Gad vide, hvad de mærkelige rækker af symboler gør på Linux? De giver dig kommandolinjemagi! Vi lærer dig, hvordan du besværger regulære udtryk og forbedrer dine kommandolinjefærdigheder.
Indholdsfortegnelse
Hvad er regulære udtryk?
regulære udtryk (regexes) er en måde at finde matchende tegnsekvenser. De bruger bogstaver og symboler til at definere et mønster, der søges efter i en fil eller stream. Der er flere forskellige smagsvarianter fra regex. Vi skal se på den version, der bruges i almindelige Linux-værktøjer og -kommandoer, som grep, kommandoen der udskriver linjer, der matcher et søgemønster.
Der er skrevet hele bøger om regexes, så denne tutorial er kun en introduktion. Der er grundlæggende og udvidede regexes, og vi vil bruge de udvidede her.
For at bruge de udvidede regulære udtryk med grep, skal du bruge muligheden -E (udvidet). Fordi dette bliver trættende meget hurtigt, blev egrep-kommandoen oprettet. egrep-kommandoen er den samme som grep -E-kombinationen, du behøver bare ikke bruge -E-indstillingen hver gang.
Hvis du finder det mere bekvemt at bruge egrep, kan du. Vær dog opmærksom på, at det er officielt forældet. Det er stadig til stede i alle de distributioner, vi tjekkede, men det kan forsvinde i fremtiden.
Du kan selvfølgelig altid lave dine egne aliaser, så dine foretrukne muligheder er altid inkluderet for dig.
Fra små begyndelser
Til vores eksempler bruger vi en almindelig tekstfil, der indeholder en liste over nørder. Husk, at du kan bruge regexes med mange Linux-kommandoer. Vi bruger bare grep som en praktisk måde at demonstrere dem på.
Her er indholdet af filen:
less geek.txt

Den første del af filen vises.

Lad os starte med et simpelt søgemønster og søge i filen efter forekomster af bogstavet “o.” Igen, fordi vi bruger muligheden -E (udvidet regex) i alle vores eksempler, skriver vi følgende:
grep -E 'o' geeks.txt

Hver linje, der indeholder søgemønsteret, vises, og det matchende bogstav er fremhævet. Vi har udført en simpel søgning uden begrænsninger. Det er lige meget, om bogstavet optræder mere end én gang, i slutningen af strengen, to gange i det samme ord eller endda ved siden af sig selv.
Et par navne havde dobbelt O’er; vi skriver følgende for kun at vise dem:
grep -E 'oo' geeks.txt

Vores resultatsæt er som forventet meget mindre, og vores søgeterm fortolkes bogstaveligt. Det betyder ikke andet end det, vi skrev: dobbelte “o”-tegn.
Vi vil se mere funktionalitet med vores søgemønstre, efterhånden som vi bevæger os fremad.
Linjenumre og andre grep-tricks
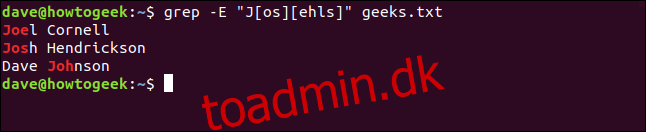
Hvis du vil have grep til at vise linjenummeret for de matchende poster, kan du bruge -n (linjenummer). Dette er et grep-trick – det er ikke en del af regex-funktionaliteten. Men nogle gange vil du måske gerne vide, hvor i en fil de matchende poster er placeret.
Vi skriver følgende:
grep -E -n 'o' geeks.txt
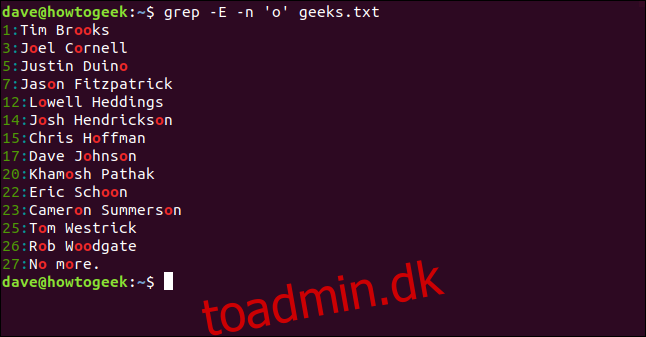
Et andet praktisk grep-trick, du kan bruge, er -o (kun matchende) mulighed. Den viser kun den matchende tegnsekvens, ikke den omgivende tekst. Dette kan være nyttigt, hvis du hurtigt har brug for at scanne en liste for dubletmatch på en af linjerne.
For at gøre det skriver vi følgende:
grep -E -n -o 'o' geeks.txt

Hvis du vil reducere outputtet til det absolutte minimum, kan du bruge -c (count) muligheden.
Vi skriver følgende for at se antallet af linjer i filen, der indeholder matches:
grep -E -c 'o' geeks.txt

Den vekslende operatør
Hvis du vil søge efter forekomster af både dobbelt “l” og dobbelt “o”, kan du bruge rørtegnet (|), som er alterneringsoperatoren. Den leder efter match for enten søgemønsteret til venstre eller højre.
Vi skriver følgende:
grep -E -n -o 'll|oo' geeks.txt
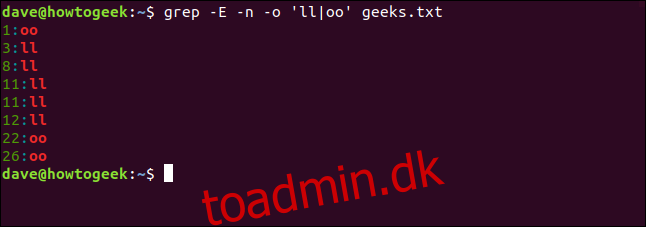
Enhver linje, der indeholder et dobbelt “l”, “o” eller begge dele, vises i resultaterne.
Store og små bogstaver
Du kan også bruge alterneringsoperatoren til at oprette søgemønstre, som dette:
am|Am
Dette vil matche både “am” og “Am”. For alt andet end trivielle eksempler fører dette hurtigt til besværlige søgemønstre. En nem måde at omgå dette på er at bruge indstillingen -i (ignorer store og små bogstaver) med grep.
For at gøre det skriver vi følgende:
grep -E 'am' geeks.txt
grep -E -i 'am' geeks.txt

Den første kommando giver tre resultater med tre match fremhævet. Den anden kommando giver fire resultater, fordi “Am” i “Amanda” også er et match.
Forankring
Vi kan også matche “Am”-sekvensen på andre måder. For eksempel kan vi søge specifikt efter det mønster eller ignorere sagen og angive, at sekvensen skal vises i begyndelsen af en linje.
Når du matcher sekvenser, der vises på den specifikke del af en linje af tegn eller et ord, kaldes det forankring. Du bruger symbolet (^) til at angive, at søgemønsteret kun bør betragte en tegnsekvens som en match, hvis den vises i begyndelsen af en linje.
Vi skriver følgende (bemærk, at indskriften er inde i de enkelte anførselstegn):
grep -E ‘Am’ geeks.txt
grep -E -i '^am' geeks.txt

Begge disse kommandoer matcher “Am.”
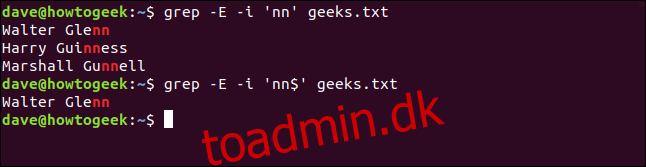
Lad os nu se efter linjer, der indeholder et dobbelt “n” i slutningen af en linje.
Vi skriver følgende ved at bruge et dollartegn ($) til at repræsentere slutningen af linjen:
grep -E -i 'nn' geeks.txt
grep -E -i 'nn$' geeks.txt
Wildcards
Du kan bruge et punktum (. ) til at repræsentere et enkelt tegn.
Vi skriver følgende for at søge efter mønstre, der starter med “T”, slutter med “m” og har et enkelt tegn mellem dem:
grep -E 'T.m' geeks.txt

Søgemønsteret matchede sekvenserne “Tim” og “Tom.” Du kan også gentage punkterne for at angive et bestemt antal tegn.
Vi skriver følgende for at indikere, at vi er ligeglade med, hvad de midterste tre tegn er:
grep-E 'J...n' geeks.txt

Linjen med “Jason” matches og vises.
Brug stjernen
for at matche nul eller flere forekomster af det foregående tegn. I dette eksempel er det tegn, der kommer foran stjernen, punktum (.), som (igen) betyder et hvilket som helst tegn.
Det betyder stjernen
vil matche et hvilket som helst antal (inklusive nul) af forekomster af et hvilket som helst tegn.
Stjernen er nogle gange forvirrende for nybegyndere. Dette er måske fordi de normalt bruger det som et jokertegn, der betyder “hvad som helst.”
I regexes matcher ‘c*t’ dog ikke “cat”, “cot”, “cot” osv. Det oversættes snarere til “match nul eller flere ‘c’-tegn efterfulgt af et ‘t’ .” Så det matcher “t”, “ct”, “cct”, “ccct” eller et hvilket som helst antal “c”-tegn.
grep -E 'J.*n ' geeks.txt
grep -E 'J.*n ' geeks.txt

Fordi vi kender formatet på indholdet i vores fil, kan vi tilføje et mellemrum som det sidste tegn i søgemønsteret. Der vises kun et mellemrum i vores fil mellem for- og efternavne.
Så vi skriver følgende for at tvinge søgningen til kun at inkludere fornavnene fra filen:
Ved første øjekast ser resultaterne fra den første kommando ud til at indeholde nogle ulige matches. De matcher dog alle reglerne for det søgemønster, vi brugte.
Sekvensen skal begynde med et stort “J” efterfulgt af et vilkårligt antal tegn og derefter et “n”. Alligevel, selvom alle kampe begynder med “J” og slutter med et “n”, er nogle af dem ikke, hvad du kunne forvente.
Fordi vi tilføjede mellemrummet i det andet søgemønster, fik vi det, vi havde til hensigt: alle fornavne, der starter med “J” og slutter med “n.”
Karakterklasser
grep -E 'N|W' geeks.txt
Lad os sige, at vi vil finde alle linjer, der starter med stort “N” eller “W”.
grep -E '^N|W' geeks.txt

Hvis vi bruger følgende kommando, matcher den enhver linje med en sekvens, der starter med enten et stort “N” eller “W”, uanset hvor den vises på linjen:
Det er ikke det, vi ønsker. Hvis vi anvender starten af linjeankeret (^) i begyndelsen af søgemønsteret, som vist nedenfor, får vi det samme sæt resultater, men af en anden årsag:
Søgningen matcher linjer, der indeholder stort “W”, hvor som helst på linjen. Den matcher også linjen “Ikke mere”, fordi den starter med stort “N”. Starten af lineanker (^) anvendes kun på det store “N”.[]Vi kunne også tilføje et startlinjeanker til stort “W”, men det ville hurtigt blive ineffektivt i et søgemønster, der er mere kompliceret end vores simple eksempel.[]Løsningen er at sætte en del af vores søgemønster i parentes (
) og anvend ankeroperatøren til gruppen. Beslagene ([]) betyder “enhver karakter fra denne liste.” Det betyder, at vi kan udelade (|) alterneringsoperatoren, fordi vi ikke har brug for den.
Vi kan anvende starten af linjeanker på alle elementerne i listen inden for parentes (
grep -E '^[NW]' geeks.txt

). (Bemærk, at lineankerets start er uden for beslagene).
Vi skriver følgende for at søge efter en linje, der starter med stort “N” eller “W”:
grep -E 'T[oi]m' geeks.txt
Vi vil også bruge disse begreber i det næste sæt kommandoer.[]Vi skriver følgende for at søge efter nogen, der hedder Tom eller Tim:
Hvis indtegningen (^) er det første tegn i parentes (
grep -E 'T[^o]m' geeks.txt
), søger søgemønsteret efter ethvert tegn, der ikke vises på listen.
grep -E 'T[aeiou]m' geeks.txt

For eksempel skriver vi følgende for at lede efter et navn, der starter med “T”, ender på “m”, og hvor det midterste bogstav ikke er “o”:
Vi kan inkludere et vilkårligt antal tegn i listen. Vi skriver følgende for at lede efter navne, der starter med “T”, slutter på “m” og indeholder en vokal i midten:
Interval udtryk
Du kan bruge intervaludtryk til at angive det antal gange, du ønsker, at det foregående tegn eller den foregående gruppe skal findes i den matchende streng. Du angiver tallet i krøllede parenteser ({}).
Et tal i sig selv betyder specifikt det tal, men hvis du følger det med et komma (,), betyder det det tal eller mere. Hvis du adskiller to tal med et komma (1,2), betyder det rækkevidden af tal fra det mindste til det største.
grep -E 'T[aeiou]{1,2}m' geeks.txt

Vi vil lede efter navne, der starter med “T”, efterfulgt af mindst én, men ikke mere end to, på hinanden følgende vokaler og ender på “m.”
Så vi skriver denne kommando:
grep -E 'el' geeks.txt
Dette matcher “Tim”, “Tom” og “Team”.
grep -E 'ell' geeks.txt
Hvis vi vil søge efter sekvensen “el”, skriver vi dette:
grep -E 'el{2}' geeks.txt
Vi tilføjer et andet “l” til søgemønsteret for kun at inkludere sekvenser, der indeholder dobbelt “l”:
Dette svarer til denne kommando:
Hvis vi angiver et område med “mindst én og ikke mere end to” forekomster af “l”, vil det matche “el” og “ell” sekvenser.
grep -E 'el{1,2}' geeks.txt

Dette er subtilt forskelligt fra resultaterne af den første af disse fire kommandoer, hvor alle matches var for “el”-sekvenser, inklusive dem inde i “ell”-sekvenserne (og kun ét “l” er fremhævet).
grep -E '[aeiou]{2,}' geeks.txt

Vi skriver følgende:
For at finde alle sekvenser af to eller flere vokaler, skriver vi denne kommando:
grep -E '.$' geeks.txt

Undslippende karakterer

Lad os sige, at vi vil finde linjer, hvor et punktum (.) er det sidste tegn. Vi ved, at dollartegnet ($) er slutningen af linjens anker, så vi kan skrive dette:
Som vist nedenfor får vi dog ikke, hvad vi forventede.
Som vi omtalte tidligere, matcher punktum (.) ethvert enkelt tegn. Fordi hver linje slutter med et tegn, blev hver linje returneret i resultaterne.
Så hvordan forhindrer du et specialtegn i at udføre sin regex-funktion, når du bare vil søge efter det faktiske tegn? For at gøre dette bruger du en omvendt skråstreg () for at undslippe tegnet.
grep -e '.$' geeks.txt

En af grundene til, at vi bruger -E (udvidede) muligheder er, fordi de kræver meget mindre escape, når du bruger de grundlæggende regexes.
Vi skriver følgende:
Dette matcher det faktiske punktum (.) i slutningen af en linje.
Forankring og Ord
Vi dækkede både start (^) og slutningen af linjen ($) ankre ovenfor. Du kan dog bruge andre ankre til at operere på ordenes grænser.
I denne sammenhæng er et ord en sekvens af tegn afgrænset af mellemrum (begyndelsen eller slutningen af en linje). Så “psy66oh” ville tælle som et ord, selvom du ikke finder det i en ordbog.
grep -E -i 'h' geeks.txt
Starten af ordanker er (
grep -E -i 'This finds only those at the start of words.
Let’s do something similar with the letter “y”; we only want to see instances in which it’s at the end of a word. We type the following:
grep -E 'y' geeks.txtVi skriver følgende:
Det finder alle forekomster af "h", ikke kun dem i begyndelsen af ord.
grep -E 'y>' geeks.txt
Dette finder alle forekomster af "y", uanset hvor det forekommer i ordene.
Nu skriver vi følgende ved at bruge slutningen af ordanker (/>) (som peger mod højre eller slutningen af ordet):
grep -E 'bGlennb' geeks.txtgrep -E 'BwayB' geeks.txt
Den anden kommando giver det ønskede resultat.
For at oprette et søgemønster, der leder efter et helt ord, kan du bruge grænseoperatoren (b). Vi bruger grænseoperatoren (B) i begge ender af søgemønsteret til at finde en sekvens af tegn, der skal være inde i et større ord:
Flere karakterklasser
Du kan bruge genveje til at angive listerne i tegnklasser. Disse rækkeviddeindikatorer sparer dig for at skulle indtaste hvert medlem af en liste i søgemønsteret.
Du kan bruge alt det følgende:
AZ: Alle store bogstaver fra "A" til "Z."
az: Alle små bogstaver fra "a" til "z."
0-9: Alle cifre fra nul til ni.dp: Alle små bogstaver fra "d" til "p." Disse stilarter i frit format giver dig mulighed for at definere dit eget udvalg.
grep -E 'J[os][ehls]' geeks.txt
2-7: Alle tal fra to til syv.
Du kan også bruge så mange karakterklasser som du vil i et søgemønster. Følgende søgemønster matcher sekvenser, der starter med "J" efterfulgt af et "o" eller "s" og derefter enten et "e", "h", "l" eller "s":
I vores næste kommando bruger vi az-områdespecifikationen.
[a-z]Vores søgekommando opdeles på denne måde:
H: Sekvensen skal starte med "H."
: Det næste tegn kan være et hvilket som helst lille bogstav i dette område.*: Stjernen repræsenterer her et vilkårligt antal små bogstaver.
grep -E 'H[a-z]*man' geeks.txt
mand: Sekvensen skal slutte med "mand."
Vi sætter det hele sammen i følgende kommando:
Intet er uigennemtrængeligt
Nogle regexes kan hurtigt blive svære at parse visuelt. Når folk skriver komplicerede regexes, starter de normalt i det små og tilføjer flere og flere sektioner, indtil det virker. De har en tendens til at stige i sofistikering over tid.
grep -E '^([0-9]{4}[- ]){3}[0-9]{4}|[0-9]{16}' geeks.txtNår du prøver at arbejde tilbage fra den endelige version for at se, hvad den gør, er det en helt anden udfordring.
Se for eksempel på denne kommando:
Hvor vil du begynde at udrede dette? Vi starter ved begyndelsen og tager det en del af gangen:[0-9]^: Starten af lineanker. Så vores sekvens skal være den første ting på en linje.[- ]( [0-9]{4}[- ]): Parenteserne samler søgemønsterelementerne i en gruppe. Andre operationer kan anvendes på denne gruppe som helhed (mere om det senere). Det første element er en karakterklasse, der indeholder en række cifre fra nul til ni
. Vores første tegn er altså et ciffer fra nul til ni. Dernæst har vi et intervaludtryk, der indeholder tallet fire {4}. Det gælder vores første tegn, som vi ved vil være et ciffer. Derfor er den første del af søgemønsteret nu på fire cifre. Det kan efterfølges af enten et mellemrum eller en bindestreg (
[0-9]) fra en anden karakterklasse. [0-9]{3}: En intervalspecifikation, der indeholder tallet tre, følger umiddelbart efter gruppen. Det anvendes på hele gruppen, så vores søgemønster er nu på fire cifre, efterfulgt af et mellemrum eller en bindestreg, som gentages tre gange.
: Dernæst har vi en anden karakterklasse, der indeholder en række cifre fra nul til ni
. Dette tilføjer endnu et tegn til søgemønsteret, og det kan være et hvilket som helst ciffer fra nul til ni.
[0-9]{4}: Et andet intervaludtryk, der indeholder tallet fire, anvendes på det forrige tegn. Det betyder, at tegn bliver til fire tegn, som alle kan være et hvilket som helst ciffer fra nul til ni.
|: Alterneringsoperatoren fortæller os, at alt til venstre for det er et komplet søgemønster, og alt til højre er et nyt søgemønster. Så denne kommando søger faktisk efter et af to søgemønstre. Den første er tre grupper med fire cifre, efterfulgt af enten et mellemrum eller en bindestreg, og derefter yderligere fire cifre, der slås på.: Det andet søgemønster starter med et vilkårligt ciffer fra nul til ni.
{16}: En intervaloperator anvendes på det første tegn og konverterer det til 16 tegn, som alle er cifre.
Så vores søgemønster vil lede efter et af følgende:Fire grupper med fire cifre, med hver gruppe adskilt af et mellemrum eller en bindestreg (-).
En gruppe på seksten cifre.
Resultaterne er vist nedenfor.
Dette søgemønster leder efter almindelige former for skrivning af kreditkortnumre. Det er også alsidigt nok til at finde forskellige stilarter med en enkelt kommando.
Tag det roligt
Kompleksitet er normalt bare en masse enkelthed boltet sammen. Når du forstår de grundlæggende byggeklodser, kan du skabe effektive, kraftfulde hjælpeprogrammer og udvikle værdifulde nye færdigheder.