

Pandas er det mest populære dataanalysebibliotek til Python. Det bruges flittigt af dataanalytikere, dataforskere og maskinlæringsingeniører.
Ved siden af NumPy er det et af de biblioteker og værktøjer, der skal kendes til alle, der arbejder med data og AI.
I denne artikel vil vi udforske pandaer og de funktioner, der gør den så populær i dataøkosystemet.
Indholdsfortegnelse
Hvad er pandaer?
Pandas er et dataanalysebibliotek til Python. Det betyder, at det bruges til at arbejde med og manipulere data fra din Python-kode. Med Pandas kan du effektivt læse, manipulere, visualisere, analysere og gemme data.
Navnet ‘Pandas’ kommer fra at forbinde ordene Panel Data, et økonometrisk udtryk, der refererer til data opnået ved at observere flere individer over tid. Pandas blev oprindeligt udgivet i januar 2008 af Wes Kinney, og det er siden vokset til at blive det mest populære bibliotek for dets use case.
I hjertet af Pandas er to essentielle datastrukturer, som du bør være bekendt med, Dataframes og Series. Når du opretter eller indlæser et datasæt i Pandas, er det repræsenteret som en af disse to datastrukturer.
I det næste afsnit vil vi undersøge, hvad de er, hvordan de er forskellige, og hvornår er det ideelle at bruge en af dem.
Nøgledatastrukturer
Som tidligere nævnt er alle data i Pandas repræsenteret ved hjælp af enten en af to datastrukturer, en dataramme eller en serie. Disse to datastrukturer er forklaret i detaljer nedenfor.
Dataramme
Dette eksempel på dataramme blev produceret ved hjælp af kodestykket nederst i dette afsnit
En Dataframe i Pandas er en todimensionel datastruktur med kolonner og rækker. Det ligner et regneark i dit regnearksprogram eller en tabel i en relationsdatabase.
Den består af kolonner, og hver kolonne repræsenterer en attribut eller funktion i dit datasæt. Disse kolonner består så af individuelle værdier. Denne liste eller serie af individuelle værdier er repræsenteret som en serie objekter. Vi vil diskutere seriedatastrukturen mere detaljeret senere i denne artikel.
Kolonner i en dataramme kan have beskrivende navne, så de kan skelnes fra hinanden. Disse navne tildeles, når datarammen oprettes eller indlæses, men kan nemt omdøbes til enhver tid.
Værdierne i en kolonne skal være af samme datatype, selvom kolonner ikke skal indeholde data af samme type. Dette betyder, at en navnekolonne i et datasæt udelukkende vil gemme strenge. Men det samme datasæt kan have andre kolonner som alder, der gemmer ints.
Dataframes har også et indeks, der bruges til at referere til rækker. Værdier på tværs af forskellige kolonner, men med det samme indeks, danner en række. Som standard er indekser nummererede, men kan omtildeles, så de passer til datasættet. I eksemplet (billedet ovenfor, kodet nedenfor), sætter vi indekskolonnen til kolonnen ‘måneder’.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Serie
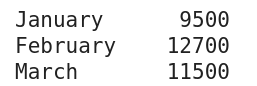 Dette eksempelserie blev produceret ved hjælp af koden nederst i dette afsnit
Dette eksempelserie blev produceret ved hjælp af koden nederst i dette afsnit
Som diskuteret tidligere, bruges en serie til at repræsentere en kolonne af data i Pandas. En serie er derfor en endimensionel datastruktur. Dette er i modsætning til en Dataframe, der er todimensionel.
Selvom en serie almindeligvis bruges som en kolonne i en dataramme, kan den også repræsentere et komplet datasæt alene, forudsat at datasættet kun har én attribut, der registreres i en enkelt kolonne. Eller rettere, datasættet er simpelthen en liste over værdier.
Fordi en serie blot er én kolonne, behøver den ikke at have et navn. Værdierne i serien er dog indekseret. Ligesom indekset for en dataramme kan datarammen for en serie ændres fra standardnummereringen.
I eksemplet (billedet ovenfor, kodet nedenfor) er indekset blevet indstillet til forskellige måneder ved hjælp af set_axis-metoden for et Pandas Series-objekt.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Funktioner af pandaer
Nu hvor du har en god idé om, hvad Pandas er, og de nøgledatastrukturer, den bruger, kan vi begynde at diskutere de funktioner, der gør Pandas til et så kraftfuldt dataanalysebibliotek og som et resultat utroligt populært inden for Data Science og Machine Learning Økosystemer.
#1. Datamanipulation
Dataframe- og Series-objekterne kan ændres. Du kan tilføje eller fjerne kolonner efter behov. Derudover giver Pandas dig mulighed for at tilføje rækker og endda flette datasæt.
Du kan udføre numeriske beregninger, såsom normalisering af data og foretage logiske sammenligninger elementmæssigt. Pandas giver dig også mulighed for at gruppere data og anvende aggregerede funktioner såsom middelværdi, gennemsnit, maks. og min. Dette gør arbejdet med data i Pandas til en leg.
#2. Datarensning
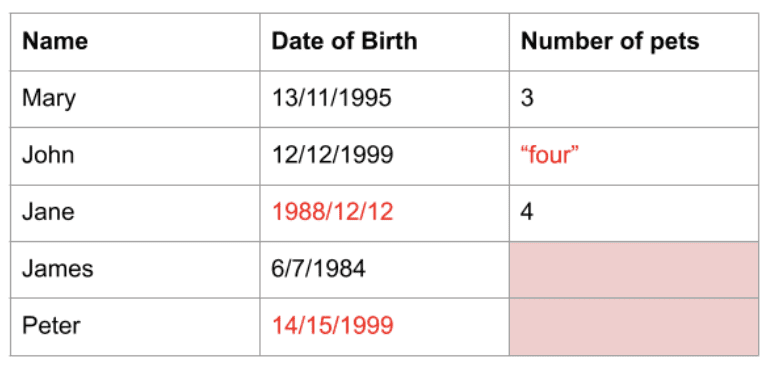
Data opnået fra den virkelige verden har ofte værdier, der gør det svært at arbejde med eller ikke ideelt til analyse eller brug i maskinlæringsmodeller. Dataene kan være af den forkerte datatype, i det forkerte format, eller det kan bare mangle fuldstændigt. Uanset hvad, skal disse data forbehandles, kaldet rensning, før de kan bruges.
Pandas har funktioner, der hjælper dig med at rense dine data. I Pandas kan du f.eks. slette duplikerede rækker, slippe kolonner eller rækker med manglende data og erstatte værdier med enten standardværdier eller en anden værdi, såsom middelværdien af kolonnen. Der er flere funktioner og biblioteker, der arbejder med Pandas for at gøre det muligt for dig at foretage mere datarensning.
#3. Datavisualisering
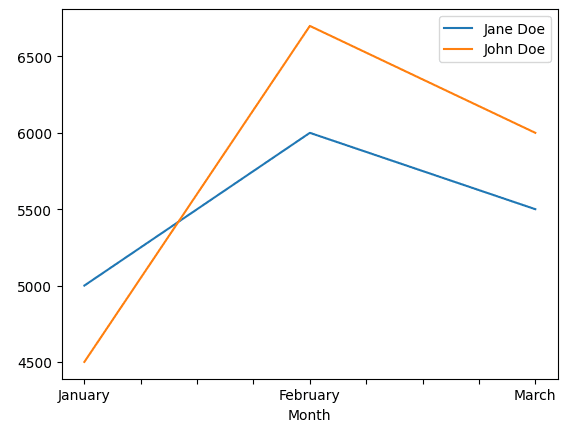 Denne graf er blevet genereret med koden under dette afsnit
Denne graf er blevet genereret med koden under dette afsnit
Selvom det ikke er et visualiseringsbibliotek som Matplotlib, har Pandas funktioner til at skabe grundlæggende datavisualiseringer. Og selvom de er grundlæggende, får de stadig arbejdet gjort i de fleste tilfælde.
Med Pandas kan du nemt plotte søjlediagrammer, histogrammer, scatter-matricer og andre forskellige typer diagrammer. Kombiner det med nogle datamanipulationer, du kan udføre i Python, og du kan skabe endnu mere komplicerede visualiseringer for bedre at forstå dine data.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Tidsserieanalyse
Pandas understøtter også arbejde med tidsstemplede data. Når Pandas genkender en kolonne som havende datetime-værdier, kan du udføre mange operationer på den samme kolonne, som er nyttige, når du arbejder med tidsseriedata.
Disse omfatter gruppering af observationer efter tidsperiode og anvendelse af aggregerede funktioner på dem, såsom sum eller middelværdi eller få de tidligste eller seneste observationer ved hjælp af min og max. Der er selvfølgelig mange flere ting, du kan gøre med tidsseriedata i Pandas.
#5. Input/output i pandaer
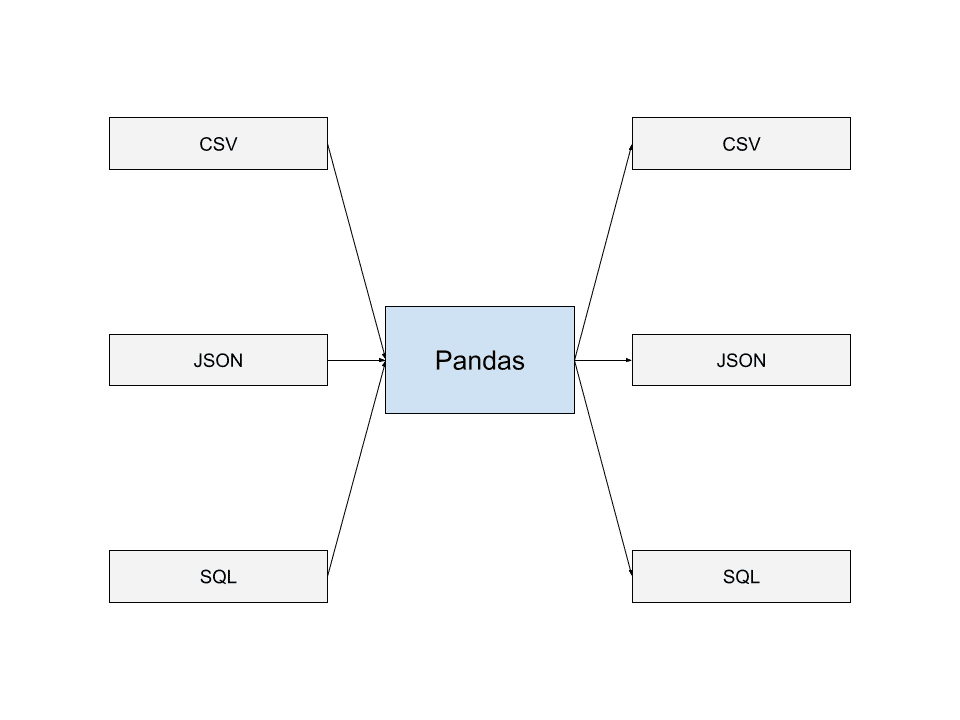
Pandas er i stand til at læse data fra de mest almindelige datalagringsformater. Disse inkluderer JSON, SQL Dumps og CSV’er. Du kan også skrive data til filer i mange af disse formater.
Denne evne til at læse fra og skrive til forskellige datafilformater giver Pandas mulighed for problemfrit at interoperere med andre applikationer og bygge datapipelines, der integreres godt med Pandas. Dette er en af grundene til, at Pandas er meget brugt af mange udviklere.
#6. Integration med andre biblioteker
Pandas har også et rigt økosystem af værktøjer og biblioteker bygget oven på det for at komplementere dets funktionalitet. Dette gør det til et endnu mere kraftfuldt og nyttigt bibliotek.
Værktøjer i Pandas økosystem forbedrer dets funktionalitet på tværs af forskellige områder, herunder datarensning, visualisering, maskinlæring, input/output og parallelisering. Pandas vedligeholder et register over sådanne værktøjer i deres dokumentation.
Overvejelser om ydeevne og effektivitet i pandaer
Mens Pandas skinner i de fleste operationer, kan det være notorisk langsomt. Den lyse side er, at du kan optimere din kode og forbedre dens hastighed. For at gøre dette skal du forstå, hvordan Pandas er bygget.
Pandas er bygget oven på NumPy, et populært Python-bibliotek til numerisk og videnskabelig beregning. Derfor fungerer Pandas, ligesom NumPy, mere effektivt, når operationer vektoriseres i modsætning til at plukke på individuelle celler eller rækker ved hjælp af loops.
Vektorisering er en form for parallelisering, hvor den samme operation anvendes på flere datapunkter på én gang. Dette kaldes SIMD – Single Instruction, Multiple Data. At drage fordel af vektoriserede operationer vil forbedre hastigheden og ydeevnen af Pandaer dramatisk.
Fordi de bruger NumPy-arrays under hætten, er DataFrame- og Series-datastrukturerne hurtigere end deres alternative ordbøger og lister.
Standard Pandas-implementeringen kører kun på én CPU-kerne. En anden måde at fremskynde din kode på er at bruge biblioteker, der gør det muligt for Pandas at bruge alle de tilgængelige CPU-kerner. Disse inkluderer Dask, Vaex, Modin og IPython.
Fællesskab og ressourcer
Da Pandas er et populært bibliotek med det mest populære programmeringssprog, har Pandas et stort fællesskab af brugere og bidragydere. Som et resultat er der masser af ressourcer at bruge til at lære at bruge det. Disse omfatter den officielle Pandas-dokumentation. Men der er også utallige kurser, tutorials og bøger at lære af.
Der er også online fællesskaber på platforme som Reddit i r/Python og r/Data Science subreddits for at stille spørgsmål og få svar. Da du er et open source-bibliotek, kan du rapportere problemer på GitHub og endda bidrage med kode.
Afsluttende ord
Pandas er utrolig nyttig og kraftfuld som et datavidenskabsbibliotek. I denne artikel forsøgte jeg at forklare dets popularitet ved at udforske de funktioner, der gør det til det bedste værktøj for datavidenskabsfolk og programmører.
Tjek derefter, hvordan du opretter en Pandas DataFrame.