

MapReduce tilbyder en effektiv, hurtigere og omkostningseffektiv måde at skabe applikationer på.
Denne model anvender avancerede koncepter såsom parallel bearbejdning, datalokalitet osv., for at give masser af fordele til programmører og organisationer.
Men der findes så mange programmeringsmodeller og rammer på markedet, at det bliver svært at vælge.
Og når det kommer til Big Data, kan du ikke bare vælge hvad som helst. Du skal vælge sådanne teknologier, der kan håndtere store bidder af data.
MapReduce er en fantastisk løsning på det.
I denne artikel vil jeg diskutere, hvad MapReduce egentlig er, og hvordan det kan være gavnligt.
Lad os begynde!
Indholdsfortegnelse
Hvad er MapReduce?
MapReduce er en programmeringsmodel eller softwareramme inden for Apache Hadoop-rammerne. Det bruges til at skabe applikationer, der er i stand til at behandle massive data parallelt på tusindvis af noder (kaldet klynger eller gitter) med fejltolerance og pålidelighed.
Denne databehandling sker på en database eller et filsystem, hvor dataene er gemt. MapReduce kan arbejde med et Hadoop-filsystem (HDFS) for at få adgang til og administrere store datamængder.
Denne ramme blev introduceret i 2004 af Google og er populær af Apache Hadoop. Det er et behandlingslag eller en motor i Hadoop, der kører MapReduce-programmer udviklet på forskellige sprog, inklusive Java, C++, Python og Ruby.
MapReduce-programmerne i cloud computing kører parallelt og er således velegnede til at udføre dataanalyse i stor skala.
MapReduce sigter mod at opdele en opgave i mindre, flere opgaver ved hjælp af funktionerne “kort” og “reducer”. Det vil kortlægge hver opgave og derefter reducere den til flere tilsvarende opgaver, hvilket resulterer i mindre processorkraft og overhead på klyngenetværket.
Eksempel: Antag, at du forbereder et måltid til et hus fyldt med gæster. Så hvis du forsøger at tilberede alle retterne og gøre alle processerne selv, bliver det hektisk og tidskrævende.
Men antag, at du involverer nogle af dine venner eller kolleger (ikke gæster) for at hjælpe dig med at forberede måltidet ved at distribuere forskellige processer til en anden person, der kan udføre opgaverne samtidigt. I så fald vil du tilberede måltidet meget hurtigere og nemmere, mens dine gæster stadig er i huset.
MapReduce arbejder på lignende måde med distribuerede opgaver og parallel behandling for at muliggøre en hurtigere og nemmere måde at udføre en given opgave på.
Apache Hadoop giver programmører mulighed for at bruge MapReduce til at udføre modeller på store distribuerede datasæt og bruge avanceret maskinlæring og statistiske teknikker til at finde mønstre, lave forudsigelser, spotte korrelationer og mere.
Funktioner i MapReduce
Nogle af hovedfunktionerne i MapReduce er:
- Brugergrænseflade: Du får en intuitiv brugergrænseflade, der giver rimelige detaljer om hvert rammeaspekt. Det hjælper dig med at konfigurere, anvende og justere dine opgaver problemfrit.

- Nyttelast: Applikationer bruger Mapper- og Reducer-grænseflader til at aktivere kortet og reducere funktioner. Mapper kortlægger input-nøgle-værdi-par til mellemliggende nøgle-værdi-par. Reducer bruges til at reducere mellemliggende nøgle-værdi-par, der deler en nøgle med andre mindre værdier. Den udfører tre funktioner – sorter, bland og reducer.
- Partitioner: Den styrer opdelingen af de mellemliggende kort-outputtaster.
- Reporter: Det er en funktion til at rapportere fremskridt, opdatere tællere og indstille statusmeddelelser.
- Tællere: Det repræsenterer globale tællere, som en MapReduce-applikation definerer.
- OutputCollector: Denne funktion indsamler outputdata fra Mapper eller Reducer i stedet for mellemudgange.
- RecordWriter: Den skriver dataoutput eller nøgleværdipar til outputfilen.
- DistributedCache: Den distribuerer effektivt større, skrivebeskyttede filer, der er applikationsspecifikke.
- Datakomprimering: Applikationsskriveren kan komprimere både joboutput og mellemkortoutput.
- Overspringning af dårlige poster: Du kan springe flere dårlige poster over, mens du behandler dine kortinput. Denne funktion kan styres gennem klassen – SkipBadRecords.
- Debugging: Du får mulighed for at køre brugerdefinerede scripts og aktivere fejlretning. Hvis en opgave i MapReduce mislykkes, kan du køre dit debug-script og finde problemerne.
MapReduce Architecture
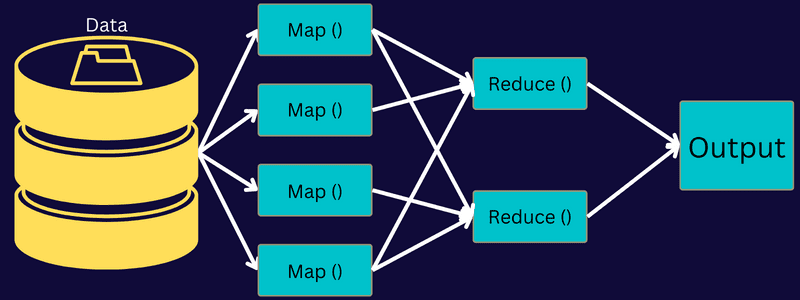
Lad os forstå arkitekturen i MapReduce ved at gå dybere ind i dets komponenter:
- Job: Et job i MapReduce er den egentlige opgave, som MapReduce-klienten ønsker at udføre. Det omfatter flere mindre opgaver, der tilsammen danner den endelige opgave.
- Jobhistorikserver: Det er en dæmonproces at gemme og gemme alle historiske data om en applikation eller opgave, såsom logfiler, der er genereret efter eller før udførelse af et job.
- Klient: En klient (program eller API) bringer et job til MapReduce til udførelse eller behandling. I MapReduce kan en eller flere klienter kontinuerligt sende job til MapReduce Manager til behandling.
- MapReduce Master: En MapReduce Master opdeler et job i flere mindre dele og sikrer, at opgaverne skrider frem samtidigt.
- Jobdele: Underjob eller jobdele opnås ved at dele det primære job. De arbejdes på og kombineres til sidst for at skabe den endelige opgave.
- Inputdata: Det er datasættet, der føres til MapReduce til opgavebehandling.
- Outputdata: Det er det endelige resultat opnået, når opgaven er behandlet.
Så hvad der virkelig sker i denne arkitektur er, at klienten sender et job til MapReduce Master, som deler det op i mindre, lige store dele. Dette gør det muligt for jobbet at blive behandlet hurtigere, da mindre opgaver tager mindre tid at få behandlet i stedet for større opgaver.
Sørg dog for, at opgaverne ikke er opdelt i for små opgaver, for hvis du gør det, kan du blive nødt til at stå over for en større overhead med at håndtere opdelinger og spilde betydelig tid på det.
Dernæst gøres jobdelene tilgængelige for at fortsætte med kort- og reduktionsopgaverne. Desuden har Kort og Reducer opgaverne et passende program baseret på den use case, som teamet arbejder på. Programmøren udvikler den logikbaserede kode for at opfylde kravene.
Herefter føres inputdataene til kortopgaven, så kortet hurtigt kan generere output som et nøgleværdi-par. I stedet for at gemme disse data på HDFS, bruges en lokal disk til at gemme dataene for at eliminere chancen for replikering.
Når opgaven er fuldført, kan du smide outputtet væk. Derfor vil replikering blive en overkill, når du gemmer outputtet på HDFS. Outputtet fra hver kortopgave vil blive ført til reduktionsopgaven, og kortoutputtet vil blive leveret til maskinen, der kører reduktionsopgaven.
Dernæst vil outputtet blive flettet og videregivet til reduktionsfunktionen defineret af brugeren. Til sidst vil det reducerede output blive gemt på en HDFS.
Desuden kan processen have flere Map og Reduce opgaver til databehandling afhængigt af slutmålet. Kort- og Reducer-algoritmerne er optimeret til at holde tids- eller rumkompleksiteten på et minimum.
Da MapReduce primært involverer Map- og Reduce-opgaver, er det relevant at forstå mere om dem. Så lad os diskutere faserne af MapReduce for at få en klar idé om disse emner.
Faser af MapReduce
Kort
Inputdataene kortlægges i output- eller nøgleværdiparrene i denne fase. Her kan nøglen referere til id’et for en adresse, mens værdien kan være den faktiske værdi af denne adresse.
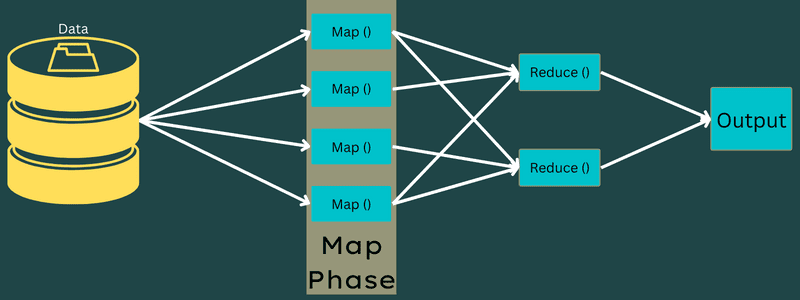
Der er kun én men to opgaver i denne fase – opdelinger og kortlægning. Opdelinger betyder underdelene eller jobdelene adskilt fra hovedjobbet. Disse kaldes også input splits. Så en input split kan kaldes en input chunk forbrugt af et kort.
Dernæst finder kortlægningsopgaven sted. Det betragtes som den første fase, mens man udfører et kort-reducer program. Her vil data indeholdt i hver opdeling blive sendt til en kortfunktion for at behandle og generere output.
Funktionen – Map() udføres i hukommelseslageret på inputnøgleværdi-parrene og genererer et mellemliggende nøgleværdipar. Dette nye nøgle-værdi-par vil fungere som input, der skal føres til funktionen Reduce() eller Reducer.
Reducere
De mellemliggende nøgle-værdi-par opnået i kortlægningsfasen fungerer som input til Reducer-funktionen eller Reducer. I lighed med kortlægningsfasen er der to opgaver involveret – blande og reducere.
Så de opnåede nøgleværdi-par sorteres og blandes for at blive ført til Reduceren. Dernæst grupperer eller aggregerer Reducer dataene i henhold til dets nøgle-værdi-par baseret på den reduktionsalgoritme, som udvikleren har skrevet.
Her kombineres værdierne fra blandefasen for at returnere en outputværdi. Denne fase opsummerer hele datasættet.
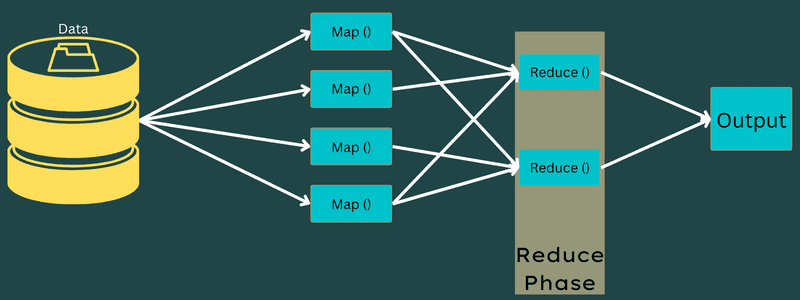
Nu styres hele processen med at udføre kort- og reduktionsopgaver af nogle entiteter. Disse er:
- Job Tracker: Med enkle ord fungerer en job tracker som en mester, der er ansvarlig for at udføre et indsendt job fuldstændigt. Jobtrackeren styrer alle job og ressourcer på tværs af en klynge. Derudover planlægger jobsporingen hvert kort, der tilføjes på opgavesporingen, der kører på en specifik dataknude.
- Flere opgavesporere: Med enkle ord fungerer flere opgavesporere som slaver, der udfører opgaven efter instruktionen fra Job Trackeren. En opgavesporing er implementeret på hver node separat i klyngen, der udfører kort- og reduktionsopgaverne.
Det virker, fordi et job vil blive opdelt i flere opgaver, der vil køre på forskellige data noder fra en klynge. Jobtrackeren er ansvarlig for at koordinere opgaven ved at planlægge opgaverne og køre dem på flere dataknudepunkter. Dernæst udfører Task Tracker, der sidder på hver dataknude, dele af jobbet og ser efter hver opgave.
Endvidere sender Task Trackers statusrapporter til jobtrackeren. Opgavesporingen sender også periodisk et “hjerteslag”-signal til jobsporingen og giver dem besked om systemstatus. I tilfælde af fejl, er en jobtracker i stand til at omplanlægge jobbet på en anden opgavetracker.
Outputfase: Når du når denne fase, vil du have de endelige nøgle-værdi-par genereret fra Reducer. Du kan bruge en outputformater til at oversætte nøgleværdi-parrene og skrive dem til en fil ved hjælp af en pladeskriver.
Hvorfor bruge MapReduce?
Her er nogle af fordelene ved MapReduce, der forklarer grundene til, hvorfor du skal bruge det i dine big data-applikationer:
Parallel behandling
Du kan opdele et job i forskellige noder, hvor hver node samtidig håndterer en del af dette job i MapReduce. Så opdeling af større opgaver i mindre mindsker kompleksiteten. Da forskellige opgaver kører parallelt i forskellige maskiner i stedet for en enkelt maskine, tager det væsentligt mindre tid at behandle dataene.
Datalokalitet
I MapReduce kan du flytte processorenheden til data, ikke omvendt.
På traditionelle måder blev dataene bragt til behandlingsenheden til behandling. Men med den hurtige vækst af data begyndte denne proces at give mange udfordringer. Nogle af dem var højere omkostninger, mere tidskrævende, belastning af masterknudepunktet, hyppige fejl og reduceret netværksydelse.
Men MapReduce hjælper med at overvinde disse problemer ved at følge en omvendt tilgang – at bringe en behandlingsenhed til data. På denne måde bliver dataene fordelt mellem forskellige noder, hvor hver node kan behandle en del af de lagrede data.
Som et resultat giver det omkostningseffektivitet og reducerer behandlingstiden, da hver node arbejder parallelt med dens tilsvarende datadel. Da hver node desuden behandler en del af disse data, vil ingen node blive overbebyrdet.
Sikkerhed

MapReduce-modellen tilbyder højere sikkerhed. Det hjælper med at beskytte din applikation mod uautoriserede data, samtidig med at klyngesikkerheden forbedres.
Skalerbarhed og fleksibilitet
MapReduce er en yderst skalerbar ramme. Det giver dig mulighed for at køre applikationer fra flere maskiner ved at bruge data med tusindvis af terabyte. Det giver også fleksibiliteten til at behandle data, der kan være strukturerede, semi-strukturerede eller ustrukturerede og af ethvert format eller størrelse.
Enkelhed
Du kan skrive MapReduce-programmer i et hvilket som helst programmeringssprog som Java, R, Perl, Python og mere. Derfor er det nemt for alle at lære og skrive programmer, mens de sikrer, at deres databehandlingskrav er opfyldt.
Brug Cases af MapReduce
- Fuldtekstindeksering: MapReduce bruges til at udføre fuldtekstindeksering. Dens Mapper kan kortlægge hvert ord eller hver sætning i et enkelt dokument. Og Reducer bruges til at skrive alle de tilknyttede elementer til et indeks.
- Beregning af PageRank: Google bruger MapReduce til at beregne PageRank.
- Loganalyse: MapReduce kan analysere logfiler. Det kan opdele en stor logfil i forskellige dele eller opdele, mens kortlæggeren søger efter tilgængelige websider.
Et nøgleværdi-par vil blive ført til reduktionen, hvis en webside bliver opdaget i loggen. Her vil websiden være nøglen, og indekset “1” er værdien. Efter at have givet et nøgle-værdi-par til Reduceren, vil forskellige websider blive samlet. Det endelige output er det samlede antal hits for hver webside.

- Omvendt Web-Link Graph: Rammen finder også brug i Reverse Web-Link Graph. Her giver Map() URL-målet og kilden og tager input fra kilden eller websiden.
Dernæst samler Reduce() listen over hver kilde-URL, der er knyttet til mål-URL’en. Til sidst udsender den kilderne og målet.
- Ordoptælling: MapReduce bruges til at tælle, hvor mange gange et ord optræder i et givet dokument.
- Global opvarmning: Organisationer, regeringer og virksomheder kan bruge MapReduce til at løse problemer med global opvarmning.
For eksempel vil du måske gerne vide om havets øgede temperaturniveau på grund af global opvarmning. Til dette kan du indsamle tusindvis af data over hele kloden. Dataene kan være høj temperatur, lav temperatur, breddegrad, længdegrad, dato, klokkeslæt osv. Dette vil tage flere kort og reducere opgaver for at beregne output ved hjælp af MapReduce.
- Lægemiddelforsøg: Traditionelt arbejdede dataforskere og matematikere sammen om at formulere et nyt lægemiddel, der kan bekæmpe en sygdom. Med formidling af algoritmer og MapReduce kan it-afdelinger i organisationer nemt tackle problemer, som kun blev håndteret af Supercomputers, Ph.D. videnskabsmænd osv. Nu kan du inspicere effektiviteten af et lægemiddel for en gruppe patienter.
- Andre applikationer: MapReduce kan behandle selv store data, som ellers ikke passer ind i en relationel database. Den bruger også datavidenskabelige værktøjer og tillader at køre dem over forskellige, distribuerede datasæt, hvilket tidligere kun var muligt på en enkelt computer.
Som et resultat af MapReduces robusthed og enkelthed finder den anvendelser i militæret, erhvervslivet, videnskaben mv.
Konklusion
MapReduce kan vise sig at være et teknologisk gennembrud. Det er ikke kun en hurtigere og enklere proces, men også omkostningseffektiv og mindre tidskrævende. På grund af dets fordele og stigende brug vil det sandsynligvis opleve en højere anvendelse på tværs af brancher og organisationer.
Du kan også udforske nogle af de bedste ressourcer til at lære Big Data og Hadoop.