
Support Vector Machine er blandt de mest populære Machine Learning-algoritmer. Det er effektivt og kan træne i begrænsede datasæt. Men hvad er det?
Indholdsfortegnelse
Hvad er en Support Vector Machine (SVM)?
Support vektor maskine er en maskinlæringsalgoritme, der bruger overvåget læring til at skabe en model til binær klassificering. Det er en mundfuld. Denne artikel vil forklare SVM, og hvordan det relaterer sig til naturlig sprogbehandling. Men lad os først analysere, hvordan en støttevektormaskine fungerer.
Hvordan virker SVM?
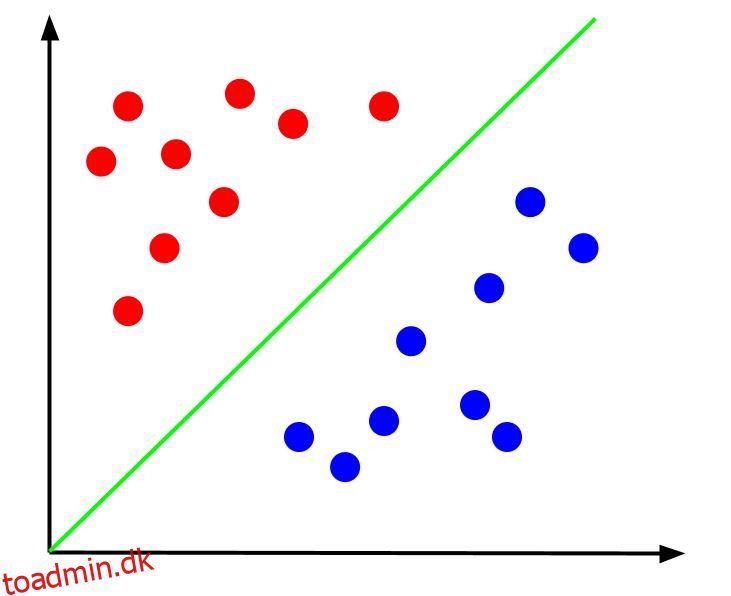
Overvej et simpelt klassifikationsproblem, hvor vi har data, der har to funktioner, x og y, og et output – en klassifikation, der enten er rød eller blå. Vi kan plotte et imaginært datasæt, der ser sådan ud:
Givet data som denne, ville opgaven være at skabe en beslutningsgrænse. En beslutningsgrænse er en linje, der adskiller de to klasser af vores datapunkter. Dette er det samme datasæt, men med en beslutningsgrænse:
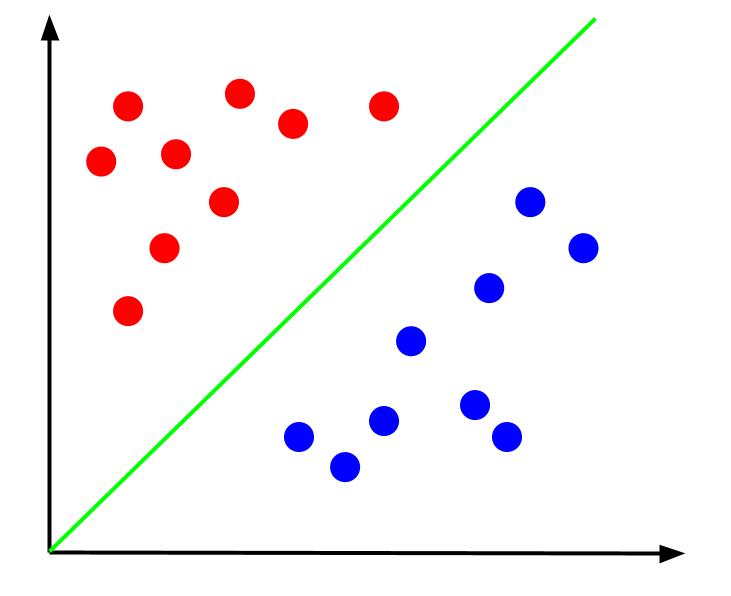
Med denne beslutningsgrænse kan vi så lave forudsigelser for, hvilken klasse et datapunkt tilhører, givet hvor det ligger i forhold til beslutningsgrænsen. Support Vector Machine-algoritmen skaber den bedste beslutningsgrænse, der vil blive brugt til at klassificere point.
Men hvad mener vi med bedste beslutningsgrænse?
Den bedste beslutningsgrænse kan hævdes at være den, der maksimerer dens afstand fra en af støttevektorerne. Støttevektorer er datapunkter i hver klasse, der er tættest på den modsatte klasse. Disse datapunkter udgør den største risiko for fejlklassificering på grund af deres nærhed til den anden klasse.
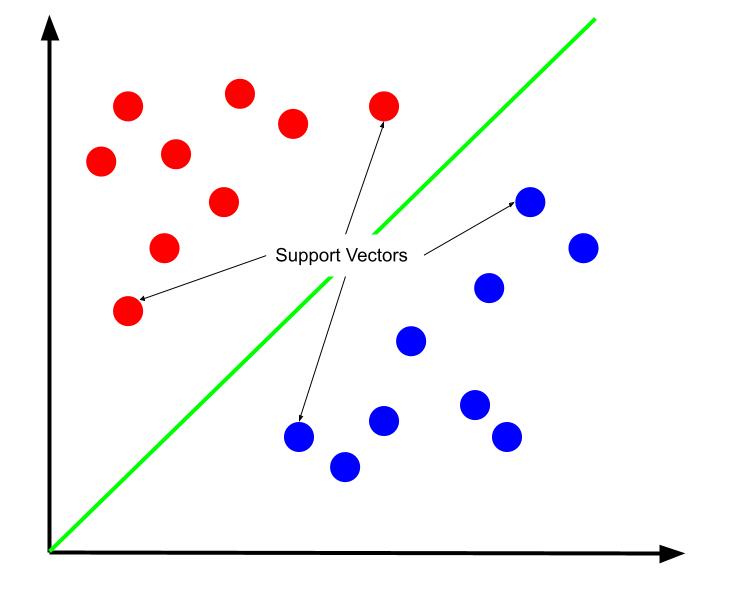
Træning af en støttevektormaskine involverer derfor at forsøge at finde en linje, der maksimerer marginen mellem støttevektorer.
Det er også vigtigt at bemærke, at fordi beslutningsgrænsen er placeret i forhold til støttevektorerne, er de de eneste determinanter for beslutningsgrænsens position. De andre datapunkter er derfor overflødige. Og således kræver træning kun støttevektorerne.
I dette eksempel er den dannede beslutningsgrænse en ret linje. Dette er kun fordi datasættet kun har to funktioner. Når datasættet har tre funktioner, er beslutningsgrænsen, der dannes, et plan snarere end en linje. Og når den har fire eller flere funktioner, er beslutningsgrænsen kendt som et hyperplan.
Ikke-lineært adskillelige data
Eksemplet ovenfor betragtede meget simple data, som, når de er plottet, kan adskilles af en lineær beslutningsgrænse. Overvej et andet tilfælde, hvor data er plottet som følger:
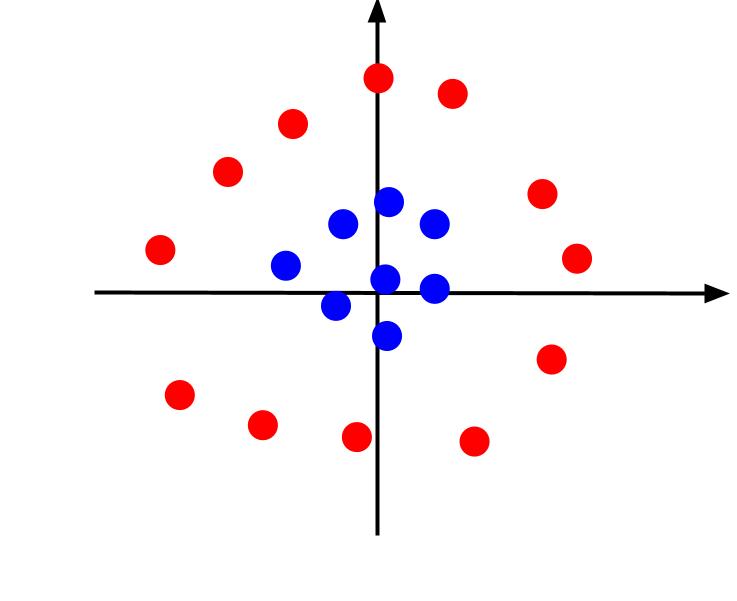
I dette tilfælde er det umuligt at adskille dataene ved hjælp af en linje. Men vi kan skabe en anden funktion, z. Og denne funktion kan defineres af ligningen: z = x^2 + y^2. Vi kan tilføje z som en tredje akse til planet for at gøre det tredimensionelt.
Når vi ser på 3D-plottet fra en vinkel, så x-aksen er vandret, mens z-aksen er lodret, er dette billedet, vi får noget, der ser sådan ud:
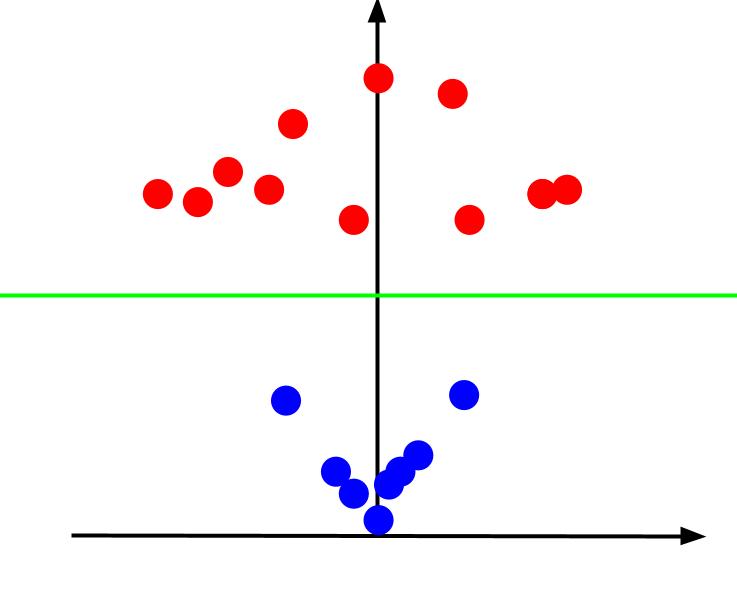
Z-værdien repræsenterer, hvor langt et punkt er fra origo i forhold til de andre punkter i det gamle XY-plan. Som følge heraf har de blå punkter tættere på oprindelsen lave z-værdier.
Mens de røde punkter længere fra oprindelsen havde højere z-værdier, giver plotning af dem mod deres z-værdier os en klar klassifikation, der kan afgrænses af en lineær beslutningsgrænse, som illustreret.
Dette er en kraftfuld idé, der bruges i Support Vector Machines. Mere generelt er det ideen om at kortlægge dimensionerne til et højere antal dimensioner, så datapunkter kan adskilles af en lineær grænse. Funktioner, der er ansvarlige for dette, er kernefunktioner. Der er mange kernefunktioner, såsom sigmoid, lineær, ikke-lineær og RBF.
For at gøre kortlægningen af disse funktioner mere effektiv bruger SVM et kernetrick.
SVM i Machine Learning
Support Vector Machine er en af de mange algoritmer, der bruges i maskinlæring sammen med populære som Decision Trees og Neurale Networks. Det foretrækkes, fordi det fungerer godt med færre data end andre algoritmer. Det bruges almindeligvis til at gøre følgende:
- Tekstklassificering: Klassificering af tekstdata såsom kommentarer og anmeldelser i en eller flere kategorier
- Ansigtsgenkendelse: Analyserer billeder for at registrere ansigter for at gøre ting som f.eks. tilføje filtre til augmented reality
- Billedklassificering: Støtte vektormaskiner kan klassificere billeder effektivt sammenlignet med andre tilgange.
Problemet med tekstklassificering
Internettet er fyldt med masser af tekstdata. Imidlertid er meget af disse data ustruktureret og umærket. For bedre at bruge disse tekstdata og forstå dem mere, er der behov for klassificering. Eksempler på tidspunkter, hvor tekst er klassificeret omfatter:
- Når tweets er kategoriseret i emner, så folk kan følge emner, de ønsker
- Når en e-mail er kategoriseret som enten Social, Kampagner eller Spam
- Når kommentarer klassificeres som værende hadefulde eller obskøne i offentlige fora
Hvordan SVM fungerer med naturlig sprogklassificering
Support Vector Machine bruges til at klassificere tekst i tekst, der hører til et bestemt emne, og tekst, der ikke hører til emnet. Dette opnås ved først at konvertere og repræsentere tekstdataene til et datasæt med flere funktioner.
En måde at gøre dette på er ved at oprette funktioner for hvert ord i datasættet. Derefter registrerer du for hvert tekstdatapunkt antallet af gange, hvert ord forekommer. Så antag, at der forekommer unikke ord i datasættet; du vil have funktioner i datasættet.
Derudover vil du give klassifikationer for disse datapunkter. Selvom disse klassifikationer er mærket med tekst, forventer de fleste SVM-implementeringer numeriske etiketter.
Derfor skal du konvertere disse etiketter til tal før træning. Når datasættet er blevet forberedt, ved at bruge disse funktioner som koordinater, kan du derefter bruge en SVM-model til at klassificere teksten.
Oprettelse af en SVM i Python
For at oprette en støttevektormaskine (SVM) i Python kan du bruge SVC-klassen fra sklearn.svm-biblioteket. Her er et eksempel på, hvordan du kan bruge SVC-klassen til at bygge en SVM-model i Python:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM model
model = SVC(kernel="linear")
# Train the model on the training data
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
I dette eksempel importerer vi først SVC-klassen fra sklearn.svm-biblioteket. Derefter indlæser vi datasættet og deler det op i trænings- og testsæt.
Dernæst opretter vi en SVM-model ved at instantiere et SVC-objekt og angive kerneparameteren som ‘lineær’. Derefter træner vi modellen på træningsdataene ved hjælp af fitmetoden og evaluerer modellen på testdataene ved hjælp af scoremetoden. Scoremetoden returnerer modellens nøjagtighed, som vi udskriver til konsollen.
Du kan også angive andre parametre for SVC-objektet, såsom C-parameteren, der styrer styrken af regulariseringen, og gamma-parameteren, som styrer kernekoefficienten for visse kerner.
Fordele ved SVM
Her er en liste over nogle fordele ved at bruge støttevektormaskiner (SVM’er):
- Effektiv: SVM’er er generelt effektive at træne, især når antallet af prøver er stort.
- Robust til støj: SVM’er er relativt robuste over for støj i træningsdataene, da de forsøger at finde den maksimale marginklassifikator, som er mindre følsom over for støj end andre klassifikatorer.
- Hukommelseseffektiv: SVM’er kræver kun, at en delmængde af træningsdataene er i hukommelsen på et givet tidspunkt, hvilket gør dem mere hukommelseseffektive end andre algoritmer.
- Effektiv i højdimensionelle rum: SVM’er kan stadig fungere godt, selv når antallet af funktioner overstiger antallet af prøver.
- Alsidighed: SVM’er kan bruges til klassificerings- og regressionsopgaver og kan håndtere forskellige typer data, herunder lineære og ikke-lineære data.
Lad os nu udforske nogle af de bedste ressourcer til at lære Support Vector Machine (SVM).
Læringsressourcer
En introduktion til support af vektormaskiner
Denne bog om Introduktion til understøttelse af vektormaskiner introducerer dig grundigt og gradvist til Kernel-baserede læringsmetoder.
Det giver dig et solidt fundament på Support Vector Machines-teorien.
Support Vector Machines-applikationer
Mens den første bog fokuserede på teorien om Support Vector Machines, fokuserer denne bog om Support Vector Machines Applications på deres praktiske anvendelser.
Den ser på, hvordan SVM’er bruges i billedbehandling, mønstergenkendelse og computersyn.
Support vektormaskiner (informationsvidenskab og statistik)
Formålet med denne bog om støttevektormaskiner (informationsvidenskab og statistik) er at give et overblik over principperne bag effektiviteten af støttevektormaskiner (SVM’er) i forskellige applikationer.
Forfatterne fremhæver flere faktorer, der bidrager til SVM’ers succes, herunder deres evne til at præstere godt med et begrænset antal justerbare parametre, deres modstandsdygtighed over for forskellige typer fejl og anomalier og deres effektive beregningsydelse sammenlignet med andre metoder.
Læring med kerner
“Learning with Kernels” er en bog, der introducerer læsere til at understøtte vektormaskiner (SVM’er) og relaterede kerneteknikker.
Det er designet til at give læserne en grundlæggende forståelse af matematik og den viden, de har brug for for at begynde at bruge kernealgoritmer i maskinlæring. Bogen har til formål at give en grundig, men tilgængelig introduktion til SVM’er og kernemetoder.
Støt vektormaskiner med Sci-kit Learn
Dette online Support Vector Machines with Sci-kit Learn-kursus af Coursera-projektnetværket lærer, hvordan man implementerer en SVM-model ved hjælp af det populære maskinlæringsbibliotek, Sci-Kit Learn.

Derudover vil du lære teorien bag SVM’er og bestemme deres styrker og begrænsninger. Kurset er på begynderniveau og tager cirka 2,5 time.
Understøtte vektormaskiner i Python: koncepter og kode
Dette betalte onlinekursus om Support Vector Machines i Python af Udemy har op til 6 timers videobaseret undervisning og kommer med en certificering.

Det dækker SVM’er og hvordan de solidt kan implementeres i Python. Desuden dækker det forretningsapplikationer af Support Vector Machines.
Machine Learning og AI: Support Vector Machines i Python
På dette kursus om Machine Learning og AI lærer du, hvordan du bruger støttevektormaskiner (SVM’er) til forskellige praktiske applikationer, herunder billedgenkendelse, spam-detektion, medicinsk diagnose og regressionsanalyse.

Du vil bruge Python-programmeringssproget til at implementere ML-modeller til disse applikationer.
Afsluttende ord
I denne artikel lærte vi kort om teorien bag Support Vector Machines. Vi lærte om deres anvendelse i Machine Learning og Natural Langauge Processing.
Vi så også, hvordan implementeringen ved hjælp af scikit-learn ser ud. Desuden talte vi om de praktiske anvendelser og fordele ved Support Vector Machines.
Selvom denne artikel kun var en introduktion, anbefalede de yderligere ressourcer at gå i detaljer og forklare mere om Support Vector Machines. I betragtning af hvor alsidige og effektive de er, er SVM’er værd at forstå for at vokse som dataforsker og ML-ingeniør.
Dernæst kan du tjekke de bedste maskinlæringsmodeller.