
Datavidenskab er for alle, der elsker at optrevle sammenfiltrede ting og opdage skjulte vidundere i et tilsyneladende rod.
Det er som at søge efter nåle i høstakke; kun at dataforskere slet ikke behøver at få deres hænder snavset. Ved at bruge smarte værktøjer med farverige diagrammer og kigge på bunker af tal, dykker de bare ned i datahøstakke og finder værdifulde nåle i form af indsigt af høj forretningsværdi.
En typisk data scientist Værktøjskassen bør indeholde mindst ét element af hver af disse kategorier: relationelle databaser, NoSQL-databaser, big data-rammer, visualiseringsværktøjer, scraping-værktøjer, programmeringssprog, IDE’er og deep learning-værktøjer.
Indholdsfortegnelse
Relationelle databaser
En relationel database er en samling af data struktureret i tabeller med attributter. Tabellerne kan knyttes til hinanden, definere relationer og begrænsninger og skabe det, man kalder en datamodel. For at arbejde med relationelle databaser bruger du almindeligvis et sprog kaldet SQL (Structured Query Language).
De applikationer, der styrer strukturen og dataene i relationelle databaser, kaldes RDBMS (Relational DataBase Management Systems). Der er mange af sådanne applikationer, og de mest relevante er for nylig begyndt at sætte deres fokus på datavidenskab, tilføjer funktionalitet til at arbejde med big data repositories og til at anvende teknikker som dataanalyse og maskinlæring.
SQL Server
Microsofts RDBMS, har udviklet sig i mere end 20 år ved konsekvent at udvide virksomhedens funktionalitet. Siden 2016-versionen tilbyder SQL Server en portefølje af tjenester, der inkluderer understøttelse af indlejret R-kode. SQL Server 2017 hæver indsatsen ved at omdøbe sine R Services til Machine Language Services og tilføje understøttelse af Python-sproget (mere om disse to sprog nedenfor).
Med disse vigtige tilføjelser sigter SQL Server mod datavidenskabsmænd, som måske ikke har erfaring med Transact SQL, det oprindelige forespørgselssprog i Microsoft SQL Server.
SQL Server er langt fra et gratis produkt. Du kan købe licenser til at installere det på en Windows Server (prisen vil variere afhængigt af antallet af samtidige brugere) eller bruge det som en gebyrbaseret tjeneste gennem Microsoft Azure-skyen. Det er nemt at lære Microsoft SQL Server.
MySQL
På open source-softwaresiden, MySQL har popularitetskronen af RDBMS’er. Selvom Oracle i øjeblikket ejer det, er det stadig gratis og open source under betingelserne i en GNU General Public License. De fleste webbaserede applikationer bruger MySQL som det underliggende datalager, takket være dets overholdelse af SQL-standarden.
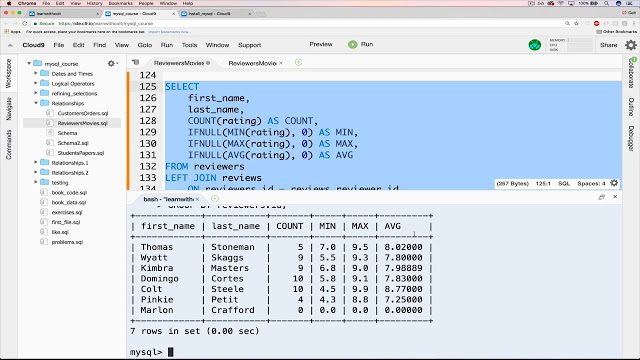
Dets lette installationsprocedurer, dets store fællesskab af udviklere, tonsvis af omfattende dokumentation og tredjepartsværktøjer, såsom phpMyAdmin, der forenkler daglige administrationsaktiviteter, hjælper også til dens popularitet. Selvom MySQL ikke har nogen indbyggede funktioner til at udføre dataanalyse, tillader dens åbenhed integration med næsten ethvert visualiserings-, rapporterings- og business intelligence-værktøj, du måtte vælge.
PostgreSQL
En anden open source RDBMS-mulighed er PostgreSQL. Selvom det ikke er så populært som MySQL, skiller PostgreSQL sig ud for dets fleksibilitet og udvidelsesmuligheder og dets understøttelse af komplekse forespørgsler, dem der går ud over de grundlæggende udsagn som SELECT, WHERE og GROUP BY.
Disse funktioner lader det vinde popularitet blandt dataforskere. En anden interessant funktion er understøttelsen af multi-miljøer, som gør det muligt at bruge det i cloud- og on-premise-miljøer eller i en blanding af begge, almindeligvis kendt som hybrid cloud-miljøer.
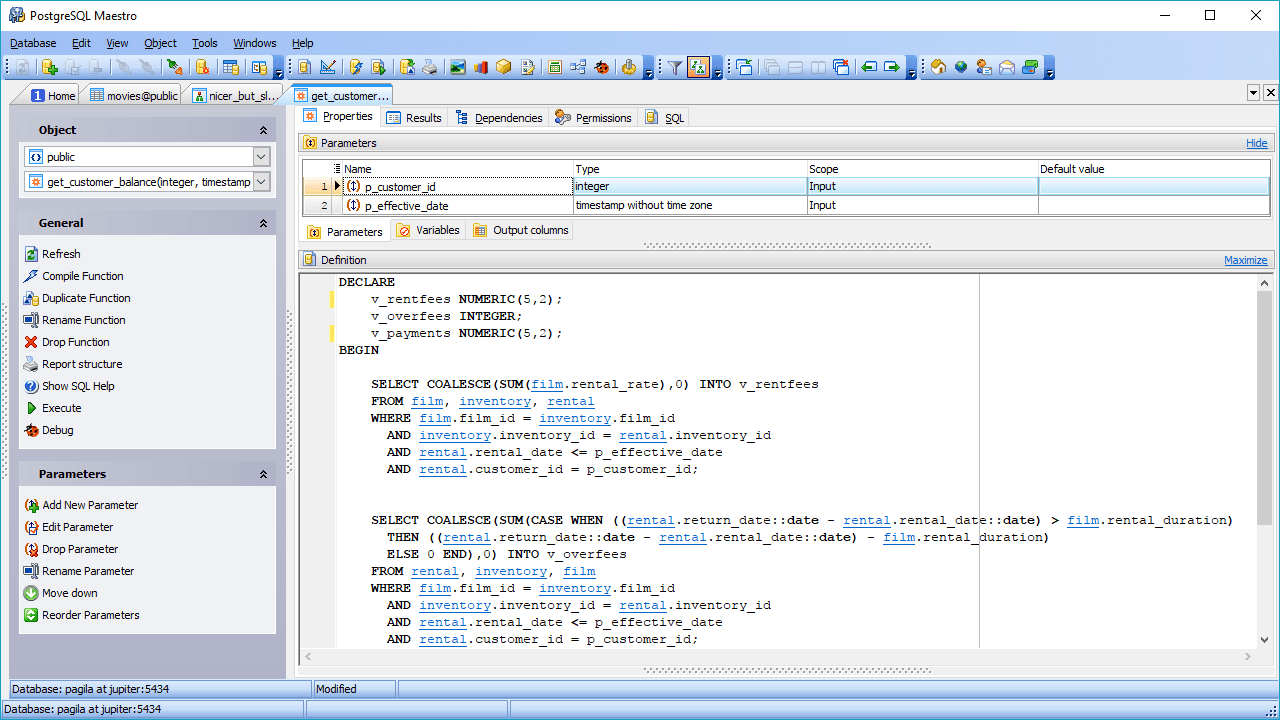
PostgreSQL er i stand til at kombinere online analytisk behandling (OLAP) med online transaktionsbehandling (OLTP), der arbejder i en tilstand kaldet hybrid transaktionel/analytisk behandling (HTAP). Den er også velegnet til at arbejde med big data, takket være tilføjelsen af PostGIS til geografiske data og JSON-B til dokumenter. PostgreSQL understøtter også ustrukturerede data, hvilket gør det muligt at være i begge kategorier: SQL- og NoSQL-databaser.
NoSQL databaser
Også kendt som ikke-relationelle databaser, giver denne type datalager hurtigere adgang til ikke-tabeldatastrukturer. Nogle eksempler på disse strukturer er grafer, dokumenter, brede kolonner, nøgleværdier, blandt mange andre. NoSQL-datalagre kan lægge datakonsistens til side til fordel for andre fordele, såsom tilgængelighed, partitionering og adgangshastighed.
Da der ikke er SQL i NoSQL-datalagre, er den eneste måde at forespørge på denne type database ved at bruge lavniveausprog, og der er ikke et sådant sprog, der er så bredt accepteret som SQL. Desuden er der ingen standardspecifikationer for NoSQL. Det er derfor, ironisk nok, nogle NoSQL-databaser begynder at tilføje understøttelse af SQL-scripts.
MongoDB
MongoDB er et populært NoSQL-databasesystem, som gemmer data i form af JSON-dokumenter. Dens fokus er på skalerbarheden og fleksibiliteten til at lagre data på en ikke-struktureret måde. Det betyder, at der ikke er en fast feltliste, som skal overholdes i alle de lagrede elementer. Ydermere kan datastrukturen ændres over tid, noget der i en relationsdatabase indebærer en høj risiko for at påvirke kørende applikationer.

Teknologien i MongoDB giver mulighed for indeksering, ad-hoc-forespørgsler og aggregering, der giver et stærkt grundlag for dataanalyse. Den distribuerede karakter af databasen giver høj tilgængelighed, skalering og geografisk distribution uden behov for sofistikerede værktøjer.
Redis
Dette en er en anden mulighed i open source, NoSQL-fronten. Det er dybest set et datastrukturlager, der opererer i hukommelsen, og udover at levere databasetjenester fungerer det også som cachehukommelse og meddelelsesmægler.

Det understøtter et utal af ukonventionelle datastrukturer, herunder hashes, geospatiale indekser, lister og sorterede sæt. Den er velegnet til datavidenskab takket være dens høje ydeevne i dataintensive opgaver, såsom computersæt-kryds, sortering af lange lister eller generering af komplekse rangeringer. Årsagen til Redis’ enestående ydeevne er dens in-memory-funktion. Det kan konfigureres til at bevare dataene selektivt.
Big Data rammer
Antag, at du skal analysere de data, Facebook-brugere genererer i løbet af en måned. Vi taler om billeder, videoer, beskeder, det hele. I betragtning af, at der hver dag tilføjes mere end 500 terabyte data til det sociale netværk af dets brugere, er det svært at måle mængden repræsenteret af en hel måneds data.
For at manipulere den enorme mængde data på en effektiv måde, har du brug for en passende ramme, der er i stand til at beregne statistik over en distribueret arkitektur. Der er to af de rammer, der fører markedet: Hadoop og Spark.
Hadoop
Som en big data-ramme, Hadoop beskæftiger sig med kompleksiteten forbundet med genfinding, bearbejdning og lagring af enorme bunker af data. Hadoop opererer i et distribueret miljø, sammensat af computerklynger, der behandler simple algoritmer. Der er en orkestreringsalgoritme, kaldet MapReduce, der opdeler store opgaver i små dele og derefter distribuerer disse små opgaver mellem tilgængelige klynger.

Hadoop anbefales til datalagre i virksomhedsklassen, der kræver hurtig adgang og høj tilgængelighed, alt det i en lavpris-ordning. Men du har brug for en Linux-administrator med dyb Hadoop viden at holde rammerne oppe og køre.
Gnist
Hadoop er ikke den eneste tilgængelige ramme for big data-manipulation. Et andet stort navn på dette område er Gnist. Spark-motoren er designet til at overgå Hadoop med hensyn til analysehastighed og brugervenlighed. Tilsyneladende nåede den dette mål: nogle sammenligninger siger, at Spark kører op til 10 gange hurtigere end Hadoop, når man arbejder på en disk, og 100 gange hurtigere i hukommelsen. Det kræver også et mindre antal maskiner at behandle den samme mængde data.

Udover hastighed er en anden fordel ved Spark dens understøttelse af strømbehandling. Denne type databehandling, også kaldet realtidsbehandling, involverer kontinuerlig input og output af data.
Visualiseringsværktøjer
En almindelig vittighed mellem dataforskere siger, at hvis du torturerer dataene længe nok, vil de indrømme, hvad du har brug for at vide. I dette tilfælde betyder “tortur” at manipulere dataene ved at transformere og filtrere dem for bedre at kunne visualisere dem. Og det er her, datavisualiseringsværktøjer kommer til scenen. Disse værktøjer tager forbehandlede data fra flere kilder og viser deres afslørede sandheder i grafiske, forståelige former.
Der er hundredvis af værktøjer, der falder ind under denne kategori. Kan du lide det eller ej, den mest brugte er Microsoft Excel og dets diagramværktøjer. Excel-diagrammer er tilgængelige for alle, der bruger Excel, men de har begrænset funktionalitet. Det samme gælder for andre regnearksapplikationer, såsom Google Sheets og Libre Office. Men vi taler her om mere specifikke værktøjer, specielt skræddersyet til business intelligence (BI) og dataanalyse.
Power BI
For kort tid siden udgav Microsoft sin Power BI visualiseringsapplikation. Det kan tage data fra forskellige kilder, såsom tekstfiler, databaser, regneark og mange online datatjenester, herunder Facebook og Twitter, og bruge det til at generere dashboards spækket med diagrammer, tabeller, kort og mange andre visualiseringsobjekter. Dashboardobjekterne er interaktive, hvilket betyder, at du kan klikke på en dataserie i et diagram for at vælge den og bruge den som et filter for de andre objekter på tavlen.
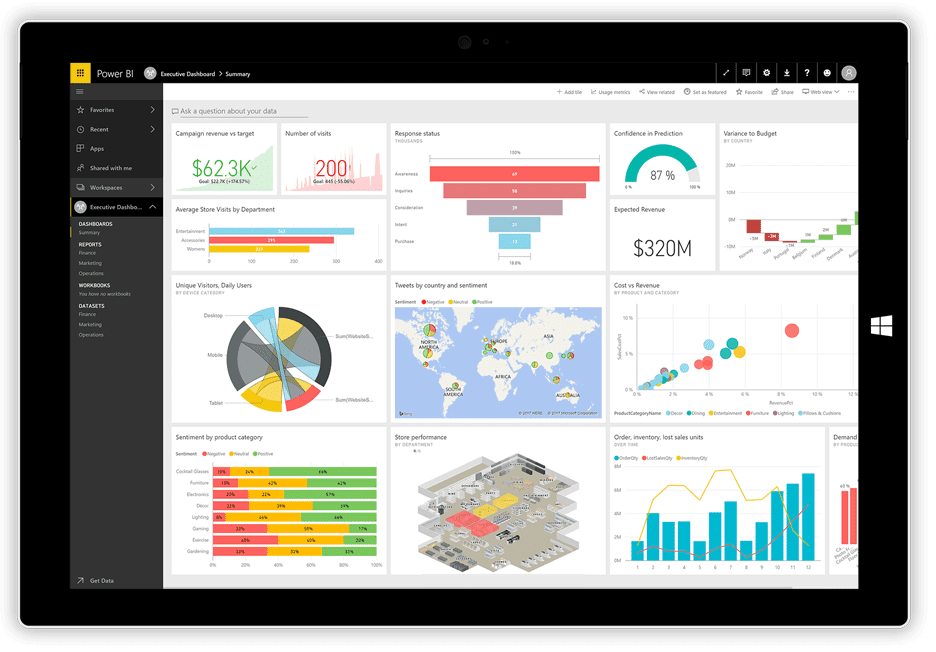
Power BI er en kombination af en Windows-desktopapplikation (en del af Office 365-pakken), en webapplikation og en onlinetjeneste til at udgive dashboards på nettet og dele dem med dine brugere. Tjenesten giver dig mulighed for at oprette og administrere tilladelser til kun at give adgang til bestyrelserne til bestemte personer.
Tableau
Tableau er en anden mulighed for at skabe interaktive dashboards fra en kombination af flere datakilder. Det tilbyder også en desktopversion, en webversion og en onlinetjeneste til at dele de dashboards, du opretter. Det fungerer naturligt “med den måde, du tænker på” (som det hævder), og det er nemt at bruge for ikke-tekniske mennesker, hvilket er forbedret gennem masser af tutorials og online videoer.
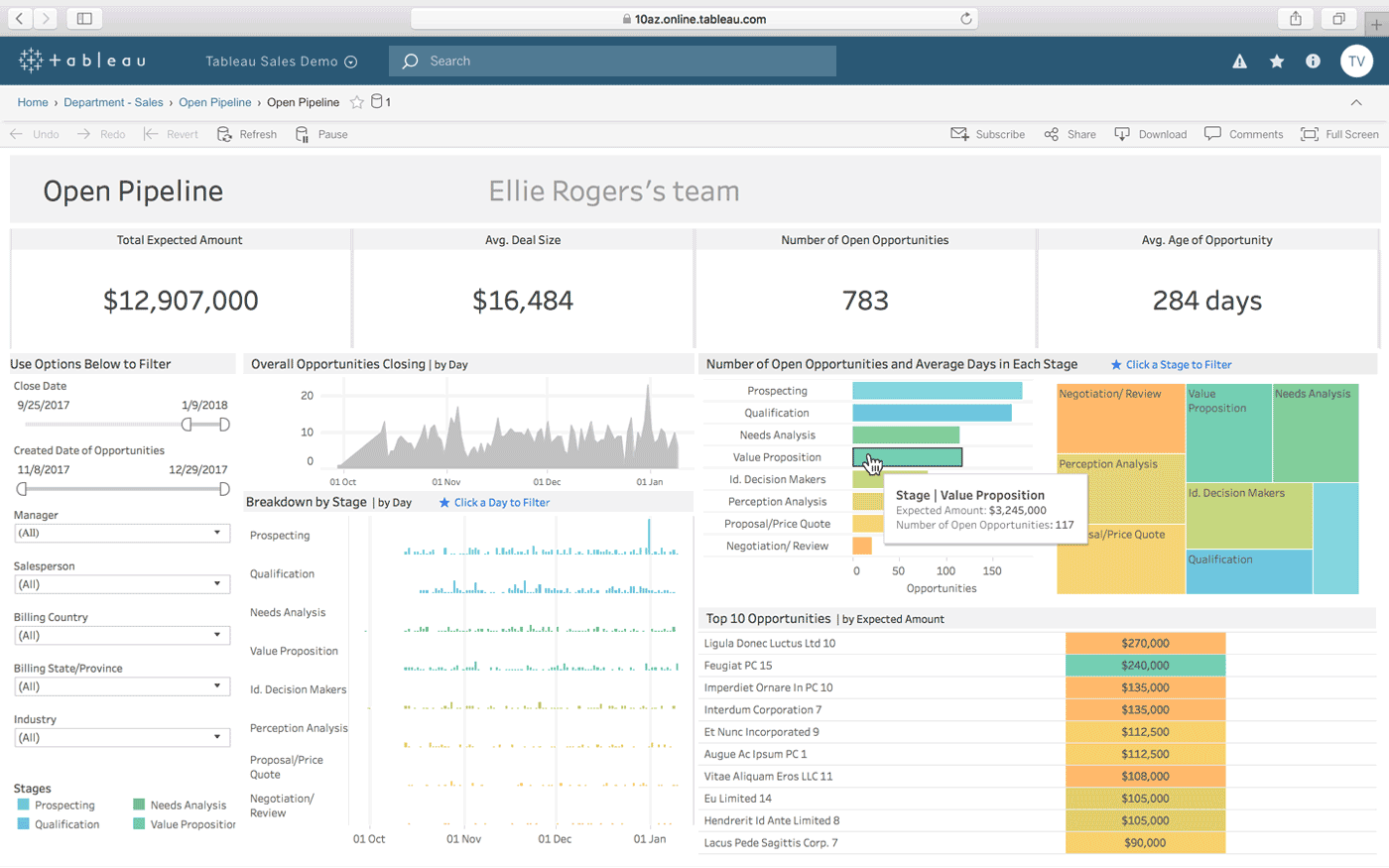
Nogle af Tableaus mest fremragende funktioner er dets ubegrænsede datastik, dets live- og hukommelsesdata og dets mobiloptimerede design.
QlikView
QlikView tilbyder en ren og ligetil brugergrænseflade til at hjælpe analytikere med at opdage ny indsigt fra eksisterende data gennem visuelle elementer, der er let forståelige for alle.
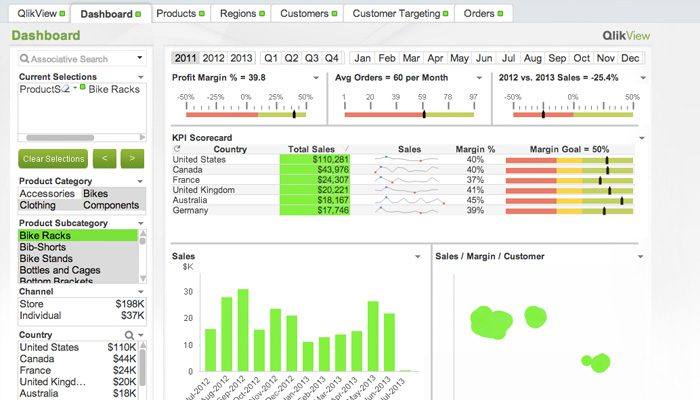
Dette værktøj er kendt for at være en af de mest fleksible business intelligence-platforme. Det giver en funktion kaldet Associative Search, som hjælper dig med at fokusere på de vigtigste data, hvilket sparer dig for den tid, det ville tage at finde dem på egen hånd.
Med QlikView kan du samarbejde med partnere i realtid og lave sammenlignende analyser. Alle de relevante data kan kombineres i én app med sikkerhedsfunktioner, der begrænser adgangen til dataene.
Skrabningsværktøj
I de tider, hvor internettet lige var ved at dukke op, begyndte webcrawlerne at rejse sammen med netværkene og indsamle information på deres måde. Efterhånden som teknologien udviklede sig, ændrede termen webcrawling sig til web-skrabning, men betyder stadig det samme: at automatisk udtrække information fra websteder. For at lave web-skrabning bruger du automatiserede processer eller bots, der springer fra en webside til en anden, udtrækker data fra dem og eksporterer dem til forskellige formater eller indsætter dem i databaser til yderligere analyse.
Nedenfor opsummerer vi egenskaberne for tre af de mest populære webskrabere, der findes i dag.
Octoparse
Octoparse web skraber tilbyder nogle interessante egenskaber, herunder indbyggede værktøjer til at få information fra websteder, der ikke gør det let for skrabe bots at udføre deres job. Det er en desktopapplikation, der ikke kræver nogen kodning, med en brugervenlig UI, der gør det muligt at visualisere udvindingsprocessen gennem en grafisk workflowdesigner.
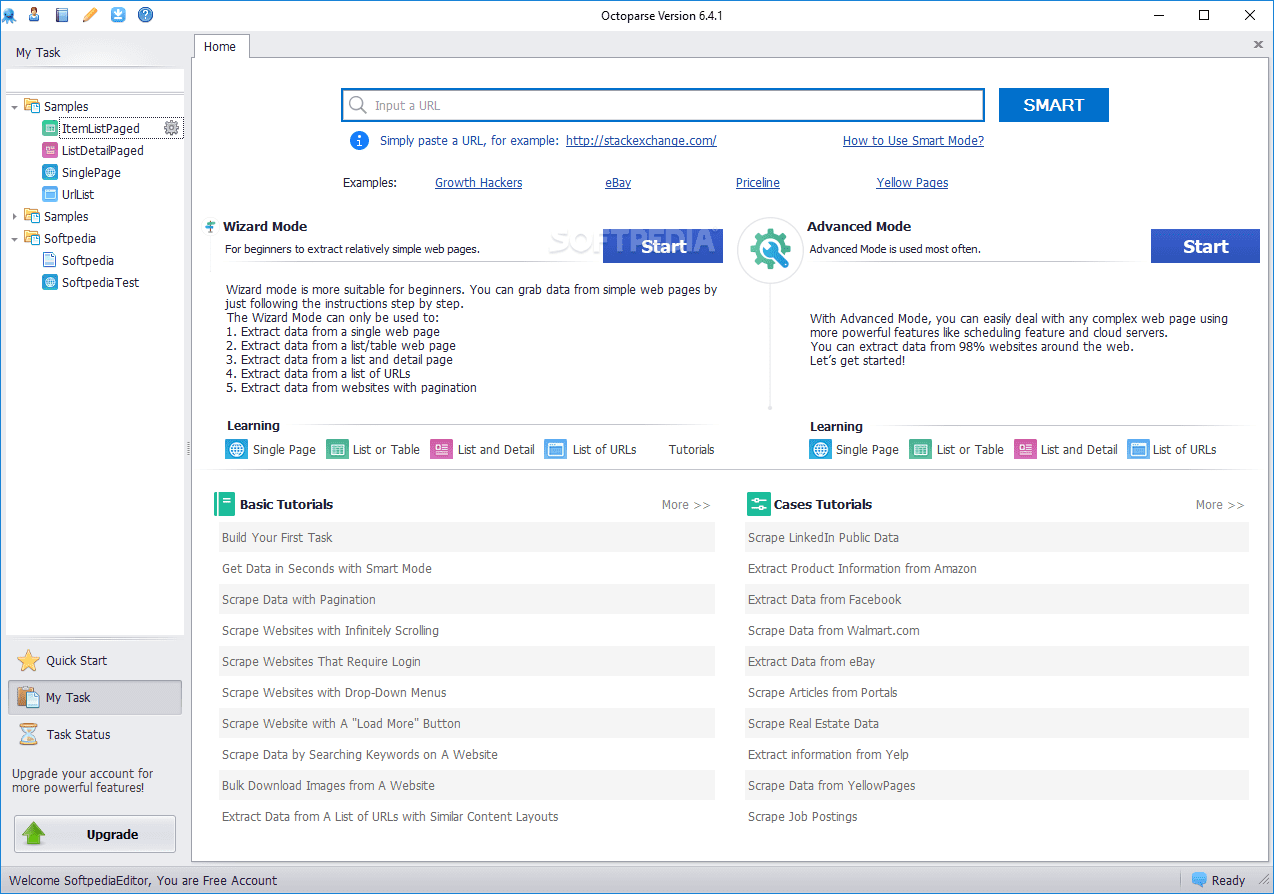
Sammen med den selvstændige applikation tilbyder Octoparse en cloud-baseret tjeneste til at fremskynde dataudtræksprocessen. Brugere kan opleve en 4x til 10x hastighedsforøgelse, når de bruger skytjenesten i stedet for desktopapplikationen. Hvis du holder dig til desktopversionen, kan du bruge Octoparse gratis. Men hvis du foretrækker at bruge cloud-tjenesten, bliver du nødt til at vælge en af dens betalte planer.
Indholdsfanger
Hvis du leder efter et funktionsrigt skrabeværktøj, bør du holde øje med Indholdsfanger. I modsætning til Octoparse er det nødvendigt at have avancerede programmeringsfærdigheder for at bruge Content Grabber. Til gengæld får du scriptredigering, fejlfindingsgrænseflader og andre avancerede funktioner. Med Content Grabber kan du bruge .Net-sprog til at skrive regulære udtryk. På denne måde behøver du ikke at generere udtrykkene ved hjælp af et indbygget værktøj.
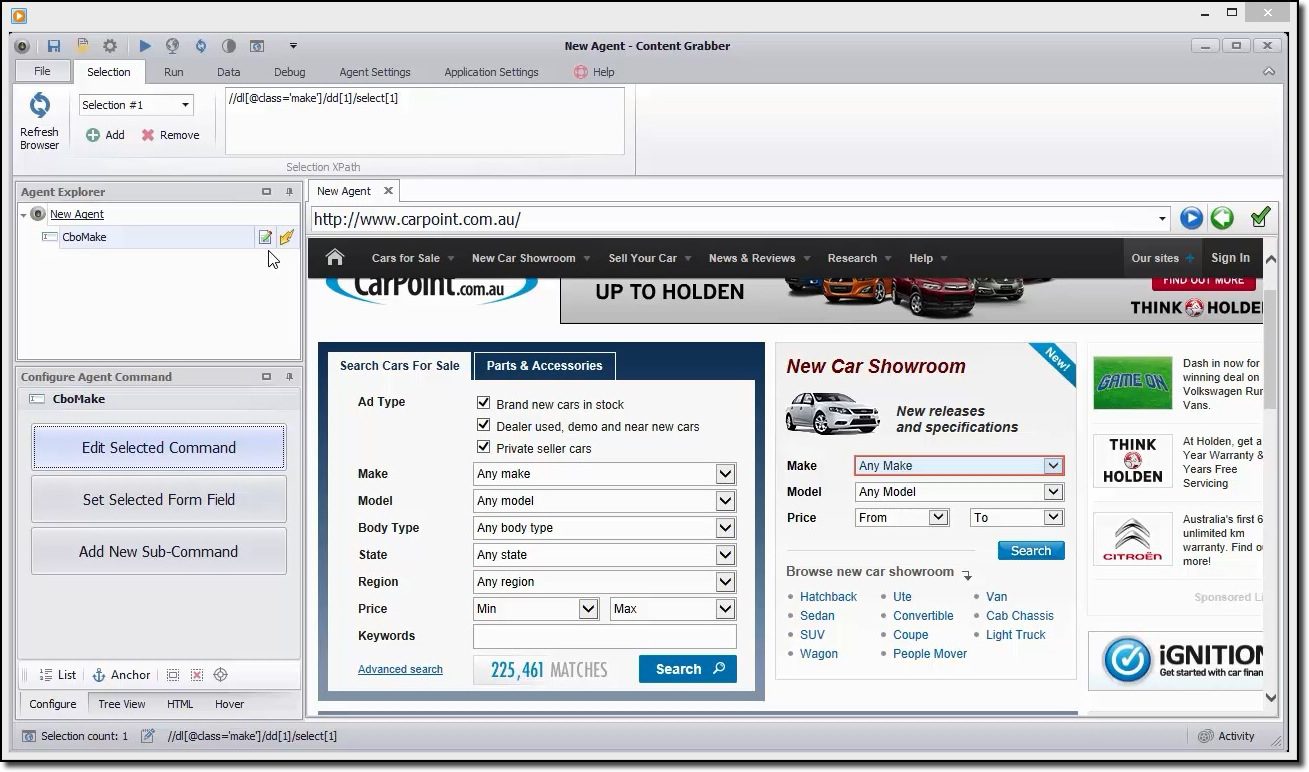
Værktøjet tilbyder en API (Application Programming Interface), som du kan bruge til at tilføje skrabefunktioner til dine desktop- og webapplikationer. For at bruge denne API skal udviklere have adgang til Content Grabber Windows-tjenesten.
ParseHub
Denne skraber kan håndtere en omfattende liste over forskellige typer indhold, herunder fora, indlejrede kommentarer, kalendere og kort. Det kan også håndtere sider, der indeholder godkendelse, Javascript, Ajax og mere. ParseHub kan bruges som en webapp eller en desktopapplikation, der kan køre på Windows, macOS X og Linux.
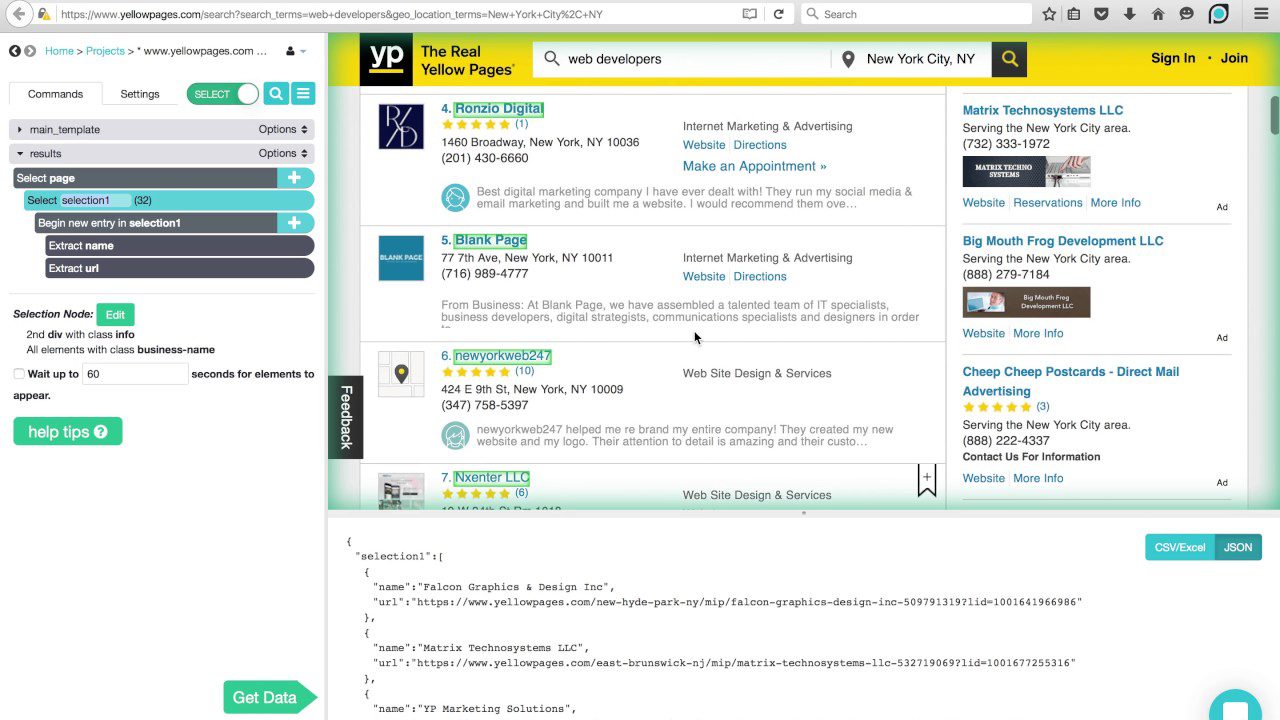
Ligesom Content Grabber anbefales det at have noget programmeringskendskab for at få mest muligt ud af ParseHub. Den har en gratis version, begrænset til 5 projekter og 200 sider pr. kørsel.
Programmeringssprog
Ligesom det tidligere nævnte SQL-sprog er designet specifikt til at arbejde med relationelle databaser, er der andre sprog skabt med et klart fokus på datavidenskab. Disse sprog giver udviklerne mulighed for at skrive programmer, der beskæftiger sig med massiv dataanalyse, såsom statistik og maskinlæring.
SQL betragtes også som en vigtig færdighed, som udviklere bør have for at lave datavidenskab, men det er fordi de fleste organisationer stadig har en masse data på relationelle databaser. “Sandte” datavidenskabelige sprog er R og Python.
Python

Python er et højniveau, fortolket, alment programmeringssprog, velegnet til hurtig applikationsudvikling. Den har en enkel og let at lære syntaks, der giver mulighed for en stejl indlæringskurve og for reduktioner i omkostningerne til programvedligeholdelse. Der er mange grunde til, at det er det foretrukne sprog for datavidenskab. For at nævne et par stykker: scriptingpotentiale, detaljering, portabilitet og ydeevne.
Dette sprog er et godt udgangspunkt for dataforskere, der planlægger at eksperimentere meget, før de hopper ud i det virkelige og hårde dataknusningsarbejde, og som ønsker at udvikle komplette applikationer.
R
Det R sprog bruges hovedsageligt til statistisk databehandling og graftegning. Selvom det ikke er meningen at udvikle fuldgyldige applikationer, som det ville være tilfældet for Python, er R blevet meget populær i de senere år på grund af dets potentiale for data mining og dataanalyse.

Takket være et stadigt voksende bibliotek af frit tilgængelige pakker, der udvider dets funktionalitet, er R i stand til at udføre alle former for dataknusende arbejde, herunder lineær/ikke-lineær modellering, klassificering, statistiske tests osv.
Det er ikke et let sprog at lære, men når du først har stiftet bekendtskab med dets filosofi, vil du udføre statistisk databehandling som en professionel.
IDE’er
Hvis du seriøst overvejer at dedikere dig til datavidenskab, så skal du nøje vælge et integreret udviklingsmiljø (IDE), der passer til dine behov, fordi du og din IDE vil bruge meget tid på at arbejde sammen.
En ideel IDE bør sammensætte alle de værktøjer, du har brug for i dit daglige arbejde som koder: en teksteditor med syntaksfremhævning og autofuldførelse, en kraftfuld debugger, en objektbrowser og nem adgang til eksterne værktøjer. Desuden skal det være kompatibelt med det sprog, du foretrækker, så det er en god idé at vælge din IDE efter at have ved, hvilket sprog du vil bruge.
Spyder
Dette generisk IDE er for det meste beregnet til videnskabsmænd og analytikere, der også skal kode. For at gøre dem behagelige begrænser den sig ikke til IDE-funktionaliteten – den giver også værktøjer til dataudforskning/visualisering og interaktiv eksekvering, som det kunne findes på en videnskabelig pakke. Redaktøren i Spyder understøtter flere sprog og tilføjer en klassebrowser, vinduesopdeling, spring-til-definition, automatisk kodefuldførelse og endda et kodeanalyseværktøj.
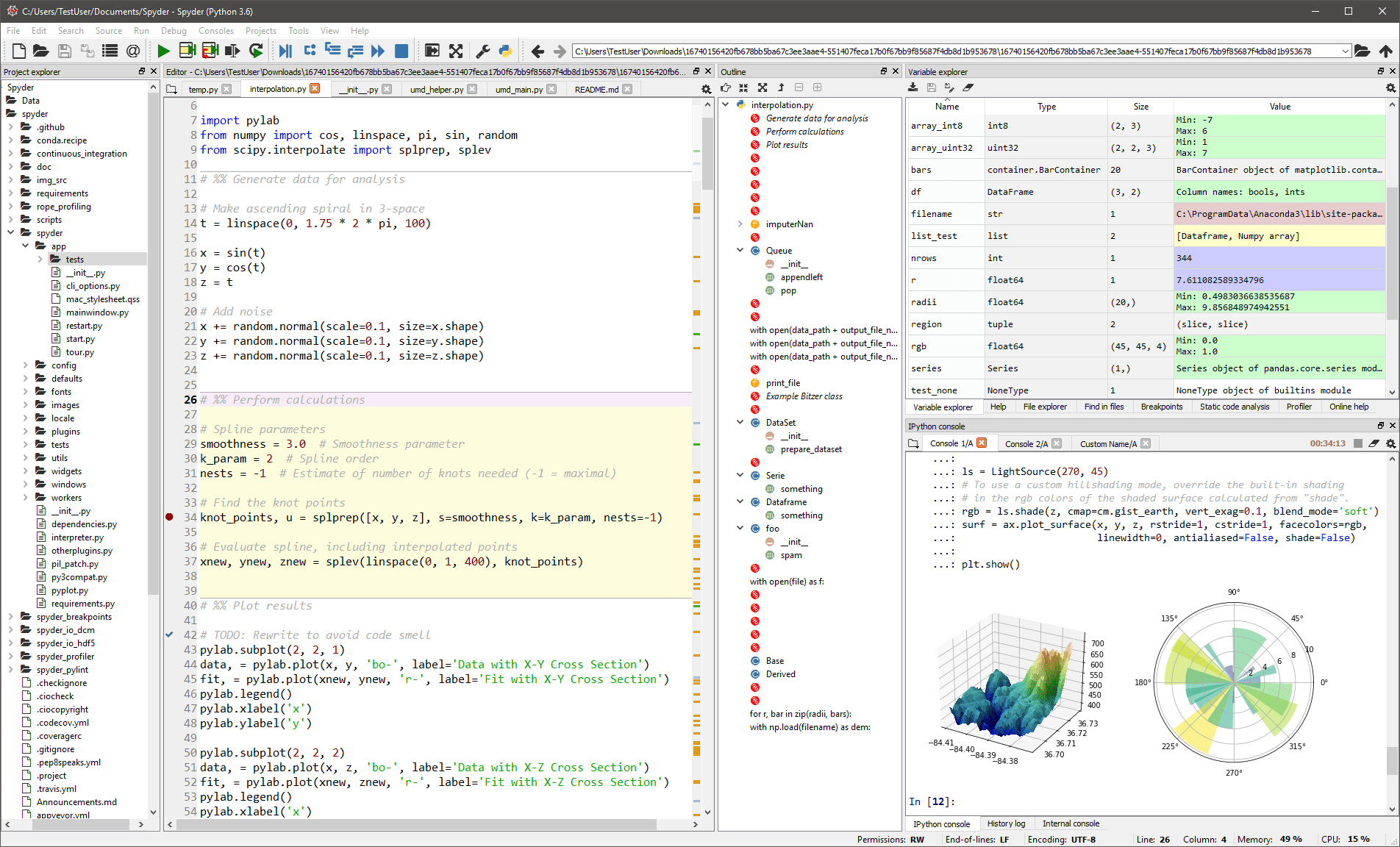
Debuggeren hjælper dig med at spore hver linje kode interaktivt, og en profiler hjælper dig med at finde og eliminere ineffektivitet.
PyCharm
Hvis du programmerer i Python, er chancerne for, at din foretrukne IDE vil være det PyCharm. Den har en smart kodeeditor med smart søgning, kodefuldførelse og fejlfinding og -fixing. Med blot ét klik kan du hoppe fra kodeeditoren til ethvert kontekstrelateret vindue, inklusive test, supermetode, implementering, erklæring og mere. PyCharm understøtter Anaconda og mange videnskabelige pakker, såsom NumPy og Matplotlib, for blot at nævne to af dem.
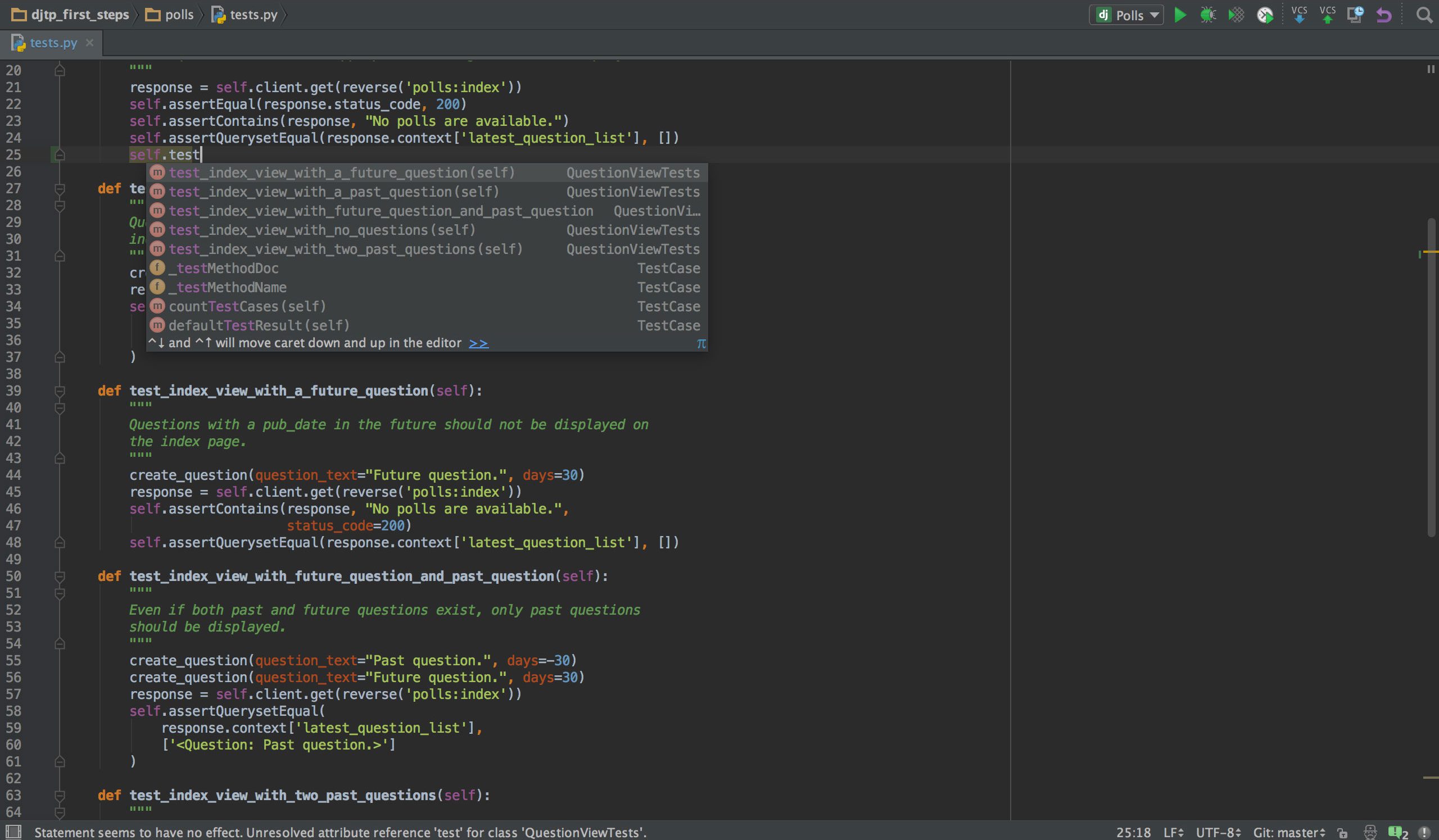
Det tilbyder integration med de vigtigste versionskontrolsystemer, og også med en testløber, en profiler og en debugger. For at lukke aftalen integreres den også med Docker og Vagrant for at sørge for udvikling og containerisering på tværs af platforme.
RStudio
For de datavidenskabsmænd, der foretrækker R-holdet, bør den foretrukne IDE være RStudio, på grund af dens mange funktioner. Du kan installere det på et skrivebord med Windows, macOS eller Linux, eller du kan køre det fra en webbrowser, hvis du ikke vil installere det lokalt. Begge versioner tilbyder godbidder såsom syntaksfremhævning, smart indrykning og kodefuldførelse. Der er en integreret datafremviser, der er praktisk, når du skal gennemse tabeldata.
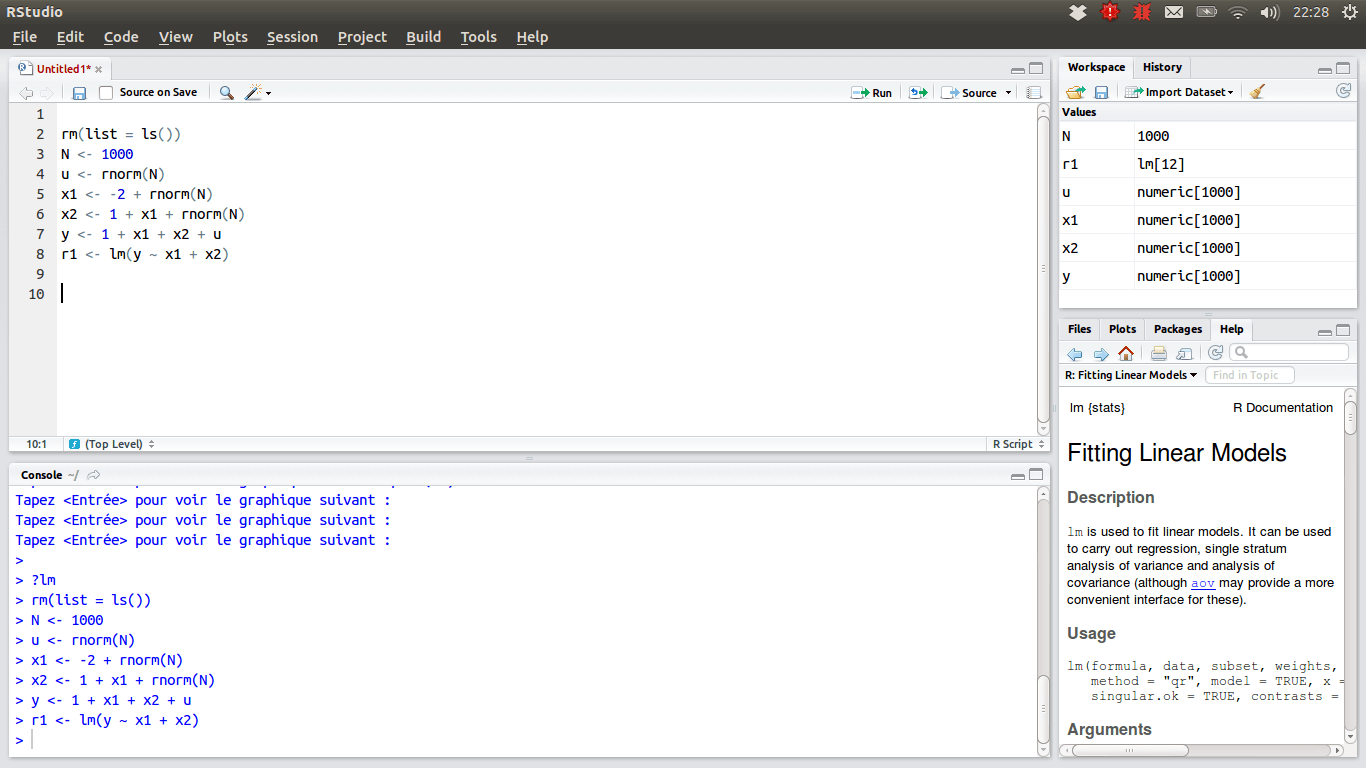
Fejlfindingstilstanden gør det muligt at se, hvordan dataene opdateres dynamisk, når et program eller script køres trin for trin. Til versionskontrol integrerer RStudio understøttelse af SVN og Git. Et godt plus er en mulighed for at skrive interaktiv grafik, med Shiny og giver biblioteker.
Din personlige værktøjskasse
På dette tidspunkt bør du have et komplet overblik over de værktøjer, du bør kende for at udmærke dig inden for datavidenskab. Vi håber også, at vi har givet dig nok information til at beslutte, hvilken der er den mest bekvemme mulighed inden for hver værktøjskategori. Nu er det op til dig. Datavidenskab er et blomstrende felt udvikle en karriere. Men hvis du vil gøre det, skal du følge med i ændringerne i trends og teknologier, da de sker næsten dagligt.