

Behandling af big data er en af de mest komplekse procedurer, som organisationer står over for. Processen bliver mere kompliceret, når du har en stor mængde realtidsdata.
I dette indlæg vil vi opdage, hvad big databehandling er, hvordan det gøres, og udforske Apache Kafka og Spark – de to af de mest berømte databehandlingsværktøjer!
Indholdsfortegnelse
Hvad er databehandling? Hvordan gøres det?
Databehandling er defineret som enhver operation eller et sæt af operationer, uanset om det udføres ved hjælp af en automatiseret proces eller ej. Det kan opfattes som indsamling, bestilling og organisering af information i overensstemmelse med en logisk og passende disposition til fortolkning.
Når en bruger får adgang til en database og får resultater for deres søgning, er det databehandlingen, der giver dem de resultater, de har brug for. De oplysninger, der udtrækkes som et søgeresultat, er resultatet af databehandling. Det er derfor, informationsteknologi har fokus i sin eksistens centreret om databehandling.
Traditionel databehandling blev udført ved hjælp af simpel software. Men med fremkomsten af Big Data har tingene ændret sig. Big Data refererer til information, hvis volumen kan være over hundrede terabyte og petabyte.
Desuden opdateres disse oplysninger regelmæssigt. Eksempler omfatter data, der kommer fra kontaktcentre, sociale medier, børshandelsdata osv. Sådanne data kaldes nogle gange også datastrøm – en konstant, ukontrolleret strøm af data. Dens vigtigste egenskab er, at dataene ikke har nogen definerede grænser, så det er umuligt at sige, hvornår streamen starter eller slutter.
Data behandles, efterhånden som de ankommer til destinationen. Nogle forfattere kalder det realtids- eller onlinebehandling. En anden tilgang er blok-, batch- eller offlinebehandling, hvor datablokke behandles i tidsvinduer på timer eller dage. Ofte er batchen en proces, der kører om natten og konsoliderer dagens data. Der er tilfælde af tidsvinduer på en uge eller endda en måned, der genererer forældede rapporter.
Da de bedste Big Data-behandlingsplatforme via streaming er åbne kilder som Kafka og Spark, tillader disse platforme brugen af andre forskellige og komplementære. Det betyder, at de er open source, udvikler sig hurtigere og bruger flere værktøjer. På denne måde modtages datastrømme fra andre steder med en variabel hastighed og uden afbrydelser.
Nu vil vi se på to af de mest kendte databehandlingsværktøjer og sammenligne dem:
Apache Kafka
Apache Kafka er et meddelelsessystem, der skaber streaming-applikationer med et kontinuerligt dataflow. Oprindeligt skabt af LinkedIn, Kafka er log-baseret; en log er en grundlæggende form for lagring, fordi hver ny information tilføjes til slutningen af filen.

Kafka er en af de bedste løsninger til big data, fordi dens vigtigste egenskab er dens høje gennemstrømning. Med Apache Kafka er det endda muligt at transformere batchbehandling i realtid,
Apache Kafka er et udgiv-abonner-meddelelsessystem, hvor en applikation udgiver, og en applikation, der abonnerer, modtager meddelelser. Tiden mellem publicering og modtagelse af beskeden kan være millisekunder, så en Kafka-løsning har lav latenstid.
Kafkas arbejde
Apache Kafkas arkitektur omfatter producenter, forbrugere og selve klyngen. Producenten er enhver applikation, der udgiver beskeder til klyngen. Forbrugeren er enhver applikation, der modtager beskeder fra Kafka. Kafka-klyngen er et sæt noder, der fungerer som en enkelt forekomst af beskedtjenesten.
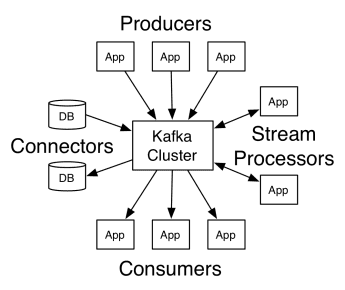 Kafkas arbejde
Kafkas arbejde
En Kafka-klynge består af flere mæglere. En mægler er en Kafka-server, der modtager beskeder fra producenter og skriver dem til disk. Hver mægler administrerer en liste over emner, og hvert emne er opdelt i flere partitioner.
Efter at have modtaget beskederne sender mægleren dem til de registrerede forbrugere for hvert emne.
Apache Kafka-indstillinger administreres af Apache Zookeeper, som gemmer klyngemetadata såsom partitionsplacering, liste over navne, liste over emner og tilgængelige noder. Zookeeper opretholder således synkronisering mellem klyngens forskellige elementer.
Zookeeper er vigtig, fordi Kafka er et distribueret system; det vil sige, at skrivning og læsning udføres af flere klienter samtidigt. Når der er en fejl, vælger dyrepasseren en afløser og genopretter operationen.
Brug Cases
Kafka blev populær, især for dets brug som et meddelelsesværktøj, men dets alsidighed rækker ud over det, og det kan bruges i en række forskellige scenarier, som i eksemplerne nedenfor.
Beskeder
Asynkron kommunikationsform, der afkobler de parter, der kommunikerer. I denne model sender en part dataene som en besked til Kafka, så en anden applikation bruger dem senere.
Aktivitetssporing
Gør det muligt for dig at gemme og behandle data, der sporer en brugers interaktion med et websted, såsom sidevisninger, klik, dataindtastning osv.; denne type aktivitet genererer normalt en stor mængde data.
Metrics
Indebærer at samle data og statistik fra flere kilder for at generere en centraliseret rapport.
Log aggregering
Aggregerer og gemmer centralt logfiler, der stammer fra andre systemer.
Stream behandling
Behandling af datapipelines består af flere stadier, hvor rådata forbruges fra emner og aggregeres, beriges eller omdannes til andre emner.
For at understøtte disse funktioner tilbyder platformen i det væsentlige tre API’er:
- Streams API: Det fungerer som en stream-processor, der forbruger data fra et emne, transformerer det og skriver det til et andet.
- Connectors API: Det giver mulighed for at forbinde emner til eksisterende systemer, såsom relationelle databaser.
- Producent- og forbruger-API’er: Det giver applikationer mulighed for at publicere og forbruge Kafka-data.
Fordele
Replikeret, opdelt og bestilt
Meddelelser i Kafka replikeres på tværs af partitioner på tværs af klynge noder i den rækkefølge, de ankommer for at sikre sikkerhed og leveringshastighed.
Datatransformation
Med Apache Kafka er det endda muligt at transformere batchbehandling i realtid ved hjælp af batch ETL streams API.
Sekventiel diskadgang
Apache Kafka fastholder beskeden på disken og ikke i hukommelsen, da den formodes at være hurtigere. Faktisk er hukommelsesadgang hurtigere i de fleste situationer, især når man overvejer at få adgang til data, der er på tilfældige steder i hukommelsen. Kafka har dog sekventiel adgang, og i dette tilfælde er disken mere effektiv.
Apache Spark
Apache Spark er en stor databeregningsmotor og et sæt biblioteker til behandling af parallelle data på tværs af klynger. Spark er en udvikling af Hadoop og Map-Reduce programmeringsparadigmet. Det kan være 100 gange hurtigere takket være dets effektive brug af hukommelse, der ikke bevarer data på diske under behandling.
Spark er organiseret på tre niveauer:
- Low-Level API’er: Dette niveau indeholder den grundlæggende funktionalitet til at køre job og anden funktionalitet, der kræves af de andre komponenter. Andre vigtige funktioner i dette lag er styring af sikkerhed, netværk, planlægning og logisk adgang til filsystemer HDFS, GlusterFS, Amazon S3 og andre.
- Structured API’er: Structured API-niveauet omhandler datamanipulation gennem DataSets eller DataFrames, som kan læses i formater som Hive, Parket, JSON og andre. Ved at bruge SparkSQL (API, der giver os mulighed for at skrive forespørgsler i SQL), kan vi manipulere dataene, som vi vil.
- Højt niveau: På højeste niveau har vi Spark-økosystemet med forskellige biblioteker, herunder Spark Streaming, Spark MLlib og Spark GraphX. De er ansvarlige for at tage sig af streaming-indtagelse og de omkringliggende processer, såsom crash recovery, oprettelse og validering af klassiske machine learning-modeller og håndtering af grafer og algoritmer.
Virkning af Spark
Arkitekturen af en Spark-applikation består af tre hoveddele:
Driverprogram: Det er ansvarligt for at orkestrere udførelsen af databehandling.
Cluster Manager: Det er den komponent, der er ansvarlig for at styre de forskellige maskiner i en klynge. Kun nødvendig hvis Spark kører distribueret.
Arbejderknudepunkter: Disse er de maskiner, der udfører opgaverne i et program. Hvis Spark køres lokalt på din maskine, vil den spille et driverprogram og en Workes-rolle. Denne måde at køre Spark på kaldes Standalone.
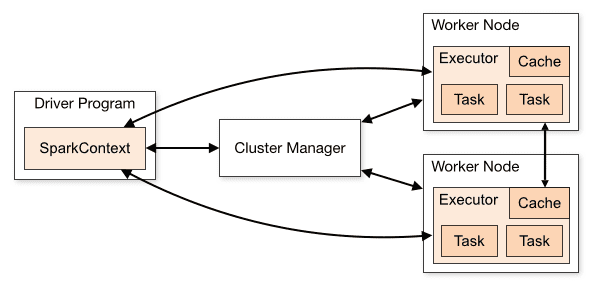 Klyngeoversigt
Klyngeoversigt
Spark-kode kan skrives på en række forskellige sprog. Spark-konsollen, kaldet Spark Shell, er interaktiv til at lære og udforske data.
Den såkaldte Spark-applikation består af et eller flere job, der muliggør understøttelse af databehandling i stor skala.
Når vi taler om udførelse, har Spark to tilstande:
- Klient: Driveren kører direkte på klienten, som ikke går gennem Resource Manager.
- Klynge: Driver, der kører på applikationsmasteren gennem ressourcehåndteringen (i klyngetilstand, hvis klienten afbryder forbindelsen, fortsætter applikationen med at køre).
Det er nødvendigt at bruge Spark korrekt, så de tilknyttede tjenester, såsom Resource Manager, kan identificere behovet for hver udførelse, hvilket giver den bedste ydeevne. Så det er op til udvikleren at kende den bedste måde at køre deres Spark-job på, strukturere opkaldet, og til dette kan du strukturere og konfigurere udførerne Spark, som du ønsker.
Spark-job bruger primært hukommelse, så det er almindeligt at justere Spark-konfigurationsværdier for arbejdsknudeudøvere. Afhængigt af Spark-arbejdsbelastningen er det muligt at bestemme, at en bestemt ikke-standard Spark-konfiguration giver mere optimale eksekveringer. Til dette formål kan der udføres sammenligningstest mellem de forskellige tilgængelige konfigurationsmuligheder og selve standard Spark-konfigurationen.
Bruger Cases
Apache Spark hjælper med at behandle enorme mængder data, uanset om det er i realtid eller arkiveret, struktureret eller ustruktureret. Følgende er nogle af dets populære anvendelsesmuligheder.
Databerigelse
Ofte bruger virksomheder en kombination af historiske kundedata med adfærdsdata i realtid. Spark kan hjælpe med at opbygge en kontinuerlig ETL-pipeline til at konvertere ustrukturerede hændelsesdata til strukturerede data.
Trigger hændelsesdetektion
Spark Streaming giver mulighed for hurtig registrering og reaktion på sjælden eller mistænkelig adfærd, der kunne indikere et potentielt problem eller bedrageri.
Kompleks sessionsdataanalyse
Ved hjælp af Spark Streaming kan hændelser relateret til brugerens session, såsom deres aktiviteter efter at have logget på applikationen, grupperes og analyseres. Disse oplysninger kan også bruges løbende til at opdatere maskinlæringsmodeller.
Fordele
Iterativ behandling
Hvis opgaven er at behandle data gentagne gange, tillader Sparks modstandsdygtige distribuerede datasæt (RDD’er) flere kortoperationer i hukommelsen uden at skulle skrive midlertidige resultater til disken.
Grafisk behandling
Sparks beregningsmodel med GraphX API er fremragende til iterative beregninger, der er typiske for grafikbehandling.
Maskinelæring
Spark har MLlib — et indbygget maskinlæringsbibliotek, der har færdige algoritmer, der også kører i hukommelsen.
Kafka vs. Spark
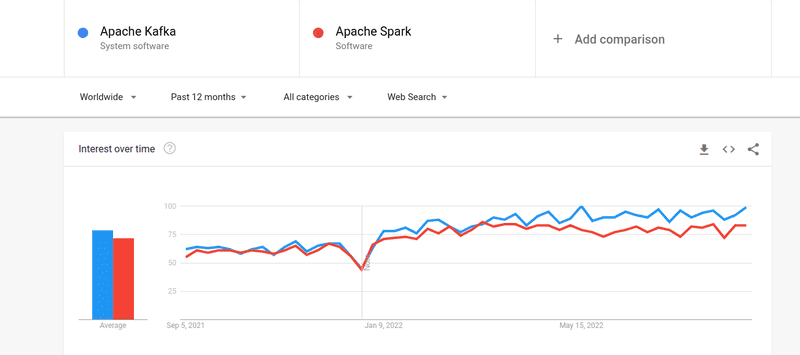
Selvom interessen blandt folk for både Kafka og Spark har været næsten ens, er der nogle store forskelle mellem de to; Lad os kigge på det.
#1. Databehandling
Kafka er et datastreaming- og lagringsværktøj i realtid, der er ansvarlig for at overføre data mellem applikationer, men det er ikke nok til at bygge en komplet løsning. Derfor er der brug for andre værktøjer til opgaver, som Kafka ikke gør, såsom Spark. Spark, på den anden side, er en batch-first databehandlingsplatform, der trækker data fra Kafka-emner og transformerer dem til kombinerede skemaer.
#2. Hukommelseshåndtering
Spark bruger Robust Distributed Datasets (RDD) til hukommelsesstyring. I stedet for at forsøge at behandle enorme datasæt, fordeler den dem over flere noder i en klynge. I modsætning hertil bruger Kafka sekventiel adgang svarende til HDFS og gemmer data i en bufferhukommelse.
#3. ETL transformation
Både Spark og Kafka understøtter ETL-transformationsprocessen, som kopierer poster fra en database til en anden, normalt fra et transaktionsgrundlag (OLTP) til et analytisk grundlag (OLAP). Men i modsætning til Spark, som kommer med en indbygget evne til ETL-proces, er Kafka afhængig af Streams API til at understøtte det.
#4. Datapersistens

Sparks brug af RRD giver dig mulighed for at gemme dataene flere steder til senere brug, hvorimod du i Kafka skal definere datasætobjekter i konfiguration for at bevare data.
#5. Vanskelighed
Spark er en komplet løsning og lettere at lære på grund af dens understøttelse af forskellige programmeringssprog på højt niveau. Kafka er afhængig af en række forskellige API’er og tredjepartsmoduler, hvilket kan gøre det svært at arbejde med.
#6. Genopretning
Både Spark og Kafka giver mulighed for gendannelse. Spark bruger RRD, som giver den mulighed for at gemme data kontinuerligt, og hvis der er en klyngefejl, kan den gendannes.

Kafka replikerer løbende data inde i klyngen og replikerer på tværs af mæglere, hvilket giver dig mulighed for at gå videre til de forskellige mæglere, hvis der er en fejl.
Ligheder mellem Spark og Kafka
Apache SparkApache KafkaOpenSourceOpenSourceBuild Datastreaming ApplicationBuild Datastreaming ApplicationUnderstøtter Stateful ProcessingUnderstøtter Stateful ProcessingUnderstøtter SQLUnderstøtter SQLLigheder mellem Spark og Kafka
Afsluttende ord
Kafka og Spark er begge open source-værktøjer skrevet i Scala og Java, som giver dig mulighed for at bygge real-time datastreaming-applikationer. De har flere ting til fælles, herunder stateful behandling, understøttelse af SQL og ETL. Kafka og Spark kan også bruges som komplementære værktøjer til at hjælpe med at løse problemet med kompleksiteten i at overføre data mellem applikationer.