
Google JAX eller Just After Execution er en ramme udviklet af Google for at fremskynde maskinlæringsopgaver.
Du kan betragte det som et bibliotek for Python, som hjælper med hurtigere opgaveudførelse, videnskabelig databehandling, funktionstransformationer, deep learning, neurale netværk og meget mere.
Indholdsfortegnelse
Om Google JAX
Den mest fundamentale beregningspakke i Python er NumPy-pakken, som har alle funktioner som aggregeringer, vektoroperationer, lineær algebra, n-dimensionelle array- og matrixmanipulationer og mange andre avancerede funktioner.
Hvad hvis vi yderligere kunne fremskynde de beregninger, der udføres ved hjælp af NumPy – især for store datasæt?
Har vi noget, der kunne fungere lige godt på forskellige typer processorer som en GPU eller TPU, uden nogen kodeændringer?
Hvad med, hvis systemet kunne udføre komponerbare funktionstransformationer automatisk og mere effektivt?
Google JAX er et bibliotek (eller framework, som Wikipedia siger), der gør netop det og måske meget mere. Det blev bygget til at optimere ydeevnen og effektivt udføre maskinlæring (ML) og deep learning-opgaver. Google JAX leverer følgende transformationsfunktioner, der gør den unik fra andre ML-biblioteker og hjælper med avanceret videnskabelig beregning til dyb læring og neurale netværk:
- Automatisk differentiering
- Auto vektorisering
- Automatisk parallelisering
- Just-in-time (JIT) kompilering
Google JAX’s unikke funktioner
Alle transformationerne bruger XLA (Accelerated Linear Algebra) for højere ydeevne og hukommelsesoptimering. XLA er en domænespecifik optimerende compilermotor, der udfører lineær algebra og accelererer TensorFlow-modeller. Brug af XLA oven på din Python-kode kræver ingen væsentlige kodeændringer!
Lad os udforske hver af disse funktioner i detaljer.
Funktioner i Google JAX
Google JAX kommer med vigtige komponerbare transformationsfunktioner for at forbedre ydeevnen og udføre deep learning-opgaver mere effektivt. For eksempel automatisk differentiering for at få gradienten af en funktion og finde afledte af en hvilken som helst rækkefølge. Tilsvarende, automatisk parallelisering og JIT til at udføre flere opgaver parallelt. Disse transformationer er nøglen til applikationer som robotteknologi, spil og endda forskning.
En komponerbar transformationsfunktion er en ren funktion, der transformerer et sæt data til en anden form. De kaldes komponerbare, da de er selvstændige (dvs. disse funktioner har ingen afhængigheder med resten af programmet) og er tilstandsløse (dvs. det samme input vil altid resultere i det samme output).
Y(x) = T: (f(x))
I ovenstående ligning er f(x) den oprindelige funktion, som en transformation anvendes på. Y(x) er den resulterende funktion efter at transformationen er anvendt.
For eksempel, hvis du har en funktion ved navn ‘total_bill_amt’, og du vil have resultatet som en funktionstransformation, kan du blot bruge den transformation, du ønsker, lad os sige gradient (grad):
grad_total_bill = grad(total_bill_amt)
Ved at transformere numeriske funktioner ved hjælp af funktioner som grad(), kan vi nemt få deres højere ordens derivater, som vi kan bruge i vid udstrækning i deep learning optimeringsalgoritmer som gradient descent, og dermed gøre algoritmerne hurtigere og mere effektive. På samme måde kan vi ved at bruge jit() kompilere Python-programmer just-in-time (dovent).
#1. Automatisk differentiering
Python bruger autograd-funktionen til automatisk at differentiere NumPy og native Python-kode. JAX bruger en modificeret version af autograd (dvs. grad) og kombinerer XLA (Accelerated Linear Algebra) for at udføre automatisk differentiering og finde derivater af enhver rækkefølge for GPU (Graphic Processing Units) og TPU (Tensor Processing Units).]
Hurtig note om TPU, GPU og CPU: CPU eller Central Processing Unit styrer alle operationer på computeren. GPU er en ekstra processor, der forbedrer computerkraften og kører avancerede operationer. TPU er en kraftfuld enhed specielt udviklet til komplekse og tunge arbejdsbelastninger som AI og deep learning algoritmer.
På samme måde som autograd-funktionen, som kan differentiere gennem loops, rekursioner, forgreninger og så videre, bruger JAX grad()-funktionen til reverse-mode gradienter (tilbagepropagation). Vi kan også differentiere en funktion til enhver rækkefølge ved hjælp af grad:
grad(grad(grad(sin θ))) (1.0)
Automatisk differentiering af højere orden
Som vi nævnte før, er grad ret nyttig til at finde de partielle afledte af en funktion. Vi kan bruge en delvis afledt til at beregne gradientnedgangen af en omkostningsfunktion med hensyn til de neurale netværksparametre i dyb læring for at minimere tab.
Beregning af partiel afledt
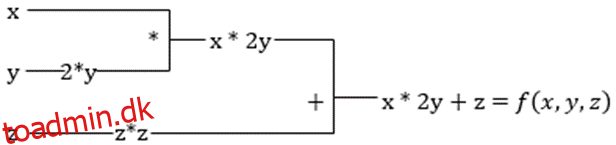
Antag, at en funktion har flere variable, x, y og z. At finde den afledede af en variabel ved at holde de andre variable konstante kaldes en partiel afledt. Antag at vi har en funktion,
f(x,y,z) = x + 2y + z2
Eksempel for at vise partiel afledt
Den partielle afledede af x vil være ∂f/∂x, som fortæller os, hvordan en funktion ændres for en variabel, når andre er konstante. Hvis vi udfører dette manuelt, skal vi skrive et program for at differentiere, anvende det for hver variabel og derefter beregne gradientnedstigningen. Dette ville blive en kompleks og tidskrævende affære for flere variabler.
Automatisk differentiering opdeler funktionen i et sæt af elementære operationer, såsom +, -, *, / eller sin, cos, tan, exp osv., og anvender derefter kædereglen til at beregne den afledede. Vi kan gøre dette i både frem- og baglæns tilstand.
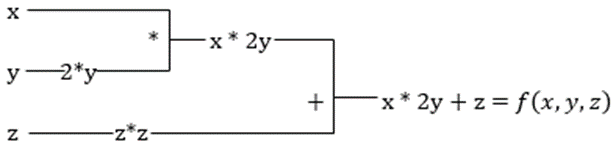
Det er det ikke! Alle disse beregninger sker så hurtigt (tænk på en million beregninger svarende til ovenstående og den tid, det kan tage!). XLA tager sig af hastigheden og ydeevnen.
#2. Accelereret lineær algebra
Lad os tage den foregående ligning. Uden XLA vil beregningen tage tre (eller flere) kerner, hvor hver kerne vil udføre en mindre opgave. For eksempel,
Kernel k1 –> x * 2y (multiplikation)
k2 –> x * 2y + z (tilføjelse)
k3 –> Reduktion
Hvis den samme opgave udføres af XLA, tager en enkelt kerne sig af alle de mellemliggende operationer ved at fusionere dem. De mellemliggende resultater af elementære operationer streames i stedet for at gemme dem i hukommelsen, hvilket sparer hukommelse og øger hastigheden.
#3. Just-in-time kompilering
JAX bruger internt XLA-kompileren til at øge udførelseshastigheden. XLA kan øge hastigheden på CPU, GPU og TPU. Alt dette er muligt ved at bruge JIT-kodeudførelsen. For at bruge dette kan vi bruge jit via import:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
En anden måde er ved at dekorere jit over funktionsdefinitionen:
@jit def my_function(x): …………some lines of code
Denne kode er meget hurtigere, fordi transformationen vil returnere den kompilerede version af koden til kalderen i stedet for at bruge Python-fortolkeren. Dette er især nyttigt til vektorinput, såsom arrays og matricer.
Det samme gælder for alle de eksisterende python-funktioner. For eksempel funktioner fra NumPy-pakken. I dette tilfælde bør vi importere jax.numpy som jnp i stedet for NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Når du har gjort dette, erstatter kerne-JAX-array-objektet kaldet DeviceArray standard-NumPy-arrayet. DeviceArray er doven – værdierne holdes i acceleratoren, indtil de skal bruges. Dette betyder også, at JAX-programmet ikke venter på, at resultaterne vender tilbage til det kaldende (Python)-program, og dermed følger en asynkron afsendelse.
#4. Automatisk vektorisering (vmap)
I en typisk maskinlæringsverden har vi datasæt med en million eller flere datapunkter. Mest sandsynligt ville vi udføre nogle beregninger eller manipulationer på hvert eller de fleste af disse datapunkter – hvilket er en meget tids- og hukommelseskrævende opgave! Hvis du f.eks. vil finde kvadratet af hvert af datapunkterne i datasættet, er det første du ville tænke på at oprette en løkke og tage kvadratet et efter et – argh!
Hvis vi opretter disse punkter som vektorer, kunne vi lave alle kvadraterne på én gang ved at udføre vektor- eller matrixmanipulationer på datapunkterne med vores foretrukne NumPy. Og hvis dit program kunne gøre dette automatisk – kan du bede om noget mere? Det er præcis, hvad JAX gør! Den kan automatisk vektorisere alle dine datapunkter, så du nemt kan udføre enhver handling på dem – hvilket gør dine algoritmer meget hurtigere og mere effektive.
JAX bruger vmap-funktionen til autovektorisering. Overvej følgende array:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Ved blot at gøre ovenstående vil kvadratmetoden udføres for hvert punkt i arrayet. Men hvis du gør følgende:
vmap(jnp.square(x))
Metodefirkanten vil kun udføres én gang, fordi datapunkterne nu vektoriseres automatisk ved hjælp af vmap-metoden, før funktionen udføres, og looping skubbes ned i det elementære operationsniveau – hvilket resulterer i en matrixmultiplikation i stedet for skalar multiplikation, hvilket giver bedre ydeevne .
#5. SPMD programmering (pmap)
SPMD – eller Single Program Multiple Data-programmering er afgørende i dybe læringssammenhænge – du vil ofte anvende de samme funktioner på forskellige datasæt, der ligger på flere GPU’er eller TPU’er. JAX har en funktion ved navn pumpe, som giver mulighed for parallel programmering på flere GPU’er eller en hvilken som helst accelerator. Ligesom JIT vil programmer, der bruger pmap, blive kompileret af XLA og eksekveret samtidigt på tværs af systemerne. Denne automatiske parallelisering virker til både fremadgående og tilbagegående beregninger.
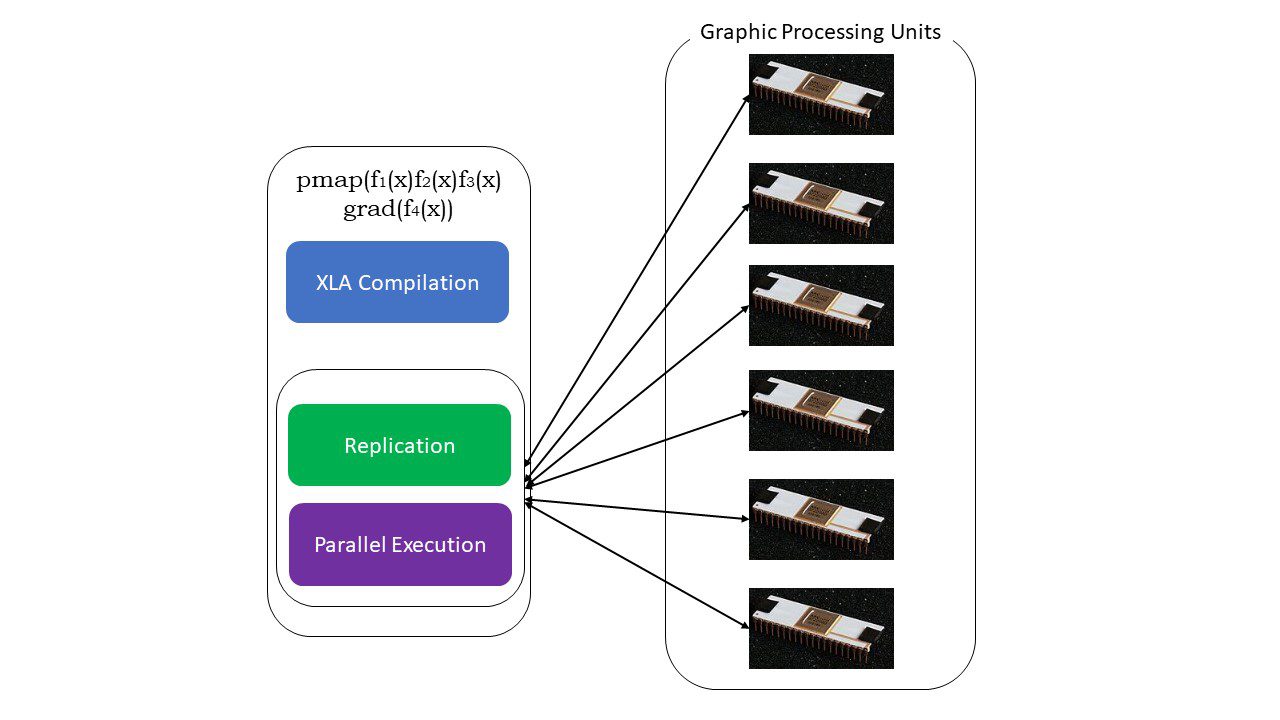 Hvordan virker pmap
Hvordan virker pmap
Vi kan også anvende flere transformationer på én gang i vilkårlig rækkefølge på enhver funktion som:
pmap(vmap(jit(grad (f(x)))))
Flere komponerbare transformationer
Begrænsninger for Google JAX
Google JAX-udviklere har tænkt godt over at fremskynde deep learning-algoritmer, mens de introducerer alle disse fantastiske transformationer. De videnskabelige beregningsfunktioner og pakker er på linje med NumPy, så du behøver ikke bekymre dig om indlæringskurven. JAX har dog følgende begrænsninger:
- Google JAX er stadig i de tidlige udviklingsstadier, og selvom dets hovedformål er ydelsesoptimering, giver det ikke meget fordel for CPU-computere. NumPy ser ud til at præstere bedre, og brug af JAX kan kun øge omkostningerne.
- JAX er stadig i sin forskning eller tidlige stadier og har brug for mere finjustering for at nå infrastrukturstandarderne for rammer som TensorFlow, som er mere etablerede og har mere foruddefinerede modeller, open source-projekter og læringsmateriale.
- Lige nu understøtter JAX ikke Windows-operativsystemet – du skal bruge en virtuel maskine for at få det til at fungere.
- JAX virker kun på rene funktioner – dem der ikke har nogen bivirkninger. For funktioner med bivirkninger er JAX muligvis ikke en god mulighed.
Sådan installeres JAX i dit Python-miljø
Hvis du har python-opsætning på dit system og ønsker at køre JAX på din lokale maskine (CPU), skal du bruge følgende kommandoer:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Hvis du vil køre Google JAX på en GPU eller TPU, skal du følge instruktionerne på GitHub JAX side. For at konfigurere Python skal du besøge Python officielle downloads side.
Konklusion
Google JAX er fantastisk til at skrive effektive deep learning-algoritmer, robotteknologi og forskning. På trods af begrænsningerne bruges det flittigt med andre rammer som Haiku, Hør og mange flere. Du vil være i stand til at sætte pris på, hvad JAX gør, når du kører programmer, og se tidsforskellene i at udføre kode med og uden JAX. Du kan starte med at læse officiel Google JAX-dokumentationhvilket er ret omfattende.