget på Plotly JS-biblioteket. Det har bred understøttelse af forskellige diagramtyper såsom linjediagrammer, punktdiagrammer og bokstyper sparklines.
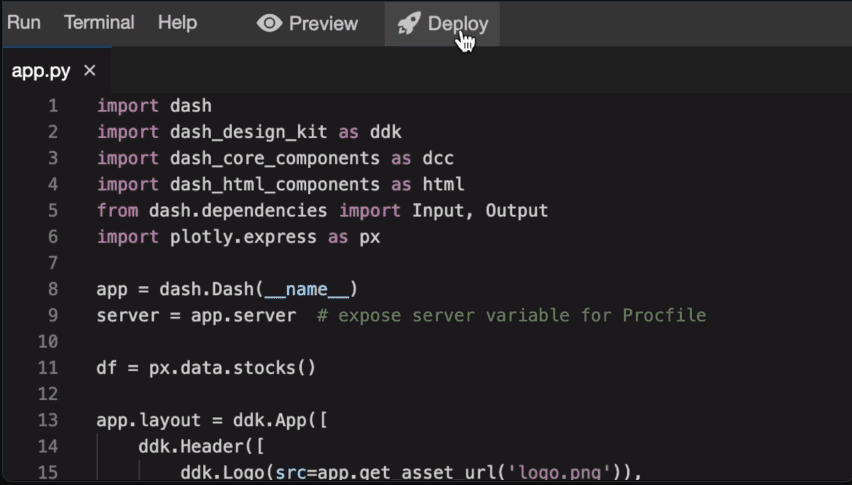
Dens applikation omfatter oprettelse af webbaserede datavisualiseringer i Jupyter-notebooks.
Plotly er velegnet til visualisering, fordi den kan påpege afvigelser eller abnormiteter i grafen med sit svæveværktøj. Du kan også tilpasse graferne, så de passer til dine præferencer.
På Plotlys ulempe er dens dokumentation forældet; derfor kan det være svært for brugeren at bruge det som vejledning. Desuden har den adskillige værktøjer, som brugeren bør lære. Det kan være udfordrende at holde styr på dem alle.
Funktioner i Plotly Python-biblioteket
SimpleITK
SimpleITK er et billedanalysebibliotek, der tilbyder en grænseflade til Insight Toolkit(ITK). Det er baseret på C++ og er open source.
Funktioner i SimpleITK-biblioteket
Dens forenklede grænseflade er tilgængelig i forskellige programmeringssprog som R, C#, C++, Java og Python.
Statsmodel
Statsmodel estimerer statistiske modeller, implementerer statistiske test og udforsker statistiske data ved hjælp af klasser og funktioner.
Angivelse af modeller bruger formler i R-stil, NumPy-arrays og Pandas-datarammer.
Skrabet
Denne open source-pakke er et foretrukket værktøj til at hente (skrabe) og crawle data fra et websted. Det er asynkront og derfor relativt hurtigt. Scrapy har arkitektur og funktioner, der gør det effektivt.
På min side er installationen forskellig for forskellige operativsystemer. Desuden kan du ikke bruge det på hjemmesider bygget på JS. Det kan også kun fungere med Python 2.7 eller nyere versioner.
Data Science-eksperter anvender det i datamining og automatiseret test.
Funktioner
Pude
Pillow er et Python-billedbibliotek, der manipulerer og behandler billeder.
Det tilføjer Python-fortolkerens billedbehandlingsfunktioner, understøtter forskellige filformater og tilbyder en fremragende intern repræsentation.
Data gemt i grundlæggende filformater kan nemt tilgås takket være Pillow.
Afslutning💃
Det opsummerer vores udforskning af nogle af de bedste Python-biblioteker for dataforskere og maskinlæringseksperter.
Som denne artikel viser, har Python mere nyttige maskinlærings- og datavidenskabspakker. Python har andre biblioteker, du kan anvende på andre områder.
Du vil måske vide noget om nogle af de bedste datavidenskabelige notesbøger.
God læring!