
Data er en uundværlig del af virksomheder og organisationer, og de er kun værdifulde, når de er struktureret korrekt og administreret effektivt.
Ifølge en statistik finder 95 % af virksomhederne i dag håndtering og strukturering af ustrukturerede data som et problem.
Det er her datamining kommer ind i billedet. Det er processen med at opdage, analysere og udtrække meningsfulde mønstre og værdifuld information fra store sæt ustrukturerede data.
Virksomheder bruger software til at identificere mønstre i store databatches for at lære mere om deres kunder og målgruppe og udvikle forretnings- og marketingstrategier for at forbedre salget og reducere omkostningerne.
Udover denne fordel er svindel- og anomalidetektion de vigtigste anvendelser af datamining.
Denne artikel forklarer afsløring af anomalier og udforsker yderligere, hvordan det kan hjælpe med at forhindre databrud og netværksindtrængen for at sikre datasikkerhed.
Indholdsfortegnelse
Hvad er anomalidetektion og dens typer?
Mens datamining involverer at finde mønstre, korrelationer og tendenser, der hænger sammen, er det en fantastisk måde at finde anomalier eller afvigende datapunkter i netværket.
Anomalier i datamining er datapunkter, der adskiller sig fra andre datapunkter i datasættet og afviger fra datasættets normale adfærdsmønster.
Anomalier kan klassificeres i forskellige typer og kategorier, herunder:
- Ændringer i hændelser: Henviser til pludselige eller systematiske ændringer fra den tidligere normale adfærd.
- Outliers: Små anomale mønstre, der optræder på en ikke-systematisk måde i dataindsamling. Disse kan yderligere klassificeres i globale, kontekstuelle og kollektive outliers.
- Drifter: Gradvis, ikke-retningsbestemt og langsigtet ændring i datasættet.
Således er anomalidetektion en databehandlingsteknik, der er meget nyttig til at opdage svigagtige transaktioner, håndtere casestudier med ubalance af høj klasse og sygdomsdetektion for at opbygge robuste datavidenskabelige modeller.
For eksempel kan en virksomhed ønsker at analysere sine pengestrømme for at finde unormale eller tilbagevendende transaktioner til en ukendt bankkonto for at opdage bedrageri og foretage yderligere undersøgelser.
Fordele ved anomalidetektion
Registrering af uregelmæssigheder i brugeradfærd hjælper med at styrke sikkerhedssystemerne og gør dem mere præcise og nøjagtige.
Den analyserer og giver mening i forskellige informationer, som sikkerhedssystemer leverer for at identificere trusler og potentielle risici inden for netværket.
Her er fordelene ved anomalidetektion for virksomheder:
- Realtidsdetektering af cybersikkerhedstrusler og databrud, da dets algoritmer for kunstig intelligens (AI) konstant scanner dine data for at finde usædvanlig adfærd.
- Det gør sporing af unormale aktiviteter og mønstre hurtigere og nemmere end manuel registrering af uregelmæssigheder, hvilket reducerer det arbejde og den tid, der kræves for at løse trusler.
- Minimerer operationelle risici ved at identificere driftsfejl, såsom pludselige ydelsesfald, før de overhovedet opstår.
- Det hjælper med at eliminere større virksomhedsskader ved at opdage uregelmæssigheder hurtigt, da virksomheder uden et system til registrering af uregelmæssigheder kan tage uger og måneder at identificere potentielle trusler.
Således er anomalidetektion et stort aktiv for virksomheder, der opbevarer omfattende kunde- og virksomhedsdatasæt for at finde vækstmuligheder og eliminere sikkerhedstrusler og operationelle flaskehalse.
Teknikker til afsløring af anomalier
Anomalidetektion bruger adskillige procedurer og ML-algoritmer til at overvåge data og opdage trusler.
Her er de vigtigste teknikker til opdagelse af anomalier:
#1. Maskinlæringsteknikker

Maskinlæringsteknikker bruger ML-algoritmer til at analysere data og detektere anomalier. De forskellige typer af Machine Learning-algoritmer til registrering af anomalier omfatter:
- Klyngealgoritmer
- Klassifikationsalgoritmer
- Deep learning algoritmer
Og de almindeligt anvendte ML-teknikker til anomali- og trusselsdetektion inkluderer støttevektormaskiner (SVM’er), k-betyder clustering og autoencodere.
#2. Statistiske teknikker
Statistiske teknikker bruger statistiske modeller til at detektere usædvanlige mønstre (som usædvanlige udsving i ydeevnen af en bestemt maskine) i dataene for at detektere værdier, der falder uden for rækkevidden af de forventede værdier.
De almindelige statistiske anomalidetektionsteknikker inkluderer hypotesetestning, IQR, Z-score, modificeret Z-score, tæthedsestimering, boxplot, ekstremværdianalyse og histogram.
#3. Data Mining Teknikker

Data mining-teknikker bruger dataklassificering og klyngeteknikker til at finde anomalier i datasættet. Nogle almindelige data mining-anomaliteknikker omfatter spektralklynger, tæthedsbaseret klyngedannelse og principalkomponentanalyse.
Clustering data mining-algoritmer bruges til at gruppere forskellige datapunkter i klynger baseret på deres lighed for at finde datapunkter og anomalier, der falder uden for disse klynger.
På den anden side allokerer klassifikationsalgoritmer datapunkter til specifikke foruddefinerede klasser og registrerer datapunkter, der ikke tilhører disse klasser.
#4. Regelbaserede teknikker
Som navnet antyder, bruger regelbaserede anomalidetektionsteknikker et sæt forudbestemte regler til at finde anomalier i dataene.
Disse teknikker er forholdsvis nemmere og enklere at konfigurere, men kan være ufleksible og er muligvis ikke effektive til at tilpasse sig de skiftende dataadfærd og mønstre.
For eksempel kan du nemt programmere et regelbaseret system til at markere transaktioner, der overstiger et bestemt dollarbeløb, som svigagtige.
#5. Domænespecifikke teknikker
Du kan bruge domænespecifikke teknikker til at opdage uregelmæssigheder i specifikke datasystemer. Selvom de kan være yderst effektive til at opdage uregelmæssigheder i specifikke domæner, kan de være mindre effektive i andre domæner uden for det angivne.
Ved at bruge domænespecifikke teknikker kan du for eksempel designe teknikker specifikt til at finde uregelmæssigheder i finansielle transaktioner. Men de virker muligvis ikke til at finde uregelmæssigheder eller ydeevnefald i en maskine.
Behov for maskinlæring til registrering af anomalier
Maskinlæring er meget vigtig og yderst nyttig til afsløring af anomalier.
I dag håndterer de fleste virksomheder og organisationer, der kræver afvigende detektion, enorme mængder data, fra tekst, kundeoplysninger og transaktioner til mediefiler som billeder og videoindhold.
At gennemgå alle banktransaktioner og data, der genereres hvert sekund manuelt for at skabe meningsfuld indsigt, er næsten umuligt. Desuden står de fleste virksomheder over for udfordringer og store vanskeligheder med at strukturere ustrukturerede data og arrangere dataene på en meningsfuld måde til dataanalyse.
Det er her værktøjer og teknikker som machine learning (ML) spiller en enorm rolle i indsamling, rengøring, strukturering, arrangering, analyse og lagring af enorme mængder af ustrukturerede data.
Maskinlæringsteknikker og algoritmer behandler store datasæt og giver fleksibiliteten til at bruge og kombinere forskellige teknikker og algoritmer for at give de bedste resultater.
Derudover hjælper maskinlæring også med at strømline processer til registrering af anomalier til applikationer i den virkelige verden og sparer værdifulde ressourcer.
Her er nogle flere fordele og vigtigheden af maskinlæring i anomalidetektion:
- Det gør detektion af skaleringsanomali lettere ved at automatisere identifikation af mønstre og anomalier uden at kræve eksplicit programmering.
- Machine Learning-algoritmer er meget tilpasningsdygtige til skiftende datasætmønstre, hvilket gør dem yderst effektive og robuste over tid.
- Håndterer nemt store og komplekse datasæt, hvilket gør detektion af anomalier effektiv på trods af datasættets kompleksitet.
- Sikrer tidlig identifikation og detektion af uregelmæssigheder ved at identificere uregelmæssigheder, efterhånden som de opstår, hvilket sparer tid og ressourcer.
- Machine Learning-baserede anomalidetektionssystemer hjælper med at opnå højere niveauer af nøjagtighed i anomalidetektion sammenlignet med traditionelle metoder.
Afvigelsesdetektion parret med maskinlæring hjælper således hurtigere og mere tidlig opdagelse af anomalier for at forhindre sikkerhedstrusler og ondsindede brud.
Machine Learning Algoritmer til Anomali Detektion
Du kan detektere anomalier og outliers i data ved hjælp af forskellige datamining-algoritmer til klassificering, klyngedannelse eller indlæring af tilknytningsregler.
Typisk er disse datamining-algoritmer klassificeret i to forskellige kategorier – overvågede og ikke-overvågede indlæringsalgoritmer.
Superviseret læring
Overvåget læring er en almindelig type læringsalgoritme, der består af algoritmer som understøttende vektormaskiner, logistisk og lineær regression og multi-klasse klassifikation. Denne algoritmetype trænes på mærkede data, hvilket betyder, at dens træningsdatasæt inkluderer både normale inputdata og tilsvarende korrekte output eller unormale eksempler for at konstruere en forudsigelig model.
Dets mål er således at lave outputforudsigelser for usete og nye data baseret på træningsdatasætmønstrene. Anvendelserne af overvågede læringsalgoritmer omfatter billed- og talegenkendelse, prædiktiv modellering og naturlig sprogbehandling (NLP).
Uovervåget læring
Uovervåget læring trænes ikke på nogen mærkede data. I stedet opdager den komplicerede processer og underliggende datastrukturer uden at give træningsalgoritmevejledningen og i stedet for at lave specifikke forudsigelser.
Anvendelserne af uovervågede indlæringsalgoritmer omfatter anomalidetektion, tæthedsestimering og datakomprimering.
Lad os nu udforske nogle populære maskinlæringsbaserede anomalidetektionsalgoritmer.
Local Outlier Factor (LOF)
Local Outlier Factor eller LOF er en anomalidetektionsalgoritme, der tager lokal datatæthed i betragtning for at bestemme, om et datapunkt er en anomali.
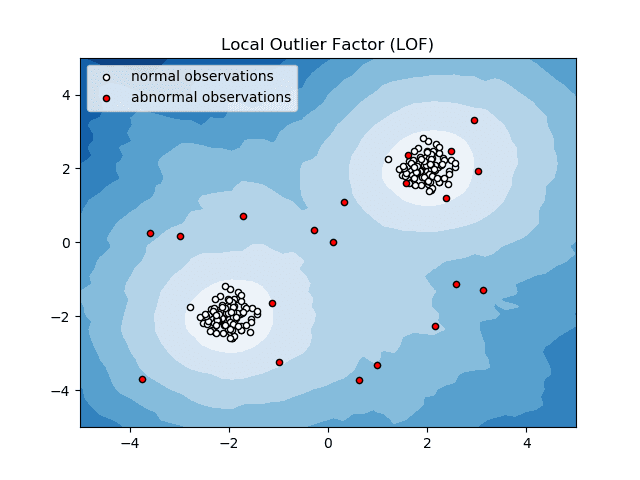 Kilde: scikit-learn.org
Kilde: scikit-learn.org
Den sammenligner en genstands lokale tæthed med dens naboers lokale tæthed for at analysere områder med lignende tæthed og varer med forholdsvis lavere tæthed end deres naboer – som ikke er andet end anomalier eller afvigelser.
Således, i enkle vendinger, er tætheden omkring en afvigende eller anomal genstand forskellig fra tætheden omkring dens naboer. Derfor kaldes denne algoritme også en tæthedsbaseret outlier-detektionsalgoritme.
K-Nærmeste Nabo (K-NN)
K-NN er den enkleste klassifikations- og overvågede anomalidetektionsalgoritme, der er nem at implementere, gemmer alle tilgængelige eksempler og data og klassificerer de nye eksempler baseret på lighederne i afstandsmålingerne.
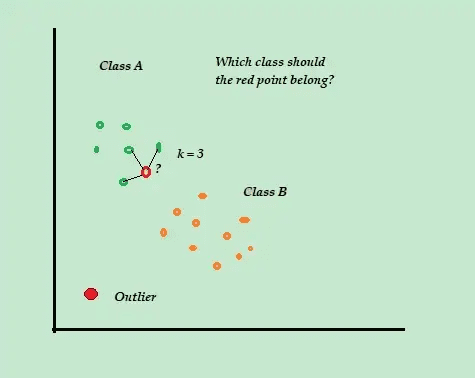 Kilde: towardsdatascience.com
Kilde: towardsdatascience.com
Denne klassifikationsalgoritme kaldes også en doven elev, fordi den kun gemmer de mærkede træningsdata – uden at gøre andet under træningsprocessen.
Når det nye umærkede træningsdatapunkt ankommer, ser algoritmen på de K-nærmeste eller de nærmeste træningsdatapunkter for at bruge dem til at klassificere og bestemme klassen for det nye umærkede datapunkt.
K-NN-algoritmen bruger følgende detektionsmetoder til at bestemme de nærmeste datapunkter:
- Euklidisk afstand til at måle afstanden for kontinuerlige data.
- Hammerafstand for at måle nærheden eller “nærheden” af de to tekststrenge for diskrete data.
Overvej for eksempel, at dine træningsdatasæt består af to klasseetiketter, A og B. Hvis der ankommer et nyt datapunkt, vil algoritmen beregne afstanden mellem det nye datapunkt og hvert af datapunkterne i datasættet og vælge punkterne som er det maksimale antal tættest på det nye datapunkt.
Så antag at K=3, og 2 ud af 3 datapunkter er mærket som A, så er det nye datapunkt mærket som klasse A.
Derfor fungerer K-NN-algoritmen bedst i dynamiske miljøer med hyppige dataopdateringskrav.
Det er en populær algoritme til registrering af uregelmæssigheder og tekstmining med applikationer inden for finans og virksomheder til at opdage svigagtige transaktioner og øge antallet af svigopdagelse.
Support Vector Machine (SVM)
Støttevektormaskine er en overvåget maskinlæringsbaseret anomalidetektionsalgoritme, der mest bruges i regressions- og klassifikationsproblemer.
Den bruger et multidimensionelt hyperplan til at adskille data i to grupper (nye og normale). Hyperplanet fungerer således som en beslutningsgrænse, der adskiller de normale dataobservationer og de nye data.
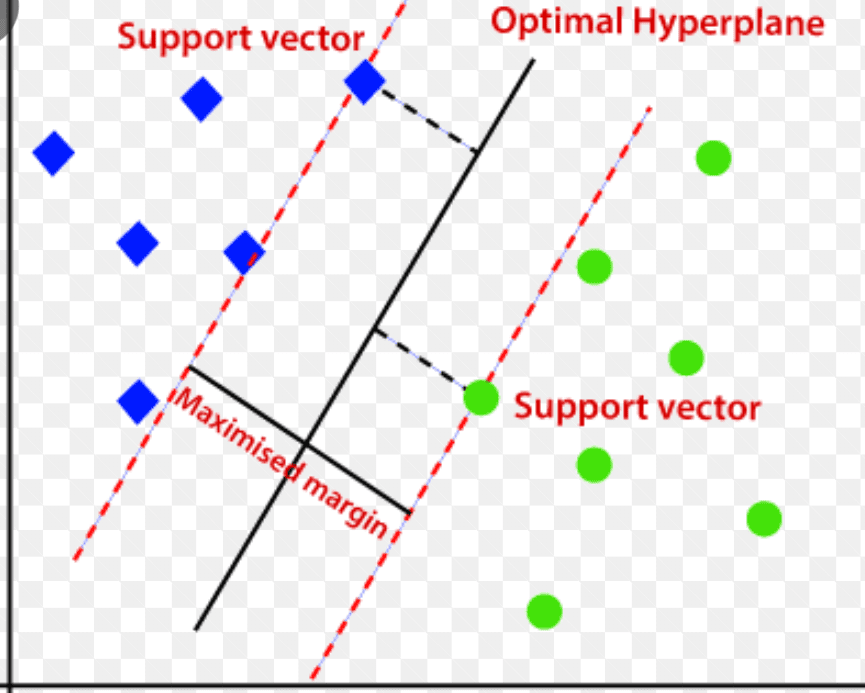 Kilde: www.analyticsvidhya.com
Kilde: www.analyticsvidhya.com
Afstanden mellem disse to datapunkter kaldes marginer.
Da målet er at øge afstanden mellem de to punkter, bestemmer SVM det bedste eller det optimale hyperplan med den maksimale margin for at sikre, at afstanden mellem de to klasser er så bred som muligt.
Med hensyn til anomalidetektion beregner SVM marginen for den nye datapunktsobservation fra hyperplanet for at klassificere den.
Hvis marginen overstiger den indstillede tærskel, klassificerer den den nye observation som en anomali. Samtidig, hvis marginen er mindre end tærsklen, klassificeres observationen som normal.
Således er SVM-algoritmerne yderst effektive til at håndtere højdimensionelle og komplekse datasæt.
Isolation Skov
Isolation Forest er en uovervåget maskinindlæringsalgoritme til detektering af anomalier baseret på konceptet med en Random Forest Classifier.
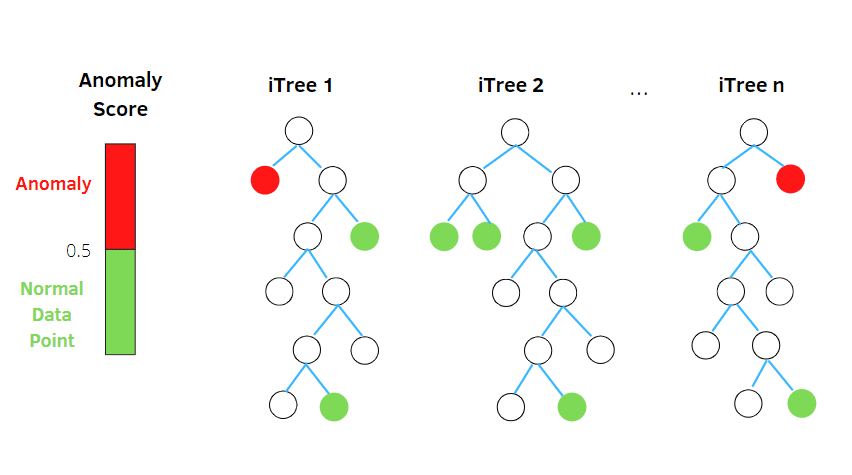 Kilde: betterprogramming.pub
Kilde: betterprogramming.pub
Denne algoritme behandler tilfældigt subsamplede data i datasættet i en træstruktur baseret på tilfældige attributter. Den konstruerer flere beslutningstræer for at isolere observationer. Og den betragter en bestemt observation som en anomali, hvis den er isoleret i færre træer baseret på dens forureningsrate.
I enkle vendinger opdeler isolationsskov-algoritmen således datapunkterne i forskellige beslutningstræer – hvilket sikrer, at hver observation bliver isoleret fra en anden.
Anomalier ligger typisk væk fra datapunktklyngen – hvilket gør det nemmere at identificere anomalierne sammenlignet med de normale datapunkter.
Isolationsskovsalgoritmer kan nemt håndtere kategoriske og numeriske data. Som et resultat er de hurtigere at træne og meget effektive til at opdage højdimensionelle og store datasæt-anomalier.
Inter-kvartil rækkevidde
Interkvartilområde eller IQR bruges til at måle statistisk variabilitet eller statistisk spredning for at finde anomale punkter i datasættene ved at opdele dem i kvartiler.
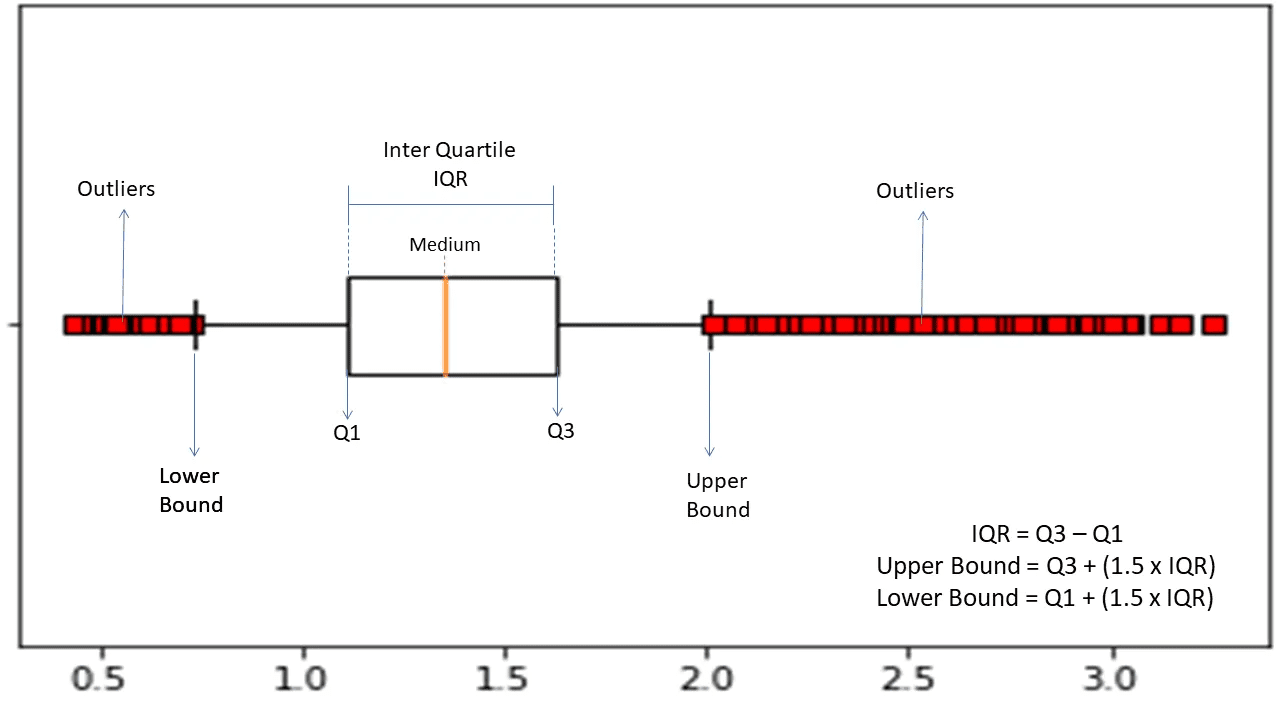 Kilde: morioh.com
Kilde: morioh.com
Algoritmen sorterer dataene i stigende rækkefølge og opdeler sættet i fire lige store dele. Værdierne, der adskiller disse dele, er Q1, Q2 og Q3 – første, anden og tredje kvartil.
Her er percentilfordelingen af disse kvartiler:
- Q1 betyder den 25. percentil af dataene.
- Q2 betegner den 50. percentil af dataene.
- Q3 betyder den 75. percentil af dataene.
IQR er forskellen mellem det tredje (75.) og det første (25.) percentildatasæt, der repræsenterer 50 % af dataene.
Brug af IQR til anomalidetektion kræver, at du beregner IQR for dit datasæt og definerer de nedre og øvre grænser for dataene for at finde anomalier.
- Nedre grænse: Q1 – 1,5 * IQR
- Øvre grænse: Q3 + 1,5 * IQR
Typisk betragtes observationer, der falder uden for disse grænser, som anomalier.
IQR-algoritmen er effektiv til datasæt med ujævnt fordelte data, og hvor fordelingen ikke er godt forstået.
Afsluttende ord
Cybersikkerhedsrisici og databrud ser ikke ud til at bremse i de kommende år – og denne risikable industri forventes at vokse yderligere i 2023, og IoT-cyberangrebene alene forventes at fordobles i 2025.
Ydermere vil cyberkriminalitet koste globale virksomheder og organisationer anslået 10,3 billioner dollars årligt i 2025.
Dette er grunden til, at behovet for teknikker til afsløring af uregelmæssigheder bliver mere udbredt og nødvendigt i dag til at opdage svindel og forhindre netværksindtrængen.
Denne artikel hjælper dig med at forstå, hvad uregelmæssigheder i datamining er, forskellige typer uregelmæssigheder og måder at forhindre netværksindtrængen på ved hjælp af ML-baserede anomalidetektionsteknikker.
Dernæst kan du udforske alt om forvirringsmatricen i maskinlæring.