
Når vi siger “serverløs” computing, antager mange, at der ikke er nogen server i denne model til at lette kodeudførelsen og andre udviklingsopgaver. Det er en ren misforståelse.
Så efter denne mytebuster tænker du måske, hvad logikken bag navnet “serverløs” er.
Lad mig give dig et tip: I stedet for “ingen server”, er det, HVORDAN serverne administreres og implementeres, hvad “Serverløs” indebærer.
Lyder det forvirrende?
Nå, vi vil lære alt om serverløs og andre termer relateret til det for at fjerne dine tvivl. For det første bliver serverløs berømt, mens vi taler. Faktisk vil det serverløse marked sandsynligvis nå 7,7 milliarder dollar i 2021 fra $1,9 milliarder i 2016.
Så lad os diskutere serverløs og prøve at finde ud af årsagen bag dens popularitet.
Indholdsfortegnelse
Hvad er serverløs computing?
Serverløs eller serverløs computing er en cloud-baseret eksekveringsmodel, hvor cloud-tjenesteudbydere leverer on-demand maskinressourcer og administrerer serverne af sig selv i stedet for kunder eller udviklere. Det er en måde, der kombinerer tjenester, strategier og praksisser for at hjælpe udviklere med at bygge cloud-baserede apps ved at lade dem fokusere på deres kode frem for serverstyring.
Fra ressourceallokering, kapacitetsplanlægning, administration, konfigurationer og skalering til patches, opdateringer, planlægning og vedligeholdelse, tager cloud-tjenesteudbyderen (som AWS eller Google Cloud Platform) alt ansvaret for at administrere almindelige infrastrukturopgaver. Som et resultat kan udviklere koncentrere deres indsats og tid om forretningslogik for deres processer og applikationer.
Denne serverløse computerarkitektur holder aldrig computerressourcer i flygtig hukommelse; i stedet foregår beregningen i korte dele. Antag, at du ikke bruger et program, vil der ikke blive allokeret ressourcer til det. Derfor betaler du for, hvilken ressource du rent faktisk bruger på apps.
Hovedformålet med at skabe den serverløse model er at forenkle kodeimplementeringsprocessen i produktionen. Mange gange fungerer det også med traditionelle stilarter som mikrotjenester. Når serverløs er implementeret, begynder de applikationer, den driver, hurtigt at reagere på krav og skaleres automatisk op eller ned efter behov.
Serverløs computing bruger en hændelsesdrevet model til at bestemme skaleringskrav. Derfor behøver udviklere ikke længere at forudse en applikations brug for at bestemme, hvor mange servere eller båndbredde de har brug for. Du kan kræve flere servere og båndbredde baseret på dine stigende behov uden forudgående booking eller skalere ned til enhver tid uden besvær.
Hvordan udviklede serverløs sig?
Det traditionelle system havde udfordringer forbundet med skalerbarhed og smidighed i app-udviklingsprocessen og -implementeringen. Efterhånden som efterspørgslen efter apps af høj kvalitet steg med hurtig time-to-market, begyndte behovet for et bedre system, der kan tilbyde mere skalerbarhed og smidighed, at dukke op. Det resulterede i udviklingen af cloud computing og serverløse modeller.
Den serverløse model udviklede sig i forskellige stadier, fra monolitisk til mikrotjenester til serverløs arkitektur eller Function-as-a-Service (FaaS).
- Monolitisk arkitektur er en traditionel samlet tilgang til softwareudvikling. Det er en tæt koblet model, hvor hver komponent og dens underkomponenter kompilerer eller eksekverer kode. Hvis en tjeneste er defekt, kan hele applikationsserveren og kørende tjenester på den gå ned.
- Mikroservicearkitektur er en samling af mindre tjenester i en stor, enkelt applikation, der er implementeret uafhængigt til at udføre en bestemt funktion. Det muliggør hurtig app-levering i stor skala og giver udviklere fleksibilitet ved at bruge Infrastructure-as-a-Service (IaaS) og Platform as a Service (PaaS). Valget mellem PaaS og IaaS er dog udfordrende i denne model.
- Serverløs arkitektur udviklede sig med cloud computing og tilbyder mere skalerbarhed og forretningsfleksibilitet. I stedet for IaaS og PaaS bruger den FaaS og Backend-as-a-Service (BaaS). Her implementeres apps efter behov, sammen med ressourcerne til det. Du behøver ikke at administrere serveren og kan stoppe med at betale, hvis kodeudførelsen afsluttes.
Attributter ved serverløs computing
Nogle af attributterne ved serverløs computing er som følger:
- De fleste applikationer, der bruger serverløs, omfatter enkelte funktioner og små kodeenheder.
- Den kører kun kode på efterspørgsel, generelt i en statsløs softwarebeholder, og skalerer problemfrit baseret på efterspørgsel.
- Der kræves ingen serverstyring fra kunder.
- Har hændelsesbaseret udførelse, hvor computermiljøet bliver oprettet, når en funktion er udløst, eller en hændelse modtages for at udføre anmodningen.
- Fleksibel skalerbarhed, så du nemt kan skalere op eller ned. Når en kode er eksekveret, stopper infrastrukturen med at køre, og omkostningerne spares. På samme måde, når funktionen fortsætter med at udføre, kan du skalere uendeligt op efter behov.
- Du kan bruge administrerede cloud-tjenester til at håndtere komplekse opgaver som fillagring, kø, databaser og mere.
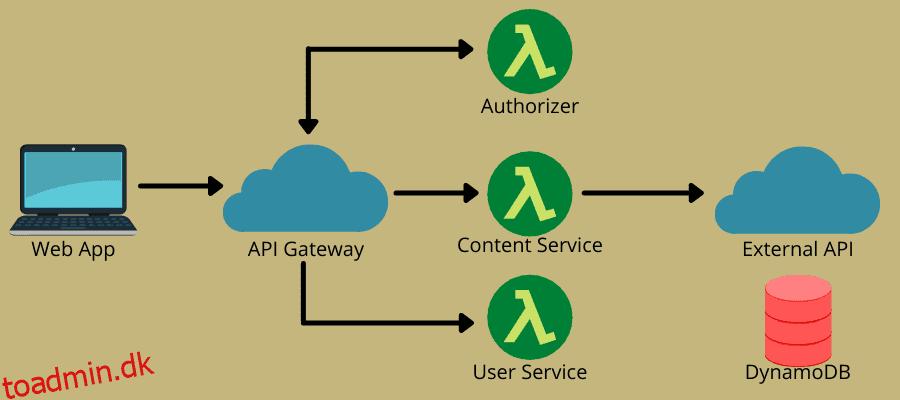
Hvordan fungerer serverløst?
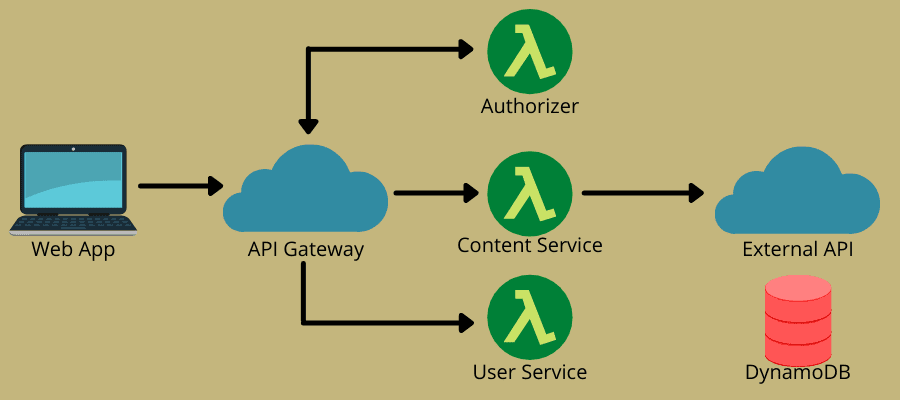
Den serverløse arkitektur kombinerer to hovedideer – Function-as-a-Service (FaaS) og Backend-as-a-Service (BaaS). Det er mere baseret på FaaS, som tillader cloud-tjenester til kodeudførelse uden behov for fuldstændigt provisionerede instanser. FaaS består af statsløse, begivenhedsdrevne, skalerbare og server-side funktioner, som cloud-tjenester administrerer fuldt ud.
Modellen gør det muligt for DevOps-teams at skrive kode med fokus på deres forretningslogik. Dernæst definerer de en hændelse, der kan udløse funktionen, såsom HTTP-anmodninger, til eksekvering. Derfor udfører cloud-udbyderen funktionen og sender resultater til apps, som brugerne kan se.
På denne måde tilbyder den serverløse model omkostningseffektivitet og bekvemmelighed med automatisk skalering, on-demand og pay-as-you-go faciliteter. Derfor går mange virksomheder og DevOps-teams serverløse i disse dage.
Hvem bruger serverløs og hvorfor?
Serverløs er blandt de mest fremspirende teknologier inden for softwareudvikling. Det kan eliminere behov for infrastrukturstyring og levering i fremtiden.
Det er nyttigt til:
- Organisationer, der ønsker mere skalerbarhed og fleksibilitet med bedre app-testbarhed, kan blive serverløse.
- Udviklere, der ønsker at reducere time-to-market ved at bygge agile og højtydende apps
- Virksomheder, der ikke har brug for, at deres servere kører hele tiden. De kan kalde modulbaserede funktioner ved hjælp af applikationer, når det er nødvendigt, for at spare omkostninger.
- Organisationer, der ønsker at bygge effektive cloud-baserede apps og forenkle skymigrering
- Udviklere, der leder efter måder at reducere latens på, kan give brugerne adgang til nogle funktioner eller apps.
- En virksomhed, der ikke har tilstrækkelige ressourcer til at håndtere it-infrastrukturvedligeholdelse og kompleksitet, kan gå efter serverløs computing for at løse problemer automatisk og behøver ingen vedligeholdelse fra deres side.
Nogle bemærkelsesværdige brugere af den serverløse model er Slack, Coca-Cola, NetFlix osv.
På grund af dens unikke egenskaber er den serverløse model velegnet til mange brugssager, såsom:
- Webapplikationer: Du kan bygge hurtige og skalerbare webapplikationer ved hjælp af denne model, der reagerer hurtigt på brugernes krav. Den er ideel til at bygge statsløse apps, som du kan starte med det samme, og apps, der kan imødekomme uforudsigelige, sjældne stigninger i brugerkrav.
- API-backends: I serverløse platforme kan enhver funktion nemt omdannes til HTTP-endepunkter, der er klar til brug af klienter. Disse funktioner eller handlinger er kendt som webhandlinger, når de er aktiveret på nettet. Og når først disse er aktiveret, bliver det nemt at samle funktionerne til et fuldt udbygget API. Du kan også bruge en anstændig API-gateway til at bringe mere sikkerhed, domæneunderstøttelse, hastighedsbegrænsning og OAuth-understøttelse.
- Mikrotjenester: Serverløs er meget brugt i mikroservicemodellen, der fokuserer på at bygge små tjenester, der er i stand til at udføre en enkelt funktion og kommunikere med hinanden ved hjælp af API’er.
Selvom det er muligt at oprette mikrotjenester ved hjælp af softwarecontainere og PaaS, er serverløs mere effektiv. Det letter mindre linjer kode, der udfører én ting og tilbyder hurtig klargøring, automatisk skalering og fleksibel prissætning, der ikke opkræver kunder, når ressourcerne ikke er i brug. - Databehandling: Serverløs er fantastisk at arbejde med data, der indeholder videoer, lyd, billeder og struktureret tekst. Den er også gunstig til forskellige opgaver som datavalidering, transformation, berigelse, rensning, lydnormalisering og PDF-behandling. Du kan udnytte det til billedbehandling, der inkluderer skarphed, rotation, generering af miniaturer og støjreduktion. Andre anvendelser af serverløs i databehandling kan være videotranskodning og optisk tegngenkendelse (OCR).
- Stream-/batchbehandling: Du kan oprette kraftfulde streaming-apps og datapipelines ved hjælp af FaaS og en database med Apache Kafka. Den serverløse model passer til forskellige stream-indtagelser, herunder data til app-logfiler, IoT-sensorer, forretningslogik og det finansielle marked.
- Parallel beregning: Serverløs er fremragende til opgaver relateret til parallel beregning, hvor hver opgave kører parallelt for at udføre en specifik opgave. Det kan omfatte datasøgning, behandling, kortoperationer, web-skrabning, genombehandling, justering af hyperparameter osv.
- Andre anvendelser: Serverløs bruges også til forskellige applikationer, såsom customer relationship management (CRM), økonomi, chatbots og business intelligence og analytics, for at nævne nogle få.
Bemærk: Serverløs er muligvis ikke ideel til nogle tilfælde. For eksempel kan store apps med forudsigelige og næsten konstante arbejdsbelastninger have mere gavn af en traditionel systemarkitektur. De kan gå efter dedikerede servere, enten administrerede eller selvadministrerede. Hvis din organisation har komplette traditionelle opsætninger med ældre systemer og applikationer, kan det være dyrt og udfordrende at flytte til en helt ny og anderledes arkitektur.
Fordele og ulemper ved serverløs computing
Hver mønt har to sider, og det samme har den serverløse arkitektur. Det har også nogle fordele og ulemper baseret på forskellige parametre. Så før du går videre, er det vigtigt at kende begge sider for at beslutte, om det ville være bedre for din organisation eller ej.
Fordele 👍
Her er nogle af fordelene ved serverløs arkitektur:
Omkostningseffektiv
Serverløs kan tilbyde mere omkostningseffektivitet end at købe eller leje servere, hvor du betaler for ressourcer, selvom du ikke bruger dem.
Serverless anvender en pay-as-you-go-model, hvor du kun betaler for de ressourcer, du bruger. Den serverløse udbyder vil kun opkræve dig for den tildelte hukommelse og tid til at køre koden uden at pådrage sig omkostninger for inaktiv tid.
Som et resultat vil du spare på driftsomkostninger til opgaver som installation, licenser, vedligeholdelse, patching, support osv. Uden serverhardware sparer du arbejdsomkostninger.
Skalerbarhed
Serverløse systemer tilbyder et højt niveau af skalerbarhed, da du kan skalere op eller ned, når du vil, baseret på kravene. De kaldes også “elastiske” af denne grund.
Her behøver udviklere ikke dedikeret tid til at indstille de automatiske skaleringssystemer eller politikker eller tune dem. Den cloud-udbyder, du har valgt, er ansvarlig for at administrere alt det. Derudover kan udviklere fra små teams også køre deres kode selv uden at kræve supportingeniører eller infrastruktur.
Reduceret latenstid
Da apps ikke hostes over en enkelt oprindelsesserver, kan du køre koden hvor som helst. Hvis den cloud-udbyder, du har valgt, understøtter det, kan du køre app-funktioner på en server tæt på slutbrugerne. Derfor pådrager det sig mindre latenstid på grund af reduceret afstand mellem brugeranmodninger og server.
Produktivitet
Den serverløse model hjælper med at forbedre dine udvikleres produktivitet, da de ikke skal håndtere serveradministration. Desuden behøver de ikke at tænke på at administrere HTTP-anmodninger eller multithreading i deres kode direkte.
Som et resultat forenkler det backend-udvikling, alt takket være FaaS, hvor eksponeret kode er hændelsesdrevne funktioner. Alle disse sparer den tid, de kan bruge på at forbedre koden og applikationen.
Hurtigere appimplementering
Med serverløs udfører udviklere ikke backend-konfiguration eller uploader kode til serveren for at implementere en appversion. De kan også hurtigt uploade koden i bits for at frigive nye produkter.
De har også fleksibiliteten til at implementere kode på én gang eller fungere efter hinanden, da det ikke er en monolitisk arkitektur. Derudover kan du reparere, opdatere, tilføje funktioner eller rette fejl fra en app hurtigt.
Andre fordele omfatter grøn computing på grund af reduceret energiforbrug med on-demand-servere, opbygning af en app, der bliver nemmere med indbyggede integrationer, hurtigere time-to-market og meget mere.
Ulemper 👎
Lad os nu se på ulemperne ved serverløs computing:
Ydeevne
Nogle gange kan serverløs kode, der bruges mindre hyppigt, udvise mere responsforsinkelse end dem, der kører kontinuerligt på dedikerede servere, softwarecontainere eller virtuelle maskiner (VM). Det er fordi det kan have brug for mere tid til at starte forfra og skabe ekstra latency.
Svært at fejlfinde og teste
Du skal vide, hvordan din kode fungerer, når du implementerer den. Til dette skal du teste det, hvilket er udfordrende i et serverløst miljø. Da udviklere mangler synlighed i hver backend-proces, og apps er opdelt i mindre funktioner, bliver fejlfinding kompliceret.
Sikkerhedsproblemer
Nye og avancerede cybersikkerhedsproblemer vokser. Men det er ikke muligt helt at kende eller måle cloududbyderens sikkerhed. Så når de håndterer hele din backend med følsomme data gemt på applikationer, er det risikabelt.
Ikke egnet til langvarige ansøgningsprocesser
Serverløs er omkostningseffektiv, men ikke til alle typer applikationer. Hvis du har en applikation med langvarige processer, kan omkostningerne ved at køre den baseret på tiden og de tildelte ressourcer være meget høje. På dette tidspunkt vil du måske gå videre med en dedikeret serverhosting.
Andre ulemper ved serverløs er problemer med at skifte fra en leverandør til en anden og privatlivsproblemer.
Terminologier, der er vigtige i serverløs arkitektur
Serverløs er aldrig komplet uden at tale om nogle vigtige terminologier relateret til det. FaaS og BaaS er to af de mest fremtrædende ideer, der førte til udviklingen af serverløs, vi kender i dag. Og for at bygge et serverløst system har du brug for en database, et lagersystem, en teknologistack, et framework og så videre. Så lad os diskutere lidt om dem.
Function as a Service (FaaS)
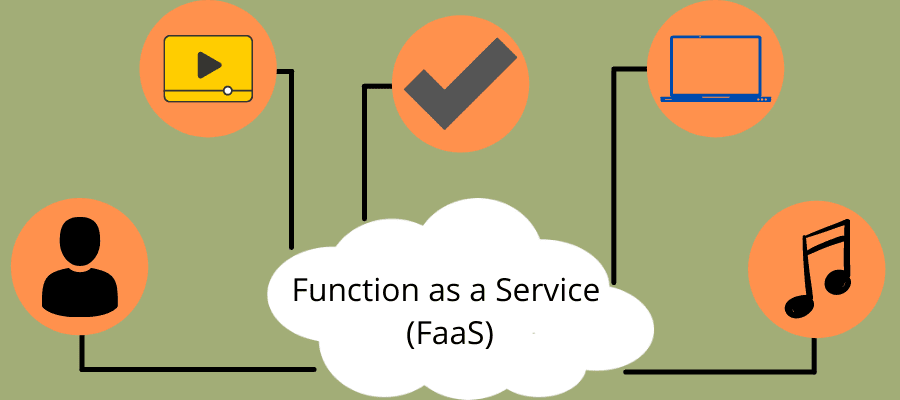
FaaS er en central idé i serverløs og fungerer som sin undergruppe. Denne hændelsesdrevne kodeeksekveringsmodel (apps, der kører som svar på en anmodning) lader dig skrive logik implementeret i softwarecontainere, eksekveret on-demand, og en cloudplatform administrerer den.
Hvis du sammenligner det med BaaS, giver FaaS mere kontrol til udviklere med at skabe brugerdefinerede apps i stedet for at være afhængige af biblioteker, der indeholder præ-lavet kode.
Softwarebeholderne, hvor koden er implementeret, er statsløse for at forenkle dataintegration, og koden kører i kortere tid. Desuden kan udviklere påberåbe sig serverløse applikationer via API’er ved hjælp af FaaS, som cloud-udbyderne administrerer via en API Gateway.
Backend-as-a-Service (BaaS)
BaaS ligner FaaS, fordi de begge har brug for en tredjepartstjenesteudbyder. I denne model leverer en cloud-udbyder backend-tjenester som datalagring for at hjælpe udviklere med at fokusere på at skrive deres frontend-kode. BaaS-applikationer er dog muligvis ikke hændelsesdrevne eller køre på kanten som med serverløse apps.
Et godt eksempel for BaaS er AWS Lambda. Udviklere bruger serverløs kode i containere med Lambda, der giver retningslinjer, der skal følges, mens de indsender koden. Det automatiserer også processer ved indtastning af koden i softwarebeholdere og tilbyder en administreret service.
Serverløs stak
Som med andre softwareteknologier kommer serverløs arkitektur også med en teknologistack. Det samler forskellige komponenter, der er afgørende for at skabe et serverløst system eller applikation.
Den serverløse stak inkluderer:
- Et programmeringssprog: Det programmeringssprog, som udviklerne vil skrive koden på. Afhængigt af leverandøren kan du vælge mellem Java, JavaScript, Python, C#, Go, Node.js, F# osv.
- En serverløs ramme: En ramme giver skelettet eller strukturen til koden. Der er masser af serverløse rammer, så du kan komme i gang. Det gør det muligt at bygge, pakke og kompilere kode og endelig til cloud-implementering. Serverløse rammer fremskynder kodningsprocessen og forenkler skalering med reduceret konfigurationstid. Eksempler på serverframeworks er Apex, AWS Serverless Application Model osv.
- Serverløse databaser: De bruges til at gemme data, som koden kræver for at få adgang til. De er også nødvendige for at interagere med funktioner til triggere. Disse databaser opfører sig som serverløse funktioner, men lagrer data på ubestemt tid. Eksempler på serverløse databaser er DynamoDB, Azure Cosmos DB, Aurora Serverless og Cloud Firestore.
- Et sæt triggere: De hjælper med at starte kodeudførelsen som HTTP-anmodninger
- Softwarecontainere: De styrker den serverløse model og tilbyder containeriserede mikrotjenester uden kompleksitet. De fungerer også som et lager for din kode og letter udviklere, mens de skriver koden til flere platforme såsom desktop eller iOS.
- API-gateways: De fungerer som en proxy til webhandlinger. De tilbyder HTTP-routing, hastighedsgrænser, visning af API-brug og svarlogfiler, klient-id osv.
Hvordan implementerer man en serverløs model og optimerer den?
At blive serverløs vil medføre betydelige ændringer med hensyn til dine applikationer, teknologi, omkostninger, sikkerhed og fordele.
Antag, at du er en nystartet virksomhed eller en lille virksomhed. I så fald vil det fremskynde din time-to-market og hjælpe dig med at skubbe opdateringer hurtigt med forenklet test, fejlretning, indsamling af feedback, arbejde med problemer og mere for at tilbyde en poleret applikation til brugerne.
Hvis du er en større organisation, vil du opleve fordele som mere skalerbarhed for at tilfredsstille dine brugerkrav, men det vil kræve betydelige omkostningsinvesteringer.
Derfor er det bedst at måle fordele og ulemper ved serverløs specifikt til din virksomhedstype og krav og derefter fortsætte. Og hvis du mener det seriøst, så start med:
- Forstå dine behov og identificere en passende serverløs teknologistack
- Vælg en serverløs leverandør såsom Google Cloud Functions, Azure Functions, AWS Lambda osv.
- Giv dit team kraftfulde værktøjer til at overvåge systemets ydeevne og funktioner. Hold øje med det samlede antal anmodninger, gasspjæld, fejlantal, succesrater, anmodningsvarighed og latens.
Serverløse leverandører

Der er mange serverløse leverandører eller cloud-udbydere derude på markedet, som du kan vælge imellem. Nogle af de bedste er:
- AWS Lambda: Det er perfekt til organisationer, der allerede udnytter AWS-tjenester. Den integreres med en bred vifte af tjenester til lagring, streaming og databaser.
- Microsoft Azure-funktioner: Hvis du bruger Visual Studio Code, skal du gå efter det. Det fungerer problemfrit med DevOps og Azure Pipelines til CI/CD. Den understøtter også holdbare funktioner til stateful funktioner og tilbyder integreret overvågning.
- Google Cloud-funktioner: Hvis du bruger Google-tjenester, er det godt. Den understøtter JS-, Go- og Python-apps, gør det muligt at udløse funktioner fra Google Assistant eller GCP og tilbyder indbygget skalering.
- IBM Cloud Functions: Hvis du vil gå efter en serverløs model baseret på Apache OpenWhisk, er IBM Cloud Functions noget for dig. Det inkluderer fremragende ydeevneovervågning, hændelsesudløsning fra en REST API eller IBM cloud-tjenester og integreres med IBM’s API Gateway til at administrere slutpunkter.
- Knative: Hvis du kører tjenester på Kubernetes, så gå efter det. Det bakkes op af Google, Red Hat, IBM osv.
- Cloudflare Workers: Det er godt for apps, der kræver høj reaktionsevne, især JavaScript-apps. Det understøtter Workers KV til datalagring og WebAssembly for at hjælpe dig med at kompilere og levere flere sprog. Dets høje distributionsnetværk med 193 datacentre forbedrer også latens og reaktionsevne.
Konklusion: Fremtiden for serverløs
Serverløs computing udvikler sig med den stigende efterspørgsel efter meget skalerbare applikationer. Det giver også mange fordele, som cloud computing tilbyder, såsom mere bekvemmelighed, omkostningseffektivitet, højere produktivitet og mere.
Ifølge en O’Reilly undersøgelse40 % af de adspurgte arbejder i virksomheder, der har taget serverløs arkitektur til sig.
Selvom serverløs stadig har visse bekymringer, såsom latenstid på grund af koldstart, test, fejlretning osv., arbejder cloud-udbydere på dem. Snart kan en mere raffineret form for serverløs dukke op med flere fordele og løste problemer. Derfor forventes populariteten og brugen af den serverløse model at stige i fremtiden.
Du kan også være interesseret i: 7 måder, serverløs computing er en stigende teknologi