
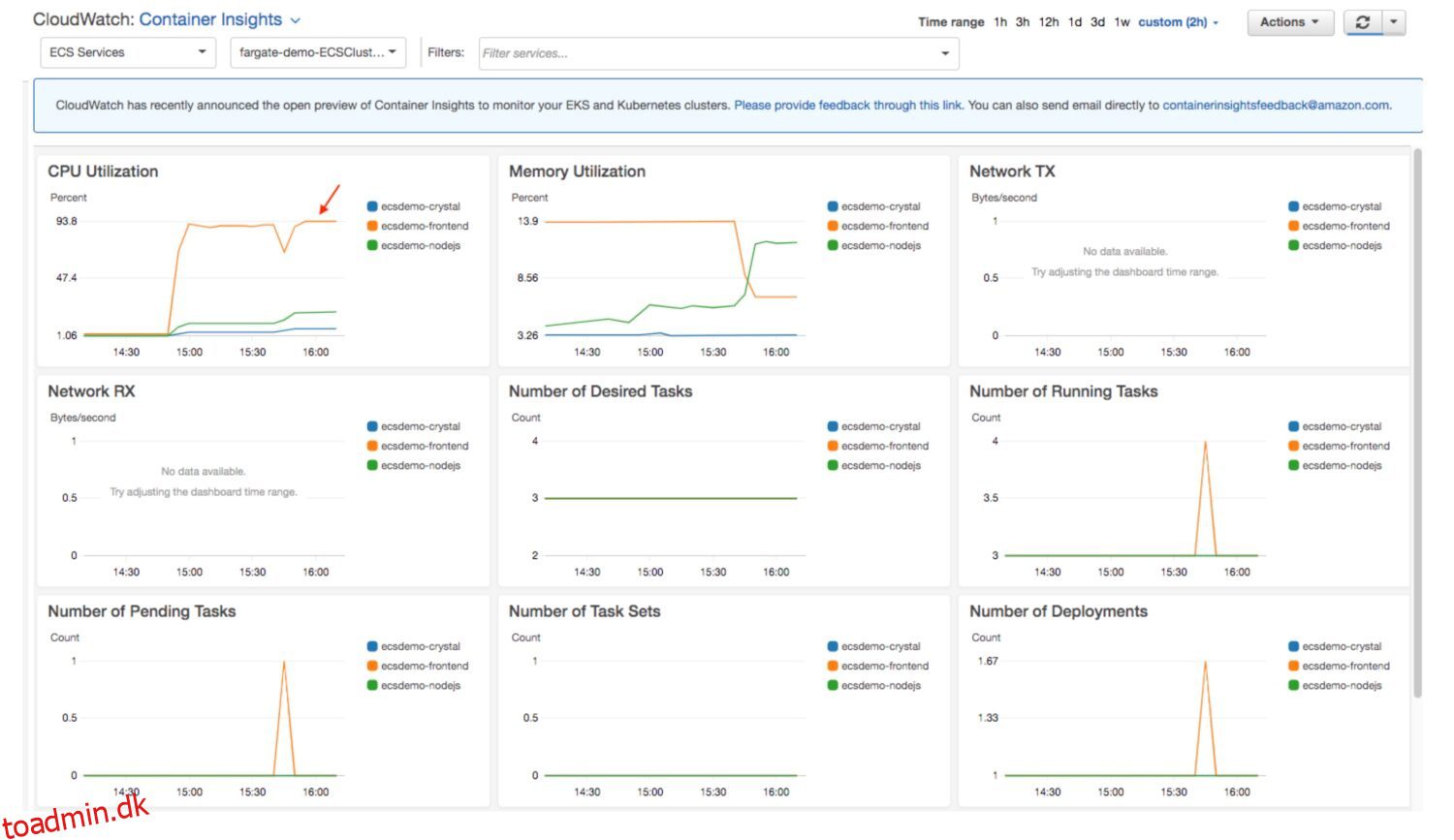
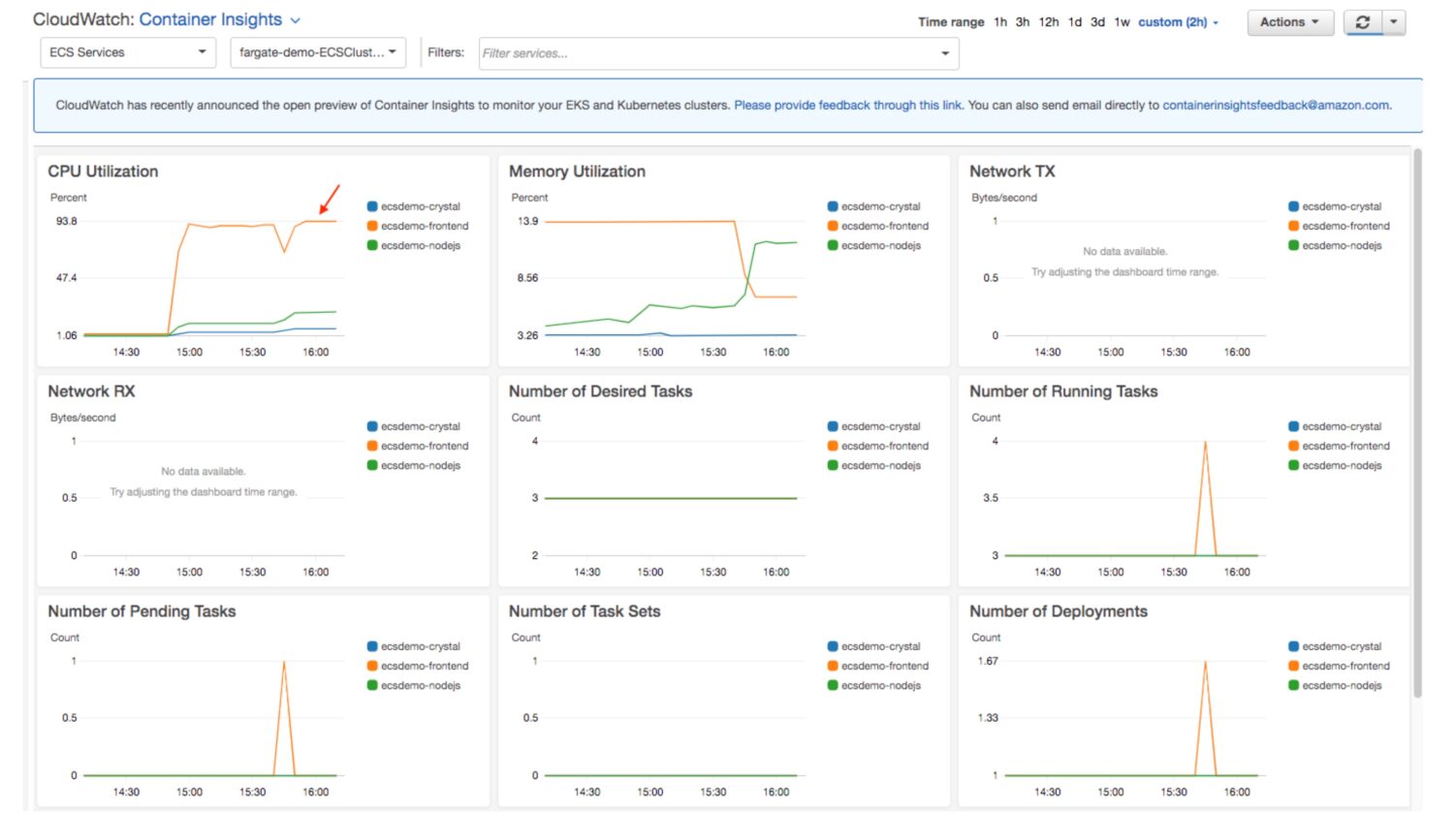
Hver AWS-tjeneste logger sin behandling til filer organiseret under CloudWatch-loggrupper. Loggrupperne er normalt opkaldt efter selve tjenesten for lettere identifikation. Tjenestens systemmeddelelser eller almindelige tilstandsoplysninger skrives som standard ind i disse logfiler.
Du kan dog tilføje brugerdefinerede logmeddelelsesoplysninger oven på standardoplysningerne. Hvis sådanne logfiler oprettes klogt, kan de tjene til at skabe nyttige CloudWatch-dashboards.
Med målinger og struktureret information, der giver ekstra detaljer om jobbehandling. Ikke alene kan de indeholde standardwidgets med systemlignende oplysninger om tjenesten. Du kan udvide dette med dit eget indhold, samlet i din tilpassede widget eller metric.
Indholdsfortegnelse
Forespørg logfilerne
Kilde: aws.amazon.com
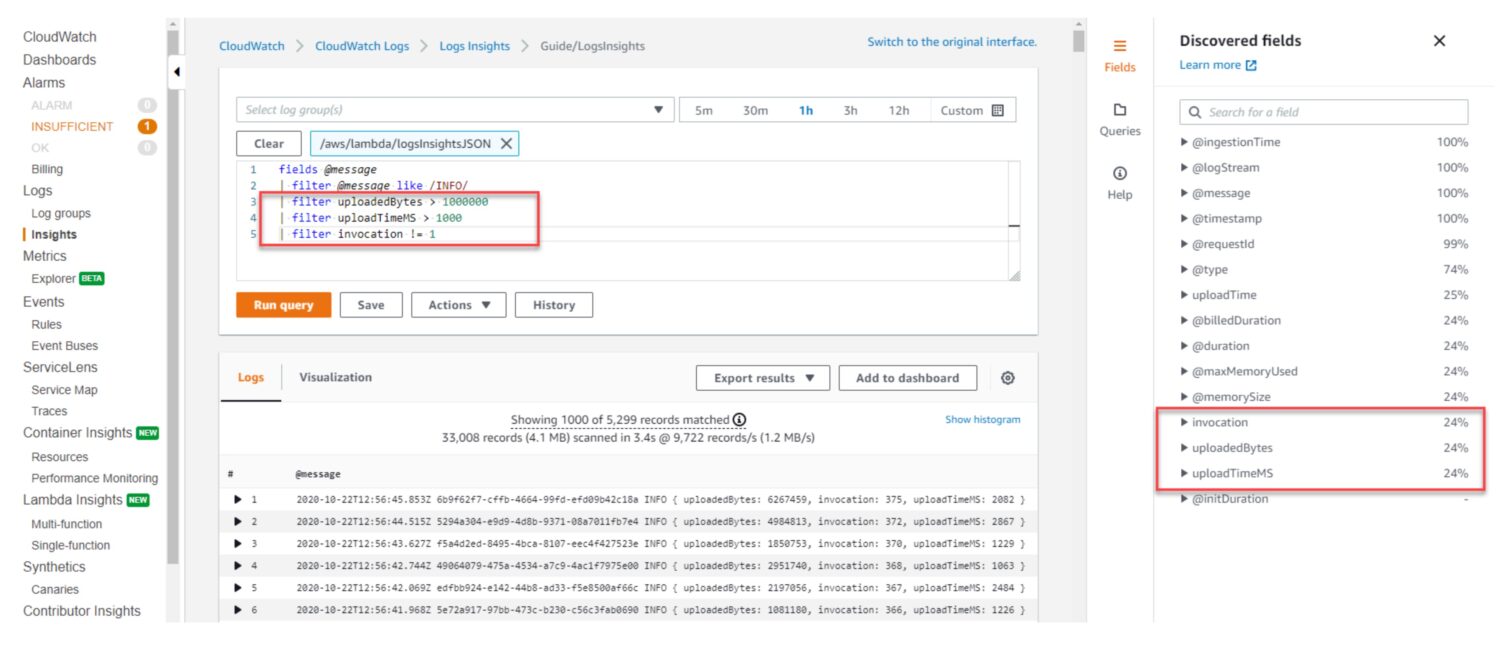
AWS CloudWatch Log Insights giver dig mulighed for at søge og analysere logdata fra dine AWS-ressourcer i realtid. Du kan se det som en databasevisning. Du definerer forespørgslen på dashboardet, og dashboardet vil vælge den, når du besøger den eller på det angivne tidsvindue i fortiden, som du definerer det i dashboardvisningen.
Det bruger et forespørgselssprog kaldet CloudWatch Logs Insights til at søge og analysere logdata. Forespørgselssproget er baseret på en delmængde af SQL-sproget. Det giver dig mulighed for at søge og filtrere logdata. Du kan søge efter specifikke loghændelser, tilpasset logtekst eller nøgleord og filtrere logdata baseret på specifikke felter. Og vigtigst af alt, samle logdata i en eller flere logfiler for at generere opsummerede metrikker og visualiseringer.
Når du kører en forespørgsel, søger CloudWatch Log Insights gennem logdataene i loggruppen. Derefter returnerer den teksterne fra de filer, der matcher dine forespørgselskriterier.
Eksempel på logfilforespørgsel
Lad os tage et kig på nogle grundlæggende spørgsmål for at forstå konceptet.
Hver service logger som standard nogle afgørende servicefejl. Også selvom du ikke opretter en dedikeret brugerdefineret log til sådanne fejlhændelser. Derefter kan du med en simpel forespørgsel tælle antallet af fejl i dine applikationslogfiler i løbet af den sidste time:
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
Eller her er, hvordan du overvåger den gennemsnitlige responstid for din API i løbet af den sidste dag:
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
Da CPU-udnyttelsen som standard er information, der logges af tjenesten i CloudWatch, kan du også samle denne type metrik:
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
Disse forespørgsler kan tilpasses, så de passer til din specifikke brugssituation og kan bruges til at skabe brugerdefinerede metrics og visualiseringer i CloudWatch Dashboards. Måden, hvordan man gør det, er at placere widgetten på dashboardet og placere koden inde i widgetten for at definere, hvad der skal vælges.
Her er nogle af de widgets, der kan bruges i CloudWatch Dashboards og udfyldes med indhold fra Log Insights:
- Tekstwidgets – Vis tekstbaseret information, såsom output fra en CloudWatch Insights-forespørgsel.
- Logforespørgselswidgets – Vis resultaterne af en CloudWatch Insights-logforespørgsel, såsom antallet af fejl i dine applikationslogfiler.
Sådan opretter du nyttige logoplysninger til dashboard
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
For effektivt at bruge CloudWatch Insights-forespørgsler i CloudWatch Dashboards er det godt at følge nogle bedste fremgangsmåder, når du opretter CloudWatch-logfiler for hver af de tjenester, du bruger i dit system. Her er nogle tips:
#1. Brug struktureret logning
Du skal holde dig til et logningsformat, der bruger et foruddefineret skema til at logge data i et struktureret format. Dette gør det nemmere at søge og filtrere logdata ved hjælp af CloudWatch Insights-forespørgsler.
Dette betyder grundlæggende at standardisere dine logfiler på tværs af forskellige tjenester i din arkitekturplatform. At få det defineret i udviklingsstandarder hjælper enormt.
For eksempel kan du definere, at hvert problem relateret til en specifik databasetabel vil blive logget med en startmeddelelse som: “[TABLE_NAME] Advarsel / Fejl:
Eller du kan adskille fulde datajob fra deltadatajob med præfikser som “[FULL/DELTA]” for kun at vælge meddelelser relateret til de konkrete dataprocesser.
Du kan definere, at mens du behandler data fra et specifikt kildesystem, vil navnet på systemet være et præfiks for hver relateret logpost. Det er meget nemmere bagefter at filtrere sådanne meddelelser fra logfilerne og bygge metrics over dem.
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
#2. Brug konsekvente logformater
Brug konsistente logformater på tværs af alle dine AWS-ressourcer for at gøre det nemmere at søge og filtrere logdata ved hjælp af CloudWatch Insights-forespørgsler.
Dette er ret relateret til det foregående punkt, men faktum er, jo mere standardiseret logformatet er, jo lettere er det at bruge logdataene. Udviklere kan derefter stole på det format og bruge det endda intuitivt.
Den grusomme kendsgerning er, at de fleste af projekterne ikke generer nogen standarder omkring logning. Hvad mere er, mange projekter opretter ikke engang nogen brugerdefinerede logfiler overhovedet. Det er chokerende, men også så almindeligt på samme tid.
Jeg kan ikke engang fortælle, hvor mange gange jeg undrede mig over, hvordan folk kan bo her uden nogen form for fejlhåndtering. Og hvis nogen gjorde en indsats for at udføre en form for fejlhåndtering som en undtagelse, gjorde de det forkert.
Så et konsekvent logformat er et stærkt aktiv. Ikke mange har dem.
#3. Inkluder relevante metadata
Inkluder metadata i dine logdata, såsom tidsstempler, ressource-id’er og fejlkoder, for at gøre det nemmere at søge og filtrere logdata ved hjælp af CloudWatch Insights-forespørgsler.
#4. Aktiver logrotation
Aktiver logrotation for at forhindre dine logdata i at blive for store og for at gøre det nemmere at søge og filtrere logdata ved hjælp af CloudWatch Insights-forespørgsler.
At have ingen logdata er én ting, men at have for mange af dem uden struktur er ligeledes desperat. Hvis du ikke kan bruge dine data, er det som at have ingen data overhovedet.
#5. Brug CloudWatch Logs Agents
Hvis du ikke kan hjælpe dig selv og bare nægter at bygge dit tilpassede logsystem, så brug i det mindste CloudWatch Logs-agenter. De sender automatisk logdata fra dine AWS-ressourcer til CloudWatch-logfiler. Dette gør det nemmere at søge og filtrere logdata ved hjælp af CloudWatch Insights-forespørgsler.
Eksempler på mere komplekse indsigter
CloudWatch Insights-forespørgsel kan være mere kompliceret end blot to linjers erklæring.
fields @timestamp, @message | filter @message like /ERROR/ | filter @message not like /404/ | parse @message /.*[(?<timestamp>[^]]+)].*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
Denne forespørgsel gør følgende:
Denne forespørgsel identificerer de mest almindelige fejl i din applikation og sporer den gennemsnitlige responstid for hver kombination af HTTP-metode, sti og statuskode. Du kan bruge resultaterne til at oprette tilpassede metrics og visualiseringer i CloudWatch Dashboards til at overvåge ydeevnen af din webapplikation og fejlfinde problemer.
Et andet eksempel på forespørgsel efter Amazon S3-tjenestemeddelelserne:
fields @timestamp, @message | filter @message like /REST.API.REQUEST/ | parse @message /.*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
- Forespørgslen vælger loghændelser, der indeholder strengen “REST.API.REQUEST”.
- Parser derefter logmeddelelsen for at udtrække HTTP-metoden, stien, statuskoden og responstiden.
- Den beregner den gennemsnitlige responstid og antallet af loghændelser for hver kombination af HTTP-metode, sti og statuskode og sorterer resultaterne efter antal i faldende rækkefølge.
- Begrænser output til de 20 bedste resultater.
Du kan bruge outputtet fra denne forespørgsel til at oprette en linjegraf i et CloudWatch Dashboard, der viser den gennemsnitlige responstid for hver kombination af HTTP-metode, sti og statuskode over tid.
Opbygning af Dashboard
For at udfylde metrics og visualiseringer i CloudWatch Dashboards fra outputtet af CloudWatch Insights logforespørgsler kan du navigere til CloudWatch-konsollen og følge Dashboard-guiden for at opbygge dit indhold.
Derefter ser koden på et CloudWatch Dashboard sådan ud og indeholder metrics udfyldt af CloudWatch Insights Query-data:
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
Dette CloudWatch Dashboard indeholder to widgets:
Det er en fil i JSON-format med en definition af dashboardet og metrics inde. Den indeholder (som egenskab) også selve indsigtsforespørgslen.
Du kan tage koden og implementere den til enhver AWS-konto, du har brug for. Forudsat at tjenesterne og logmeddelelserne er konsistente over alle dine AWS-konti og faser, vil dashboardet fungere på alle konti uden behov for at ændre kildekoden til dashboardet.
Afsluttende ord
Opbygning af en solid logningsstruktur var altid en god investering i fremtiden for systemets pålidelighed. Nu kan det tjene et endnu større formål. Du kan have nyttige dashboards med målinger og visualiseringer bare som en bivirkning af det.
Med en nødvendighed, der kun skal gøres én gang, med kun lidt ekstra arbejde, kan udviklingsteamet, testteamet og produktionsbrugerne alle drage fordel af den samme løsning.
Tjek derefter de bedste AWS-overvågningsværktøjer.