Linux curl-kommandoen kan meget mere end at downloade filer. Find ud af, hvad curl er i stand til, og hvornår du skal bruge det i stedet for wget.
Indholdsfortegnelse
curl vs. wget: Hvad er forskellen?
Folk har ofte svært ved at identificere de relative styrker ved wget- og curl-kommandoerne. Kommandoerne har en vis funktionel overlapning. De kan hver især hente filer fra fjerntliggende steder, men det er her ligheden slutter.
wget er en fantastisk værktøj til at downloade indhold og filer. Det kan downloade filer, websider og mapper. Den indeholder intelligente rutiner til at krydse links på websider og rekursivt downloade indhold på tværs af et helt websted. Det er uovertruffen som en kommandolinje download manager.
krølle tilfredsstiller et helt andet behov. Ja, den kan hente filer, men den kan ikke rekursivt navigere på et websted, der leder efter indhold, der skal hentes. Hvad curl faktisk gør, er at lade dig interagere med fjernsystemer ved at stille anmodninger til disse systemer og hente og vise deres svar til dig. Disse svar kan meget vel være websideindhold og filer, men de kan også indeholde data leveret via en webservice eller API som et resultat af “spørgsmålet” stillet af curl-anmodningen.
Og curl er ikke begrænset til websteder. curl understøtter over 20 protokoller, inklusive HTTP, HTTPS, SCP, SFTP og FTP. Og på grund af dens overlegne håndtering af Linux-pipes kan curl nok nemmere integreres med andre kommandoer og scripts.
Forfatteren af curl har en webside, der beskriver de forskelle, han ser mellem curl og wget.
Installation af krølle
Ud af de computere, der blev brugt til at undersøge denne artikel, havde Fedora 31 og Manjaro 18.1.0 allerede curl installeret. curl skulle installeres på Ubuntu 18.04 LTS. På Ubuntu skal du køre denne kommando for at installere den:
sudo apt-get install curl

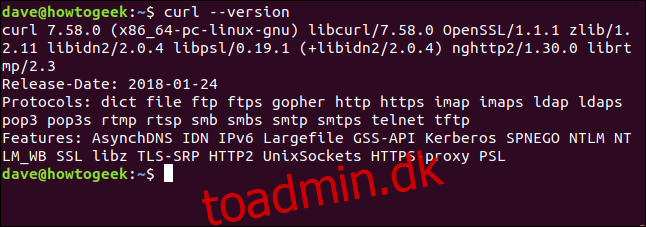
Curl-versionen
Indstillingen –version gør curlreport til sin version. Den viser også alle de protokoller, den understøtter.
curl --version
Hentning af en webside
Hvis vi peger curl på en webside, vil den hente den for os.
curl https://www.bbc.com

Men dens standardhandling er at dumpe den til terminalvinduet som kildekode.
Pas på: Hvis du ikke fortæller curl, at du vil have noget gemt som en fil, vil den altid dumpe det til terminalvinduet. Hvis filen, den henter, er en binær fil, kan resultatet være uforudsigeligt. Skallen kan forsøge at fortolke nogle af byteværdierne i den binære fil som kontroltegn eller escape-sekvenser.
Lagring af data til en fil
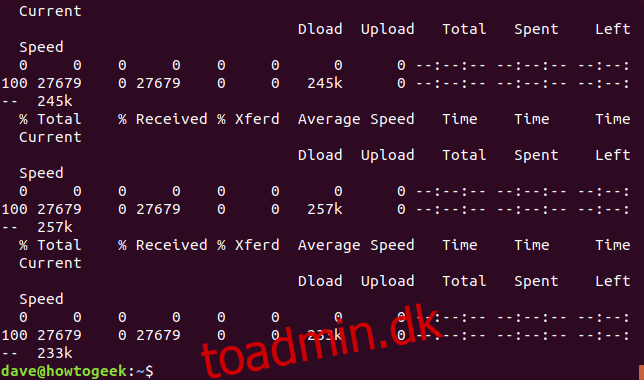
Lad os fortælle curl at omdirigere outputtet til en fil:
curl https://www.bbc.com > bbc.html

Oplysningerne er:
% Total: Det samlede beløb, der skal hentes.
% Modtaget: Procentdelen og de faktiske værdier af de data, der er hentet indtil videre.
% Xferd: Procenten og faktisk sendt, hvis data bliver uploadet.
Gennemsnitlig downloadhastighed: Den gennemsnitlige downloadhastighed.
Gennemsnitlig uploadhastighed: Den gennemsnitlige uploadhastighed.
Time Total: Den anslåede samlede varighed af overførslen.
Tid brugt: Den hidtil forløbne tid for denne overførsel.
Tid tilbage: Den anslåede tid, der er tilbage, før overførslen er fuldført
Aktuel hastighed: Den aktuelle overførselshastighed for denne overførsel.
Fordi vi omdirigerede outputtet fra curl til en fil, har vi nu en fil kaldet “bbc.html.”

Dobbeltklik på den fil vil åbne din standardbrowser, så den viser den hentede webside.
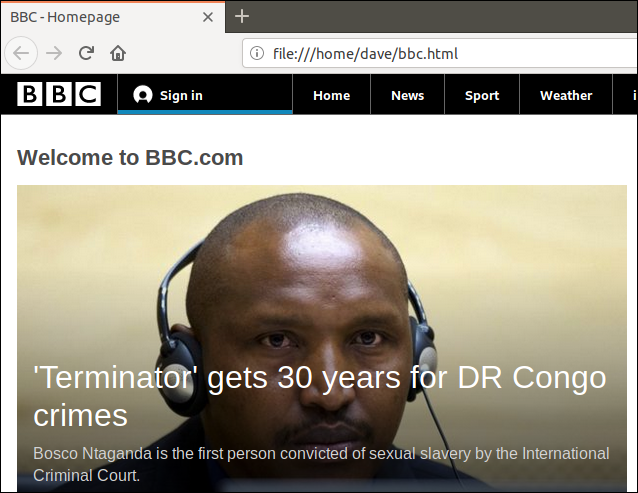
Bemærk, at adressen i browserens adresselinje er en lokal fil på denne computer, ikke et eksternt websted.
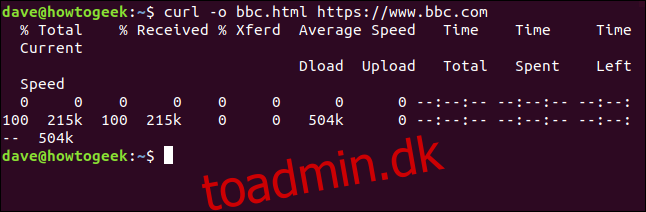
Vi behøver ikke at omdirigere outputtet for at oprette en fil. Vi kan oprette en fil ved at bruge -o (output) muligheden og bede curl om at oprette filen. Her bruger vi muligheden -o og angiver navnet på den fil, vi ønsker at oprette “bbc.html.”
curl -o bbc.html https://www.bbc.com
Brug af en statuslinje til at overvåge downloads
For at få den tekstbaserede downloadinformation erstattet af en simpel statuslinje, skal du bruge -# (fremskridtslinje).
curl -x -o bbc.html https://www.bbc.com

Genstart af en afbrudt download
Det er nemt at genstarte en download, der er blevet afsluttet eller afbrudt. Lad os starte en download af en stor fil. Vi bruger den seneste Long Term Support build af Ubuntu 18.04. Vi bruger –output-indstillingen til at angive navnet på den fil, vi ønsker at gemme den i: “ubuntu180403.iso.”
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Downloaden starter og arbejder sig hen imod fuldførelse.
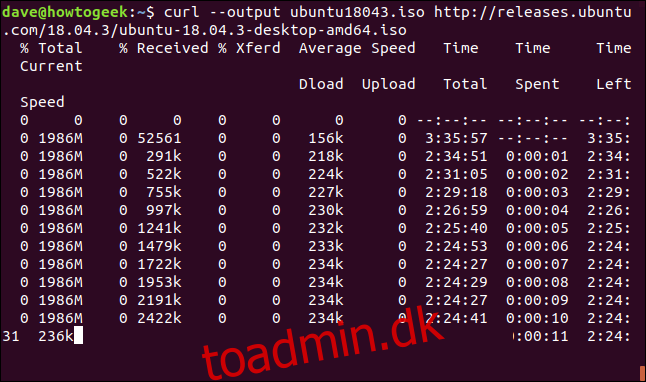
Hvis vi tvangsafbryder overførslen med Ctrl+C , vender vi tilbage til kommandoprompten, og overførslen afbrydes.
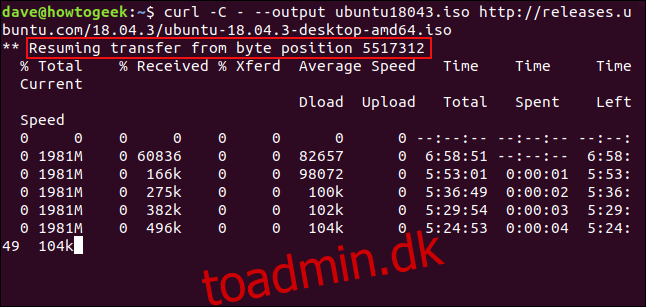
For at genstarte download skal du bruge -C (fortsæt ved). Dette får curl til at genstarte overførslen på et bestemt tidspunkt eller forskydning i målfilen. Hvis du bruger en bindestreg – som forskydning, vil curl se på den allerede downloadede del af filen og bestemme den korrekte forskydning, der skal bruges til sig selv.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Downloaden genstartes. curl rapporterer den offset, hvor den genstartes.
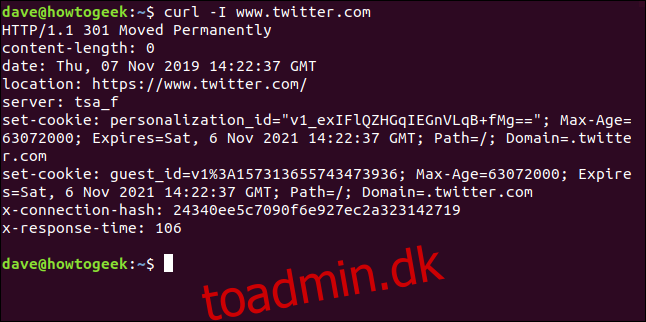
Henter HTTP-headere
Med muligheden -I (hoved) kan du kun hente HTTP-headerne. Dette er det samme som at sende HTTP HEAD kommando til en webserver.
curl -I www.twitter.com

Denne kommando henter kun information; den downloader ingen websider eller filer.
Download af flere URL’er
Ved hjælp af xargs kan vi downloade flere URL’er på en gang. Måske vil vi downloade en række websider, der udgør en enkelt artikel eller vejledning.
Kopier disse URL’er til en editor, og gem den i en fil kaldet “urls-to-download.txt.” Vi kan bruge xargs til behandle indholdet af hver linje af tekstfilen som en parameter, som den igen vil føre til at krølle.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Dette er kommandoen, vi skal bruge for at få xargs til at videregive disse URL’er til at krølle én ad gangen:
xargs -n 1 curl -ONote that this command uses the -O (remote file) output command, which uses an uppercase “O.” This option causes curl to save the retrieved file with the same name that the file has on the remote server.
The -n 1 option tells xargs to treat each line of the text file as a single parameter.
When you run the command, you’ll see multiple downloads start and finish, one after the other.
Checking in the file browser shows the multiple files have been downloaded. Each one bears the name it had on the remote server.
Downloading Files From an FTP Server
Using curl with a File Transfer Protocol (FTP) server is easy, even if you have to authenticate with a username and password. To pass a username and password with curl use the -u (user) option, and type the username, a colon “:”, and the password. Don’t put a space before or after the colon.
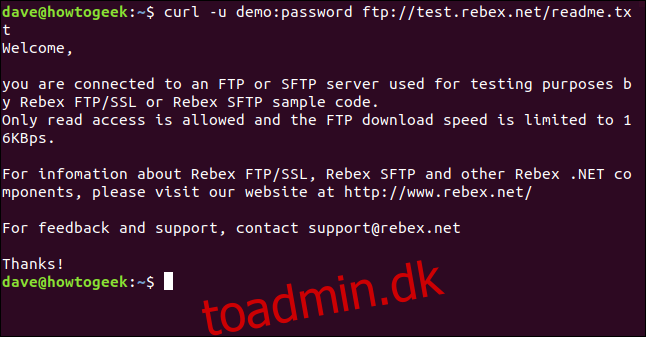
This is a free-for-testing FTP server hosted by Rebex. The test FTP site has a pre-set username of “demo”, and the password is “password.” Don’t use this type of weak username and password on a production or “real” FTP server.
curl -u demo:password ftp://test.rebex.net
curl finder ud af, at vi peger den mod en FTP-server, og returnerer en liste over de filer, der er til stede på serveren.
Den eneste fil på denne server er en "readme.txt"-fil med en længde på 403 bytes. Lad os hente det. Brug den samme kommando som for et øjeblik siden, med filnavnet tilføjet:
curl -u demo:password ftp://test.rebex.net/readme.txt
Filen hentes og curl viser dens indhold i terminalvinduet.
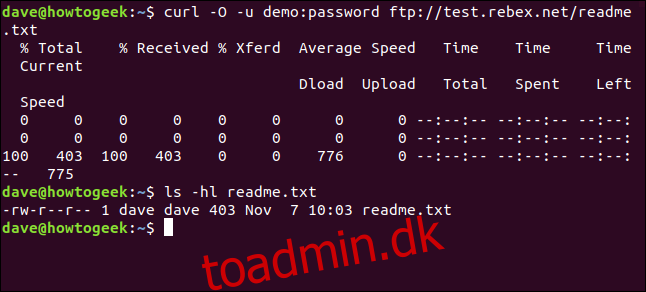
I næsten alle tilfælde vil det være mere bekvemt at have den hentede fil gemt på disken for os i stedet for at blive vist i terminalvinduet. Endnu en gang kan vi bruge outputkommandoen -O (fjernfil) til at få filen gemt på disken med det samme filnavn, som den har på fjernserveren.
curl -O -u demo:password ftp://test.rebex.net/readme.txt
Filen hentes og gemmes på disken. Vi kan bruge ls til at kontrollere fildetaljerne. Den har samme navn som filen på FTP-serveren, og den har samme længde, 403 bytes.
ls -hl readme.txt
Afsendelse af parametre til fjernservere
Nogle fjernservere vil acceptere parametre i anmodninger, der sendes til dem. Parametrene kan f.eks. bruges til at formatere de returnerede data, eller de kan bruges til at vælge de nøjagtige data, som brugeren ønsker at hente. Det er ofte muligt at interagere med web applikationsprogrammeringsgrænseflader (API'er) ved hjælp af curl.
Som et simpelt eksempel ipify webstedet har en API kan forespørges for at fastslå din eksterne IP-adresse.
curl https://api.ipify.orgVed at tilføje formatparameteren til kommandoen med værdien "json" kan vi igen anmode om vores eksterne IP-adresse, men denne gang vil de returnerede data blive kodet i JSON-format.
curl https://api.ipify.org?format=json
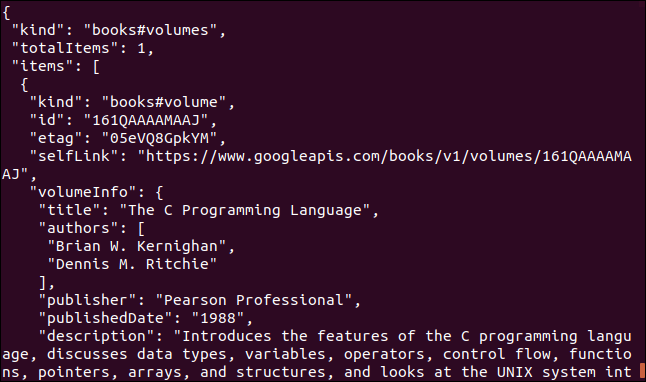
Her er et andet eksempel, der gør brug af en Google API. Det returnerer et JSON-objekt, der beskriver en bog. Den parameter du skal angive er Internationalt standardbognummer (ISBN) nummer på en bog. Du kan finde disse på bagsiden af de fleste bøger, normalt under en stregkode. Parameteren, vi vil bruge her, er "0131103628."
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628
De returnerede data er omfattende:
Nogle gange krøller, nogle gange wget
Hvis jeg ville downloade indhold fra en hjemmeside og få træstrukturen på hjemmesiden til at søge rekursivt efter det indhold, ville jeg bruge wget.
Hvis jeg ville interagere med en ekstern server eller API og muligvis downloade nogle filer eller websider, ville jeg bruge curl. Især hvis protokollen var en af de mange, der ikke blev understøttet af wget.