

Er du klar til at lære funktionsteknik til maskinlæring og datavidenskab? Du er på det rigtige sted!
Feature engineering er en kritisk færdighed til at udtrække værdifuld indsigt fra data, og i denne hurtige guide vil jeg opdele det i enkle, fordøjelige bidder. Så lad os dykke direkte ind og komme i gang med din rejse til at mestre udtræk af funktioner!
Indholdsfortegnelse
Hvad er Feature Engineering?

Når du opretter en maskinlæringsmodel relateret til et forretnings- eller eksperimentelt problem, leverer du læringsdata i kolonner og rækker. Inden for datavidenskab og ML-udviklingsdomænet er kolonner kendt som attributterne eller variablerne.
Granulære data eller rækker under disse kolonner er kendt som observationer eller forekomster. Kolonnerne eller attributterne er funktionerne i et rådatasæt.
Disse rå funktioner er ikke nok eller optimale til at træne en ML-model. For at reducere støjen fra de indsamlede metadata og maksimere unikke signaler fra funktioner, skal du transformere eller konvertere metadatakolonner til funktionelle funktioner gennem feature engineering.
Eksempel 1: Finansiel modellering
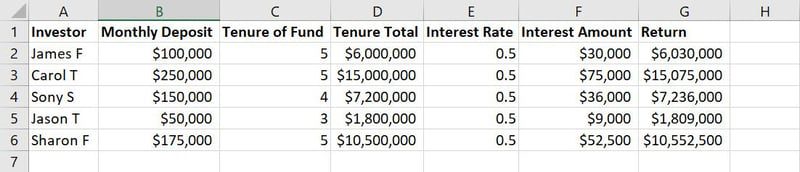 Rådata til ML-modeltræning
Rådata til ML-modeltræning
For eksempel i ovenstående billede af et eksempeldatasæt er kolonnerne fra A til G funktioner. Værdier eller tekststrenge i hver kolonne langs rækkerne, som navne, indskudsbeløb, indbetalingsår, renter osv., er observationer.
I ML-modellering skal du slette, tilføje, kombinere eller transformere data for at skabe meningsfulde funktioner og reducere størrelsen af den overordnede modeltræningsdatabase. Dette er feature engineering.
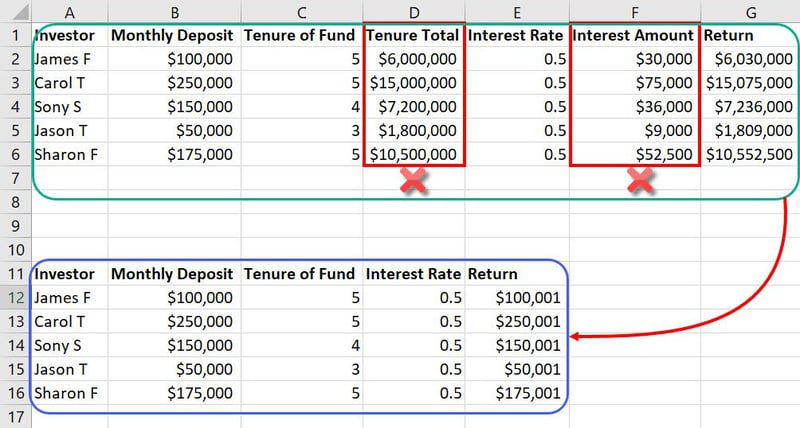 Eksempel på feature engineering
Eksempel på feature engineering
I det samme datasæt, der er nævnt tidligere, er funktioner som Tenure Total og Interest Amount unødvendige input. Disse vil simpelthen tage mere plads og forvirre ML-modellen. Så du kan reducere to funktioner fra i alt syv funktioner.
Da databaserne i ML-modeller indeholder tusindvis af kolonner og millioner af rækker, påvirker reduktionen af to funktioner projektet meget.
Eksempel 2: AI Music Playlist Maker
Nogle gange kan du oprette en helt ny funktion ud af flere eksisterende funktioner. Antag, at du opretter en AI-model, der automatisk opretter en afspilningsliste med musik og sange i henhold til begivenhed, smag, tilstand osv.
Nu har du indsamlet data om sange og musik fra forskellige kilder og oprettet følgende database:
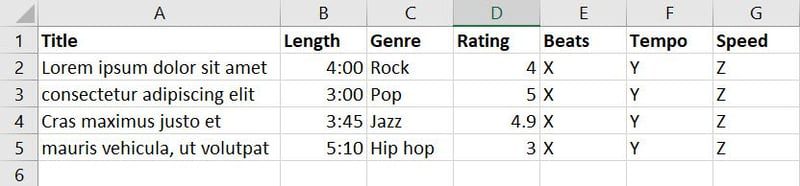
Der er syv funktioner i ovenstående database. Men da dit mål er at træne ML-modellen til at afgøre, hvilken sang eller musik der er egnet til hvilken begivenhed, kan du sammenlægge funktioner som Genre, Rating, Beats, Tempo og Speed i en ny funktion kaldet Applicability.
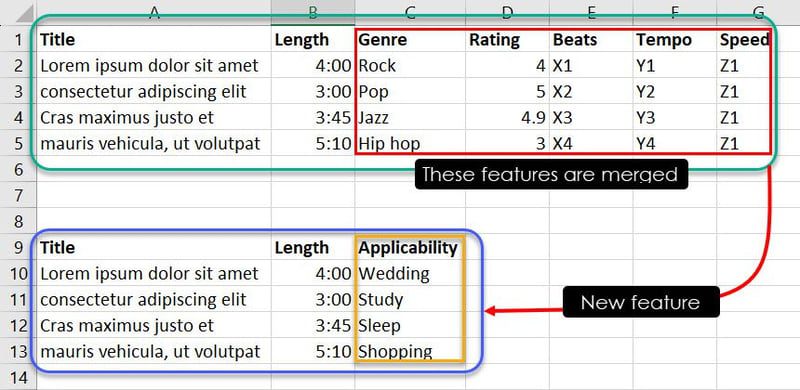
Nu kan du enten gennem ekspertise eller mønsteridentifikation kombinere visse forekomster af funktioner for at afgøre, hvilken sang der er egnet til hvilken begivenhed. For eksempel fortæller observationer som Jazz, 4.9, X3, Y3 og Z1 ML-modellen, at sangen Cras maximus justo et skal være på brugerens spilleliste, hvis de leder efter en sang om søvn.
Typer af funktioner i maskinlæring
Kategoriske træk
Disse er dataattributter, der repræsenterer forskellige kategorier eller etiketter. Du skal bruge denne type til at tagge kvalitative datasæt.
#1. Ordinale kategoriske træk
Ordinaltræk har kategorier med en meningsfuld rækkefølge. For eksempel har uddannelsesniveauer som gymnasier, bachelorer, kandidater osv. en klar skelnen i standarderne, men der er ingen kvantitative forskelle.
#2. Nominelle kategoriske træk
Nominelle funktioner er kategorier uden nogen iboende rækkefølge. Eksempler kunne være farver, lande eller dyretyper. Desuden er der kun kvalitative forskelle.
Array funktioner
Denne funktionstype repræsenterer data organiseret i arrays eller lister. Dataforskere og ML-udviklere bruger ofte Array Features til at håndtere sekvenser eller indlejre kategoriske data.
#1. Indlejring af Array-funktioner
Embedding-arrays konverterer kategoriske data til tætte vektorer. Det er almindeligt anvendt i naturlig sprogbehandling og anbefalingssystemer.
#2. Liste Array-funktioner
Listearrays gemmer sekvenser af data, såsom lister over elementer i en ordre eller historikken for handlinger.
Numeriske funktioner
Disse ML træningsfunktioner bruges til at udføre matematiske operationer, da disse funktioner repræsenterer kvantitative data.
#1. Interval numeriske funktioner
Intervalfunktioner har ensartede intervaller mellem værdier, men intet sandt nulpunkt – for eksempel temperaturovervågningsdata. Her betyder nul frysetemperatur, men attributten er der stadig.
#2. Forhold Numeriske funktioner
Forholdsfunktioner har ensartede intervaller mellem værdier og et sandt nulpunkt. Eksempler inkluderer alder, højde og indkomst.
Betydningen af Feature Engineering i ML og Data Science
Dernæst vil vi udforske trin-for-trin-processen med feature engineering.
Feature Engineering Process Trin-for-trin

Dernæst vil vi diskutere feature engineering metoder.
Feature Engineering metoder
#1. Principal Component Analysis (PCA)
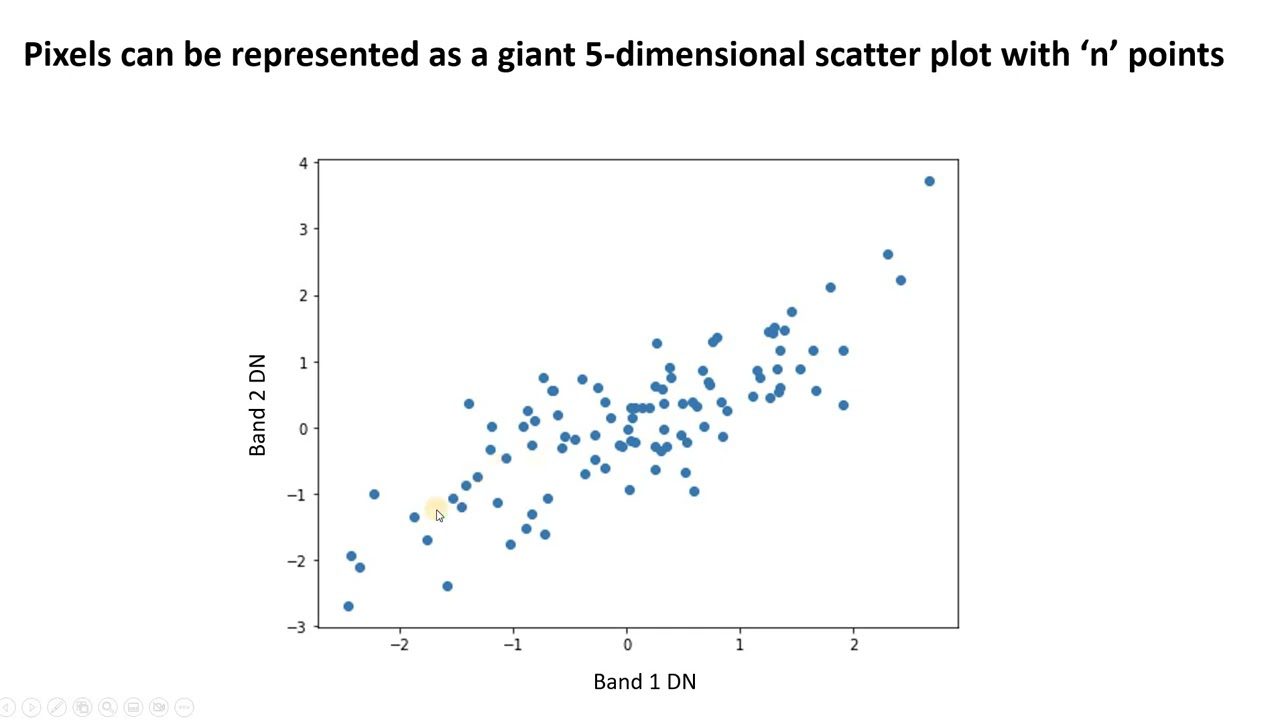
PCA forenkler komplekse data ved at finde nye ukorrelerede funktioner. Disse kaldes hovedkomponenter. Du kan bruge det til at reducere dimensionalitet og forbedre modellens ydeevne.
#2. Polynomiske egenskaber
Oprettelse af polynomiske funktioner betyder at tilføje kræfter af eksisterende funktioner for at fange komplekse relationer i dine data. Det hjælper din model med at forstå ikke-lineære mønstre.
#3. Håndtering af outliers
Outliers er usædvanlige datapunkter, der kan påvirke ydeevnen af dine modeller. Du skal identificere og håndtere outliers for at forhindre skæve resultater.
#4. Log Transform
Logaritmisk transformation kan hjælpe dig med at normalisere data med en skæv fordeling. Det reducerer virkningen af ekstreme værdier for at gøre dataene mere egnede til modellering.
#5. t-Distribueret Stokastisk Neighbor Embedding (t-SNE)
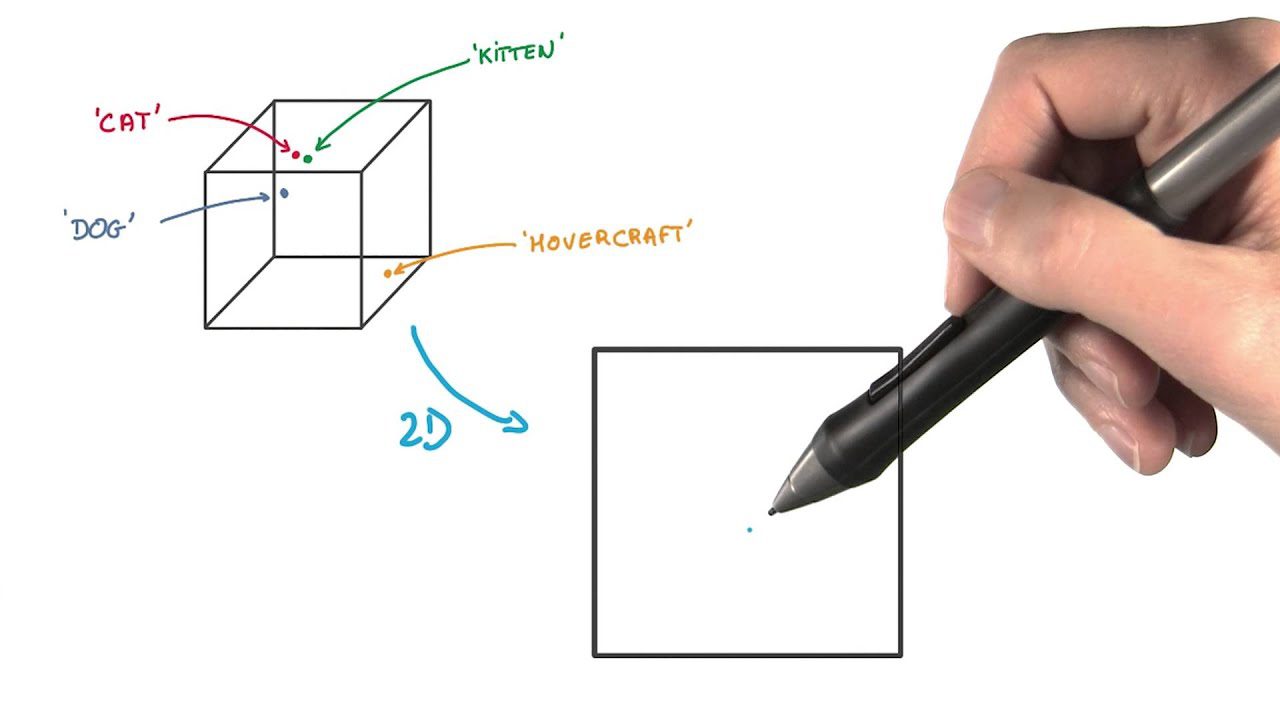
t-SNE er nyttig til at visualisere højdimensionelle data. Det reducerer dimensionalitet og gør klynger mere synlige, samtidig med at datastrukturen bevares.
I denne funktionsekstraktionsmetode repræsenterer du datapunkter som prikker i et rum med lavere dimensioner. Derefter placerer du de lignende datapunkter i det oprindelige højdimensionelle rum og modelleres til at være tæt på hinanden i den lavere dimensionelle repræsentation.
Den adskiller sig fra andre dimensionsreduktionsmetoder ved at bevare strukturen og afstandene mellem datapunkter.
#6. One-Hot-kodning
One-hot-kodning transformerer kategoriske variabler til binært format (0 eller 1). Så du får nye binære kolonner for hver kategori. One-hot-kodning gør kategoriske data egnede til ML-algoritmer.
#7. Tælle kodning
Optællingskodning erstatter kategoriske værdier med det antal gange, de vises i datasættet. Det kan fange værdifuld information fra kategoriske variabler.
I denne metode til funktionskonstruktion bruger du frekvensen eller antallet af hver kategori som en ny numerisk funktion i stedet for at bruge de originale kategorietiketter.
#8. Funktionsstandardisering

Træk af større værdier dominerer ofte træk ved små værdier. Dermed kan ML-modellen nemt blive forudindtaget. Standardisering forhindrer sådanne årsager til skævheder i en maskinlæringsmodel.
Standardiseringsprocessen involverer typisk følgende to almindelige teknikker:
- Z-Score Standardisering: Denne metode transformerer hver funktion, så den har et middelværdi (gennemsnit) på 0 og en standardafvigelse på 1. Her trækker du middelværdien af træk fra hvert datapunkt og dividerer resultatet med standardafvigelsen.
- Min-Max-skalering: Min-max-skalering transformerer dataene til et specifikt område, typisk mellem 0 og 1. Du kan opnå dette ved at trække funktionens minimumværdi fra hvert datapunkt og dividere med området.
#9. Normalisering
Gennem normalisering skaleres numeriske funktioner til et fælles område, normalt mellem 0 og 1. Det fastholder de relative forskelle mellem værdier og sikrer, at alle funktioner er på lige vilkår.

#1. Funktionsværktøjer
Funktionsværktøjer er en open source Python-ramme, der automatisk opretter funktioner fra tidsmæssige og relationelle datasæt. Det kan bruges med værktøjer, du allerede bruger til at udvikle ML-pipelines.
Løsningen bruger Deep Feature Synthesis til at automatisere feature engineering. Den har et bibliotek med funktioner på lavt niveau til at skabe funktioner. Featuretools har også en API, som også er ideel til præcis håndtering af tid.
#2. CatBoost
Hvis du leder efter et open source-bibliotek, der kombinerer flere beslutningstræer for at skabe en kraftfuld forudsigelsesmodel, så gå efter CatBoost. Denne løsning giver nøjagtige resultater med standardparametre, så du ikke skal bruge timer på at finjustere parametrene.
CatBoost lader dig også bruge ikke-numeriske faktorer til at forbedre dine træningsresultater. Med det kan du også forvente at få mere præcise resultater og hurtige forudsigelser.
#3. Feature-motor
Feature-motor er et Python-bibliotek med flere transformere og udvalgte funktioner, som du kan bruge til ML-modeller. Transformatorerne, den inkluderer, kan bruges til variabel transformation, variabel oprettelse, dato-tidsfunktioner, forbehandling, kategorisk kodning, outlier-begrænsning eller fjernelse og manglende dataimputering. Den er i stand til automatisk at genkende numeriske, kategoriske og datetime-variabler.
Feature Engineering læringsressourcer
Onlinekurser og virtuelle klasser

#1. Feature Engineering for Machine Learning i Python: Datacamp
Denne Datacamp kursus om Feature Engineering for Machine Learning i Python giver dig mulighed for at skabe nye funktioner, der forbedrer din maskinlæringsmodels ydeevne. Det vil lære dig at udføre feature engineering og datamunging for at udvikle sofistikerede ML-applikationer.
#2. Feature Engineering for Machine Learning: Udemy
Fra Feature Engineering for Machine Learning kursusvil du lære emner, herunder imputation, variabelkodning, feature-ekstraktion, diskretisering, datetime-funktionalitet, outliers osv. Deltagerne vil også lære at arbejde med skæve variabler og håndtere sjældne, usete og sjældne kategorier.
#3. Feature Engineering: Pluralsight
Det her Pluralsight læringsforløbet har i alt seks forløb. Disse kurser hjælper dig med at lære vigtigheden af feature engineering i ML workflow, måder at anvende dets teknikker på og feature ekstraktion fra tekst og billeder.
#4. Funktionsvalg til maskinlæring: Udemy
Ved hjælp af dette Udemy kursusdeltagere kan lære funktionsblanding, filter, indpakning og indlejrede metoder, rekursiv funktionseliminering og udtømmende søgning. Den diskuterer også teknikker til valg af funktioner, herunder dem med Python, Lasso og beslutningstræer. Dette kursus indeholder 5,5 timers on-demand video og 22 artikler.
#5. Feature Engineering for Machine Learning: Fantastisk læring
Dette kursus fra Fantastisk læring vil introducere dig til feature engineering, mens du lærer dig om over- og under-sampling. Desuden vil det lade dig udføre praktiske øvelser på modeljustering.
#6. Feature Engineering: Coursera
Deltag i Coursera kursus for at bruge BigQuery ML, Keras og TensorFlow til at udføre feature engineering. Dette kursus på mellemniveau dækker også avanceret funktionsteknik.
Digitale eller indbundne bøger

#1. Feature Engineering til Machine Learning
Denne bog lærer dig, hvordan du omdanner funktioner til formater til maskinlæringsmodeller.
Det lærer dig også funktionstekniske principper og praktisk anvendelse gennem træning.
#2. Feature Engineering og udvælgelse
Ved at læse denne bog vil du lære metoderne til at udvikle prædiktive modeller i forskellige stadier.
Ud fra det kan du lære teknikker til at finde de bedste prædiktorrepræsentationer til modellering.
#3. Funktionsteknik gjort let
Bogen er en guide til at forbedre forudsigelseskraften af ML-algoritmer.
Det lærer dig at designe og skabe effektive funktioner til ML-baserede applikationer ved at tilbyde dybdegående dataindsigt.
#4. Feature Engineering Bookcamp
Denne bog beskæftiger sig med praktiske casestudier for at lære dig funktionstekniske teknikker til bedre ML-resultater og opgraderet datastrid.
At læse dette vil sikre, at du kan levere forbedrede resultater uden at bruge meget tid på at finjustere ML-parametrene.
#5. The Art of Feature Engineering
Ressourcen fungerer som et væsentligt element for enhver dataforsker eller maskinlæringsingeniør.
Bogen bruger en tilgang på tværs af domæner til at diskutere grafer, tekster, tidsserier, billeder og casestudier.
Konklusion
Så det er sådan, du kan udføre feature engineering. Nu hvor du kender definitionen, den trinvise proces, metoderne og læringsressourcerne, kan du implementere disse i dine ML-projekter og se succesen!
Næste op, tjek artiklen om forstærkende læring.