

Den 1. september 2020 afslørede NVIDIA sin nye serie af gaming-GPU’er: RTX 3000-serien, baseret på deres Ampere-arkitektur. Vi vil diskutere, hvad der er nyt, den AI-drevne software, der følger med, og alle de detaljer, der gør denne generation virkelig fantastisk.
Indholdsfortegnelse
Mød RTX 3000-seriens GPU’er

NVIDIAs vigtigste meddelelse var dens skinnende nye GPU’er, alle bygget på en brugerdefineret 8 nm fremstillingsproces, og alle medførte store fremskyndelser i både rasterisering og ray-tracing ydeevne.
I den lave ende af rækken er der RTX 3070, som kommer ind på $499. Det er lidt dyrt for det billigste kort, der blev afsløret af NVIDIA ved den første meddelelse, men det er en absolut tyveri, når du først finder ud af, at det slår det eksisterende RTX 2080 Ti, et top-of-the-line-kort, som regelmæssigt sælges for over $1400. Efter NVIDIAs annoncering faldt prisen på tredjepartssalget, og et stort antal af dem blev solgt i panik på eBay for under $600.
Der er ingen solide benchmarks ude fra meddelelsen, så det er uklart, om kortet virkelig objektivt set er “bedre” end en 2080 Ti, eller om NVIDIA vrider markedsføringen en smule. De benchmarks, der blev kørt, var ved 4K og havde sandsynligvis RTX på, hvilket kan få kløften til at se større ud, end den vil være i rent rasteriserede spil, da den Ampere-baserede 3000-serie vil præstere mere end dobbelt så godt ved ray-tracing end Turing. Men da ray tracing nu er noget, der ikke skader ydeevnen meget, og er understøttet i den seneste generation af konsoller, er det et stort salgsargument at få det til at køre lige så hurtigt som sidste generations flagskib til næsten en tredjedel af prisen.
Det er også uklart, om prisen forbliver sådan. Tredjepartsdesign tilføjer regelmæssigt mindst $50 til prisskiltet, og med hvor høj efterspørgsel der sandsynligvis vil være, vil det ikke være overraskende at se det sælges for $600 i oktober 2020.
Lige over det er RTX 3080 til $699, hvilket burde være dobbelt så hurtigt som RTX 2080, og komme ind omkring 25-30% hurtigere end 3080.
Så i den øverste ende er det nye flagskib RTX 3090, hvilket er komisk stort. NVIDIA er godt klar over det og omtalte det som en “BFGPU”, som firmaet siger står for “Big Ferocious GPU.”

NVIDIA viste ikke nogen direkte præstationsmålinger, men virksomheden viste, at den kører 8K-spil ved 60 FPS, hvilket er seriøst imponerende. Indrømmet, NVIDIA bruger næsten helt sikkert DLSS til at ramme det mærke, men 8K-spil er 8K-spil.
Selvfølgelig vil der i sidste ende komme en 3060 og andre varianter af mere budgetorienterede kort, men dem kommer normalt senere.
For rent faktisk at afkøle tingene havde NVIDIA brug for et fornyet kølerdesign. 3080’eren er normeret til 320 watt, hvilket er ret højt, så NVIDIA har valgt et dobbelt blæserdesign, men i stedet for at begge blæsere vwinf placeret i bunden, har NVIDIA sat en blæser i den øverste ende, hvor bagpladen normalt går. Blæseren leder luften opad mod CPU-køleren og toppen af kabinettet.

At dømme efter, hvor meget ydeevnen kan blive påvirket af dårlig luftstrøm i en sag, giver dette perfekt mening. Printkortet er dog meget trangt på grund af dette, hvilket sandsynligvis vil påvirke tredjeparts salgspriser.
DLSS: En softwarefordel
Strålesporing er ikke den eneste fordel ved disse nye kort. Virkelig, det hele er lidt af et hack – RTX 2000-serien og 3000-serien er ikke så meget bedre til at lave egentlig ray-tracing sammenlignet med ældre generationer af kort. Ray-sporing af en fuld scene i 3D-software som Blender tager normalt et par sekunder eller endda minutter pr. billede, så det er udelukket at tvinge den på under 10 millisekunder.
Selvfølgelig er der dedikeret hardware til at køre stråleberegninger, kaldet RT-kernerne, men stort set valgte NVIDIA en anden tilgang. NVIDIA forbedrede denoising-algoritmerne, som gør det muligt for GPU’erne at gengive et meget billigt enkelt pass, der ser forfærdeligt ud, og på en eller anden måde – gennem AI-magi – forvandle det til noget, som en gamer ønsker at se på. Når det kombineres med traditionelle rasteriseringsbaserede teknikker, giver det en behagelig oplevelse forstærket af raytracing-effekter.

For at gøre dette hurtigt har NVIDIA dog tilføjet AI-specifikke behandlingskerner kaldet Tensor-kerner. Disse behandler al den matematik, der kræves for at køre maskinlæringsmodeller, og gør det meget hurtigt. De er en total game-changer for AI i skyserverrummet, da AI bruges flittigt af mange virksomheder.
Ud over denoising kaldes hovedanvendelsen af Tensor-kernerne til gamere DLSS, eller deep learning super sampling. Den tager en ramme af lav kvalitet og opskalerer den til fuld-native kvalitet. Dette betyder i bund og grund, at du kan spille med 1080p-niveau framerates, mens du ser på et 4K-billede.
Dette hjælper også en del med ray-tracing ydeevne –benchmarks fra PCMag vis en RTX 2080 Super running Control i ultrakvalitet, med alle ray-tracing-indstillinger skruet til max. Ved 4K kæmper den med kun 19 FPS, men med DLSS tændt får den meget bedre 54 FPS. DLSS er gratis ydeevne til NVIDIA, muliggjort af Tensor-kernerne på Turing og Ampere. Ethvert spil, der understøtter det og er GPU-begrænset, kan se alvorlige speedups kun fra software alene.
DLSS er ikke nyt og blev annonceret som en funktion, da RTX 2000-serien blev lanceret for to år siden. På det tidspunkt blev det understøttet af meget få spil, da det krævede, at NVIDIA skulle træne og tune en maskinlæringsmodel til hvert enkelt spil.
Men i den tid har NVIDIA fuldstændig omskrevet den og kalder den nye version DLSS 2.0. Det er en generel API, hvilket betyder, at enhver udvikler kan implementere den, og den bliver allerede opfanget af de fleste større udgivelser. I stedet for at arbejde på én frame, tager den i bevægelse vektordata fra den forrige frame, på samme måde som TAA. Resultatet er meget skarpere end DLSS 1.0, og i nogle tilfælde ser det faktisk bedre og skarpere ud end selv native opløsning, så der er ikke meget grund til ikke at slå det til.
Der er én hak – når man skifter scener helt, som i mellemsekvenser, skal DLSS 2.0 gengive det allerførste billede i 50 % kvalitet, mens man venter på bevægelsesvektordataene. Dette kan resultere i et lille fald i kvaliteten i nogle få millisekunder. Men 99% af alt, hvad du ser på, vil blive gengivet korrekt, og de fleste mennesker bemærker det ikke i praksis.
Ampere Architecture: Bygget til AI
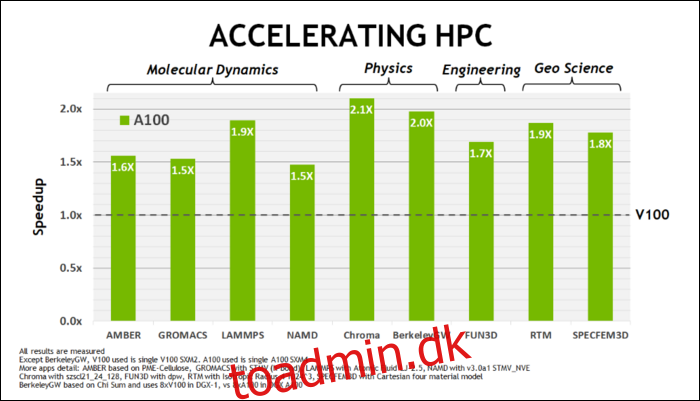
Ampere er hurtig. Seriøst hurtigt, især ved AI-beregninger. RT-kernen er 1,7x hurtigere end Turing, og den nye Tensor-kerne er 2,7x hurtigere end Turing. Kombinationen af de to er et sandt generationsspring i raytracing-ydeevne.

Tidligere i maj NVIDIA frigav Ampere A100 GPU, en datacenter-GPU designet til at køre AI. Med den detaljerede de meget af, hvad der gør Ampere så meget hurtigere. For datacenter og højtydende computerarbejdsbelastninger er Ampere generelt omkring 1,7 gange hurtigere end Turing. Til AI-træning er det op til 6 gange hurtigere.
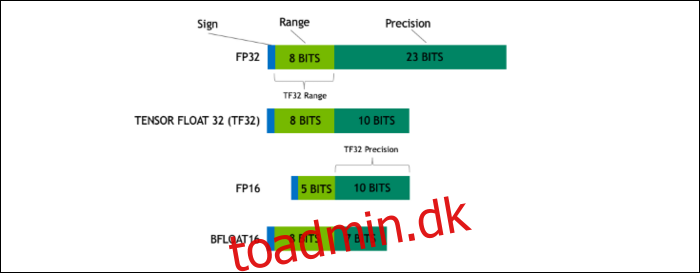
Med Ampere bruger NVIDIA et nyt talformat designet til at erstatte industristandarden “Floating-Point 32” eller FP32 i nogle arbejdsbelastninger. Under motorhjelmen fylder hvert tal, som din computer behandler, et foruddefineret antal bits i hukommelsen, uanset om det er 8 bit, 16 bit, 32, 64 eller endnu større. Tal, der er større, er sværere at behandle, så hvis du kan bruge en mindre størrelse, har du mindre at knaske.
FP32 gemmer et 32-bit decimaltal, og det bruger 8 bit til rækkevidden af tallet (hvor stort eller lille det kan være), og 23 bit til præcisionen. NVIDIAs påstand er, at disse 23 præcisionsbits ikke er helt nødvendige for mange AI-arbejdsbelastninger, og du kan få lignende resultater og meget bedre ydeevne ud af kun 10 af dem. At reducere størrelsen ned til kun 19 bit i stedet for 32, gør en stor forskel på tværs af mange beregninger.
Dette nye format hedder Tensor Float 32, og Tensor-kernerne i A100 er optimeret til at håndtere det underligt store format. Dette er, ud over formkrympninger og stigninger i antallet af kerner, hvordan de får den massive 6x speedup i AI-træning.
Oven i det nye talformat ser Ampere store ydelsesforøgelser i specifikke beregninger, såsom FP32 og FP64. Disse oversættes ikke direkte til mere FPS for lægmanden, men de er en del af det, der gør det næsten tre gange hurtigere generelt ved Tensor-operationer.

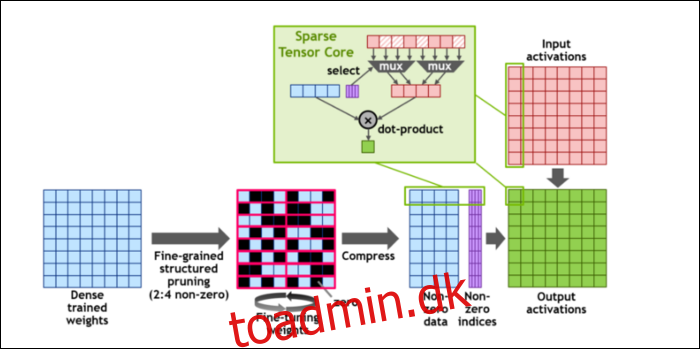
Så, for at fremskynde beregningerne endnu mere, har de introduceret begrebet finkornet struktureret sparsomhed, hvilket er et meget fancy ord for et ret simpelt koncept. Neurale netværk arbejder med store lister af tal, kaldet vægte, som påvirker det endelige output. Jo flere tal der skal knas, jo langsommere vil det være.
Men ikke alle disse tal er faktisk nyttige. Nogle af dem er bogstaveligt talt bare nul, og kan stort set smides ud, hvilket fører til massive speedups, når du kan knuse flere tal på samme tid. Sparsity komprimerer i det væsentlige tallene, hvilket kræver mindre indsats at lave beregninger med. Den nye “Sparse Tensor Core” er bygget til at fungere på komprimerede data.
På trods af ændringerne siger NVIDIA, at dette overhovedet ikke burde påvirke nøjagtigheden af trænede modeller mærkbart.
For sparse INT8-beregninger, et af de mindste talformater, er topydelsen for en enkelt A100 GPU over 1,25 PetaFLOPs, et svimlende højt tal. Det er selvfølgelig kun, når man knuser én bestemt slags tal, men det er alligevel imponerende.