
Python er et meget alsidigt sprog, og Python-udviklere skal ofte arbejde med en række forskellige filer og få gemt information i dem til behandling. Et populært filformat, du er bundet til at støde på som Python-udvikler, er det bærbare dokumentformat populært kendt som PDF
PDF-filer kan indeholde tekst, billeder og links. Når du behandler data i et Python-program, kan du opleve, at du har brug for at udtrække de data, der er gemt i et PDF-dokument. I modsætning til datastrukturer såsom tupler, lister og ordbøger, kan det virke som en vanskelig ting at få gemt oplysninger i et PDF-dokument.
Heldigvis er der en række biblioteker, der gør det nemt at arbejde med PDF-filer og udtrække de data, der er gemt i PDF-filer. For at lære om disse forskellige biblioteker, lad os se på, hvordan du kan udtrække tekster, links og billeder fra PDF-filer. For at følge med skal du downloade følgende PDF-fil og gemme den i samme mappe som din Python-programfil.
For at udtrække tekst fra PDF-filer ved hjælp af Python, vil vi bruge PyPDF2 bibliotek. PyPDF2 er et gratis og open source Python-bibliotek, der kan bruges til at flette, beskære og transformere siderne i PDF-filer. Det kan tilføje brugerdefinerede data, visningsmuligheder og adgangskoder til PDF-filer. Det er dog vigtigt, at PyPDF2 kan hente tekst fra PDF-filer.
For at bruge PyPDF2 til at udtrække tekst fra PDF-filer, skal du installere det ved hjælp af pip, som er et pakkeinstallationsprogram til Python. pip giver dig mulighed for at installere forskellige Python-pakker på din maskine:
1. Tjek, om du allerede har pip installeret ved at køre:
pip --version
Hvis du ikke får et versionsnummer tilbage, betyder det, at pip ikke er installeret.
2. Klik på for at installere pip få pip for at downloade dets installationsscript.
Linket åbner en side med scriptet til at installere pip som vist nedenfor:
Højreklik på siden og klik på Gem som for at gemme filen. Som standard er navnet på filen get-pip.py
Åbn terminalen og naviger til mappen med den get-pip.py-fil, du lige har downloadet, og kør derefter kommandoen:
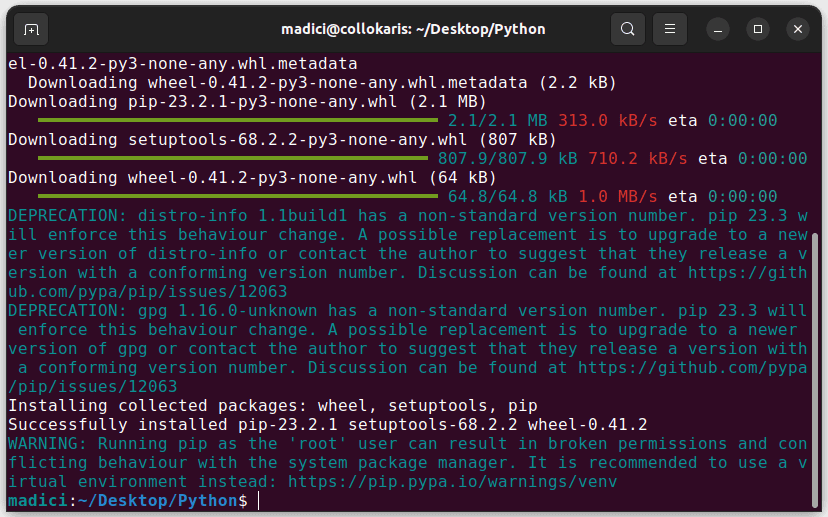
sudo python3 get-pip.py
Dette skal installere pip som vist nedenfor:
3. Kontroller, at pip blev installeret korrekt ved at køre:
pip --version
Hvis det lykkes, bør du få et versionsnummer:

Med pip installeret kan vi nu begynde at arbejde med PyPDF2.
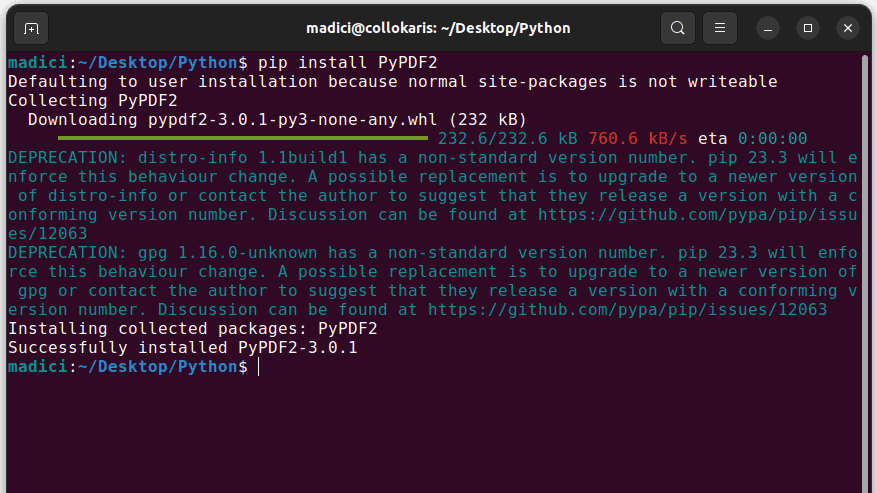
1. Installer PyPDF2 ved at udføre følgende kommando i terminalen:
pip install PyPDF2
2. Opret en Python-fil og importer PdfReader fra PyPDF2 ved hjælp af følgende linje:
from PyPDF2 import PdfReader
PyPDF2-biblioteket tilbyder en række klasser til at arbejde med PDF-filer. En sådan klasse er PdfReader, som blandt andet kan bruges til at åbne PDF-filer, læse indholdet og udtrække tekst fra PDF-filer.
3. For at begynde at arbejde med en PDF-fil skal du først åbne filen. For at gøre dette skal du oprette en instans af PdfReader-klassen og sende den PDF-fil, du vil arbejde med:
reader = PdfReader('games.pdf')
Linjen ovenfor instansierer PdfReader og forbereder den til at få adgang til indholdet af den PDF-fil, du angiver. Forekomsten er gemt i en variabel kaldet reader, som skal have adgang til en række forskellige metoder og egenskaber, der er tilgængelige i klassen PdfReader.
4. For at se, om alt fungerer fint, skal du udskrive antallet af sider i den PDF-fil, du har sendt i, ved hjælp af følgende kode:
print(len(reader.pages))
Produktion:
5
5. Da vores PDF-fil har 5 sider, kan vi få adgang til hver side, der er tilgængelig i PDF’en. Dog starter optællingen fra 0, ligesom Pythons indekseringskonvention. Derfor vil den første side i pdf-filen være sidenummer 0. For at hente den første side af PDF-filen skal du tilføje følgende linje til din kode:
page1 = reader.pages[0]
Linjen ovenfor henter den første side i PDF-filen og gemmer den i en variabel med navnet side1.
6. For at udtrække teksten på den første side af PDF-filen skal du tilføje følgende linje:
textPage1 = page1.extract_text()
Dette udtrækker teksten på den første side af PDF’en og gemmer indholdet i en variabel med navnet textPage1. Du har således adgang til teksten på første side af PDF-filen gennem variablen textPage1.
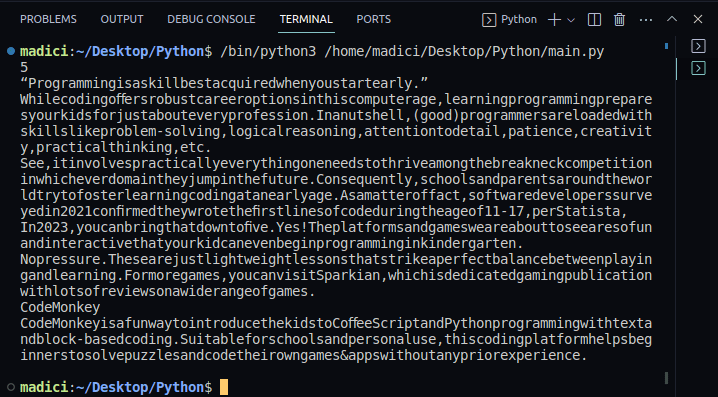
7. For at bekræfte, at teksten blev udtrukket, kan du udskrive indholdet af variablen textPage1. Hele vores kode, som også udskriver teksten på første side af PDF-filen, er vist nedenfor:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Produktion:
For at udtrække links fra PDF-filer går vi til PyMuPDF, som er et Python-bibliotek til at udtrække, analysere, konvertere og manipulere de data, der er gemt i dokumenter såsom PDF’er. For at bruge PyMuPDF skal du have Python 3.8 eller nyere. Sådan kommer du i gang:
1. Installer PyMuPDF ved at udføre følgende linje i terminalen:
pip install PyMuPDF
2. Importer PyMuPDF til din Python-fil ved hjælp af følgende sætning:
import fitz
3. For at få adgang til den PDF, du vil udtrække links fra, skal du først åbne den. Indtast følgende linje for at åbne den:
doc = fitz.open("games.pdf")
4. Når du har åbnet PDF-filen, skal du udskrive antallet af sider i PDF’en ved at bruge følgende linje:
print(doc.page_count)
Produktion:
5
4. For at udtrække links fra en side i PDF-filen skal vi indlæse den side, vi vil udpakke links fra. For at indlæse en side skal du indtaste følgende linje, hvor du indtaster det sidenummer, du vil indlæse i en funktion kaldet load_page()
page = doc.load_page(0)
For at udtrække links fra den første side sender vi 0(nul). Optællingen af sider starter fra nul ligesom i datastrukturer som arrays og ordbøger.
5. Udpak linkene fra siden ved hjælp af følgende linje:
links = page.get_links()
Alle links på den side, du har angivet, i vores tilfælde side 1, vil blive udtrukket og gemt i variablen kaldet links
6. For at se indholdet af linkvariablen skal du udskrive den sådan:
print(links)
Produktion:
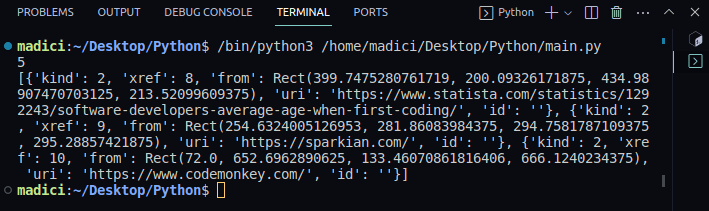
Fra det udskrevne output skal du bemærke, at de variable links indeholder en liste over ordbøger med nøgleværdi-par. Hvert link på siden er repræsenteret af en ordbog, med det faktiske link gemt under nøglen “uri”
7. For at få linkene fra listen over objekter, der er gemt under variabelnavnslinkene, skal du gentage listen ved hjælp af en for-in-sætning og udskrive de specifikke links, der er gemt under nøgle-urien. Hele koden, der gør dette, er vist nedenfor:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
Produktion:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
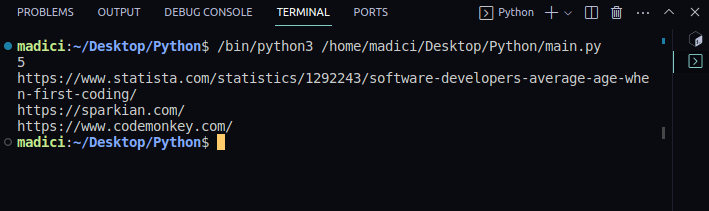
8. For at gøre vores kode mere genbrugelig, kan vi omfaktorere den ved at definere en funktion til at udtrække alle links i en PDF og en funktion til at udskrive alle links fundet i en PDF. På denne måde kan du kalde funktionerne med en hvilken som helst PDF, og du får alle links i PDF’en tilbage. Koden, der gør dette, er vist nedenfor:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
Produktion:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
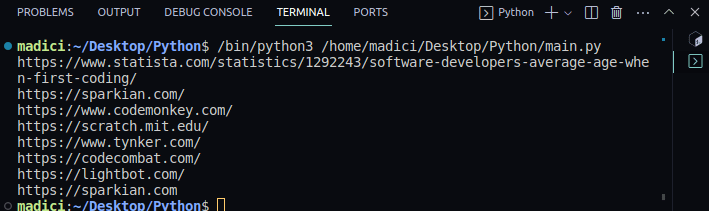
Fra koden ovenfor modtager funktionen extract_link() en PDF-fil, gentager alle siderne i PDF’en, udtrækker alle links og returnerer dem. Resultatet af denne funktion er gemt i en variabel ved navn alle_links
Funktionen print_all_links() tager resultatet af extract_link(), itererer gennem listen og udskriver alle de faktiske links, der er fundet i den PDF, du har sendt til funktionen extract_link().
For at udtrække billeder fra en PDF, vil vi stadig bruge PyMuPDF. Sådan udtrækkes billeder fra en PDF-fil:
1. Importer PyMuPDF, io og PIL. Python Imaging Library (PIL) giver værktøjer, der gør det nemt at oprette og gemme billeder, blandt andre funktioner. io giver klasser til nem og effektiv håndtering af binære data.
import fitz from io import BytesIO from PIL import Image
2. Åbn den PDF-fil, du vil udpakke billeder fra:
doc = fitz.open("games.pdf")
3. Indlæs den side, du vil udtrække billeder fra:
page = doc.load_page(0)
4. PyMuPdf identificerer billeder på en PDF-fil ved hjælp af et krydsreferencenummer(xref), som normalt er et heltal. Hvert billede på en PDF-fil har en unik xref. Derfor, for at udtrække et billede fra en PDF, skal vi først få det xref-nummer, der identificerer det. For at få xref-nummeret for billederne på en side, bruger vi funktionen get_images() sådan:
image_xref = page.get_images() print(image_xref)
Produktion:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
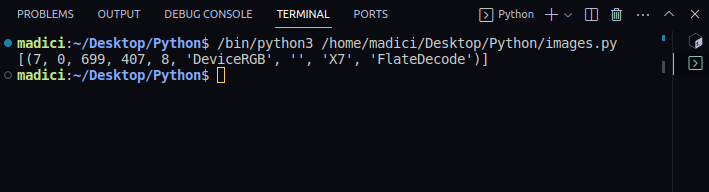
get_images() returnerer en liste over tuples med information om billedet. Da vi kun har ét billede på første side, er der kun én tupel. Det første element i tuplet repræsenterer xref af billedet på siden. Derfor er xref af billedet på den første side 7.
5. For at udtrække xref-værdien for billedet fra listen over tupler, bruger vi koden nedenfor:
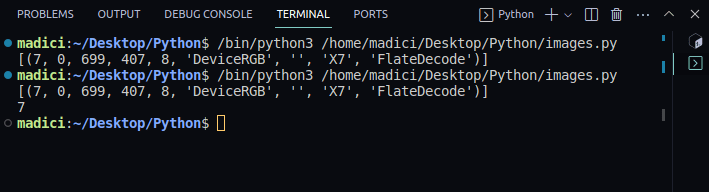
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Produktion:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
6. Da du nu har xref, der identificerer et billede på PDF’en, kan du udtrække billedet ved hjælp af extract_image()-funktionen sådan:
img_dictionary = doc.extract_image(xref_value)
Denne funktion returnerer dog ikke det faktiske billede. I stedet returnerer den en ordbog, der blandt andet indeholder billedets binære billeddata og metadata om billedet.
7. Fra ordbogen returneret af funktionen extract_image() skal du kontrollere filtypenavnet på det udpakkede billede. Filtypenavnet er gemt under nøglen “ext”:
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Produktion:
png
8. Uddrag de binære billedfiler fra ordbogen gemt i img_dictionary. Billedets binære filer er gemt under nøglen “image”
# get the actual image binary data img_binary = img_dictionary["image"]
9. Opret et BytesIO-objekt, og initialiser det med de binære billeddata, der repræsenterer billedet. Dette skaber et fillignende objekt, der kan behandles af Python-biblioteker såsom PIL, så du kan gemme billedet.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Åbn og parse billeddataene, der er gemt i BytesIO-objektet ved navn image_io ved hjælp af PIL-biblioteket. Dette er vigtigt, da det giver PIL-biblioteket mulighed for at bestemme billedformatet for det billede, du forsøger at arbejde med, i dette tilfælde en PNG. Efter at have fundet billedformatet opretter PIL et billedobjekt, der kan manipuleres med PIL-funktioner og -metoder, såsom save()-metoden, for at gemme billedet til lokalt lager.
# open the image using Pillow image = Image.open(image_io)
11. Angiv stien, hvor du vil gemme billedet.
output_path = "image_1.png"
Da stien ovenfor kun indeholder navnet på filen med dens filtypenavn, vil det udpakkede billede blive gemt i samme mappe som Python-filen, der indeholder dette program. Billedet vil blive gemt som image_1.png. PNG-udvidelsen er vigtig for, at den passer til billedets originale udvidelse.
12. Gem billedet og luk ByteIO-objektet.
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Hele koden til at udtrække et billede fra en PDF-fil er vist nedenfor:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
Kør koden og gå til mappen, der indeholder din Python-fil; du skulle se det udpakkede billede med navnet image_1.png, som vist nedenfor:
Konklusion
For at få mere øvelse med at udtrække links, billeder og tekster fra PDF’er, prøv at omfaktorere koden i eksemplerne for at gøre dem mere genbrugelige, som vist i linkeksemplet. På denne måde behøver du kun at sende en PDF-fil ind, og dit Python-program vil udtrække alle links, billeder eller tekst i hele PDF’en. God kodning!
Du kan også udforske nogle af de bedste PDF API’er til ethvert forretningsbehov.