

I nutidens datadrevne verden er den traditionelle metode til manuel dataindsamling forældet. En computer med internetforbindelse på hvert skrivebord gjorde nettet til en enorm datakilde. Den mere effektive og tidsbesparende moderne metode til dataindsamling er således web-skrabning. Og når det kommer til web-skrabning, har Python et værktøj kaldet Beautiful Soup. I dette indlæg vil jeg lede dig gennem installationstrinnene af Beautiful Soup for at komme i gang med web-skrabning.
Før du installerer og arbejder med Beautiful Soup, lad os finde ud af, hvorfor du skal gå efter det.
Indholdsfortegnelse
Hvad er en smuk suppe?
Lad os foregive, at du forsker i “COVIDs indvirkning på folks sundhed” og har fundet et par websider, der indeholder relevante data. Men hvad nu, hvis de ikke tilbyder dig en enkelt-klik download mulighed for at låne deres data? Her kommer den smukke suppe i spil.
Beautiful Soup er blandt indekset for Python-biblioteker til at trække data fra målrettede websteder. Det er mere behageligt at hente data fra HTML- eller XML-sider.
Leonard Richardson bragte ideen om Beautiful Soup til at skrabe nettet frem i lyset i 2004. Men hans bidrag til projektet fortsætter til dette i dag. Han opdaterer stolt hver smuk suppes nye udgivelse på sin Twitter-konto.
Selvom Beautiful Soup for web scraping blev udviklet ved hjælp af Python 3.8, fungerer den også perfekt med både Python 3 og Python 2.4.
Ofte bruger websteder captcha-beskyttelse til at redde deres data fra AI-værktøjer. I dette tilfælde kan nogle få ændringer af ‘brugeragent’-headeren i Beautiful Soup eller brug af Captcha-løsnings-API’er efterligne en pålidelig browser og narre detektionsværktøjet.
Men hvis du ikke har tid til at udforske Smuk suppe eller ønsker, at skrabningen skal foregå effektivt og med lethed, så bør du ikke gå glip af at tjekke denne web-scraping API, hvor du bare kan angive en URL og få dataene ind. dine hænder.
Hvis du allerede er programmør, vil det ikke være skræmmende at bruge Beautiful Soup til skrabning på grund af dens ligetil syntaks til at navigere på websider og udtrække de ønskede data baseret på betinget parsing. Samtidig er den også nybegyndervenlig.
Selvom Beautiful Soup ikke er til avanceret skrabning, fungerer det bedst at skrabe dataene fra filer skrevet på markup-sprog.
Klar og detaljeret dokumentation er et andet brownie-punkt, som Beautiful Soup pakkede.
Lad os finde en nem måde at få smuk suppe ind i din maskine.
Hvordan installeres smuk suppe til webskrabning?
Pip – En ubesværet Python-pakkehåndtering udviklet i 2008 er nu et standardværktøj blandt udviklere til at installere alle Python-biblioteker eller afhængigheder.
Pip leveres som standard med installationen af de seneste Python-versioner. Så hvis du har nogle nyere Python-versioner installeret på dit system, er du god til at gå.
Åbn kommandoprompten og skriv følgende pip-kommando for at installere den smukke suppe med det samme.
pip install beautifulsoup4
Du vil se noget, der ligner det følgende skærmbillede på din skærm.
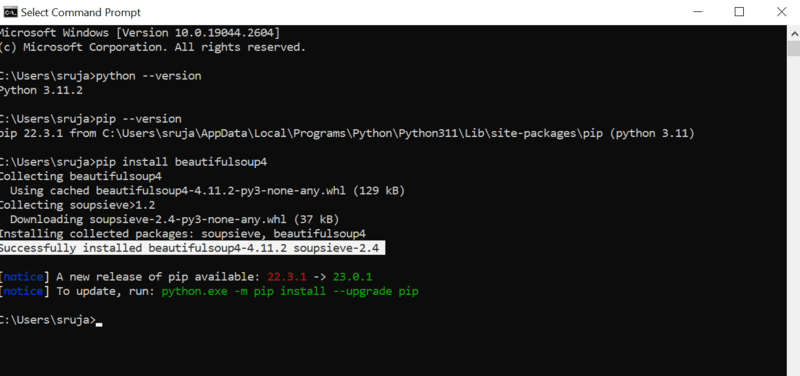
Sørg for, at du har opdateret PIP-installationsprogrammet til den nyeste version for at undgå almindelige fejl.
Kommandoen til at opdatere pip-installationsprogrammet til den nyeste version er:
pip install --upgrade pip
Vi har med succes dækket halvdelen af jorden i dette indlæg.
Nu har du Smuk suppe installeret på din maskine, så lad os dykke ned i, hvordan du bruger den til web-skrabning.
Hvordan importerer og arbejder man med smuk suppe til webskrabning?
Indtast følgende kommando i din python IDE for at importere smuk suppe til det aktuelle python-script.
from bs4 import BeautifulSoup
Nu er den smukke suppe i din Python-fil, som du kan bruge til at skrabe.
Lad os se på et kodeeksempel for at lære at udtrække de ønskede data med smuk suppe.
Vi kan fortælle smukke Soup at lede efter specifikke HTML-tags på kildewebstedet og skrabe dataene i disse tags.
I dette stykke vil jeg bruge marketwatch.com, som opdaterer aktiekurserne i realtid for forskellige virksomheder. Lad os hente nogle data fra denne hjemmeside for at blive fortrolig med biblioteket Beautiful Soup.
Importer “requests”-pakke, der giver os mulighed for at modtage og svare på HTTP-anmodninger og “urllib” for at indlæse websiden fra dens URL.
from urllib.request import urlopen import requests
Gem websidelinket i en variabel, så du nemt kan få adgang til det senere.
url="https://www.marketwatch.com/investing/stock/amzn"
Det næste ville være at bruge “urlopen”-metoden fra “urllib”-biblioteket til at gemme HTML-siden i en variabel. Send URL’en til funktionen “urlopen” og gem resultatet i en variabel.
page = urlopen(url)
Opret et smukt suppeobjekt og parse den ønskede webside ved hjælp af “html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')
Nu er hele HTML-scriptet på den målrettede webside gemt i variablen ‘soup_obj’.
Før vi fortsætter, lad os se på den målrettede sides kildekode for at vide mere om HTML-scriptet og tags.
Højreklik hvor som helst på websiden med musen. Så finder du en inspektionsmulighed, som vist nedenfor.
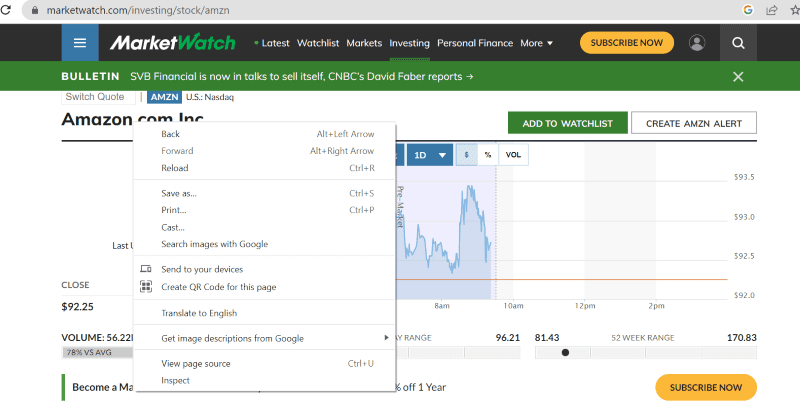
Klik på inspicer for at se kildekoden.
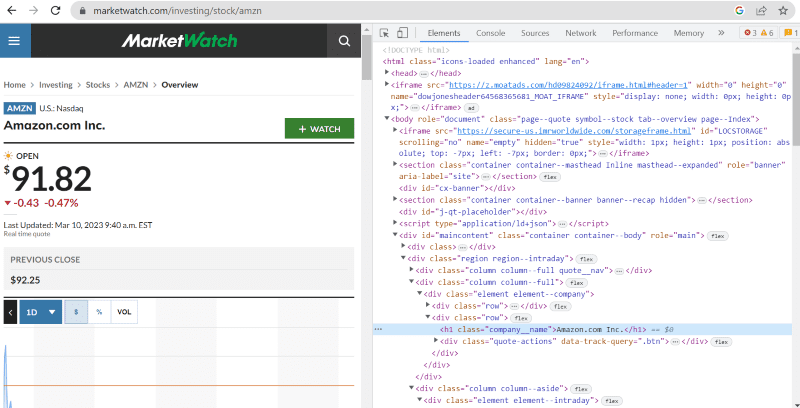
I ovenstående kildekode kan du finde tags, klasser og mere specifik information om hvert element, der er synligt på webstedets grænseflade.
“Find”-metoden i smukke Soup giver os mulighed for at søge efter de ønskede HTML-tags og hente dataene. For at gøre dette giver vi klassens navn og tags til den metode, der udtrækker specifikke data.
For eksempel “Amazon.com Inc.” vist på websiden har klassenavnet: ‘company__name’ tagget under ‘h1’. Vi kan indtaste disse oplysninger i ‘find’-metoden for at udtrække det relevante HTML-uddrag til en variabel.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Lad os udskrive HTML-scriptet, der er gemt i variablen “navn” og den nødvendige tekst på skærmen.
print(name) print(name.text)

Du kan se de udtrukne data udskrevet på skærmen.
Web Skrab IMDb-webstedet
Mange af os leder efter filmvurderinger på IMBbs websted, før vi ser en film. Denne demonstration giver dig en liste over topbedømte film og hjælper dig med at vænne dig til den smukke suppe til webskrabning.
Trin 1: Importer den smukke suppe og anmoder om biblioteker.
from bs4 import BeautifulSoup import requests
Trin 2: Lad os tildele den URL, vi ønsker at skrabe, til en variabel kaldet ‘url’ for nem adgang i koden.
“Requests”-pakken bruges til at hente HTML-siden fra URL’en.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Trin 3: I det følgende kodestykke analyserer vi HTML-siden for den aktuelle URL for at skabe et objekt med smuk suppe.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Variablen “soup_obj” indeholder nu hele HTML-scriptet på den ønskede webside, som i det følgende billede.
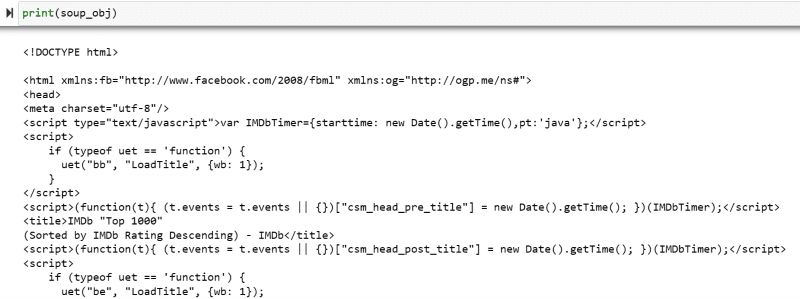
Lad os inspicere kildekoden på websiden for at finde HTML-scriptet for de data, vi vil skrabe.
Hold markøren over det websideelement, du vil udpakke. Dernæst skal du højreklikke på det og gå med inspiceringsindstillingen for at se kildekoden for det specifikke element. Følgende billeder vil guide dig bedre.
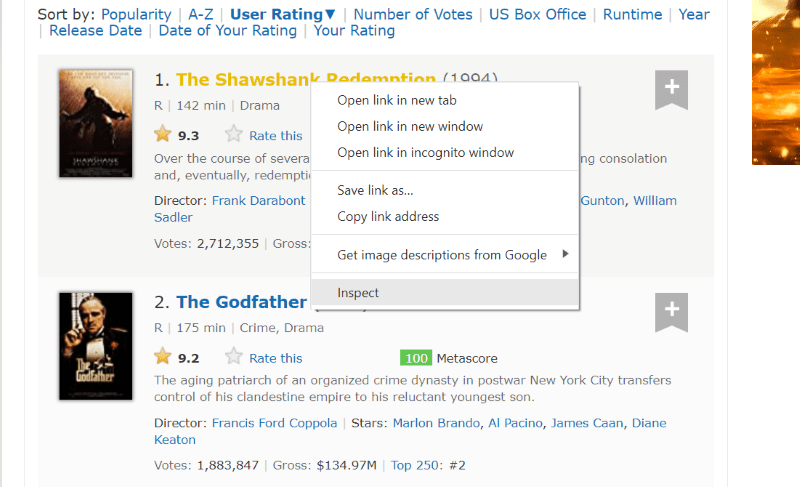
Klassens ‘lister-list’ indeholder alle de bedst bedømte filmrelaterede data som underopdelinger i successive div-tags.
I hvert filmkorts HTML-script, under klassens ‘lister-item mode-advanced’, har vi et tag ‘h3’, der gemmer filmens navn, rangering og udgivelsesår, som fremhævet i billedet nedenfor.
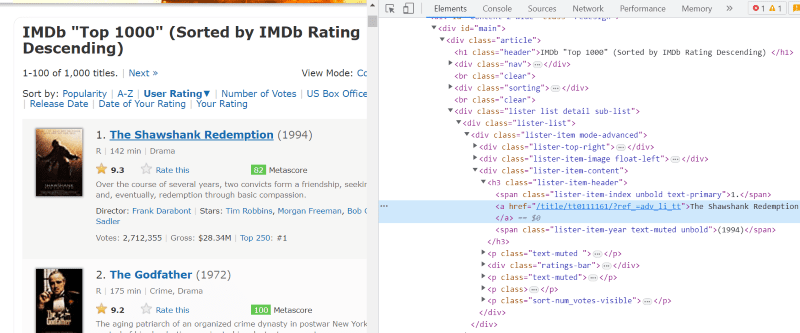
Bemærk: “Find”-metoden i smuk suppe søger efter det første mærke, der matcher det inputnavn, der er givet til det. I modsætning til “find”, leder “find_all”-metoden efter alle de tags, der matcher det givne input.
Trin 4: Du kan bruge metoderne “find” og “find_all” til at gemme HTML-scriptet for hver films navn, rangering og år i en listevariabel.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Trin 5: Gå gennem listen over film, der er gemt i variablen: “top_movies”, og udtræk navnet, rangeringen og året for hver film i tekstformat fra dets HTML-script ved hjælp af nedenstående kode.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
I output-skærmbilledet kan du se listen over film med deres navn, rang og udgivelsesår.
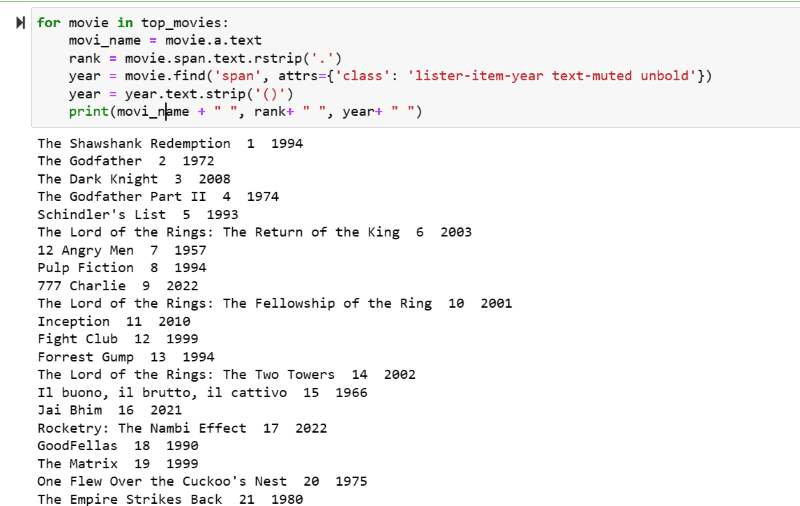
Du kan nemt flytte de udskrevne data til et excel-ark med noget python-kode og bruge det til din analyse.
Afsluttende ord
Dette indlæg guider dig til at installere smuk suppe til webskrabning. Også de skrabeeksempler, jeg har vist, skulle hjælpe dig i gang med Smuk suppe.
Da du er interesseret i, hvordan du installerer Beautiful Soup til web-skrabning, anbefaler jeg stærkt, at du tjekker denne forståelige guide for at vide mere om web-skrabning ved hjælp af Python.