
Hvis du har brugt Linux i et stykke tid, kender du allerede til grep — Global Regular Expression Print, et tekstbehandlingsværktøj, som du kan bruge til at søge i filer og mapper. Det er meget nyttigt i hænderne på en Linux-power-bruger. Men at bruge det uden regex kan begrænse dets muligheder.
Men hvad er Regex?
Regex er regulære udtryk, som du kan bruge til at forbedre grep-søgefunktionaliteten. Regex er per definition et avanceret output-filtreringsmønster. Med øvelse kan du bruge regex effektivt, da du også kan bruge det med andre Linux-kommandoer.
I vores selvstudie lærer vi, hvordan du bruger Grep og Regex effektivt.
Indholdsfortegnelse
Forudsætning
Brug af grep med regex kræver god Linux viden. Hvis du er nybegynder, så tjek vores Linux-guides.
Du skal også have adgang til en bærbar eller computer, der kører Linux-operativsystemet. Du kan bruge enhver Linux-distro efter eget valg. Og hvis du har en Windows-maskine, kan du stadig bruge Linux med WSL2. Se vores detaljerede bud på det her.
Adgang til kommandolinjen/terminalen giver dig mulighed for at køre alle kommandoerne i vores grep/regex tutorial.
Desuden skal du også have adgang til en eller flere tekstfiler, som du skal bruge for at køre eksemplerne. Jeg brugte ChatGPT til at generere en tekstvæg, der fortalte den at skrive om teknologi. Den prompt, jeg brugte, er som nedenfor.
“Generer 400 ord om teknologi. Det bør omfatte det meste af teknologi. Sørg også for, at du gentager teknologinavne på tværs af teksten.”
Når den genererede teksten, kopierede jeg den og gemte den i tech.txt-filen, som vi vil bruge i hele vejledningen.
Endelig er en grundlæggende forståelse af grep-kommandoen et must. Du kan tjekke 16 eksempler på grep-kommandoer for at genopfriske din viden. Vi introducerer også grep-kommandoen kort for at komme i gang.
Syntaks og eksempler på grep-kommando
grep kommandosyntaksen er enkel.
$ grep -options [regex/pattern] [files]
Som du kan bemærke, forventer den et mønster og listen over filer, du vil køre kommandoen.
Der er masser af grep-muligheder tilgængelige, der ændrer dens funktionalitet. Disse omfatter:
- – i: ignorer sager
- -r: lav rekursiv søgning
- -w: udfør en søgning for kun at finde hele ord
- -v: vis alle ikke-matchende linjer
- -n: Vis alle matchende linjenumre
- -l: udskriv filnavnene
- –farve: farvet resultatoutput
- -c: viser matchantal for det anvendte mønster
#1. Søg efter et helt ord
Du skal bruge -w-argumentet med grep til en hel ordsøgning. Ved at bruge det, omgår du alle strenge, der matcher det givne mønster.
$ grep -w ‘tech\|5G’ tech.txt
Som du kan se, resulterer kommandoen i et output, hvor den søger efter to ord, “5G” og “tech”, i hele teksten. Det markerer dem derefter med rød farve.
Her er | pipesymbolet escapes, så grep ikke behandler det som et metategn.
#2. Versal-ufølsom søgning
For at lave en søgning uden store og små bogstaver, brug grep med argumentet -i.
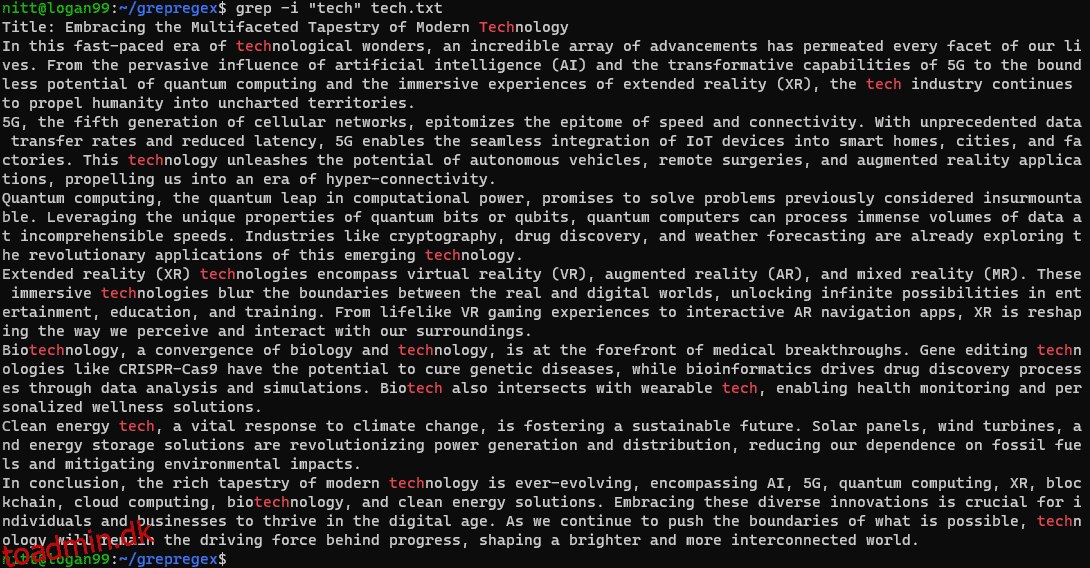
$ grep -i ‘tech’ tech.txt
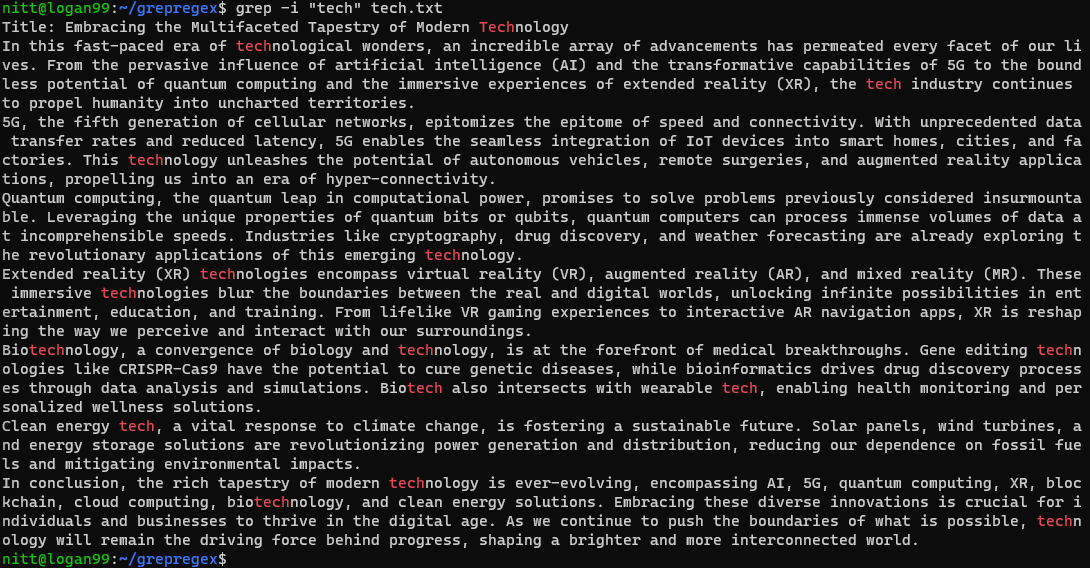
Kommandoen søger efter enhver forekomst af “tech”-strengen, der ikke skiller mellem store og små bogstaver, uanset om det er et komplet ord eller en del af det.
#3. Foretag en ikke-matchende linjesøgning
For at vise alle de linjer, der ikke indeholder et givet mønster, skal du bruge argumentet -v.
$ grep -v ‘tech’ tech.txt

Outputtet viser alle de linjer, der ikke indeholder ordet “tech.” Du vil også se tomme linjer. Disse linjer er de linjer, der er efter et afsnit.
#4. Lav en rekursiv søgning
For at lave en rekursiv søgning, brug argumentet -r med grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
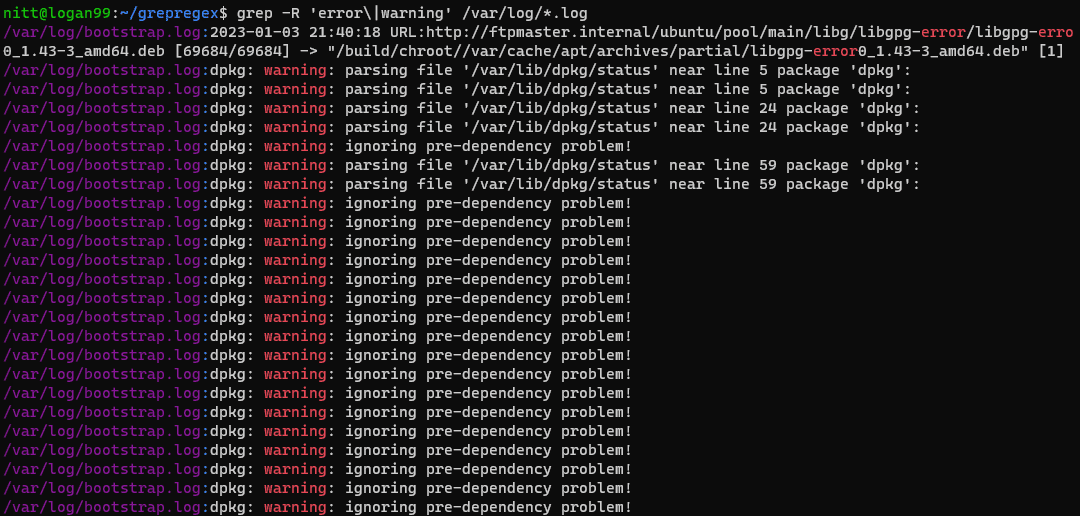
grep-kommandoen søger rekursivt efter to ord, “fejl” og “advarsel”, i mappen /var/log. Dette er en praktisk kommando til at lære om eventuelle advarsler og fejl i logfilerne.
Grep og Regex: Hvad det er og eksempler
Mens vi arbejder med regex, skal du vide, at regex tilbyder tre syntaksmuligheder. Disse omfatter:
- Grundlæggende regulære udtryk (BRE)
- Udvidede regulære udtryk (ERE)
- Pearl-kompatible regulære udtryk (PCRE)
grep-kommandoen bruger BRE som standardindstilling. Så hvis du vil bruge andre regex-tilstande, skal du nævne dem. grep-kommandoen behandler også metategn, som de er. Så hvis du bruger metategn såsom ?, +, ), bliver du nødt til at undslippe dem med kommandoen omvendt skråstreg (\).
Syntaksen for grep med regex er som nedenfor.
$ grep [regex] [filenames]
Lad os se grep og regex i aktion med eksemplerne nedenfor.
#1. Ordrette ord matches
For at lave et bogstaveligt ordmatch, skal du angive en streng som regex. Et ord er jo også et regex.
$ grep "technologies" tech.txt

På samme måde kan du også bruge bogstavelige matches til at finde aktuelle brugere. For at gøre det, løb,
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
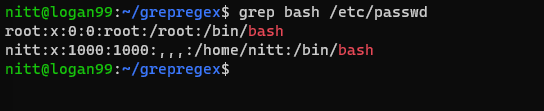
Dette viser de brugere, der kan få adgang til bash.
#2. Anker Matching
Ankermatchning er en nyttig teknik til avancerede søgninger ved hjælp af specialtegn. I regex er der forskellige ankertegn, som du kan bruge til at repræsentere bestemte positioner i en tekst. Disse omfatter:
- ‘^’ cart-symbol: Caret-symbolet matcher starten af inputstrengen eller linjen og leder efter en tom streng.
- ‘$’ dollarsymbol: Dollarsymbolet matcher slutningen af inputstrengen eller linjen og leder efter en tom streng.
De to andre ankermatchende tegn inkluderer ‘\ b’-ordgrænsen og ‘\B’ ikke-ordgrænse.
- ‘\ b’ ordgrænse: Med \b kan du hævde positionen mellem et ord og et ikke-ordstegn. I enkle ord giver det dig mulighed for at matche komplette ord. På denne måde kan du undgå delvise kampe. Du kan også bruge det til at erstatte ord eller tælle ordforekomster i en streng.
- \B ikke-ord grænse: Det er det modsatte af \b ord grænse i regex, da det hævder en position, der ikke er mellem to-ord eller ikke-ord tegn.
Lad os gennemgå eksempler for at få en klar idé.
$ grep ‘^From’ tech.txt

Brug af caret kræver, at ordet eller mønsteret indtastes med det rigtige bogstav. Det er fordi der skelnes mellem store og små bogstaver. Så hvis du kører følgende kommando, returnerer den ikke noget.
$ grep ‘^from’ tech.txt
På samme måde kan du bruge $-symbolet til at finde den sætning, der matcher et givet mønster, streng eller ord.
$ grep ‘technology.$' tech.txt

Du kan også kombinere både ^- og $-symboler. Lad os se på eksemplet nedenfor.
$ grep “^From \| technology.$” tech.txt
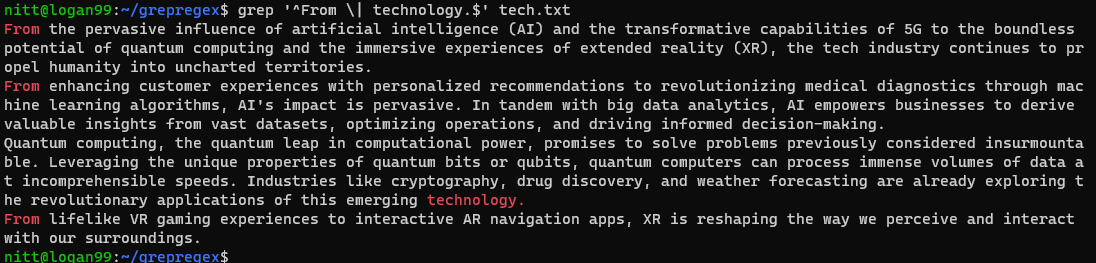
Som du kan se, indeholder outputtet sætninger, der starter med “Fra” og sætninger, der slutter med “teknologi.”
#3. Gruppering
Hvis du ønsker at søge i flere mønstre på én gang, skal du bruge gruppering. Det hjælper dig med at skabe små grupper af karakterer og mønstre, som du kan behandle som en enkelt enhed. For eksempel kan du oprette en gruppe (tech), der inkluderer udtrykket ‘t’, ‘e’,’ c’,’ h.’
For at få en klar idé, lad os se et eksempel.
$ grep 'technol\(ogy\)\?' tech.txt

Med gruppering kan du matche gentagne mønstre, fange grupper og søge efter alternativer.
Alternativ søgning med gruppering
Lad os se et eksempel på en alternativ søgning.
$ grep "\(tech\|technology\)" tech.txt
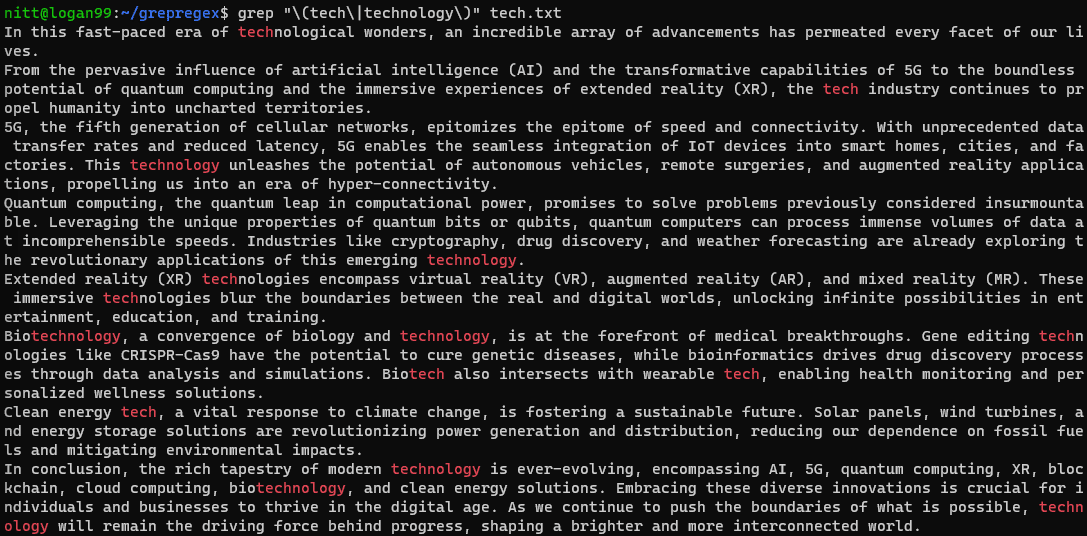
Hvis du vil udføre en søgning på en streng, skal du sende den med rørsymbolet. Lad os se det i eksemplet nedenfor.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Indfangning af grupper, ikke-fangende grupper og gentagne mønstre
Og hvad med at fange og ikke-fange grupper?
Du skal oprette en gruppe i regex og sende den til strengen eller en fil for at fange grupper.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

Og for ikke-fangende grupper skal du bruge ?: inden for parentes.
Til sidst har vi gentagne mønstre. Du bliver nødt til at ændre regex for at kontrollere for gentagne mønstre.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Her leder regex efter en eller flere forekomster af ‘t’-tegnet.
#4. Karakterklasser
Med karakterklasser kan du nemt skrive regex-udtryk. Disse karakterklasser bruger firkantede parenteser. Nogle af de velkendte karakterklasser inkluderer:
- [:digit:] – 0 til 9 cifre
- [:alpha:] – alfabetiske tegn
- [:alnum:] – Alfanumeriske tegn
- [:lower:] – små bogstaver
- [:upper:] – store bogstaver
- [:xdigit:] – hexadecimale cifre, herunder 0-9, AF, af
- [:blank:] – tomme tegn såsom tabulator eller mellemrum
Og så videre!
Lad os se et par af dem i aktion.
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
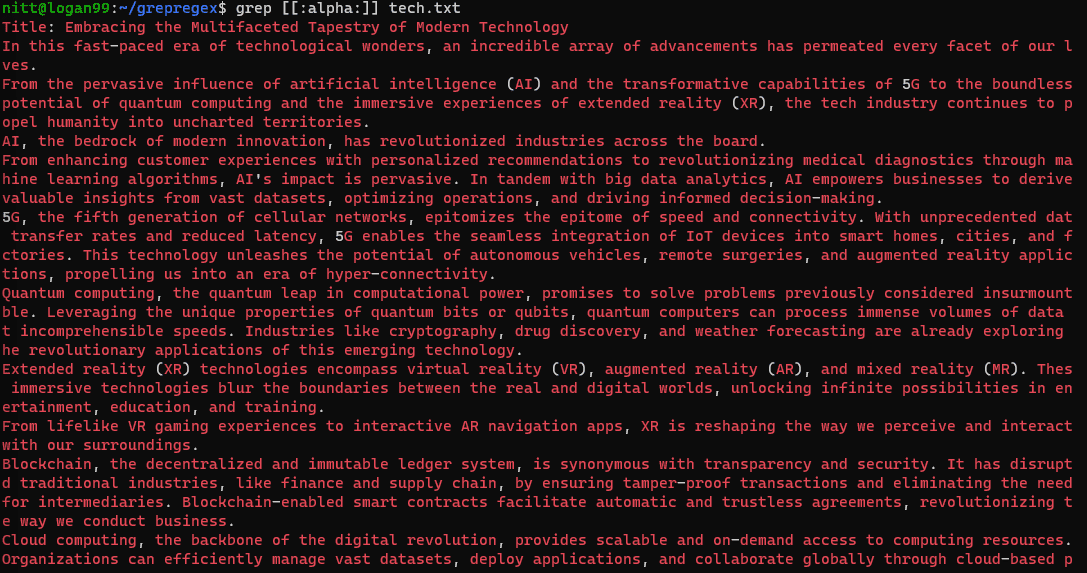
$ grep [[:xdigit:]] tech.txt
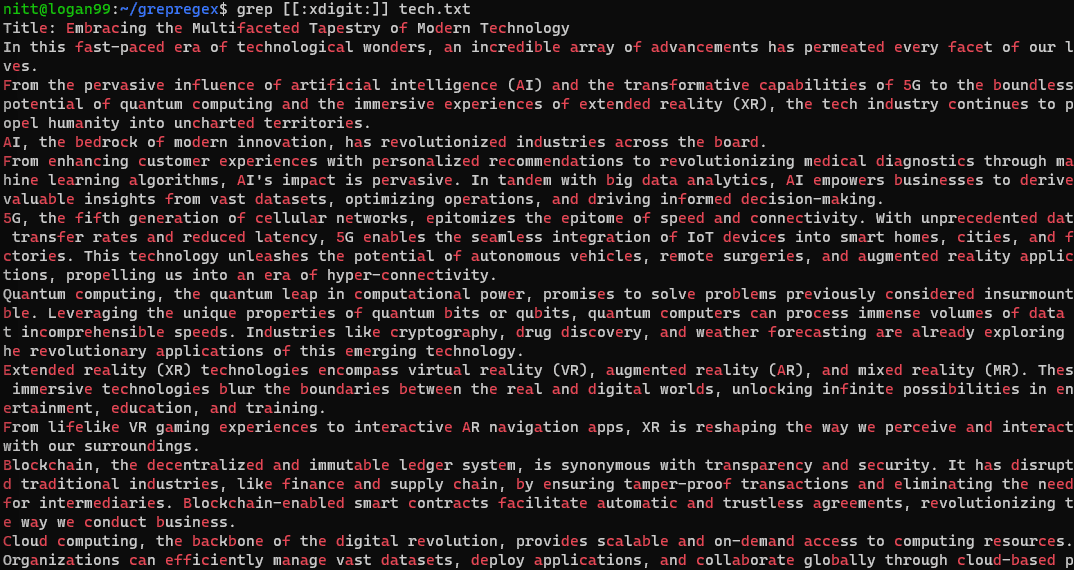
#5. Kvantifikatorer
Kvantifikatorer er metakarakterer og er kernen i regex. Disse lader dig matche det nøjagtige udseende. Lad os se på dem nedenfor.
- * → Nul eller flere matches
- + → et eller flere matcher
- ? → Nul eller et match
- {x} → x matcher
- {x, } → x eller flere matcher
- {x,z} → fra x til z matcher
- {, z} → op til z matcher
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Her søger den efter ‘t’-tegnforekomsterne for en eller flere matches. Her står -E for udvidet regex (som vi vil diskutere senere.)

#6. Udvidet Regex
Hvis du ikke kan lide at tilføje escape-tegn i regex-mønsteret, skal du bruge udvidet regex. Det fjerner behovet for at tilføje escape-tegn. For at gøre det skal du bruge flaget -E.
$ grep -E 'in+ovation' tech.txt

#7. Brug af PCRE til at udføre komplekse søgninger
PCRE (Perl Compatible Regular Expression) lader dig gøre meget mere end at skrive grundlæggende udtryk. For eksempel kan du skrive “\d”, som angiver [0-9].
For eksempel kan du bruge PCRE til at søge efter e-mailadresser.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Her sikrer PCRE, at mønsteret er afstemt. På samme måde kan du også bruge et PCRE-mønster til at tjekke for datomønstre.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Kommandoen finder datoen i formatet ÅÅÅÅ-MM-DD. Du kan også ændre den, så den matcher andre datoformater.
#8. Veksling
Hvis du vil have alternative matchninger, kan du bruge de escaped pipe-tegn (\|).
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Outputtet viser filnavnene, der indeholder “advarsel” eller “fejl”.
Afsluttende ord
Dette fører os til slutningen af vores grep og regex guide. Du kan bruge grep med regex i udstrakt grad til at forfine søgninger. Med korrekt brug kan du spare masser af tid og hjælpe med at automatisere mange opgaver, især hvis du bruger dem til at skrive scripts eller bruge regex til at udføre søgninger gennem teksten.
Tjek derefter ofte stillede Linux-interviewspørgsmål og -svar.