

Web skrabning er ideen om at udtrække information fra et websted og bruge det til en bestemt brugssag.
Lad os sige, at du forsøger at udtrække en tabel fra en webside, konvertere den til en JSON-fil og bruge JSON-filen til at bygge nogle interne værktøjer. Ved hjælp af web-skrabning kan du udtrække de data, du ønsker, ved at målrette de specifikke elementer på en webside. Web-skrabning ved hjælp af Python er et meget populært valg, da Python tilbyder flere biblioteker som BeautifulSoup eller Scrapy for at udtrække data effektivt.
At have evnen til at udtrække data effektivt er også meget vigtigt som udvikler eller dataforsker. Denne artikel hjælper dig med at forstå, hvordan du skraber et websted effektivt og får det nødvendige indhold til at manipulere det efter dit behov. Til denne vejledning vil vi bruge BeautifulSoup-pakken. Det er en trendy pakke til at skrabe data i Python.
Indholdsfortegnelse
Hvorfor bruge Python til Web Scraping?
Python er det første valg for mange udviklere, når de bygger webskrabere. Der er mange grunde til, at Python er det første valg, men lad os til denne artikel diskutere tre hovedårsager til, at Python bruges til dataskrabning.
Bibliotek og Community Support: Der er adskillige fantastiske biblioteker, som BeautifulSoup, Scrapy, Selen, osv., der giver fantastiske funktioner til effektivt at skrabe websider. Det har bygget et fremragende økosystem til web-skrabning, og også fordi mange udviklere verden over allerede bruger Python, kan du hurtigt få hjælp, når du sidder fast.
Automation: Python er berømt for sine automatiseringsmuligheder. Der kræves mere end webskrabning, hvis du forsøger at lave et komplekst værktøj, der er afhængig af skrabning. For eksempel, hvis du vil bygge et værktøj, der sporer prisen på varer i en onlinebutik, skal du tilføje nogle automatiseringsmuligheder, så det kan spore priserne dagligt og tilføje dem til din database. Python giver dig muligheden for at automatisere sådanne processer med lethed.
Datavisualisering: Web-skrabning er meget brugt af datavidenskabsfolk. Dataforskere har ofte brug for at udtrække data fra websider. Med biblioteker som Pandas gør Python datavisualisering enklere fra rå data.
Biblioteker til webskrabning i Python
Der er flere tilgængelige biblioteker i Python til at gøre web-skrabning enklere. Lad os diskutere de tre mest populære biblioteker her.
#1. Smuk suppe
Et af de mest populære biblioteker til web-skrabning. BeautifulSoup har hjulpet udviklere med at skrabe websider siden 2004. Det giver enkle metoder til at navigere, søge og ændre parsetræet. Beautifulsoup selv laver også kodningen for indgående og udgående data. Det er velholdt og har et godt fællesskab.
#2. Skrabet
En anden populær ramme for dataudtræk. Scrapy har mere end 43000 stjerner på GitHub. Det kan også bruges til at skrabe data fra API’er. Det har også et par interessante indbyggede support, som at sende e-mails.
#3. Selen
Selen er ikke hovedsageligt et webskrabningsbibliotek. I stedet er det en browserautomatiseringspakke. Men vi kan nemt udvide dens funktionaliteter til at skrabe websider. Den bruger WebDriver-protokollen til at styre forskellige browsere. Selen har været på markedet i næsten 20 år nu. Men ved at bruge Selenium kan du nemt automatisere og skrabe data fra websider.
Udfordringer med Python Web Scraping
Man kan stå over for mange udfordringer, når man forsøger at skrabe data fra hjemmesider. Der er problemer som langsomme netværk, anti-skrabeværktøjer, IP-baseret blokering, captcha-blokering osv. Disse problemer kan forårsage massive problemer, når du forsøger at skrabe et websted.
Men du kan effektivt omgå udfordringer ved at følge nogle måder. For eksempel blokeres en IP-adresse i de fleste tilfælde af et websted, når der er mere end en vis mængde af forespørgsler sendt i et bestemt tidsinterval. For at undgå IP-blokering skal du kode din skraber, så den køles af efter afsendelse af anmodninger.

Udviklere har også en tendens til at sætte honeypot-fælder til skrabere. Disse fælder er normalt usynlige for bare menneskelige øjne, men kan gennemsøges af en skraber. Hvis du skraber et websted, der sætter en sådan honningpotfælde, skal du kode din skraber i overensstemmelse hermed.
Captcha er et andet alvorligt problem med skrabere. De fleste websteder bruger i dag en captcha til at beskytte botadgang til deres sider. I et sådant tilfælde skal du muligvis bruge en captcha-løser.
Skrabning af en hjemmeside med Python
Som vi diskuterede, vil vi bruge BeautifulSoup til at skrotte et websted. I denne vejledning vil vi skrabe de historiske data for Ethereum fra Coingecko og gemme tabeldataene som en JSON-fil. Lad os gå videre til at bygge skraberen.
Det første trin er at installere BeautifulSoup and Requests. Til denne tutorial bruger jeg Pipenv. Pipenv er en virtuelt miljømanager for Python. Du kan også bruge Venv, hvis du vil, men jeg foretrækker Pipenv. At diskutere Pipenv ligger uden for denne tutorials rammer. Men hvis du vil lære, hvordan Pipenv kan bruges, så følg denne vejledning. Eller, hvis du ønsker at forstå Python virtuelle miljøer, følg denne vejledning.
Start Pipenv-skallen i din projektmappe ved at køre kommandoen pipenv-shell. Det vil lancere en subshell i dit virtuelle miljø. For at installere BeautifulSoup skal du køre følgende kommando:
pipenv install beautifulsoup4
Og for at installere anmodninger, kør kommandoen svarende til ovenstående:
pipenv install requests
Når installationen er færdig, skal du importere de nødvendige pakker til hovedfilen. Opret en fil kaldet main.py og importer pakkerne som nedenstående:
from bs4 import BeautifulSoup import requests import json
Det næste trin er at få den historiske datasides indhold og parse dem ved hjælp af HTML-parseren, der er tilgængelig i BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
I ovenstående kode tilgås siden ved hjælp af get-metoden, der er tilgængelig i anmodningsbiblioteket. Det analyserede indhold gemmes derefter i en variabel kaldet suppe.
Den originale skrabedel starter nu. Først skal du identificere tabellen korrekt i DOM. Hvis du åbner denne side og inspicerer den ved hjælp af de udviklerværktøjer, der er tilgængelige i browseren, vil du se, at tabellen har disse klassetabeller, tabelstribet tekst-sm text-lg-normal.
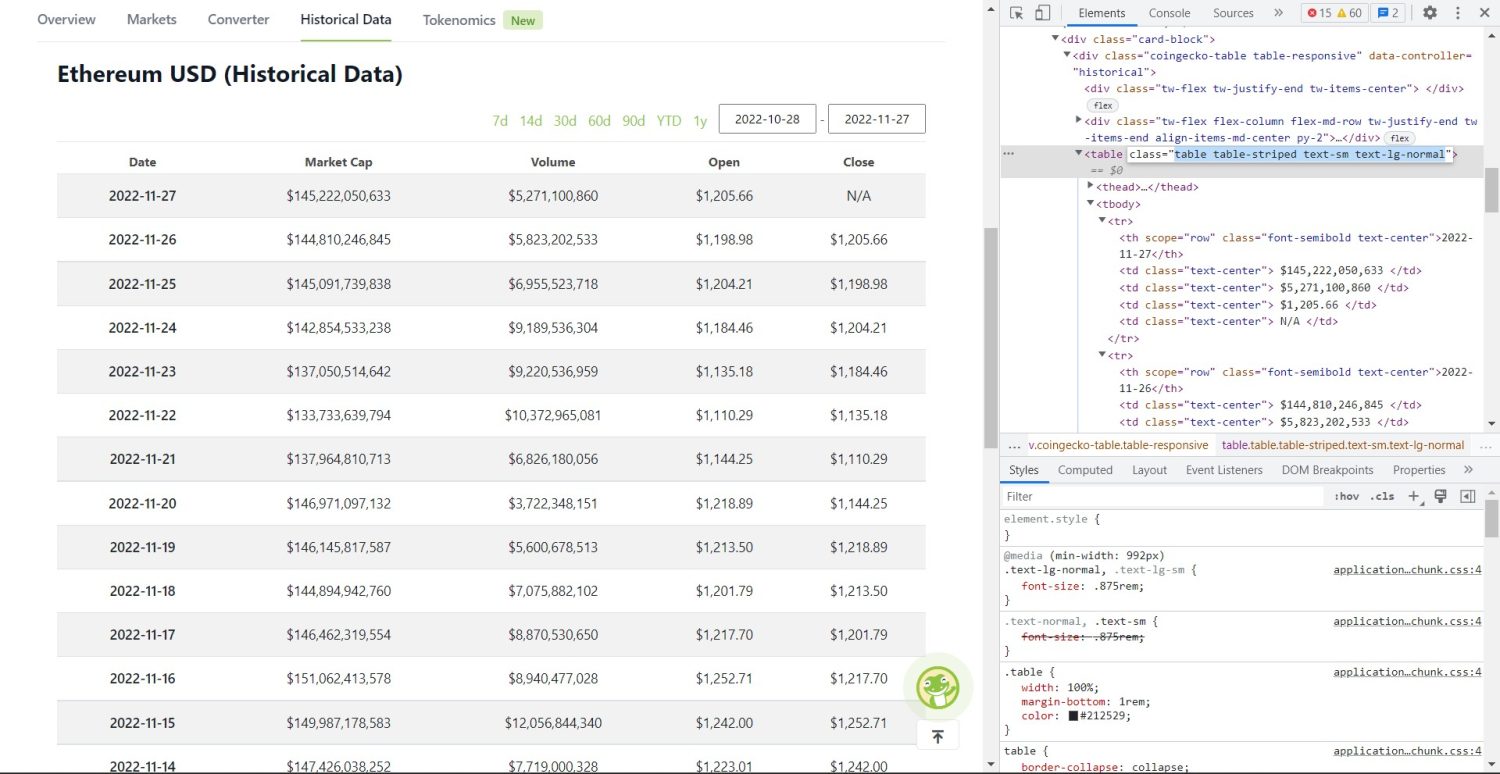 Coingecko Ethereum historiske datatabel
Coingecko Ethereum historiske datatabel
For at målrette denne tabel korrekt kan du bruge find-metoden.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
I ovenstående kode findes først tabellen ved hjælp af soup.find metoden, derefter ved hjælp af find_all metoden søges alle tr-elementer inde i tabellen. Disse tr-elementer er gemt i en variabel kaldet table_data. Tabellen har nogle få elementer til titlen. En ny variabel kaldet table_headings initialiseres for at holde titlerne på en liste.
En for-løkke køres derefter for den første række i tabellen. I denne række søges alle elementer med th, og deres tekstværdi tilføjes til tabeloverskrifter-listen. Teksten er udtrukket ved hjælp af tekstmetoden. Hvis du udskriver variablen table_headings nu, vil du kunne se følgende output:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Det næste trin er at skrabe resten af elementerne, generere en ordbog for hver række og derefter tilføje rækkerne til en liste.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Dette er den væsentlige del af koden. For hver tr i tabeldata-variablen søges først de th elementer. De th elementer er datoen vist i tabellen. Disse th elementer er gemt inde i en variabel th. På samme måde er alle td-elementerne gemt i td-variablen.
En tom ordbogsdata initialiseres. Efter initialiseringen går vi gennem rækken af td-elementer. For hver række opdaterer vi først det første felt i ordbogen med det første punkt i th. Koden table_headings[0]: th[0].text tildeler et nøgleværdi-par af dato og det første element.
Efter initialisering af det første element tildeles de andre elementer ved hjælp af data.update({table_headings[i+1]: td[i].text.replace(‘n’, ”)}). Her udtrækkes td elements-tekst først ved hjælp af tekstmetoden, og derefter erstattes alle n med erstatningsmetoden. Værdien tildeles derefter til elementet i+1 i tabeloverskrifter-listen, fordi det i-de element allerede er tildelt.
Hvis dataordbogens længde overstiger nul, føjer vi ordbogen til listen table_details. Du kan udskrive table_details listen for at kontrollere. Men vi vil skrive værdierne en JSON-fil. Lad os tage et kig på koden til dette,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Vi bruger her json.dump-metoden til at skrive værdierne ind i en JSON-fil kaldet table.json. Når skrivningen er fuldført, udskriver vi Data gemt i json-filen… i konsollen.
Kør nu filen ved at bruge følgende kommando,
python run main.py
Efter et stykke tid vil du være i stand til at se data gemt i JSON-fil… tekst i konsollen. Du vil også se en ny fil kaldet table.json i arbejdsfilbiblioteket. Filen vil ligne følgende JSON-fil:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Du har med succes implementeret en webskraber ved hjælp af Python. For at se den komplette kode kan du besøge denne GitHub-repo.
Konklusion
Denne artikel diskuterede, hvordan du kunne implementere en simpel Python-skrabe. Vi diskuterede, hvordan BeautifulSoup kunne bruges til hurtigt at skrabe data fra hjemmesiden. Vi diskuterede også andre tilgængelige biblioteker, og hvorfor Python er det første valg for mange udviklere til at skrabe websteder.
Du kan også se på disse web-skrabningsrammer.