
Data er et kritisk aktiv, der kan forbedre driften, effektiviteten, kundeoplevelsen og beslutningstagningen.
Med henblik herpå genererer, indsamler og lagrer virksomheder og organisationer enorme mængder data fra forskellige kilder. Men efterhånden som datamængderne stiger, kan det være en udfordring at udtrække den mest nyttige information, især når informationen er uorganiseret og spredt på tværs af forskellige steder.
En måde at overvinde disse udfordringer på er at gemme data i et passende datalager. Dette giver en samlet datakilde, der indeholder information, der er filtreret, søgbar og klar til analyse og rapportering.
Kilde: aws.amazon.com
I dette vil vi definere datalageret og lære dets fordele, de forskellige typer og bedste praksis.
Indholdsfortegnelse
Hvad er et datalager?
Et datalager er et bibliotek eller et arkiv, der indeholder data til at understøtte analyse- og rapporteringsfunktioner i forskning eller forretningsdrift. I praksis er et datalager en generel term, der refererer til den centraliserede placering, hvor data opbevares. Det kan referere til en enkelt lagerenhed eller et sæt databaser, der spænder over forskellige enheder.
I en typisk operation kan organisationer indsamle forskellige data fra salgssteder, CRM, ERP, regneark og andre kilder. De flytter det derefter til et datalager, hvor det sorteres, renses, valideres, formateres, organiseres og gemmes.
Normalt kan organisationer isolere og gemme specifikke typer data i depotet til analytiske eller rapporteringsmæssige formål. Og da dette er langtidsopbevaring, kan de genbruge det flere gange til at udføre forskellige typer analyser.
Et typisk datalager har tre hovedlag.
- Datakildelag
- Databehandlingslag eller lager
- Målapplikationslaget, som f.eks. består af brugere, analytikere og rapportering
Hvorfor har du brug for et datalager?
Data er tilgængelige fra kundekontaktpunkter, internettet, forskning, marketing, applikationer og mange andre kilder. Men det er normalt i råformat, og organisationer har brug for passende værktøjer til at udtrække nyttig information for at hjælpe dem med at nå deres mål. En god praksis er at oprette et datalager for at organisere dataene og gøre dem tilgængelige for analyse og andre applikationer.
Depotet gør det muligt for autoriserede brugere nemt og hurtigt at få adgang til, hente og administrere data ved hjælp af søgning, forespørgsler og andre værktøjer. Derfor kan brugere og virksomheder udføre analyser, research, deling og rapportering. Og dette gør dem i stand til at strømline driften og træffe bedre datadrevne beslutninger.
Antag, at du ønsker at fastslå, hvilken afdeling i din organisation, der har de største driftsomkostninger. Du kan oprette et datalager for lejekontrakter, sikkerhed, energiomkostninger, forsyningsselskaber og andre udgifter. At opbevare dataene på et centraliseret sted hjælper dig med at analysere og identificere den afdeling, der har de fleste udgifter, og dermed træffe mere informerede og fokuserede beslutninger, når du vil reducere omkostningerne.
Selvom datalagre almindeligvis bruges af forsknings- og videnskabelige institutioner, er det også anvendeligt til generelle organisationer og virksomheder.
Fordele ved datalagre
I dag bruger de fleste organisationer datalagre som et middel til at administrere og udnytte deres data mere effektivt. Datalagerkonceptet er fortsat med at vinde popularitet på grund af fordele som nem adgang til information, styring, analyse og rapportering.
Andre fordele omfatter:
- Giver bedre synlighed: Lagring af data på et centralt, pålideligt sted gør det tilgængeligt når som helst. I modsætning hertil betyder det at holde dataene i ikke-delte applikationer eller lokale siloer, at de kun er tilgængelige for en enkeltperson eller få personer. Dette reducerer dets synlighed og brugervenlighed. Derfor kan teams tage længere tid og bruge yderligere ressourcer til at få adgang til dataene.
- Nem adgang til nyttige data: Data i digital form er let at søge og få adgang til. Tilføjelse af metadata til dataene i depotet gør det muligt for brugerne at forstå og bruge dem meget bedre.
- Nemt at sikre data og overholde standarder: Det er meget nemmere at beskytte data på en central placering, i modsætning til når de er spredt ud over forskellige steder. Derudover gør et datalager det nemt og billigere at overholde forskellige regulatoriske standarder.
- Genanvendelige data: Datalageret indeholder en lang række data til analyse og rapportering. Analytikere og forskere kan bruge de samme data til at generere forskellige typer rapporter.
- Giver nyttig indsigt: Brug af passende værktøjer på datalagre giver dig mulighed for at få et multidimensionelt overblik over dataene i modsætning til at analysere information på forskellige steder.
Typer af datalagre
Datalager er en generel betegnelse, der refererer til informationsarkivet. Der er dog forskellige arkiver baseret på målapplikationen eller målet. Og nedenfor er de fire hovedtyper af datalagre.
#1. Data varehus
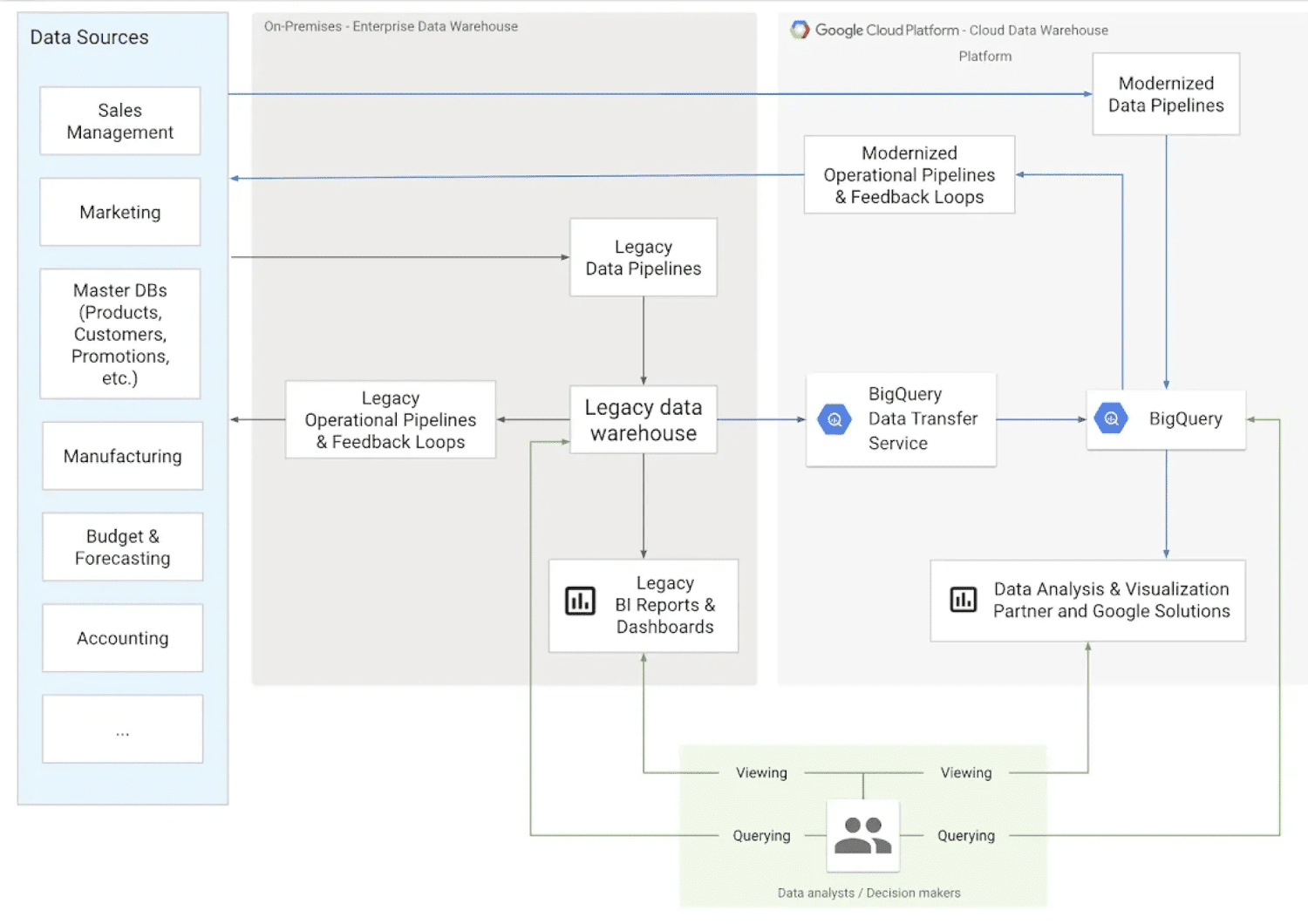 Kilde: cloud.google.com
Kilde: cloud.google.com
Datavarehuset er en af de største datalagertyper. I denne kategori kan virksomheder indsamle data fra flere kilder og i forskellige formater. Et typisk datavarehus gemmer store mængder data fra forskellige kilder. Dens struktur gør det muligt for organisationer nemt at organisere dataene, analysere og lave rapporter. Og dette gør det muligt for teams at træffe bedre datadrevne beslutninger.
Oplysninger i et datavarehus kan dække flere emner og er normalt renset, filtreret og defineret til en bestemt anvendelse.
#2. Data Mart
En datamart er en adskilt sektion af et datavarehus. Det emneorienterede datalager gemmer en delmængde af data med fokus på en specifik forretningsfunktion eller afdeling, såsom økonomi, support, indkøb eller markedsføring.
Typisk er en datamart mindre i størrelse. Dette hjælper med at fremskynde forretningsprocesser ved at give adgang til de relevante data inden for en kortere periode. Disse giver et omkostningseffektivt middel til hurtigt at få brugbar indsigt.
#3. Data Lake
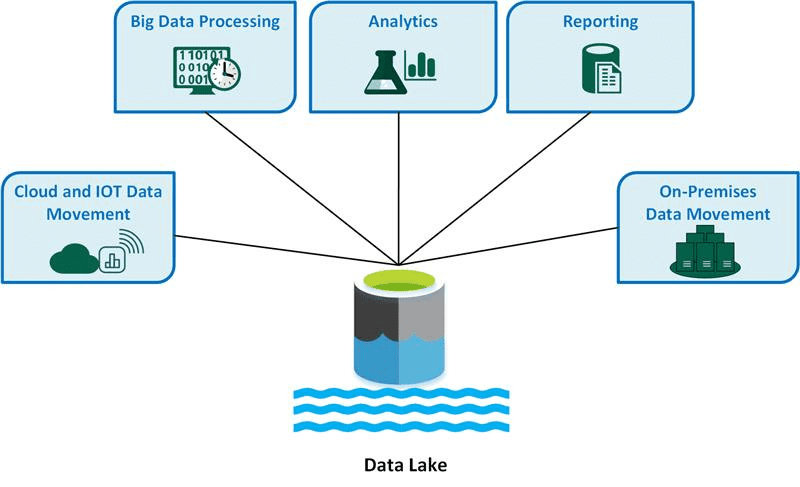 Kilde: microsoft.com
Kilde: microsoft.com
En datasø er et stort arkiv, der indeholder data i enhver form. Dette omfatter ustrukturerede, semistrukturerede og strukturerede data. Den bruger metadata til at kategorisere og mærke dataene, som stort set er ustrukturerede. En datasø giver total kontrol og bedre datastyring end et datavarehus.
#4. Datakuber
Datakuber er multidimensionelle datalagre, der fokuserer mere på komplekse data, der ikke understøttes af de andre typer. Disse har tre eller flere dimensioner, der hver repræsenterer en specifik egenskab, såsom daglige, månedlige eller årlige omkostninger eller salg. Datasøer gør det muligt for forskere at vurdere data fra forskellige synspunkter.
Læs også: Data Lake vs. Data Warehouse: Hvad er forskellene?
Bedste praksis for design og vedligeholdelse af datalagre
Et typisk datalager har værktøjer til at gemme, administrere og sikre informationen. Den har funktioner som adgangskontrol, indeksering, komprimering, rapportering, kryptering og mere.
Når du designer og opretter et datalager, skal du overveje flere hardware- og softwarefaktorer ud over at arbejde med datapipelineingeniører, dataanalytikere og andre eksperter. Afhængigt af domænet skal du involvere brancheeksperter. For eksempel, hvis du opretter et klinisk datalager, vil du arbejde med læger og andre medicinske fagfolk.
En effektiv datastyringsstrategi omfatter følgende:
✅ Organisering af filer
✅ Sikker opbevaring og korrekt adgangskontrol
✅ Versions- og dokumentationskontrol
✅ Understøtter samarbejde
✅ Klare politikker om genbrug og deling
✅ Arkivering og opbevaring af data til fremtidig reference eller brug.
Selvom trinene til at designe, oprette og administrere et datalager kan variere fra den ene branche eller organisation til den anden, er der nogle bedste fremgangsmåder nedenfor.
Begræns omfanget i de indledende faser
I begyndelsen er det bedste praksis at bruge et mindre omfang af datalageret. En strategi er at bruge et mindre antal fagområder og datasæt og øge omfanget gradvist.
Vælg de rigtige værktøjer
Værktøjer er afgørende for at skabe, gemme, dele, analysere og administrere datalagre. Som sådan vil datakvaliteten og -analysen afhænge af de værktøjer, du bruger. Da der er forskellige typer værktøjer med forskellige muligheder, skal du sikre dig, at dit valg opfylder dine behov.
Automatiser så mange processer som muligt
Hvis det er muligt, automatiser belastnings- og vedligeholdelsesopgaverne for at forbedre effektiviteten, reducere tidsspild og risikoen for fejl.
Design et fleksibelt og skalerbart lager
For at imødekomme øgede datamængder, skiftende datatyper og formater er det bedste praksis at designe og skabe et skalerbart lager. Et sådant system vil tjene de nuværende behov og skala for at understøtte øgede datatyper og -mængder i fremtiden. Det skal også være fleksibelt at arbejde med forskellige værktøjer og nye teknologier.
Beskyt data til enhver tid
Sørg for dataintegritet og sikkerhed, da eventuelle uoverensstemmelser, kompromiser eller tyveri kan føre til unøjagtige analyseresultater og dårlige beslutninger. Indstil korrekte adgangsregler og giv kun autoriserede brugere de tilladelser, de har brug for for at udføre deres opgaver. Krypter desuden dataene i hvile og under transport. Overvej andre foranstaltninger som multifaktorgodkendelse for at tilføje et ekstra beskyttelseslag.
Brug standarddatamodeller
Datamodellering hjælper med at konvertere data til værdifuld information, som forskere og virksomhedsledere kan forstå bedre. Normalt kan oplysninger i et datalager genbruges.
Organisationer kan bruge de samme data til at udtrække nyttig information på forskellige områder. Data har mange sammenhænge baseret på, hvordan de bruges i forskellige processer og analytiske applikationer. Som sådan kan en organisation bruge flere datamodeller til at imødekomme forskellige analytiske behov.
Indeksering af data
Oprettelse af indekser på datalagertabellerne forbedrer forespørgselsydeevnen og bør være standardpraksis. Det forbedrer forespørgselshastigheden ved at give en organiseret opslagstabel baseret på bestemte attributter og med indtastninger, der peger på specifikke dataplaceringer.
Indeksering på datalagre kan variere afhængigt af brugen. Det kan være let eller omfattende, afhængigt af brugen. Ideelt set bør indekseringsstrategien fokusere på at fremskynde ETL-processerne. En bedste praksis ved transformation af data er at sikre, at indekset giver den nødvendige information uden at gå glip af brugbare data og være unødvendigt store.
Det er også vigtigt at balancere afvejningen mellem forbedret forespørgselsydeevne for datalageret og de tilhørende faste omkostninger og vedligeholdelsesomkostninger ved indekseringen.
Læs også: Bedste ETL-værktøjer til SMB’er at bruge.
Eksempler på datalagre
Datalagre falder ind under forskellige kategorier:
Brug Cases of Data Repositories
Fintech, sundhedspleje, e-handel, forsyningskæde og andre industrier kan drage fordel af at bruge datalagre. Ved fuldt ud at udnytte de store mængder data, de indsamler og genererer, kan de få bedre indsigt til at optimere deres tjenester og levere bedre og hurtigere tjenester.
Klinisk forskning
Klinisk forskning er et dataintensivt felt. At få mest muligt ud af data er med til at drive sundhedsindustrien i den rigtige retning. Analyse af big data gør det muligt for forskere og andre fagfolk at grave dybt ned i kliniske forsøg og få indsigt, der hjælper med at forbedre sundhedsvæsenet og redde liv.
Finansielle tjenesteydelser

Den finansielle serviceindustri kan drage fordel af at analysere store mængder data, de har. Analysen giver dem indsigt, som de kan bruge til at forbedre tjenester, effektivitet og indtjening. Nogle af de områder, finansielle institutioner kan bruge datalagre omfatter:
- At generere økonomiske rapporter ved at analysere data fra en central placering.
- Muliggør AI-drevet automatisk beslutningstagning.
Afsluttende ord
Data er et væsentligt aktiv i beslutningstagning. Organisationer, der lagrer store mængder data, har dog brug for de rigtige løsninger til at indsamle, lagre, administrere og analysere dataene.
Med henblik herpå giver et datalager en løsning til at konsolidere og administrere kritiske data. Lagrene gør det muligt for organisationer at analysere data, få indsigt og træffe bedre datadrevne beslutninger.
Et datalager giver centraliseret lagring af forskellige typer information, men på en logisk måde, der gør det nemt at få adgang til, søge, analysere og administrere. Det hjælper også organisationer med at sikre, dele, vedligeholde og sikre dataintegritet og kvalitet og overholde regulatoriske standarder.
Tjek derefter de bedste datastyringsværktøjer til mellemstore og store virksomheder.