

Det lyder måske skørt, men Linux sed-kommandoen er en teksteditor uden en grænseflade. Du kan bruge det fra kommandolinjen til at manipulere tekst i filer og streams. Vi viser dig, hvordan du udnytter dens kraft.
Indholdsfortegnelse
Kraften af sed
Sed-kommandoen er lidt ligesom skak: det tager en time at lære det grundlæggende og et helt liv at mestre dem (eller i det mindste en masse øvelse). Vi viser dig et udvalg af åbningsspil i hver af hovedkategorierne af sed-funktionalitet.
sed er en stream editor der virker på piped input eller filer med tekst. Det har dog ikke en interaktiv tekstredigeringsgrænseflade. I stedet giver du instruktioner, som den skal følge, mens den arbejder gennem teksten. Alt dette virker i Bash og andre kommandolinjeskaller.
Med sed kan du gøre alt af følgende:
Vælg tekst
Erstatningstekst
Tilføj linjer til tekst
Slet linjer fra tekst
Rediger (eller bevar) en original fil
Vi har struktureret vores eksempler for at introducere og demonstrere koncepter, ikke for at producere de mest relevante (og mindst tilgængelige) sed-kommandoer. Mønstertilpasning og tekstvalgsfunktionaliteter i sed er dog stærkt afhængige af regulære udtryk (regexes). Du får brug for lidt fortrolighed med disse for at få det bedste ud af sed.
Et simpelt eksempel
Først skal vi bruge ekko til at sende noget tekst til sed gennem et rør, og få sed til at erstatte en del af teksten. For at gøre det skriver vi følgende:
echo howtogonk | sed 's/gonk/geek/'
Ekkokommandoen sender “howtogonk” ind i sed, og vores simple substitutionsregel (“s” står for substitution) anvendes. sed søger i inputteksten efter en forekomst af den første streng og erstatter alle matches med den anden.
Strengen “gonk” erstattes af “nørd”, og den nye streng udskrives i terminalvinduet.

Substitutioner er nok den mest almindelige brug af sed. Før vi kan dykke dybere ned i erstatninger, skal vi dog vide, hvordan man vælger og matcher tekst.
Valg af tekst
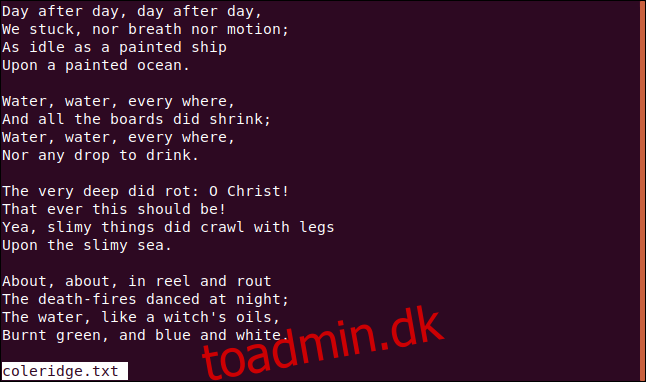
Vi skal bruge en tekstfil til vores eksempler. Vi bruger en, der indeholder et udvalg af vers fra Samuel Taylor Coleridges episke digt “The Rime of the Ancient Mariner.”
Vi skriver følgende for at se på det med mindre:
less coleridge.txt
For at vælge nogle linjer fra filen angiver vi start- og slutlinjerne for det område, vi ønsker at vælge. Et enkelt tal vælger den ene linje.
For at udtrække linje et til fire, skriver vi denne kommando:
sed -n '1,4p' coleridge.txt
Bemærk kommaet mellem 1 og 4. P betyder “udskriv matchede linjer.” Som standard udskriver sed alle linjer. Vi ville se al teksten i filen med de matchende linjer udskrevet to gange. For at forhindre dette, bruger vi muligheden -n (stille) til at undertrykke den umatchede tekst.
Vi ændrer linjenumrene, så vi kan vælge et andet vers, som vist nedenfor:
sed -n '6,9p' coleridge.txt

Vi kan bruge muligheden -e (udtryk) til at foretage flere valg. Med to udtryk kan vi vælge to vers, som sådan:
sed -n -e '1,4p' -e '31,34p' coleridge.txt
Hvis vi reducerer det første tal i det andet udtryk, kan vi indsætte et blanktegn mellem de to vers. Vi skriver følgende:
sed -n -e '1,4p' -e '30,34p' coleridge.txt

Vi kan også vælge en startlinje og bede sed om at gå gennem filen og udskrive alternative linjer, hver femte linje, eller at springe et vilkårligt antal linjer over. Kommandoen ligner dem, vi brugte ovenfor til at vælge et område. Denne gang vil vi dog bruge en tilde (~) i stedet for et komma til at adskille tallene.
Det første tal angiver startlinjen. Det andet tal fortæller sed hvilke linjer efter startlinjen vi vil se. Tallet 2 betyder hver anden linje, 3 betyder hver tredje linje og så videre.
Vi skriver følgende:
sed -n '1~2p' coleridge.txt

Du vil ikke altid vide, hvor den tekst, du leder efter, er placeret i filen, hvilket betyder, at linjenumre ikke altid vil være megen hjælp. Du kan dog også bruge sed til at vælge linjer, der indeholder matchende tekstmønstre. Lad os f.eks. udtrække alle linjer, der starter med “Og”.
Karetten (^) repræsenterer begyndelsen af linjen. Vi omslutter vores søgeterm i skråstreger (/). Vi inkluderer også et mellemrum efter “Og”, så ord som “Android” vil ikke blive inkluderet i resultatet.
At læse sed-scripts kan være lidt svært i starten. /p betyder “print”, ligesom det gjorde i de kommandoer, vi brugte ovenfor. I den følgende kommando går der dog en skråstreg foran den:
sed -n '/^And /p' coleridge.txt
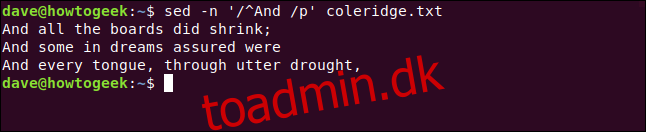
Tre linjer, der starter med “Og “, udtrækkes fra filen og vises for os.
At lave udskiftninger
I vores første eksempel viste vi dig følgende grundlæggende format for en sed-substitution:
echo howtogonk | sed 's/gonk/geek/'
S’et fortæller sed, at dette er en erstatning. Den første streng er søgemønsteret, og den anden er den tekst, som vi vil erstatte den matchede tekst med. Selvfølgelig, som med alt andet Linux, er djævelen i detaljerne.
Vi skriver følgende for at ændre alle forekomster af “dag” til “uge”, og give søfareren og albatrossen mere tid til at binde sig:
sed -n 's/day/week/p' coleridge.txt
I den første linje ændres kun den anden forekomst af “dag”. Dette skyldes, at sed stopper efter den første kamp pr. linje. Vi skal tilføje et “g” i slutningen af udtrykket, som vist nedenfor, for at udføre en global søgning, så alle matches i hver linje behandles:
sed -n 's/day/week/gp' coleridge.txt
Dette matcher tre ud af de fire i første linje. Fordi det første ord er “Dag”, og sed skelner mellem store og små bogstaver, betragter det ikke den instans som værende det samme som “dag”.
Vi skriver følgende og tilføjer et i til kommandoen i slutningen af udtrykket for at indikere ufølsomhed for store og små bogstaver:
sed -n 's/day/week/gip' coleridge.txt
Dette virker, men du vil måske ikke altid slå ufølsomhed over for store og små bogstaver til for alt. I disse tilfælde kan du bruge en regex-gruppe til at tilføje mønsterspecifik case-insensitivitet.
Hvis vi f.eks. indsætter tegn i firkantede parenteser ([]), tolkes de som “enhver karakter fra denne liste over karakterer.”
Vi skriver følgende og inkluderer “D” og “d” i gruppen for at sikre, at det matcher både “Dag” og “dag”:
sed -n 's/[Dd]ay/week/gp' coleridge.txt

Vi kan også begrænse erstatninger til dele af filen. Lad os sige, at vores fil indeholder mærkelige mellemrum i første vers. Vi kan bruge følgende velkendte kommando til at se det første vers:
sed -n '1,4p' coleridge.txt
Vi søger efter to mellemrum og erstatter dem med én. Vi vil gøre dette globalt, så handlingen gentages på tværs af hele linjen. For at være klar, er søgemønsteret mellemrum, mellemrumsstjerne
, og substitutionsstrengen er et enkelt mellemrum. 1,4 begrænser substitutionen til de første fire linjer i filen.
sed -n '1,4 s/ */ /gp' coleridge.txt
Vi sætter alt det sammen i følgende kommando:
Dette fungerer fint! Søgemønsteret er det, der er vigtigt her. Stjernen
repræsenterer nul eller mere af det foregående tegn, som er et mellemrum. Således leder søgemønsteret efter strenge på et mellemrum eller flere.
sed -n '1,4 s/ */ /gp' coleridge.txt

Hvis vi erstatter et enkelt mellemrum med en sekvens af flere mellemrum, returnerer vi filen til almindelig mellemrum med et enkelt mellemrum mellem hvert ord. Dette vil også erstatte en enkelt plads med en enkelt plads i nogle tilfælde, men dette vil ikke påvirke noget negativt – vi får stadig vores ønskede resultat.
Hvis vi skriver følgende og reducerer søgemønsteret til et enkelt mellemrum, vil du straks se, hvorfor vi skal inkludere to mellemrum:
Fordi stjernen matcher nul eller mere af det foregående tegn, ser den hvert tegn, der ikke er et mellemrum, som et “nul mellemrum” og anvender erstatningen på det.
sed -n -e 's/motion/flutter/gip' -e 's/ocean/gutter/gip' coleridge.txt
Men hvis vi inkluderer to mellemrum i søgemønsteret, skal sed finde mindst ét mellemrumstegn, før den anvender substitutionen. Dette sikrer, at tegn uden mellemrum forbliver uberørte.
sed -n 's/motion/flutter/gip;s/ocean/gutter/gip' coleridge.txt

Vi skriver følgende ved at bruge det -e (udtryk), vi brugte tidligere, som giver os mulighed for at lave to eller flere substitutioner samtidigt:
sed -n 's/[Dd]ay/week/gp' coleridge.txt
Vi kan opnå det samme resultat, hvis vi bruger et semikolon (;) til at adskille de to udtryk, som sådan:
Da vi byttede “dag” til “uge” i den følgende kommando, blev forekomsten af ”dag” i udtrykket “godt om dagen” også byttet:
sed -n '/after/ s/[Dd]ay/week/gp' coleridge.txt
For at forhindre dette kan vi kun forsøge udskiftninger på linjer, der matcher et andet mønster. Hvis vi ændrer kommandoen til at have et søgemønster i starten, vil vi kun overveje at operere på linjer, der matcher det mønster.

Vi skriver følgende for at gøre vores matchende mønster til ordet “efter”:
Det giver os det svar, vi ønsker.
Mere komplekse udskiftninger
Lad os give Coleridge en pause og bruge sed til at udtrække navne fra etc/passwd-filen. [()] Der er kortere måder at gøre dette på (mere om det senere), men vi vil bruge den længere måde her til at demonstrere et andet koncept. Hvert matchende element i et søgemønster (kaldet underudtryk) kan nummereres (op til et maksimum på ni elementer). Du kan derefter bruge disse tal i dine sed-kommandoer til at referere til specifikke underudtryk.
Du skal sætte underudtrykket i parentes
sed 's/([^:]*).*/1/' /etc/passwd

for at dette virker. Parenteserne skal også indledes med en baglæns skråstreg () for at forhindre dem i at blive behandlet som et normalt tegn.
For at gøre dette skal du skrive følgende:
Lad os opdele dette: [(] sed ‘s/: sed-kommandoen og begyndelsen af substitutionsudtrykket.
[^:](: Åbningsparentesen
omslutter underudtrykket, efter en omvendt skråstreg (). [)] *: Det første underudtryk af søgeordet indeholder en gruppe i firkantede parenteser. Caretten (^) betyder “ikke”, når det bruges i en gruppe. En gruppe betyder, at ethvert tegn, der ikke er et kolon (:), vil blive accepteret som et match.
): Den afsluttende parentes
med en forudgående skråstreg ().
.*: Dette andet søgeunderudtryk betyder “et hvilket som helst tegn og et hvilket som helst antal af dem.”
/1: Substitutionsdelen af udtrykket indeholder 1 efter en omvendt skråstreg (). Dette repræsenterer den tekst, der matcher det første underudtryk.
/’: Den afsluttende fremadgående skråstreg (/) og det enkelte citat (‘) afslutter sed-kommandoen.

Alt dette betyder, at vi skal lede efter en streng af tegn, der ikke indeholder et kolon (:), som vil være den første forekomst af matchende tekst. Derefter søger vi efter noget andet på den linje, som vil være den anden forekomst af matchende tekst. Vi vil erstatte hele linjen med den tekst, der matchede det første underudtryk. [()] Hver linje i filen /etc/passwd starter med et kolon-termineret brugernavn. Vi matcher alt op til det første kolon, og erstatter derefter denne værdi for hele linjen. Så vi har isoleret brugernavnene.
Dernæst vil vi omslutte det andet underudtryk i parentes
sed 's/([^:]*)(.*)/2/' /etc/passwd

så vi kan også referere det efter nummer. Vi erstatter også 1 med 2. Vores kommando vil nu erstatte hele linjen med alt fra det første kolon (:) til slutningen af linjen.

Vi skriver følgende:
Disse små ændringer inverterer betydningen af kommandoen, og vi får alt undtagen brugernavnene.
Lad os nu tage et kig på den hurtige og nemme måde at gøre dette på.
sed 's/:.*//" /etc/passwd

Vores søgeord er fra det første kolon (:) til slutningen af linjen. Fordi vores substitutionsudtryk er tomt (//), erstatter vi ikke den matchede tekst med noget.
Så vi skriver følgende og skærer alt fra det første kolon (:) til slutningen af linjen, og efterlader kun brugernavnene:
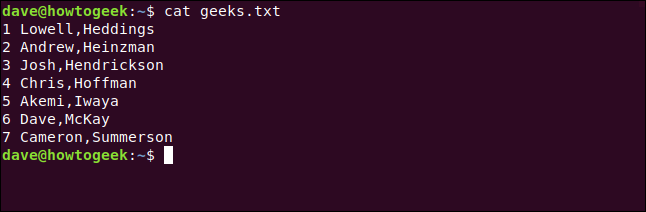
cat geeks.txt
Lad os se på et eksempel, hvor vi refererer til det første og det andet match i den samme kommando.
sed 's/^(.*),(.*)$/2,1 /g' geeks.txt

Vi har en fil med kommaer (,), der adskiller for- og efternavne. Vi ønsker at angive dem som “efternavn, fornavn.” Vi kan bruge kat, som vist nedenfor, til at se, hvad der er i filen:
Ligesom mange sed-kommandoer kan denne næste måske se uigennemtrængelig ud i starten:
Dette er en erstatningskommando ligesom de andre, vi har brugt, og søgemønsteret er ret nemt. Vi opdeler det nedenfor:[]sed ‘s/: Den normale substitutionskommando.
^: Fordi caret ikke er i en gruppe ( [()]), betyder det “Starten af linjen.”
(.*),: Det første underudtryk er et vilkårligt antal tegn. Det er omgivet af parentes [()], som hver er indledt af en omvendt skråstreg (), så vi kan henvise til det efter nummer. Hele vores søgemønster er indtil videre oversat som søgning fra begyndelsen af linjen op til det første komma (,) for et vilkårligt antal tegn.
(.*): Det næste underudtryk er (igen) et vilkårligt tal af et hvilket som helst tegn. Den står også i parentes
, som begge er indledt af en omvendt skråstreg (), så vi kan henvise til den matchende tekst efter nummer.
$/: Dollartegnet ($) repræsenterer slutningen af linjen og vil tillade vores søgning at fortsætte til slutningen af linjen. Vi har brugt dette blot til at introducere dollartegnet. Vi har ikke rigtig brug for det her, som stjernen
ville gå til slutningen af linjen i dette scenarie. Den fremadrettede skråstreg (/) fuldender søgemønsterafsnittet.
2,1 /g’: Fordi vi omsluttede vores to underudtryk i parentes, kan vi henvise til dem begge ved deres tal. Fordi vi ønsker at vende rækkefølgen, skriver vi dem som andet match, første match. Tallene skal indledes med en omvendt skråstreg ().
sed '/neck/c Around my wrist was strung' coleridge.txt

/g: Dette gør det muligt for vores kommando at arbejde globalt på hver linje.

geeks.txt: Filen vi arbejder på.
Du kan også bruge kommandoen Klip (c) til at erstatte hele linjer, der matcher dit søgemønster. Vi skriver følgende for at søge efter en linje med ordet “hals” i den og erstatter den med en ny tekststreng:
Vores nye linje vises nu nederst i vores uddrag.
Indsættelse af linjer og tekst
Her er filen, vi skal arbejde med:
cat geeks.txt
sed '/He/a --> Inserted!' geeks.txt
 Det
Det
Vi har nummereret linjerne for at gøre dette lidt nemmere at følge.
sed '/He/i --> Inserted!' geeks.txt
 Vi skriver følgende for at søge efter linjer, der indeholder ordet “Han”, og indsætter en ny linje under dem:
Vi skriver følgende for at søge efter linjer, der indeholder ordet “Han”, og indsætter en ny linje under dem:
Indsat!’ geeks.txt” kommandoen i et terminalvindue.” width=”646″ højde=”262″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Vi skriver følgende og inkluderer kommandoen Indsæt (i) for at indsætte den nye linje over dem, der indeholder matchende tekst:
Indsat!’ geeks.txt” kommandoen i et terminalvindue.” width=”646″ højde=”262″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
sed 's/.*/--> Inserted &/' geeks.txt
 Vi kan bruge og-tegnet (&), som repræsenterer den originale matchede tekst, til at tilføje ny tekst til en matchende linje. 1, 2 og så videre repræsenterer matchende underudtryk.
Vi kan bruge og-tegnet (&), som repræsenterer den originale matchede tekst, til at tilføje ny tekst til en matchende linje. 1, 2 og så videre repræsenterer matchende underudtryk.
For at tilføje tekst til starten af en linje, bruger vi en erstatningskommando, der matcher alt på linjen, kombineret med en erstatningsklausul, der kombinerer vores nye tekst med den originale linje.
sed 'G' geeks.txt

For at gøre alt dette, skriver vi følgende:
Indsat &/’ geeks.txt” kommando i et terminalvindue.” width=”646″ height=”212″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Vi skriver følgende, inklusive G-kommandoen, som tilføjer en tom linje mellem hver linje:
Hvis du vil tilføje to eller flere tomme linjer, kan du bruge G;G, G;G;G og så videre.
sed '3d' geeks.txt
Sletning af linjer
sed '4,5d' geeks.txt
Kommandoen Slet (d) sletter linjer, der matcher et søgemønster, eller dem, der er angivet med linjenumre eller intervaller.
sed '6,7!d' geeks.txt

For at slette den tredje linje, skriver vi f.eks. følgende:
For at slette rækken af linjer fire til fem, skriver vi følgende:
For at slette linjer uden for et område, bruger vi et udråbstegn (!), som vist nedenfor:
Gem dine ændringer
Indtil videre er alle vores resultater udskrevet til terminalvinduet, men vi har endnu ikke gemt dem nogen steder. For at gøre disse permanente kan du enten skrive dine ændringer til den originale fil eller omdirigere dem til en ny.
Overskrivning af din originale fil kræver en vis forsigtighed. Hvis din sed-kommando er forkert, kan du muligvis lave nogle ændringer i den originale fil, som er svære at fortryde.
For en vis ro i sindet kan sed oprette en sikkerhedskopi af den originale fil, før den udfører sin kommando.
sed -i'.bak' '/^.*He.*$/d' geeks.txt
Du kan bruge In-place-indstillingen (-i) til at bede sed om at skrive ændringerne til den originale fil, men hvis du tilføjer en filtypenavn til den, vil sed sikkerhedskopiere den originale fil til en ny. Den vil have samme navn som den originale fil, men med en ny filtypenavn.
cat geeks.txt.bak

For at demonstrere søger vi efter alle linjer, der indeholder ordet “Han” og sletter dem. Vi sikkerhedskopierer også vores originale fil til en ny ved hjælp af BAK-udvidelsen.
sed -i'.bak' '/^.*He.*$/d' geeks.txt > new_geeks.txt
For at gøre alt dette, skriver vi følgende:
cat new_geeks.txt
 Vi skriver følgende for at sikre, at vores backup-fil er uændret:
Vi skriver følgende for at sikre, at vores backup-fil er uændret:
Vi kan også skrive følgende for at omdirigere outputtet til en ny fil og opnå et lignende resultat:
Vi bruger cat til at bekræfte, at ændringerne blev skrevet til den nye fil, som vist nedenfor: new_geeks.txt” og “cat new_geeks.txt” kommandoer i et terminalvindue.” width=”646″ height=”307″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>Efter at have set alt det
Som du sikkert har bemærket, er selv denne hurtige primer på sed ret lang. Der er meget til denne kommando, og der er endda
mere du kan gøre med det
.
Forhåbentlig har disse grundlæggende koncepter dog givet et solidt grundlag, som du kan bygge på, mens du fortsætter med at lære mere.