
Multidimensionelt skema er designet til at bygge en datavarehussystemmodel.
Hovedformålet med disse skemaer er at imødekomme behovene i større databaser bygget til analytiske formål (OLAP).
Denne metode bruges til at bestille data i databasen med en god opstilling af indholdet i en database. Skemaet giver kunderne mulighed for at stille spørgsmål i forbindelse med forretnings- eller markedstendenser.
Ydermere repræsenterer et multidimensionelt skema dataene i form af datakuber, som gør det muligt at se og modellere data fra forskellige perspektiver og dimensioner.
Det er af tre typer, men mange forveksler mellem stjerne og snefnug. Derfor bliver det svært for dem at vælge den foretrukne model.
Hvis du er en af dem, lad os diskutere forskellene mellem stjerne- og snefnugskemaet, begyndende med definitionen og forstå deres fordele, udfordringer, diagram og karakteristika.
Indholdsfortegnelse
Hvad er et multidimensionelt skema?
Skema refererer til den logiske beskrivelse af en komplet database og data marts. Det inkluderer navnet på poster og deres beskrivelser, herunder aggregater og tilknyttede dataelementer.
En database bruger generelt en relationel model til at beskrive, hvorimod et datavarehussystem bruger en skemamodel.
Multidimensionelt skema kan defineres med Data Mining Query Language (DMQL).
For at definere data marts og datavarehuse bruger den to primitiver – dimensionsdefinition og kubedefinition.
Det multidimensionelle skema bruger forskellige typer skemamodeller. De er:
- Stjerneskema
- Snefnug skema
- Galaxy skema
Lad os diskutere, hvad stjerne- og snefnugskemaer er.
Stjerne vs. Snowflake: Hvad er de?
Hvad er stjerneskema?
Et stjerneskema er en arkitektonisk data warehousing og business intelligence model, der kræver en enkelt faktatabel til at gemme målte og transaktionelle data. Det bruger også forskellige mindre dimensionelle tabeller til at indeholde attributter om forretningsdata.
Det er navngivet i henhold til dens struktur. Som en stjerne indtager faktatabellen sin plads i midten af diagrammet, og små dimensionstabeller sidder som grene til midterbordet for at danne en stjernelignende struktur.
Hvert stjerneskema består af en enkelt faktatabel men flere små dimensionelle tabeller. Faktatabellerne inkluderer specifikke, målbare data, der skal analyseres, såsom logget ydeevne, økonomiske data eller salgsregistreringer. Det kan være et snap af historiske data ad gangen eller transaktionsmæssige.
Desuden er Star-skemaet det enkleste og mest grundlæggende blandt datavarehusene og datamart-skemaerne. Det er effektivt til at håndtere grundlæggende forespørgsler. Stjerneskema understøtter generelt business intelligence, ad hoc-forespørgsler, analytisk applikation og online analytisk behandlingskuber.
Stjerneskema understøtter også antal, gennemsnit, sum og andre sammenlægninger af mange poster. Brugere kan nemt filtrere og gruppere sammenlægningerne efter dimensioner. For eksempel genererer brugere forespørgsler som “find alle salgsoptegnelser i juni” eller “analyserer den samlede omsætning fra XYZ-kontoret i 2022”.
Hvad er Snowflake Schema?
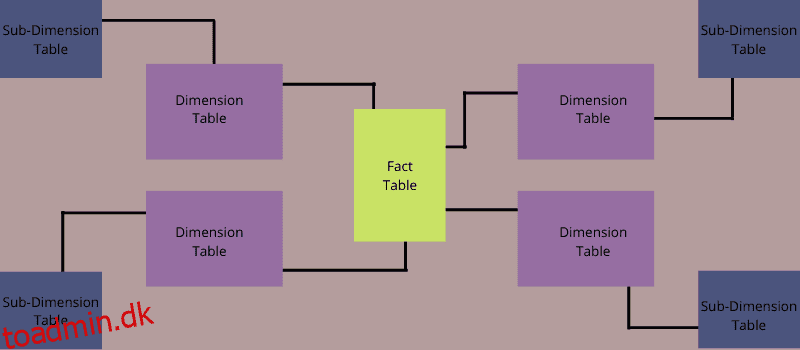
Et snefnugskema er en multidimensionel datamodel, som også kan kendes som udvidelsen af stjerneskemaet. Dette skyldes, at dimensionstabeller i snefnugskemaet opdeles i underdimensioner.
Et skema er et snefnug, hvis en og flere dimensionstabeller ikke linker direkte til faktatabellen, men snarere forbindes gennem andre dimensionstabeller.
Snefnug er et fænomen, der normaliserer dimensionstabellerne i et stjerneskema. Når du normaliserer alle dimensionstabellerne, ligner den resulterende struktur et snefnug, der indeholder en faktatabel i midten af strukturen.
Snefnugskemaet består med enkle ord af én faktatabel i midten af modellen, som er forbundet med dimensionstabeller, som igen er knyttet til andre dimensionstabeller. Dette skema bruges til at forbedre ydelsen af forespørgslerne.
Modellen er skabt til hurtig, fleksibel forespørgsel på tværs af komplekse relationer og dimensioner. Det er nyttigt for en til mange og mange til mange forhold mellem forskellige dimensionsniveauer.
På grund af den strammere overholdelse af mere normaliseringsstandarder, vil du få mere opbevaringseffektivitet. Men dataredundansen er ubetydelig, og ydeevnen er lav sammenlignet med denormaliserede datamodeller som stjerneskema.
Stjerne vs. Snefnug: Hvordan virker de?
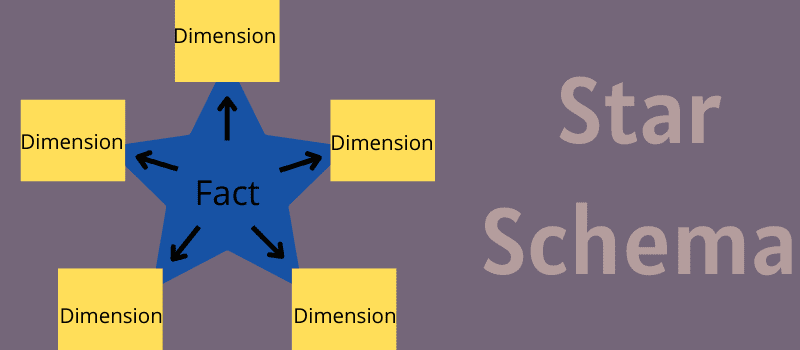
Hvordan fungerer et stjerneskema?
Faktatabellen i midten af stjernemodellen gemmer to typer information – numeriske og dimensionsattributværdier. Lad os forstå dem med et eksempel på en salgsdatabase.
- Numeriske værdier er unikke for hver række og datapunkt. Dette korrelerer ikke med eller relaterer til de data, der er gemt i en anden række. Disse er fakta om en given transaktion, såsom samlet beløb, ordremængde, nøjagtigt tidspunkt, nettooverskud, ordre-id osv.
- Dimensionsattributværdier gemmer ikke nogen data direkte, men de gemmer fremmednøgleværdier for rækken i en dimensionstabel. Forskellige rækker i den midterste tabel vil referere til disse oplysninger, såsom dataværdi, salgsmedarbejder-id, filialkontor-id, produkt-id osv.
Dimensionstabeller gemmer altid understøttende information fra faktatabellen. Hver dimensionel tabel relaterer til kolonnen i en faktatabel sammen med en dimensionel værdi og gemmer yderligere data om denne værdi.
Eksempel: Medarbejderdimensionstabellen bruger medarbejder-id som nøgleværdi og indeholder også oplysninger, såsom navn, køn, adresse og telefonnummer. På samme måde gemmer en produktdimensionstabel information, herunder produktnavn, farve, første dato til markedet, fremstillingsomkostninger osv.
Hvordan fungerer et snefnugskema?
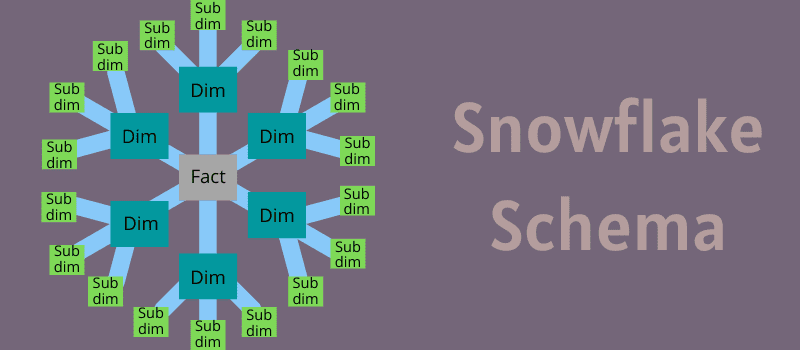
Tænk på et snefnugdesign med en centerboks og forskellige forbindelser gennem den boks til forskellige prikker. For at vedligeholde data marts og datavarehuse kommer snefnugskemadesign ind i billedet.
Det ligner stjerneskemaet, men med minutændringer. I modsætning til stjerneskema udvider snefnugskema sine underdimensionstabeller, som er knyttet til dimensionstabeller.
Det primære formål med denne model er at normalisere den denormaliserede information af stjernemodellen. På denne måde kan den løse almindelige problemer forbundet med et stjerneskema.
I kernen af skemaet finder du en faktatabel, der forbinder med informationen i dimensionstabeller. Disse tabeller stråler igen udad til underdimensionstabeller, der har detaljeret information, der beskriver dimensionstabelinformationen.
Eksempel: Snefnugskemaet indeholder en salgsfaktatabel og tabeller for butiksplacering, linje, familie, produkt og tidsdimension. Markedsdimensionerne består af to dimensionstabeller med butikken som primær dimensionstabel og butikkens placering som underdimensionstabel. Produktdimensionen har tre underdimensionstabeller, der nævner en produkt-, linje- og familieunderdimensionstabel.
Stjerne vs. Snefnug: Karakteristika
Karakteristika for stjerneskema
- Stjerneskema kan filtrere data fra normaliserede data for at imødekomme datavarehusbehov. Den unikke nøgle genereres ud fra den tilknyttede information for hver faktatabel for at identificere hver række.
- Det giver hurtige beregninger og sammenlægninger, såsom indtægter fra opnået indkomst og samlede solgte varer i slutningen af hver måned. Disse detaljer kan filtreres efter behovene ved at indramme passende forespørgsler.
- Det er måling af hændelser, der inkluderer endelige talværdier bestående af fremmednøglen. Disse nøgler er relateret til dimensionstabellerne. Der findes forskellige typer faktatabeller, der er indrammet med værdier på atomniveau.
- Transaktionsfaktatabellen indeholder data om specifikke begivenheder, såsom salg og helligdage.
- Registreringsfakta omfatter givne perioder som kontooplysninger ved årets udgang eller hvert kvartal.
- Den dimensionelle tabel giver detaljerede data om attributter eller poster fundet i den midterste tabel.
- Brugeren er i stand til selv at designe et bord efter behov.
- Du kan bruge stjerneskema til at akkumulere snapshottabeller.
Karakteristika for Snowflake Schema
- Snefnugskemaet har brug for lille diskplads.
- Denne model er nem at implementere på grund af dens separate og hoveddimensionstabeller.
- Dimensionstabellerne indeholder mindst to attributter til at definere information ved flere korn.
- På grund af flere tabeller er ydeevnen lav sammenlignet med stjerneskemaet.
- Snefnugskemaet har det højeste dataintegritetsniveau og lave redundanser på grund af normalisering.
Stjerne vs. Snowflake: Fordele

Fordele ved Star Schema
- Stjerneskema er den enkleste måde blandt datamart-skemaerne.
- Det har en simpel rapporteringslogik. Denne logik er underforstået dynamisk.
- Den er designet ved at bruge fødeterninger, der er anvendt gennem onlinetransaktionsprocessen, for at få kuber til at fungere effektivt.
- Stjerneskema er dannet med simpel logik og forespørgsler, der er nemme at udtrække fra transaktionsprocessen.
- Det giver forbedret ydeevne til rapporteringsapplikationer.
- Det er implementeret til at kontrollere hurtig gendannelse af data.
- Den filtrerede og valgte information kan nemt anvendes i forskellige tilfælde.
Fordele ved Snowflake Schema
- Stjerneskema bruges til at udvikle forespørgselsydeevne på grund af færre krav til disklagring.
- Det giver større skalerbarhed i forholdet mellem komponenter og dimensionsniveauer.
- Det er nemmere at vedligeholde.
- Stjerneskema tilbyder hurtig datahentning.
- Det er et almindeligt og enkelt dataskema til data warehousing.
- Det hjælper med at forbedre datakvaliteten.
- De strukturerede data reducerer spørgsmålet om dataintegritet.
Stjerne vs. Snowflake: Begrænsninger
Begrænsninger af stjerneskema
Det har en høj denormaliseret og integritetstilstand. Hele processen vil kollapse, hvis brugeren undlader at opdatere dataene. Sikkerheden og beskyttelsen er også begrænset. Derudover er stjerneskemaet ikke så fleksibelt som den analytiske model. Det tilbyder ikke effektiv støtte til forskellige relationer.
Begrænsninger af Snowflake Schema
Den største begrænsning, du vil finde med Snowflake, er den ekstra vedligeholdelsesindsats på grund af det stigende antal små dimensionstabeller. Mange komplekse forespørgsler gør det udfordrende at finde de nødvendige data. Derudover er implementeringstiden for spørgsmålet høj på grund af højere tabeller. Denne model er også stiv og kræver højere vedligeholdelsesomkostninger.
Stjerne vs. Snowflake: Forskelle
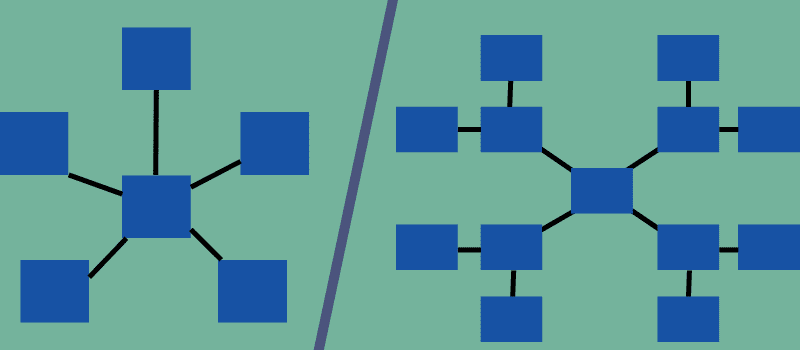
Stjerne og snefnug er typer af flerdimensionelle skemaer, men har forskellige strukturer og egenskaber. Førstnævnte er som en stjerne, og sidstnævnte ligner et snefnug, der definerer deres navne.
I stjerneskemaet bygger kun en enkelt joinforbindelse en relation mellem den centrale faktatabel og sidedimensionstabeller. På den anden side, i snefnugskemaet, er der behov for flere sammenføjninger for at linke til dimensionstabeller.
Stjerneskema bruges generelt, når du har færre rækker i dimensionstabellen, hvorimod snefnugskema bruges, når en dimensionstabel er relativt stor.
Diagrammet nedenfor adskiller de to modeller og hvordan dimensionstabellerne og faktatabellen er forbundet i forskellige skemaer.
ParametreStjerneskemaSnefnugskemaDiskpladsStjerneskema bruger mere diskplads.Snefnugskema bruger mindre diskplads.DatareundansDet har høj dataredundans.Det har lav dataredundans.NormaliseringDimensionstabellerne er denormaliserede, hvilket betyder at gentage den samme værdi i tabellen.Dimensionstabellerne er fuldt normaliseret.ForespørgselsydeevneDet tager minimum tid at udføre forespørgslerne, hvilket resulterer i bedre ydeevne.Det tager mere tid end stjerneskemaet til forespørgselsudførelsen, hvilket gør det mindre effektivt end stjerneskemaet.ForespørgselskompleksitetForespørgselskompleksiteten er lav.Forespørgselskompleksiteten er højere end stjerneskemaet.VedligeholdelsePå grund af høj dataredundans er det lidt vanskeligt at vedligeholde stjerneskemaet.På grund af lav dataredundans er det nemt at vedligeholde og ændre snefnugskemaet.DataintegritetDataintegritet er høj, fordi data lagres redundant, hvor der er flere kopier findes i dimensionstabellerne. Dataintegriteten er lav, da den fuldstændig normaliserer dimensionstabellerne. Hierarkier Hierarkier for dimensionstabellerne i stjerneskemaet er gemt i dimensionstabellen. Hierarkier er opdelt i separate dimensionstabeller.DB-designDet har et simpelt DB-design.Det har et meget komplekst DB-design.Fakta-tabelFlere dimensionstabeller omgiver en faktatabel. Faktatabellen er omgivet af dimensionstabeller, som også er omgivet af underdimensionstabeller.Set upStar-skemaet er nemt at designe og opsætte, da direkte relationer repræsenterer dem. På den anden side er snefnugskemaet lidt komplekst at sætte op. TerningbehandlingKubebehandling er hurtigere.På grund af kompleks sammenføjning er kubbearbejdning lidt langsom.FremmednøglerDen har et minimum antal fremmednøgler.Den har det maksimale antal fremmednøgler.
Konklusion
Både Star- og Snowflake-skemaer er nyttige i forskellige sektorer. Så beslutningen om, hvilken der er bedst blandt dem, er baseret på deres krav.
Snefnugskemaet er en forlængelse af stjerneskemaet, hvor det normaliserer dimensionstabellerne i stjerneskemaet.
Stjerneskemaet er enkelt i designet, kører forespørgsler hurtigere, og opsætningen er nem. På den anden side er snefnugskemaet lettere at vedligeholde, tager mindre diskplads og er mindre tilbøjeligt til problemer med dataintegritet.
Så et stjerneskema kunne være den bedre mulighed, hvis du har brug for et simpelt design, færre fremmednøgler og hurtigere kubebehandling. Men hvis du har brug for mindre diskplads, lav dataintegritet og lav vedligeholdelse, kan snefnugskemaet være mere egnet.
Du kan også udforske nogle af de bedste grafdatabaseløsninger.