

Data varehus. Data sø. Lakehouse. Hvis ingen af disse ord vækker genklang hos dig i det mindste en smule, så er dit job tydeligvis ikke relateret til data.
Det ville dog være en ret urealistisk præmis, da alt i dag er relateret til data, ser ud til. Eller hvordan virksomhedens ledere kan lide at beskrive det:
- Datacentreret og datadrevet forretning.
- Data hvor som helst, når som helst og alligevel.
Indholdsfortegnelse
Det vigtigste aktiv
Det ser ud til, at data er blevet det mest værdifulde aktiv for flere og flere virksomheder. Jeg kan huske, at store virksomheder altid genererede en masse data, tænk på terabyte af nye data hver måned. Det var stadig 10-15 år siden. Men nu kan du nemt generere den mængde data inden for et par dage. Man ville spørge, om det virkelig er nødvendigt, selvom det er noget indhold, nogen vil bruge. Og ja, det er det bestemt ikke 😃.
Ikke alt indhold vil være til nogen nytte, og nogle dele ikke engang en enkelt gang. Ofte var jeg vidne til på frontlinjen, hvordan virksomheder genererede en enorm mængde data for kun at blive ubrugelige efter en vellykket indlæsning.
Men det er ikke relevant længere. Datalagring – nu i skyen – er billig, datakilderne vokser eksponentielt, og i dag kan ingen forudsige, hvad de får brug for et år senere, når nye tjenester er indbygget i systemet. På det tidspunkt kan selv de gamle data blive værdifulde.
Derfor er strategien at gemme så meget data som muligt. Men også i så effektiv form som muligt. Så data kan ikke kun gemmes effektivt, men også forespørges, genbruges eller transformeres og distribueres videre.
Lad os se på tre indbyggede måder, hvordan man opnår dette inde i AWS:
- Athena Database – billig og effektiv, men simpel måde at skabe en datasø i skyen på.
- Redshift Database – en seriøs cloudversion af et datavarehus, der har potentialet til at erstatte størstedelen af de nuværende on-premise-løsninger, der ikke er i stand til at indhente den eksponentielle vækst af data.
- Databricks – en kombination af en datasø og datavarehus i én enkelt løsning, med lidt bonus oven i det hele.
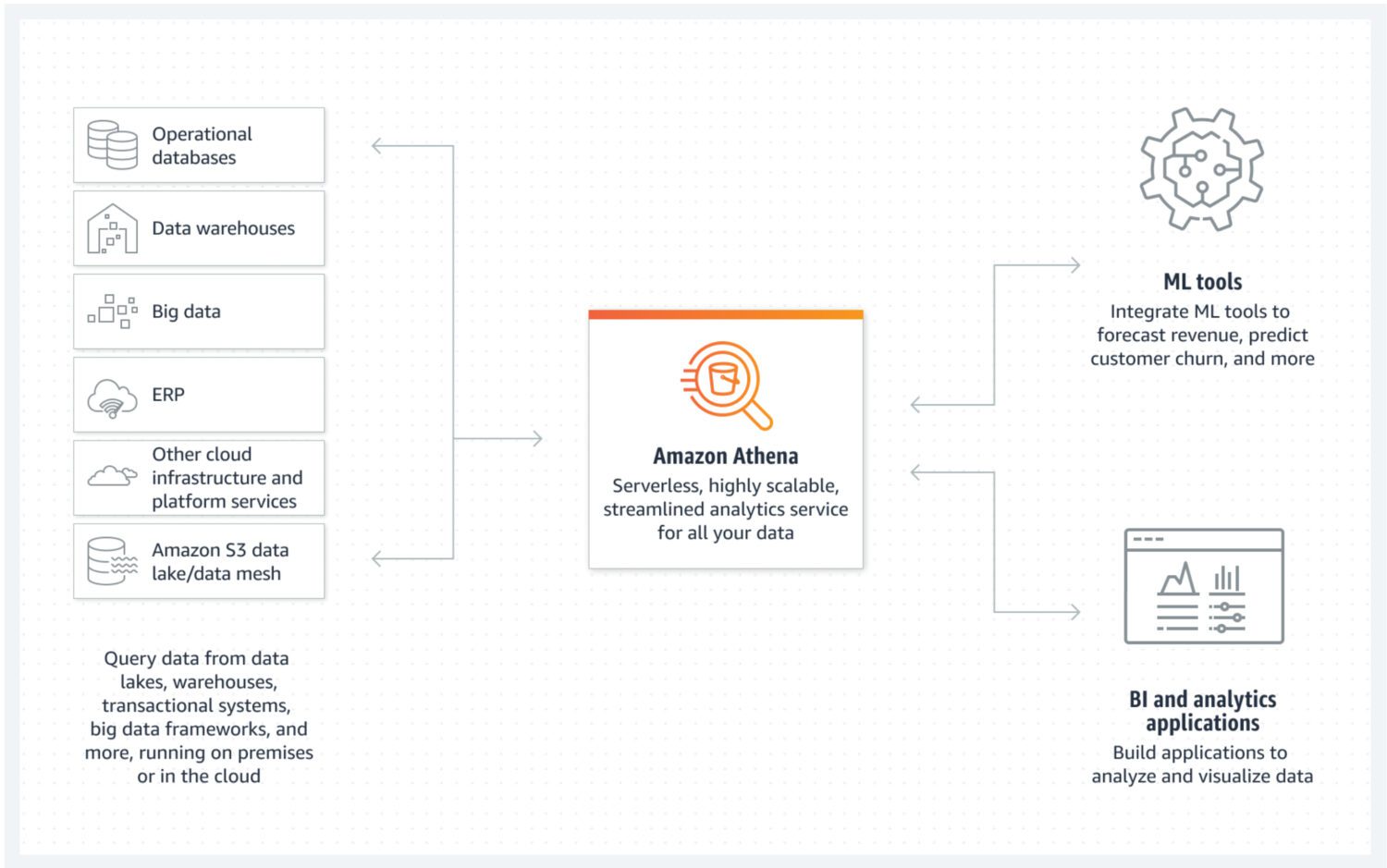
Data Lake af AWS Athena
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Datasøen er et sted, hvor du kan gemme indgående data i ustruktureret, semi-struktureret eller struktureret form på en hurtig måde. Samtidig forventer du ikke, at disse data bliver ændret, når de først er gemt. I stedet ønsker du, at de skal være så atomare og uforanderlige som muligt. Kun dette vil sikre det største potentiale for genbrug i senere faser. Hvis du ville miste denne atomare egenskab ved dataene lige efter den første indlæsning i en datasø, er der ingen måde, hvordan du får denne tabte information tilbage igen.
AWS Athena er en database med lagring direkte på S3 buckets og uden serverklynger, der kører i baggrunden. Det betyder, at det er en rigtig billig datasø-tjeneste. Strukturerede filformater såsom parket eller CSV-filer (kommaseparerede værdier) opretholder dataorganisationen. S3-bøtten rummer filerne, og Athena henviser til dem, når processer vælger data fra databasen.
Athena understøtter ikke forskellige funktionaliteter, der ellers anses for at være standard, såsom opdateringserklæringer. Det er derfor, du skal se på Athena som en meget enkel mulighed. På den anden side hjælper det dig med at forhindre ændring af din atomare datasø, simpelthen fordi du ikke kan 😐.
Den understøtter indeksering og partitionering, hvilket gør den anvendelig til effektiv udførelse af udvalgte sætninger og oprettelse af logisk adskilte bidder af data (for eksempel adskilt af dato eller nøglekolonner). Den kan også meget nemt skalere horisontalt, da dette er lige så komplekst som at tilføje nye skovle til infrastrukturen.

Fordele og ulemper
Fordelene at overveje:
- Den kendsgerning, at Athena er billig (kun bestående af S3-bøtter og SQL-brugsomkostninger pr. brug) giver den største fordel. Hvis du vil bygge en overkommelig datasø i AWS, er det her.
- Som en indbygget tjeneste kan Athena nemt integreres med andre nyttige AWS-tjenester som Amazon QuickSight til datavisualisering eller AWS Glue Data Catalog for at skabe vedvarende strukturerede metadata.
- Bedst til at køre ad hoc-forespørgsler over en stor mængde strukturerede eller ustrukturerede data uden at opretholde en hel infrastruktur omkring det.
Ulemperne at overveje:
- Athena er ikke særlig effektiv til at returnere komplekse udvalgte forespørgsler hurtigt, især hvis forespørgslerne ikke følger datamodellens antagelser om, hvordan du har designet til at anmode om data fra datasøen.
- Dette gør den også mindre fleksibel med hensyn til de potentielle fremtidige ændringer i datamodellen.
- Athena understøtter ikke yderligere avancerede funktionaliteter ud af boksen, og hvis du vil have noget specifikt til at være en del af tjenesten, skal du implementere det oveni.
- Hvis du forventer datasøens dataforbrug i et mere avanceret præsentationslag, er det eneste valg ofte at kombinere det med en anden databasetjeneste, der er mere egnet til det formål, såsom AWS Aurora eller AWS Dynamo DB.
Formål og Real-World Use Case
Vælg Athena, hvis målet er skabelsen af en simpel datasø uden nogen avanceret datavarehuslignende funktionalitet. Så hvis du for eksempel ikke forventer seriøse højtydende analyseforespørgsler, der kører regelmæssigt over datasøen. I stedet er det prioriteret at have en pulje af uforanderlige data med nem datalagringsudvidelse.
Du behøver ikke længere bekymre dig for meget om manglen på plads. Selv omkostningerne ved S3 bucket storage kan reduceres yderligere ved at implementere en datalivscykluspolitik. Dette betyder dybest set at flytte data på tværs af forskellige typer af S3-bøtter, mere målrettet mod arkivformål med langsommere indtagelsesreturtider, men lavere omkostninger.
En fantastisk funktion ved Athena er, at den automatisk opretter en fil, der består af data, der er en del af et resultat af din SQL-forespørgsel. Du kan derefter tage denne fil og bruge den til ethvert formål. Så det er en god mulighed, hvis du har mange lambda-tjenester, der viderebehandler dataene i flere trin. Hvert lambda-udfald vil automatisk være resultatet i et struktureret filformat som input klar til den efterfølgende behandling.
Athena er en god mulighed i situationer, hvor en stor mængde rå data kommer til din cloud-infrastruktur, og du ikke behøver at behandle det på tidspunktet for indlæsning. Det betyder, at alt hvad du behøver er hurtig lagring i skyen i en letforståelig struktur.
En anden brugssag ville være at skabe et dedikeret rum til dataarkiveringsformål til en anden tjeneste. I sådan et tilfælde ville Athena DB blive et billigt backupsted for alle de data, du ikke har brug for lige nu, men det kan ændre sig i fremtiden. På dette tidspunkt vil du blot indtage dataene og sende dem videre.
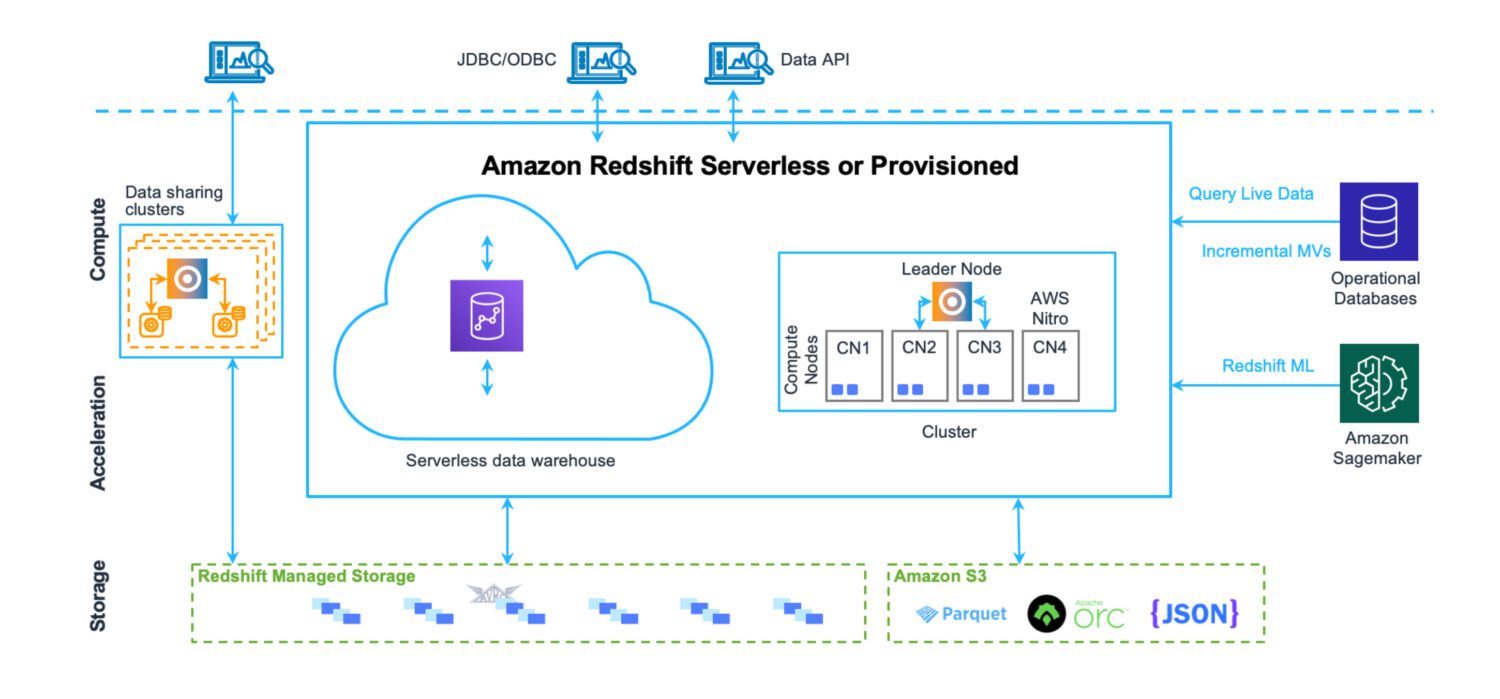
Data Warehouse af AWS Redshift
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Et datavarehus er et sted, hvor data opbevares på en meget struktureret måde. Let at fylde og udtrække. Hensigten er at køre et stort antal meget komplekse forespørgsler, der forbinder mange tabeller via komplekse joinforbindelser. Forskellige analytiske funktioner er på plads til at beregne forskellige statistikker over de eksisterende data. Det ultimative mål er at udtrække fremtidige forudsigelser og fakta, der skal udnyttes i forretningen fremadrettet, ved hjælp af eksisterende data.
Redshift er et fuldgyldigt data warehouse-system. Med klyngeservere til at tune og skalere – vandret og lodret og et databaselagersystem optimeret til hurtige komplekse forespørgselsreturneringer. Selvom du i dag også kan køre Redshift i serverløs tilstand. Der er ingen filer på S3 eller noget lignende. Dette er en standard databaseklyngeserver med sit eget lagerformat.
Den har præstationsovervågningsværktøjer på plads ud af kassen, sammen med brugerdefinerbare dashboard-metrics, du kan bruge og se for at finjustere ydeevnen til din brug. Administrationen er også tilgængelig via separate dashboards. Det kræver en indsats at forstå alle de mulige funktioner og indstillinger, og hvordan de påvirker klyngen. Men alligevel er det ingen steder så komplekst, som administrationen af Oracle-servere plejede at være i tilfældet med de lokale løsninger.
Selvom der er forskellige AWS-grænser i Redshift, der sætter nogle grænser for, hvordan det skal bruges på daglig basis (for eksempel hårde grænser for antallet af samtidige aktive brugere eller sessioner i en databaseklynge), er det faktum, at operationer er eksekveret virkelig hurtigt hjælper med at omgå disse grænser til en vis grad.

Fordele og ulemper
Fordelene at overveje:
- Native AWS cloud data warehouse service, der er nem at integrere med andre tjenester.
- Et centralt sted til lagring, overvågning og indtagelse af forskellige typer datakilder fra vidt forskellige kildesystemer.
- Hvis du nogensinde har ønsket at have et serverløst datavarehus uden infrastrukturen til at vedligeholde det, kan du nu.
- Optimeret til højtydende analyser og rapportering. I modsætning til en data lake-løsning er der en stærk relationel datamodel til lagring af alle indkommende data.
- Redshift databasemotor stammer fra PostgreSQL, som sikrer høj kompatibilitet med andre databasesystemer.
- Meget nyttige COPY- og UNLOAD-udsagn til at indlæse og aflæse data fra og til S3-bøtter.
Ulemperne at overveje:
- Redshift understøtter ikke en stor mængde af samtidige aktive sessioner. Sessionerne vil blive sat i bero og behandlet sekventielt. Selvom det måske ikke er et problem i de fleste tilfælde, da operationerne er virkelig hurtige, er det en begrænsende faktor i systemer med mange aktive brugere.
- Selvom Redshift understøtter en masse funktionaliteter, der tidligere var kendt fra modne Oracle-systemer, er det stadig ikke på samme niveau. Nogle af de forventede funktioner er der måske bare ikke (som DB-triggere). Eller Redshift understøtter dem i ret begrænset form (som materialiserede visninger).
- Når du har brug for et mere avanceret brugerdefineret databehandlingsjob, skal du oprette det fra bunden. Det meste af tiden, brug Python eller Javascript kodesprog. Det er ikke så naturligt som PL/SQL i tilfældet med Oracle-systemet, hvor selv funktionen og procedurerne bruger et sprog, der ligner SQL-forespørgsler.
Formål og Real-World Use Case
Redshift kan være dit centrale lager for alle de forskellige datakilder, der tidligere har levet uden for skyen. Det er en gyldig erstatning for tidligere Oracle data warehouse-løsninger. Da det også er en relationel database, er migreringen fra Oracle endda en ganske simpel operation.
Hvis du har eksisterende data warehouse-løsninger mange steder, som ikke rigtig er samlet med hensyn til tilgang, struktur eller et foruddefineret sæt af fælles processer, der skal køre over dataene, er Redshift et godt valg.
Det vil blot give dig en mulighed for at samle alle de forskellige data warehouse-systemer fra forskellige steder og lande under ét tag. Du kan stadig adskille dem efter land, så dataene forbliver sikre og kun tilgængelige for dem, der har brug for dem. Men samtidig vil det give dig mulighed for at bygge en samlet lagerløsning, der dækker alle virksomhedens data.
En anden sag kan være, hvis målet er at bygge en datavarehusplatform med omfattende support fra selvbetjeninger. Du kan forstå det som et sæt behandlinger, som individuelle systembrugere kan bygge. Men samtidig er de aldrig en del af den fælles platformsløsning. Det betyder, at sådanne tjenester kun forbliver tilgængelige for skaberen eller den gruppe af mennesker, der er defineret af den oprettede. De vil ikke påvirke resten af brugerne på nogen måde.
Tjek vores sammenligning mellem Datalake og Datawarehouse.
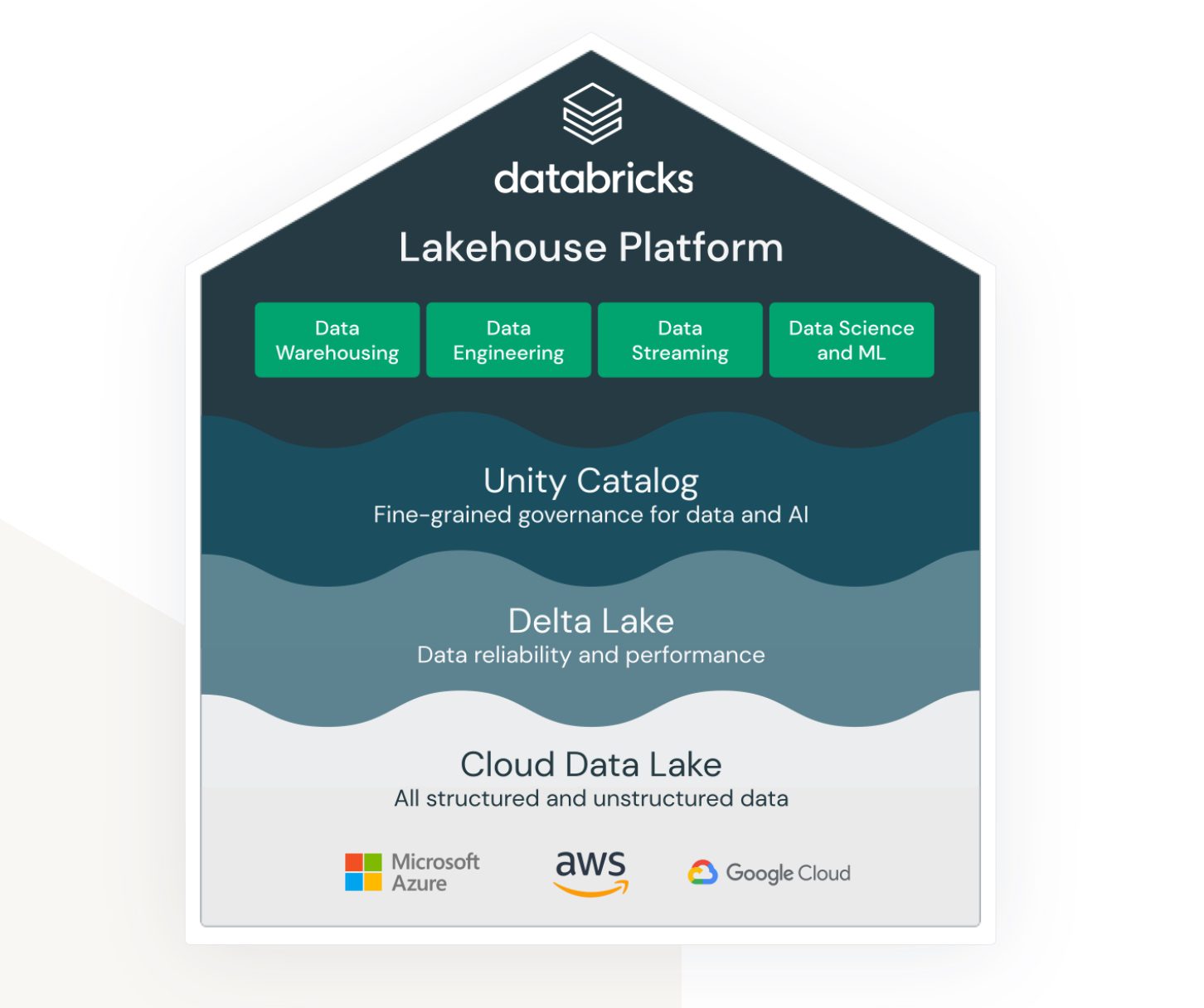
Lakehouse af Databricks på AWS
 Kilde: databricks.com
Kilde: databricks.com
Lakehouse er et udtryk, der virkelig er bundet til Databricks-tjenesten. Selvom det ikke er en indbygget AWS-tjeneste, lever og fungerer den meget pænt i AWS-økosystemet og giver forskellige muligheder for, hvordan man forbinder og integrerer med andre AWS-tjenester.
Databricks sigter mod at forbinde (tidligere) meget forskellige områder:
- En løsning til datasø-lagring af ustrukturerede, semi-strukturerede og strukturerede data.
- En løsning til datavarehusstrukturerede og hurtigt tilgængelige forespørgselsdata (også kaldet Delta Lake).
- En løsning, der understøtter analyse og maskinlæring over datasøen.
- Datastyring for alle ovenstående områder med centraliseret administration og færdige værktøjer til at understøtte produktiviteten for forskellige typer udviklere og brugere.
Det er en fælles platform, som dataingeniører, SQL-udviklere og maskinlæringsdataforskere kan bruge samtidigt. Hver af grupperne har også et sæt værktøjer, som de kan bruge til at udføre deres opgaver.
Så Databricks sigter mod en altomfattende løsning, der forsøger at kombinere fordelene ved datasøen og datavarehuset i en enkelt løsning. Oven i det giver det værktøjerne til at teste og køre maskinlæringsmodeller direkte over allerede byggede datalagre.

Fordele og ulemper
Fordelene at overveje:
- Databricks er en meget skalerbar dataplatform. Den skaleres afhængigt af arbejdsbelastningens størrelse, og den gør det endda automatisk.
- Det er et samarbejdsmiljø for datavidenskabsfolk, dataingeniører og forretningsanalytikere. At have muligheden for at gøre alt dette i samme rum og sammen er en stor fordel. Ikke kun fra et organisatorisk perspektiv, men det hjælper også med at spare en anden omkostning, der ellers er nødvendig for separate miljøer.
- AWS Databricks integreres problemfrit med andre AWS-tjenester, såsom Amazon S3, Amazon Redshift og Amazon EMR. Dette giver brugerne mulighed for nemt at overføre data mellem tjenester og drage fordel af hele udvalget af AWS cloud-tjenester.
Ulemperne at overveje:
- Databricks kan være komplekse at konfigurere og administrere, især for brugere, der er nye til big data-behandling. Det kræver et betydeligt niveau af teknisk ekspertise at få mest muligt ud af platformen.
- Selvom Databricks er omkostningseffektive i forhold til sin pay-as-you-go prismodel, kan det stadig være dyrt for store databehandlingsprojekter. Omkostningerne ved at bruge platformen kan hurtigt stige, især hvis brugerne skal skalere deres ressourcer op.
- Databricks leverer en række præ-byggede værktøjer og skabeloner, men dette kan også være en begrænsning for brugere, der har brug for flere tilpasningsmuligheder. Platformen er muligvis ikke egnet til brugere, der kræver mere fleksibilitet og kontrol over deres arbejdsgange til behandling af big data.
Formål og anvendelse i den virkelige verden
AWS Databricks er bedst egnet til store virksomheder med en meget stor mængde data. Her kan det dække kravet om at indlæse og kontekstualisere forskellige datakilder fra forskellige eksterne systemer.
Ofte er kravet at levere data i realtid. Det betyder fra det tidspunkt, hvor dataene vises i kildesystemet, at processerne skal samles op med det samme og behandle og gemme dataene i Databricks øjeblikkeligt eller med kun minimal forsinkelse. Hvis forsinkelsen er noget over et minut, betragtes det som næsten-realtidsbehandling. Under alle omstændigheder er begge scenarier ofte opnåelige med Databricks-platformen. Dette skyldes hovedsageligt den omfattende mængde af adaptere og realtidsgrænseflader, der forbinder til forskellige andre native AWS-tjenester.
Databricks kan også nemt integreres med Informatica ETL-systemer. Når organisationssystemet allerede bruger Informatica-økosystemet i vid udstrækning, ligner Databricks en god kompatibel tilføjelse til platformen.
Afsluttende ord
Da datamængden fortsætter med at vokse eksponentielt, er det godt at vide, at der er løsninger, der kan klare det effektivt. Det, der engang var et mareridt at administrere og vedligeholde, kræver meget lidt administrationsarbejde. Teamet kan fokusere på at skabe værdi ud af dataene.
Afhængigt af dine behov skal du blot vælge den service, der kan håndtere det. Mens AWS Databricks er noget, du sandsynligvis bliver nødt til at holde fast i, efter at beslutningen er truffet, er de andre alternativer ret mere fleksible, selvom de er mindre egnede, især deres serverløse tilstande. Det er ret nemt at migrere til en anden løsning senere.