
Prometheus er et open source, metrik-baseret overvågningssystem. Det indsamler data fra tjenester og værter ved at sende HTTP-anmodninger på metric-endepunkter. Den gemmer derefter resultaterne i en tidsseriedatabase og gør den tilgængelig til analyse og advarsel.
Indholdsfortegnelse
Hvorfor overvåge?
- Aktiverer advarsler, når ting går galt, helst før de går galt. Så nogen kan se på det.
- Det giver indsigt for at muliggøre analyse, fejlfinding og løsning af problemet.
- Det giver dig mulighed for at se tendenser/ændringer over tid. For eksempel hvor mange aktive sessioner på et givet tidspunkt. Dette hjælper med designbeslutninger og kapacitetsplanlægning.
Overvågning vedrører normalt begivenheder. En hændelse kan omfatte modtagelse af en HTTP-anmodning, afsendelse af et svar, læsning fra disk, et brugerlogin. Overvågning af et system kan omfatte profilering, logning, sporing, metrik, alarmering og visualisering.
Blackbox vs. Whitebox overvågning
Overvågning falder ind under to hovedkategorier:
Blackbox overvågning
I Blackbox-overvågning er overvågningen på applikations- eller værtsniveau, da de observeres udefra. Dette kan være ret begrænsende.
Whitebox overvågning
Whitebox-overvågning betyder overvågning af det interne i en tjeneste. Det ville afsløre data om de interne komponenters tilstand og ydeevne.
De fire gyldne signaler
Ifølge Googlehvis du kun kan måle fire metrics af dit brugervendte system, skal du fokusere på følgende fire, kaldet de fire gyldne signaler:
#1. Reaktionstid
Den tid, det tager at betjene en anmodning – vellykket eller mislykket. Det er vigtigt at spore ikke kun vellykkede anmodninger, men også mislykkede.
#2. Trafik
Et mål for, hvor meget efterspørgsel der stilles på dit system. For en webservice er dette normalt HTTP-anmodninger pr. sekund.
#3. Fejl
Antallet af anmodninger, der mislykkes.
#4. Mætning
Hvor fuld din service er. Latensstigning er ofte en vigtig indikator for mætning. Mange systemer forringes i ydeevne meget før de opnår 100 % udnyttelse.
Prometheus-metriktyper
Prometheus-metrikker er af fire hovedtyper:
#1. Tæller
Værdien af en tæller vil altid stige. Den kan aldrig falde, men den kan nulstilles. Så hvis en skrabe fejler, betyder det kun et mistet datapunkt. Den kumulative stigning vil være tilgængelig ved næste læsning. Eksempler:
- Samlet antal modtagne HTTP-anmodninger
- Antallet af undtagelser.
#2. Målestok
En måler er et øjebliksbillede på et givet tidspunkt. Det kan både stige eller falde. Hvis en datahentning mislykkes, mister du en prøve; den næste hentning kan vise en anden værdi: eksempler på diskplads, hukommelsesbrug.
#3. Histogram
Et histogram prøver observationer og tæller dem i konfigurerbare buckets. De bruges til ting som anmodningsvarighed eller svarstørrelser. For eksempel kan du måle anmodningsvarighed for en specifik HTTP-anmodning. Histogrammet vil have et sæt buckets, f.eks. 1 ms, 10 ms og 25 ms. I stedet for at gemme hver varighed for hver anmodning, vil Prometheus gemme hyppigheden af anmodninger, der falder ind i en bestemt bøtte.
#4. Resumé
Svarende til observationer med histogramprøver, anmoder typisk om varigheder eller svarstørrelser. Det vil give en samlet optælling af observationer og en sum af alle observerede værdier, så du kan beregne gennemsnittet af observerede værdier. For eksempel havde du på et minut tre anmodninger, der tog 2,3,4 sekunder. Summen ville være 9, og antallet ville være 3. Latensen ville være 3 sekunder.
Komponenter af Prometheus økosystem
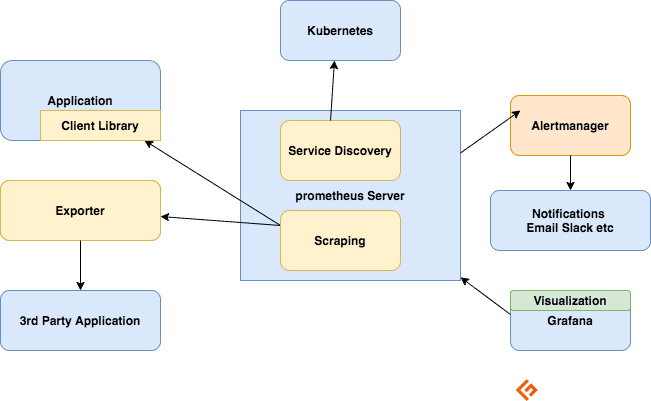
Prometheus-serveren
Indsamler metrics, gemmer dem og gør dem tilgængelige for forespørgsler, sender advarsler baseret på de indsamlede metrics.
Skrabning
Prometheus er et pull-baseret system. For at hente metrics sender Prometheus en HTTP-anmodning kaldet en scrape. Den sender skrammer til mål baseret på dens konfiguration.
Hvert mål (statisk defineret eller dynamisk opdaget) skrabes med et regelmæssigt interval (skrabeinterval). Hver scrape læser /metrics HTTP-slutpunktet for at få den aktuelle tilstand af klientmetrikkene og bevarer værdierne i Prometheus tidsseriedatabase.
Der er flere tidsseriedatabaser til overvågningsløsninger, som du måske vil udforske.
Klientbiblioteker
For at overvåge en tjeneste skal du tilføje instrumentering til din kode. Der er klientbiblioteker tilgængelige for alle populære sprog og kørselstider. Når du bruger disse biblioteker, kan din kode begynde at udsende metrics, når du tilføjer et par linjer kode. Dette kaldes direkte instrumentering. Disse biblioteker giver dig mulighed for at definere interne målinger og også eksponere dem via et HTTP-slutpunkt. Når Prometheus skraber metrics HTTP-slutpunktet, sender klientbiblioteket metrics til serveren.
Officielle klientbiblioteker tilbydes af Prometheus til Go, Java, Python og Ruby. Prometheus har et åbent økosystem. Der er også fællesskabsbyggede klientbiblioteker tilgængelige for C, PHP, Node.js, C#/.NET og mange andre.
Eksportører
Mange applikationer afslører målinger i ikke-Prometheus-format. For disse og for applikationer, som du ikke ejer, eller som du ikke har adgang til kode, kan du ikke tilføje instrumentering direkte. For eksempel MySQL, Kafka, JMX, HAProxy og NGINX server. I disse scenarier gør du brug af eksportører.
En eksportør er et værktøj, du implementerer sammen med den applikation, du vil have metrics fra. En eksportør fungerer som en proxy mellem applikationen og Prometheus. Det vil modtage anmodninger fra Prometheus-serveren, indsamle data fra adgangslogfilerne, fejllogfiler for applikationen, transformere det til det korrekte format og til sidst vende tilbage til Prometheus-serveren.
Nogle af de populære eksportører er:
- Windows – til Windows-server-metrics
- Node – til Linux-servermetrik
- Sort kasse – til DNS- og webstedsydelsesmålinger
- JMX – til Java-baserede applikationsmålinger
Når applikationerne er blevet instrumenteret, eller eksportørerne er på plads, skal du fortælle Prometheus, hvor de er. Dette kan gøres ved hjælp af statisk konfiguration. I tilfælde af dynamiske miljøer kan dette ikke lade sig gøre; derfor bruges service discovery.
Alarmer
Alarmering med Prometheus består af to dele –
Alarmeringsregler sender advarsler til Alertmanageren.
Alertmanageren administrerer derefter disse advarsler. Det udsender meddelelser ved hjælp af mange out-of-the-box integrationer som e-mail, Slack, Hipchat og PagerDuty. Alertmanageren kan også udføre lyddæmpning eller aggregering for at reducere antallet af meddelelser.
Her er guiden til overvågning af Linux-serveren ved hjælp af Prometheus og Dashboard.
Visualisering med Dashboards
Prometheus har en række API’er, hvormed PromQL-forespørgsler kan producere rådata til visualiseringer.
Selvom Prometheus inkluderer en udtryksbrowser, der kan bruges til ad hoc-forespørgsler, er det bedste tilgængelige værktøj Grafana. Grafana integreres fuldt ud med Prometheus og kan producere en bred vifte af dashboards.
Du skal konfigurere Prometheus som datakilden for Grafana.
Du kan tilføje dashboards ved at:
- Import af fællesskabsbyggede dashboards
- Byg din egen
- Brug af et foruddefineret dashboard.
Sådan ser et foruddefineret node-eksportør-dashboard ud:
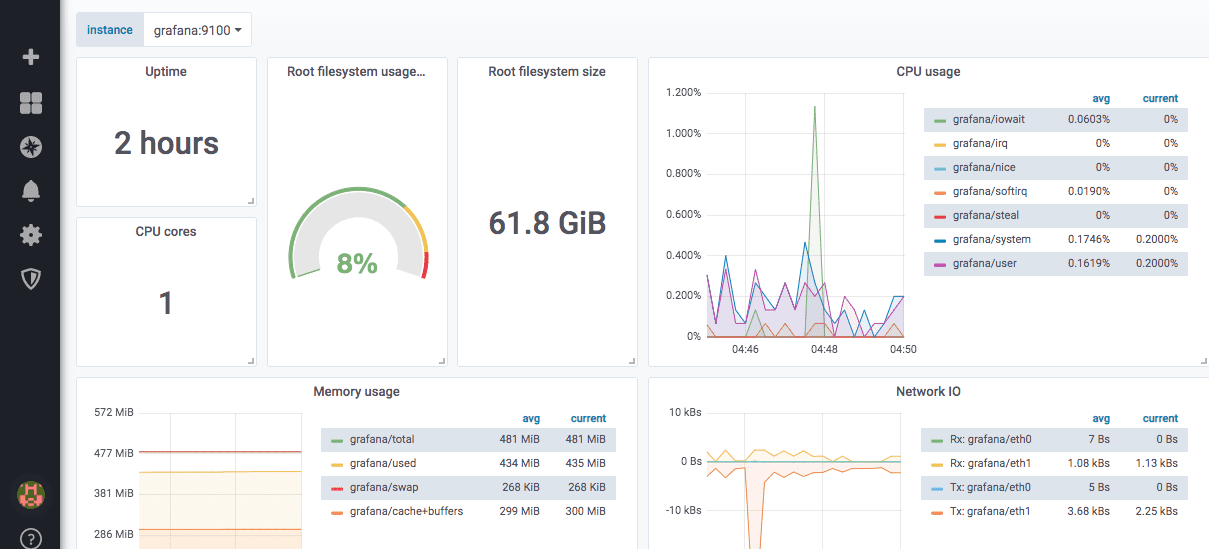
Grafana har et worldPing-modul, der lader dig overvåge site- og DNS-ydeevnemålinger over hele verden.
Resumé
Prometheus har meget få krav. Det kan være ret simpelt at køre, da det er en enkelt binær med en konfigurationsfil. Den kan håndtere tusindvis af mål og indtage millioner af prøver i sekundet. Prometheus er designet til at spore systemets overordnede system, sundhed og adfærd.
Grafana er det bedste tilgængelige værktøj til visualisering af metrikker og integreres problemfrit med Prometheus.