
Apache Parquet giver flere fordele for datalagring og -hentning sammenlignet med traditionelle metoder som CSV.
Parket format er designet til hurtigere databehandling af komplekse typer. I denne artikel taler vi om, hvordan Parket-formatet er velegnet til nutidens stadigt voksende databehov.
Før vi graver i detaljerne i Parquet-format, lad os forstå, hvad CSV-data er, og de udfordringer, det udgør for datalagring.
Indholdsfortegnelse
Hvad er CSV-lagring?
Vi har alle hørt meget om CSV (Comma Separated Values) – en af de mest almindelige måder at organisere og formatere data på. CSV-datalagring er rækkebaseret. CSV-filer gemmes med filtypenavnet .csv. Vi kan gemme og åbne CSV-data ved hjælp af Excel, Google Sheets eller en hvilken som helst teksteditor. Dataene er let synlige, når filen er åbnet.
Nå, det er ikke godt – bestemt ikke for et databaseformat.
Ydermere, efterhånden som datamængden vokser, bliver det vanskeligt at forespørge, administrere og hente.
Her er et eksempel på data gemt i en .CSV-fil:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Hvis vi ser det i Excel, kan vi se en række-kolonne struktur som nedenfor:
Udfordringer med CSV-lagring
Rækkebaserede lager som CSV er velegnede til oprettelse, opdatering og sletning.
Hvad så med Read in CRUD?
Forestil dig en million rækker i ovenstående .csv-fil. Det ville tage en rimelig tid at åbne filen og søge efter de data, du leder efter. Ikke så cool. De fleste cloud-udbydere som AWS opkræver virksomheder baseret på mængden af data, der er scannet eller gemt – igen, CSV-filer bruger meget plads.
CSV-lagring har ikke en eksklusiv mulighed for at gemme metadata, hvilket gør datascanning til en kedelig opgave.
Så hvad er den omkostningseffektive og optimale løsning til at udføre alle CRUD-operationer? Lad os udforske.
Hvad er Parket datalagring?
Parket er et open source-lagringsformat til lagring af data. Det er meget udbredt i Hadoop- og Spark-økosystemer. Parketfiler gemmes som .parquet-udvidelse.
Parket er et meget struktureret format. Det kan også bruges til at optimere komplekse rådata, der findes i bulk i datasøer. Dette kan reducere forespørgselstiden betydeligt.
Parket gør datalagring effektiv og genfinding hurtigere på grund af en blanding af række- og søjlebaserede (hybride) lagringsformater. I dette format er dataene opdelt både vandret og lodret. Parketformat eliminerer også parsing-overhead i vid udstrækning.
Formatet begrænser det samlede antal I/O-operationer og i sidste ende omkostningerne.
Parquet gemmer også metadataene, som gemmer information om data som dataskemaet, antal værdier, placering af kolonner, min værdi, max værdi antal rækkegrupper, type kodning osv. Metadataene gemmes på forskellige niveauer i filen , hvilket gør dataadgang hurtigere.
I rækkebaseret adgang som CSV tager datahentning tid, da forespørgslen skal navigere gennem hver række og få de specifikke kolonneværdier. Med Parketopbevaring kan alle de nødvendige søjler tilgås på én gang.
Sammenfattende,
- Parket er baseret på søjlestrukturen til datalagring
- Det er et optimeret dataformat til at lagre komplekse data i bulk i lagersystemer
- Parketformat omfatter forskellige metoder til datakomprimering og kodning
- Det reducerer datascanningstiden og forespørgselstiden markant og tager mindre diskplads sammenlignet med andre lagringsformater som CSV
- Minimerer antallet af IO-operationer, hvilket sænker omkostningerne til lager og udførelse af forespørgsler
- Indeholder metadata, som gør det nemmere at finde data
- Giver open source support
Parket dataformat
Før vi går ind i et eksempel, lad os forstå, hvordan data lagres i Parket-formatet mere detaljeret:
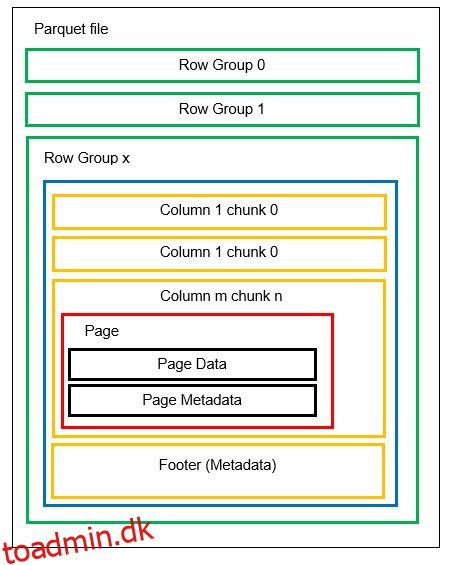
Vi kan have flere vandrette partitioner kendt som rækkegrupper i én fil. Inden for hver rækkegruppe anvendes lodret opdeling. Søjlerne er opdelt i flere søjlebidder. Dataene gemmes som sider inde i kolonneklumperne. Hver side indeholder de kodede dataværdier og metadata. Som vi nævnte før, gemmes metadataene for hele filen også i filens footer på rækkegruppeniveau.
Da dataene er opdelt i kolonnestykker, er det også nemt at tilføje nye data ved at indkode de nye værdier i en ny del og fil. Metadataene opdateres derefter for de berørte filer og rækkegrupper. Således kan vi sige, at Parket er et fleksibelt format.
Parket understøtter indbygget komprimering af data ved hjælp af sidekomprimering og ordbogskodningsteknikker. Lad os se et simpelt eksempel på ordbogskomprimering:
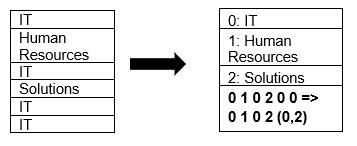
Bemærk, at vi i ovenstående eksempel ser IT-inddelingen 4 gange. Så mens du gemmer i ordbogen, koder formatet dataene med en anden let at gemme værdi (0,1,2…) sammen med antallet af gange, det gentages kontinuerligt – IT, IT ændres til 0,2 for at gemme mere plads. Det tager kortere tid at søge efter komprimerede data.
Head-to-head sammenligning
Nu hvor vi har en rimelig idé om, hvordan CSV- og Parket-formaterne ser ud, er det tid til nogle statistikker til at sammenligne begge formater:
CSV
Parket
Rækkebaseret lagerformat.
En hybrid af rækkebaserede og kolonnebaserede lagerformater.
Det bruger meget plads, da der ikke er nogen standard komprimeringsmulighed tilgængelig. For eksempel vil en 1TB-fil optage den samme plads, når den er gemt på Amazon S3 eller en hvilken som helst anden sky.
Komprimerer data under lagring og bruger dermed mindre plads. En 1 TB fil gemt i Parket-format vil kun optage 130 GB plads.
Forespørgselskørselstiden er langsom på grund af den rækkebaserede søgning. For hver kolonne skal hver række data hentes.
Forespørgselstiden er omkring 34 gange hurtigere på grund af den kolonnebaserede lagring og tilstedeværelsen af metadata.
Flere data skal scannes pr. forespørgsel.
Omkring 99 % færre data scannes til udførelsen af forespørgslen, hvilket optimerer ydeevnen.
De fleste lagerenheder oplades baseret på lagerpladsen, så CSV-format betyder de høje lageromkostninger.
Mindre lageromkostninger, da data gemmes i komprimeret, kodet format.
Filskema skal enten udledes (fører til fejl) eller leveres (kedeligt).
Filskemaet er gemt i metadataene.
Formatet er velegnet til simple datatyper.
Parket er velegnet selv til komplekse typer som indlejrede skemaer, arrays, ordbøger.
Konklusion 👩💻
Vi har gennem eksempler set, at Parket er mere effektivt end CSV med hensyn til omkostninger, fleksibilitet og ydeevne. Det er en effektiv mekanisme til lagring og genfinding af data, især når hele verden bevæger sig mod cloud-lagring og pladsoptimering. Alle større platforme som Azure, AWS og BigQuery understøtter Parket-format.