
Amazon Glue vinder popularitet, fordi mange virksomheder er begyndt at bruge administrerede dataintegrationstjenester.
ETL er en proces, der overfører data fra en kildedatabase til et datavarehus. ETL er kompleks og vanskelig at implementere for alle virksomhedsdata på grund af dens kompleksitet. Amazon introducerede AWS Glue for at løse dette problem.
ETL-udviklere og dataingeniører bruger Glue til at bygge, overvåge og køre ETL-arbejdsgange.
Indholdsfortegnelse
Hvad er AWS-lim?
AWS Glue, en serverløs dataintegrationstjeneste, gør det nemt at finde, forberede, flytte og integrere data fra flere kilder. Dette er nyttigt til maskinlæring (ML) og analyse.
Det reducerer dramatisk den tid, det tager at forberede dataene til analyse. Den finder og lister automatisk dataene, genererer Scala- eller Python-kode for at overføre dataene fra kilden og indlæser og transformerer jobbet i henhold til de tidsbestemte hændelser.
Dette giver mulighed for fleksibel planlægning og skaber et Apache Spark-miljø, der kan skaleres til målrettet dataindlæsning. Derudover giver AWS Glue kompleks datastrømovervågning og -ændring. AWS Glue er en serverløs tjeneste, der forenkler applikationsudviklingens komplicerede operationer.
Det giver mulighed for hurtig integration af flere gyldige data. Det nedbryder og godkender også data hurtigt.
Hvad bruges AWS lim til?
Det er vigtigt at kende de bedste steder at bruge Amazon Glue. Dette er blot nogle få eksempler på AWS Glue-anvendelser, du bør overveje.
- Glue er et værktøj, der giver dig mulighed for at køre serverløse forespørgsler på Amazon S3-datasøerne. Amazon Glue er et fantastisk værktøj til at komme i gang. Det gør alle dine data tilgængelige på én grænseflade, så du kan analysere dem uden at skulle flytte dem.
- Amazon Glue kan bruges til at forstå dine dataaktiver. Amazon Glue gør det nemt for dig at søge i forskellige AWS-datasæt ved hjælp af datakataloget. Du kan også gemme data på tværs af flere AWS-tjenester ved hjælp af datakataloget, mens du stadig har en ensartet visning.
- Lim kan være nyttigt, når du bygger begivenhedsdrevne ETL-arbejdsgange. Du kan udføre dine ETL-operationer fra Amazon S3 ved at kalde dine Glue ETL-opgaver via en AWS Lambda-tjeneste.
- AWS Glue kan også bruges til at rense, verificere, formatere og organisere data til opbevaring i en datasø eller et lager.
Hvad er komponenterne i AWS-lim?
Nedenfor er hovedkomponenterne i AWS Glue:
- Datakatalog: Dette datakatalog indeholder metadata og datastrukturen.
- Database: Dette er nøglen til at få adgang til og oprette databasen for kilder og mål.
- Tabel: Opret en eller flere tabeller i databasen, der kan bruges af både målet og kilden.
- Crawler og klassificering: Crawleren henter data fra kilden ved at bruge enten indbyggede eller brugerdefinerede klassifikationer. Den opretter/bruger foruddefinerede metadatatabeller i datakataloget.
- Job: Dette er forretningslogikkens opgave at udføre en ETL-opgave. Denne forretningslogik er skrevet internt af Apache Spark ved hjælp af python- og scala-sprog.
- Trigger: En ETL-trigger er en enhed, der initierer udførelsen af et ETL-job on-demand eller på et bestemt tidspunkt.
- Slutpunkt for udvikling: Dette skaber et miljø, hvor ETL-jobscriptet testes, udvikles og fejlfindes.
Fordele ved AWS Lim
Disse er fordelene ved at bruge det på din arbejdsplads eller i en organisation.
- AWS Glue scanner alle tilgængelige data med en crawler.
- Endelig behandlede data kan gemmes mange steder (Amazon RDS og Amazon Redshift, Amazon S3 osv.
- Det er en cloud-baseret tjeneste. Der er ingen grund til at bruge penge på infrastrukturer på stedet.
- Fordi det er en serverløs ETL, er det et omkostningseffektivt valg.
- Det er hurtigt. Det giver dig straks Python/Scala ETL-koden.
Topfunktioner ved AWS Lim?
Amazon Glue har alle de funktioner, du skal bruge for at integrere data, så du kan få bedre indsigt og bruge din viden til at gøre nye fremskridt på få minutter i stedet for måneder. Her er nogle af de funktioner, du bør kende.
- Træk og slip-grænseflade: En træk-og-slip jobeditor giver dig mulighed for at oprette en ETL-proces. AWS Glue vil straks bygge den nødvendige kode til at udtrække, konvertere og uploade dataene.
- Automatisk skemaopdagelse: For at oprette crawlere, der forbinder til forskellige datakilder, kan du bruge Glue-tjenesten. Den organiserer data og udtrækker relevant information. Disse data kan derefter bruges til at overvåge ETL-processer ved hjælp af ETL-opgaver.
- Jobplanlægning: Lim kan enten bruges on-demand eller i henhold til en planlagt tidsplan. Planlæggeren kan bruges til at bygge komplekse ETL-pipelines, der etablerer afhængigheder mellem opgaver.
- Kodegenerering: Glue Elastic Views giver dig mulighed for nemt at skabe materialiserede visninger, der kombinerer og replikerer data fra forskellige datakilder uden at skulle skrive nogen proprietær kode.
- Indbygget Machine Learning: Lim kommer med en indbygget Machine Learning-funktion kaldet “FindMatches”. Det deduplikerer poster, der ikke er perfekte kopier af hinanden.
- Udviklerendepunkter: Hvis du aktivt vil udvikle din ETL-kode, leverer Glue udviklerendepunkter, der giver dig mulighed for at ændre, fejlsøge og teste den kode, den opretter.
- Glue DataBrew: Det er et dataforberedelsesværktøj, der kan bruges af dataanalytikere og dataforskere til at hjælpe dem med at rense og normalisere data. Den bruger Glue DataBrews aktive og visuelle grænseflade.
Hvordan fungerer AWS limpriser?
AWS Glue opkræver et timegebyr, som faktureres per sekund for crawlere (opdagelse af dataene) og ETL-job (behandling og indlæsning af data). Der opkræves et simpelt månedligt gebyr for at få adgang til og gemme metadata i AWS Glue Data Catalog.
Amazon Glue starter ved $0,44. Du kan vælge mellem fire planer:
- ETL-opgaver, udviklingsendepunkter og andre ETL-opgaver er tilgængelige for $0,44
- Crawlers interaktive sessioner er tilgængelige for $0,44
- DataBrew-job starter ved $0,48
- Månedlig opbevaring og anmodninger til datakataloget koster $1,00
AWS tilbyder ikke en gratis Glue-plan. Hver time vil koste $0,44 pr. DPU. I gennemsnit ville det koste dig 21 USD pr. dag. Priserne kan variere alt efter hvor du bor.
Trin til opsætning af AWS Glue
Datakataloget kan bruges til hurtigt at finde og søge i flere AWS-datasæt uden at skulle flytte dataene. Efter at dataene er blevet katalogiseret, er de straks tilgængelige for forespørgsel og søgning ved hjælp af Amazon Athena og Amazon EMR.
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS og databaser på Amazon EC2 – Opdag dine data, gem metadata, og brug AWS Glue Data Catalog til at finde dem
- AWS Glue Data Catalog – Administrer data med datakataloget, der fungerer som et centralt lager for metadata
- AWS Glue ETL – Læs og skriv metadata til dit datakatalog
- Amazon Athena og Amazon Redshift, Amazon EMR, Amazon ETL – Hent datakataloget til ETL, analyser og mere.
Hvordan konfigurerer man AWS-lim?
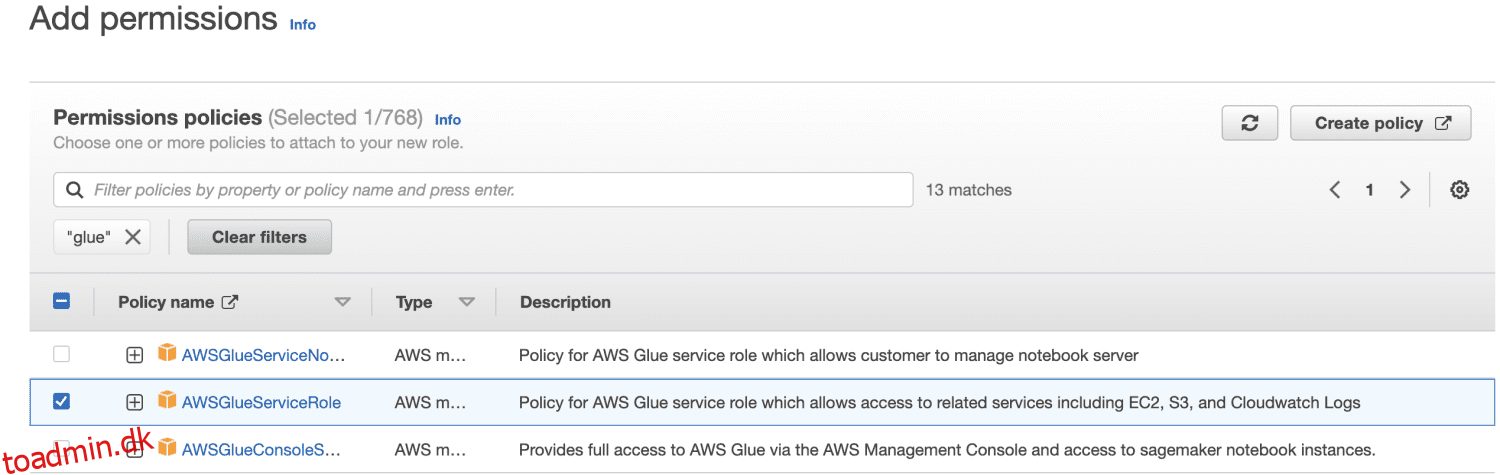
Først skal du logge ind på AWS Management Console og åbne IAM-konsollen. Klik på Opret rolle. Find derefter Glue for rolletype og vælg Tilladelser.
Jeg vælger AWSGlueServiceRole til generelle AWS Glue Studio- og AWS Glue-tilladelser og den AWS-administrerede politik AmazonS3FullAccess for adgang til Amazon S3-ressourcer.
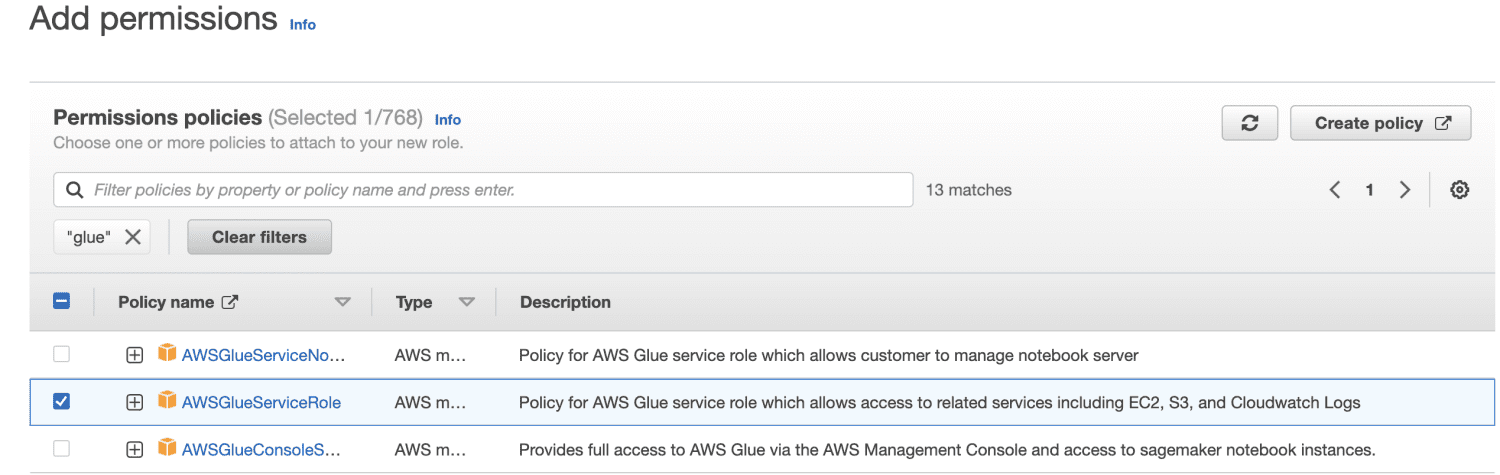
Indtast et rollenavn.
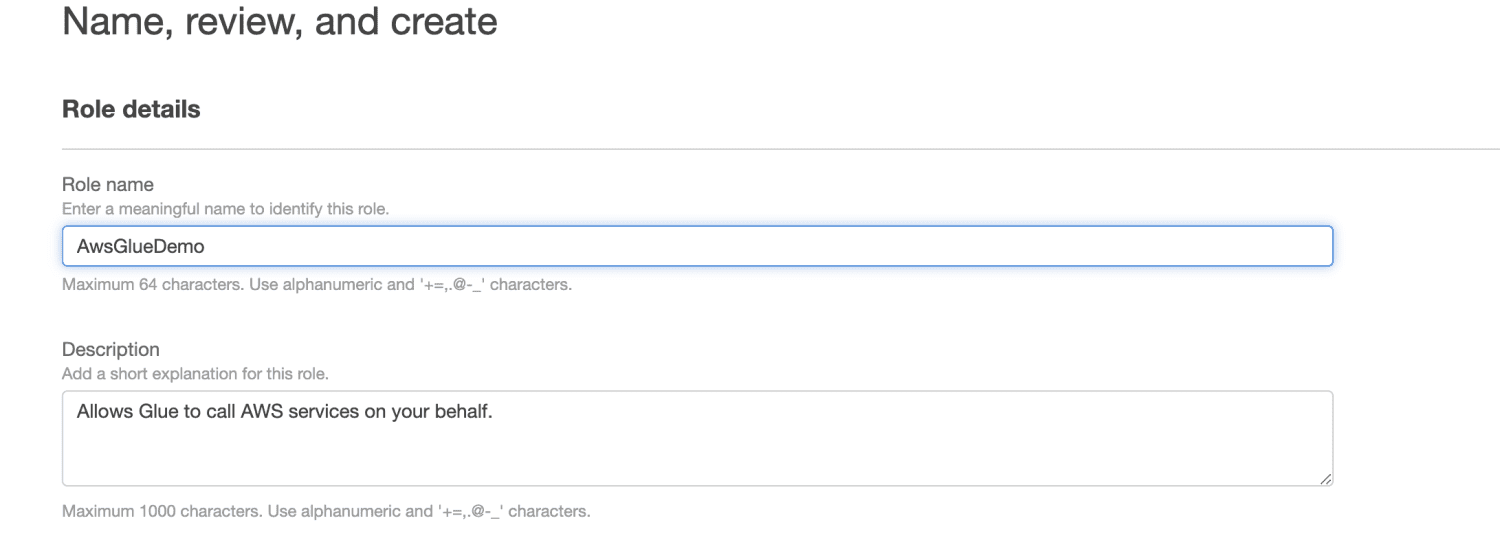
Klik på Opret rolle.
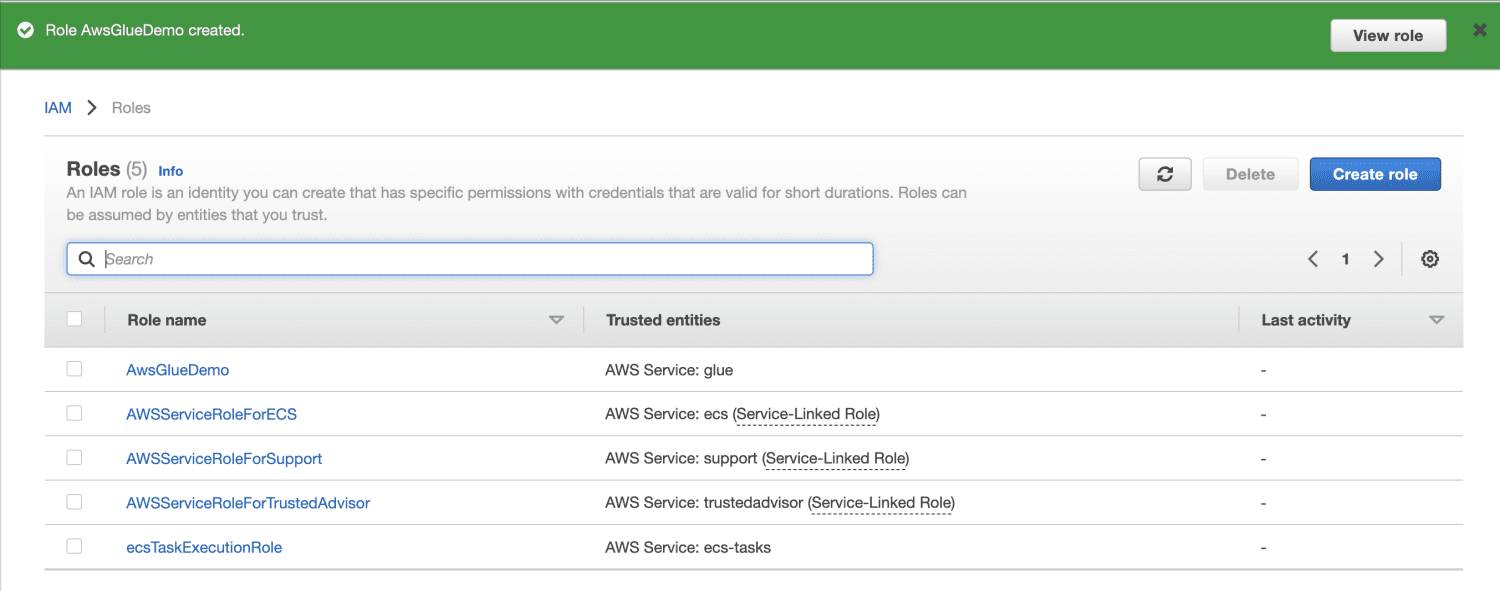
Opret en Amazon S3-spand.
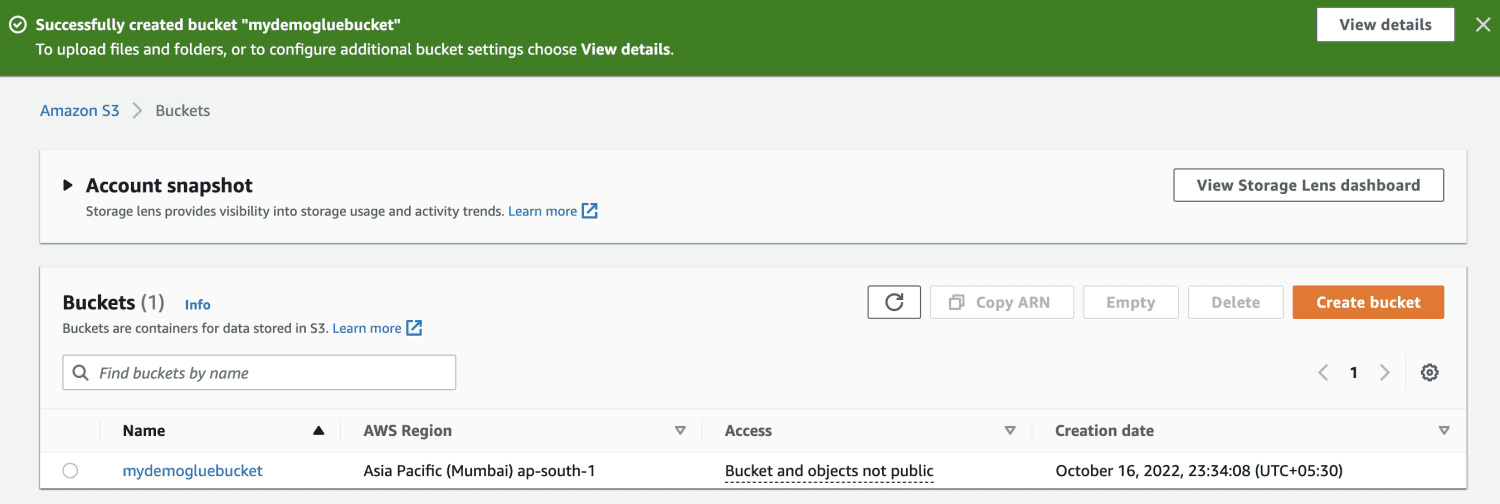
Opret en mappe inde i S3-bøtten.
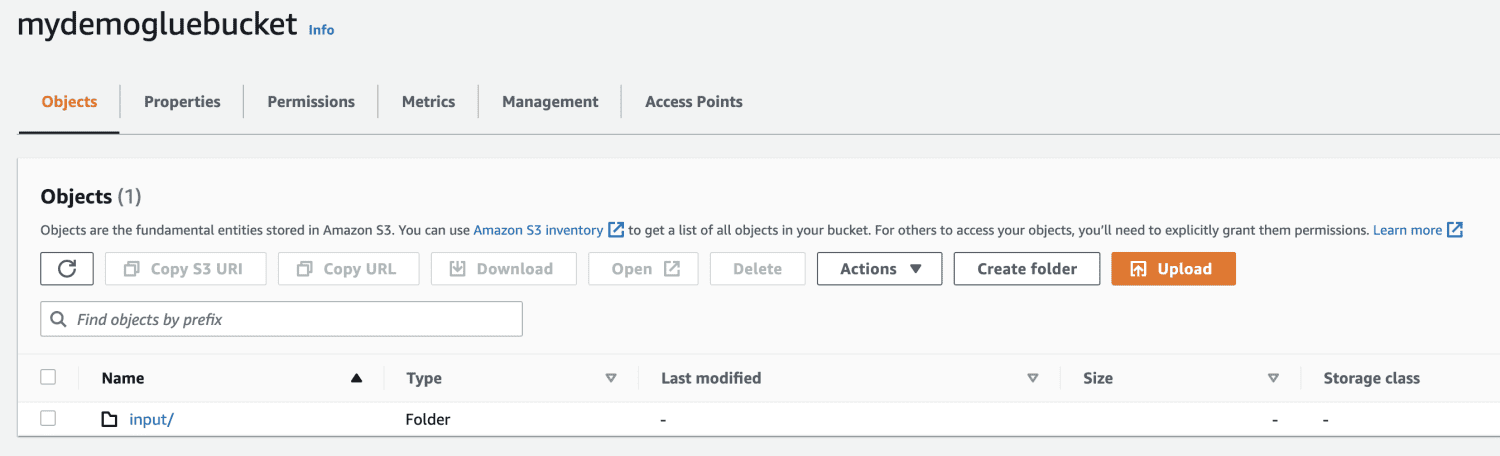
Vælg den fil, der skal uploades.
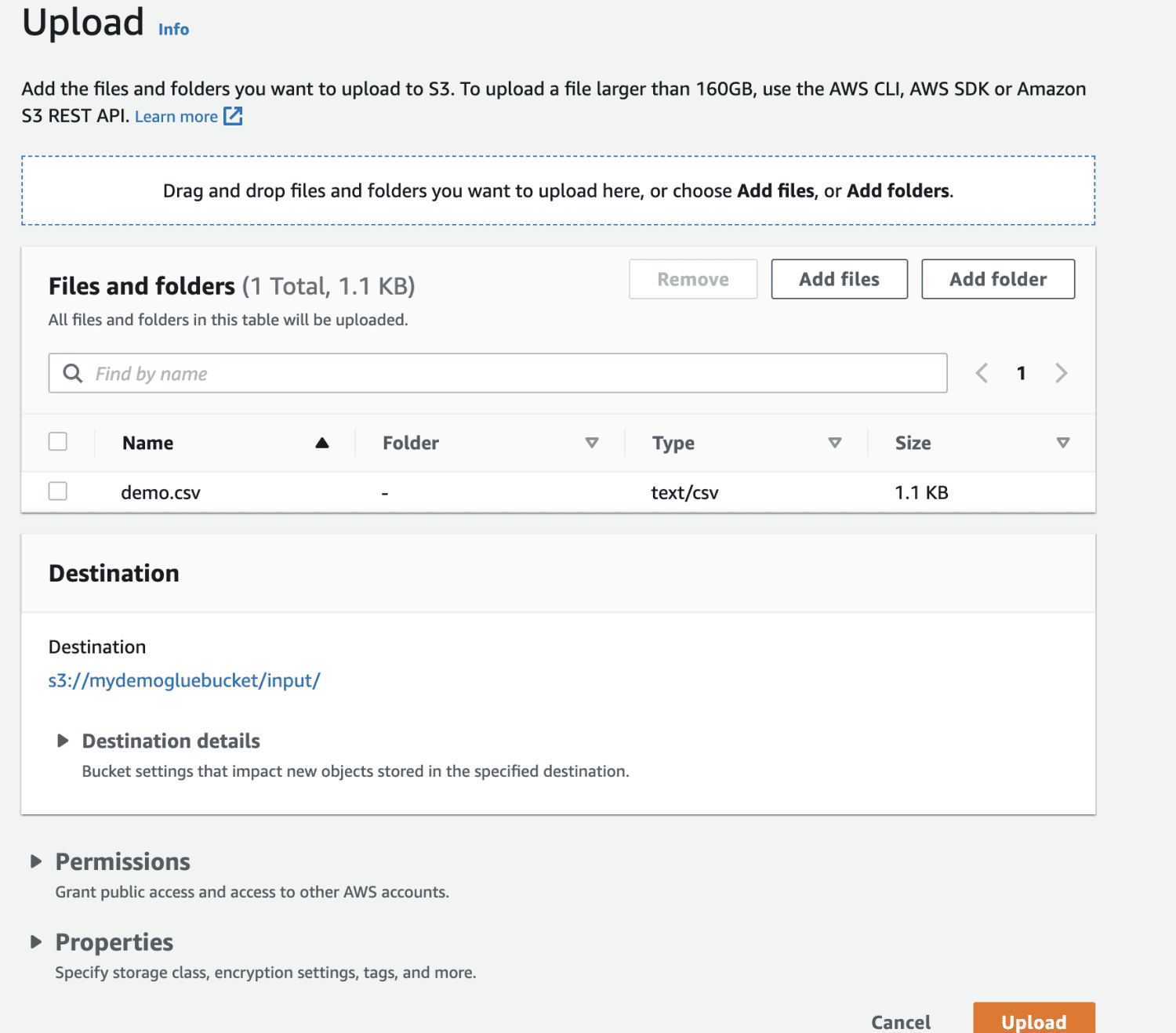
Til sidst uploader du filen i bøtten.
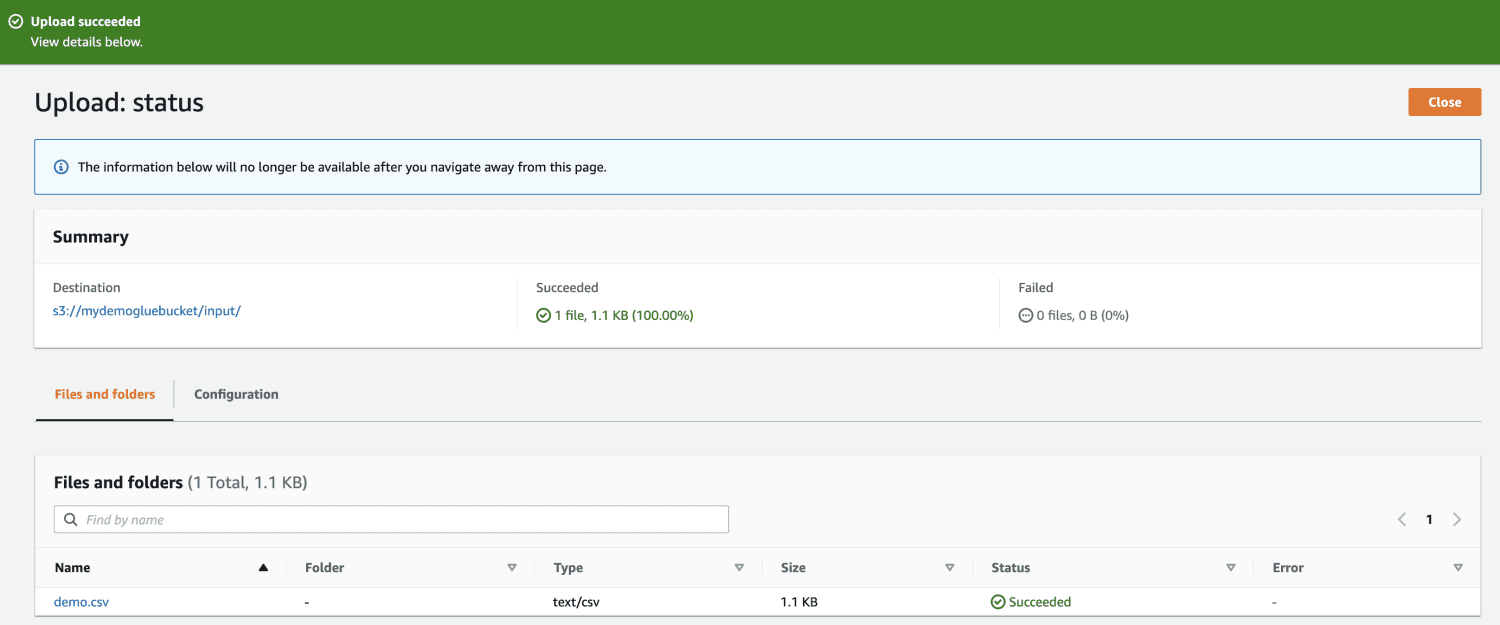
Åbn derefter AWS Glue fra AWS-administrationskonsollen og opret en database.
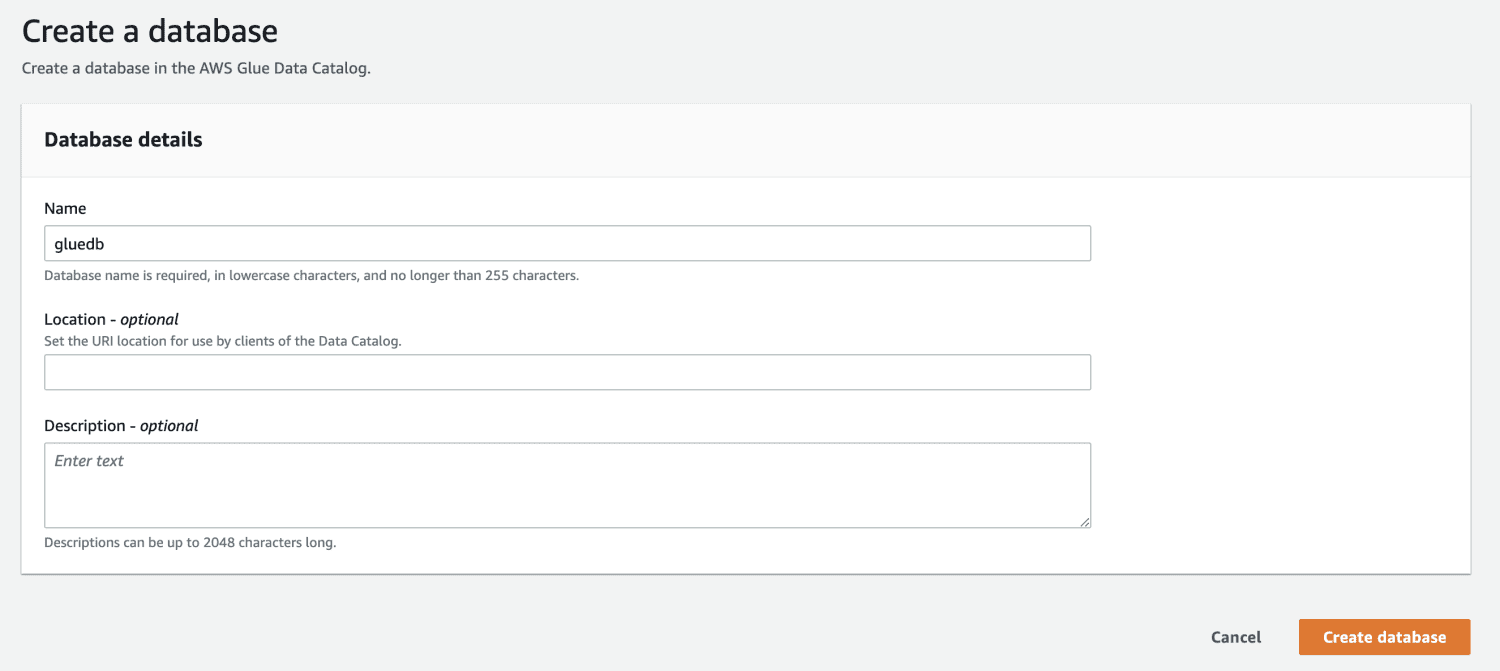
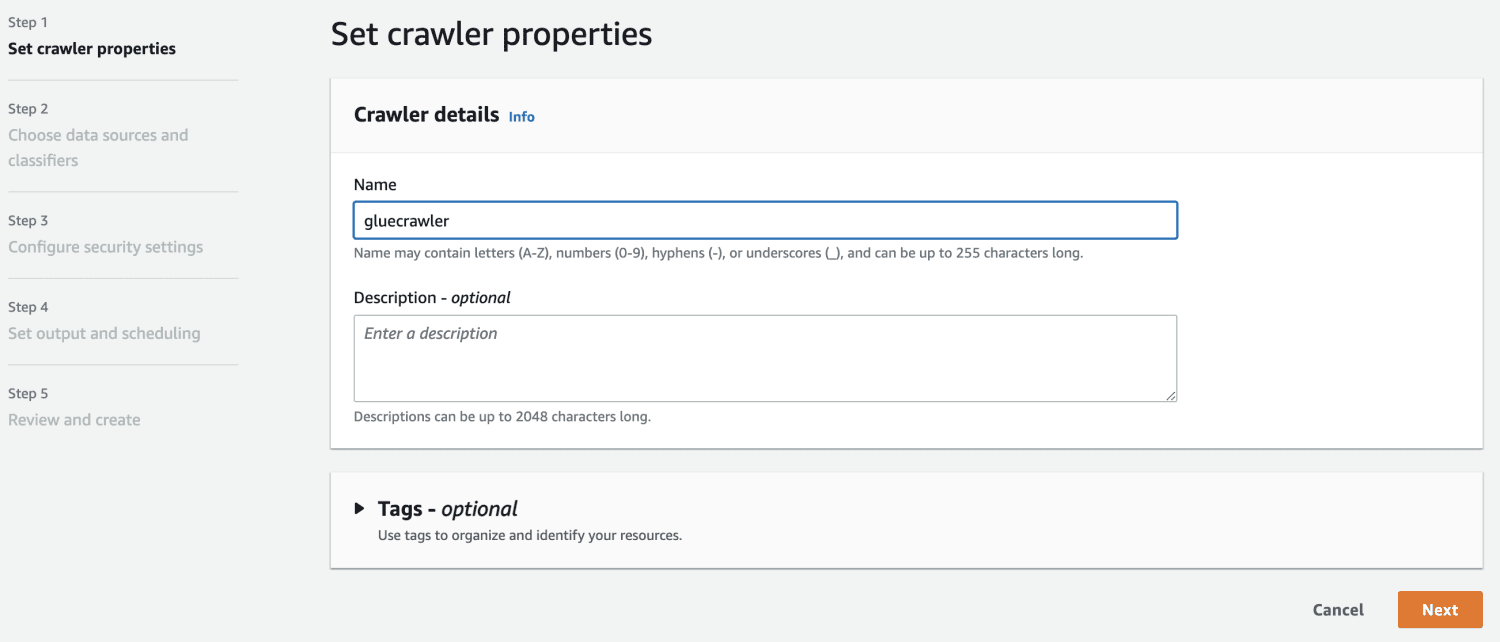
Nu hvor du har en database i AWS Glue, skal du oprette en crawler.
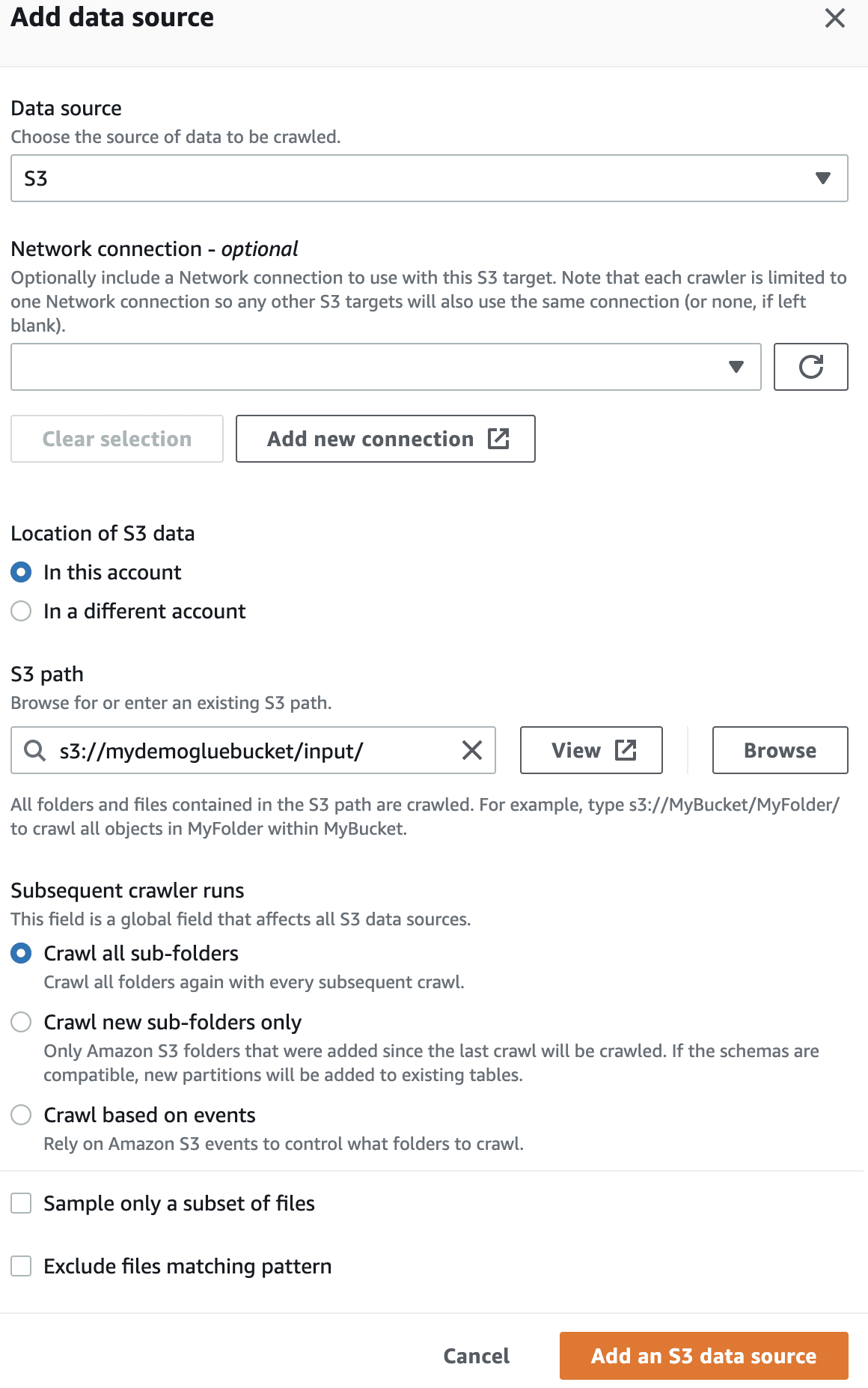
I datakilden skal du vælge den S3-bøtte, som du har oprettet.
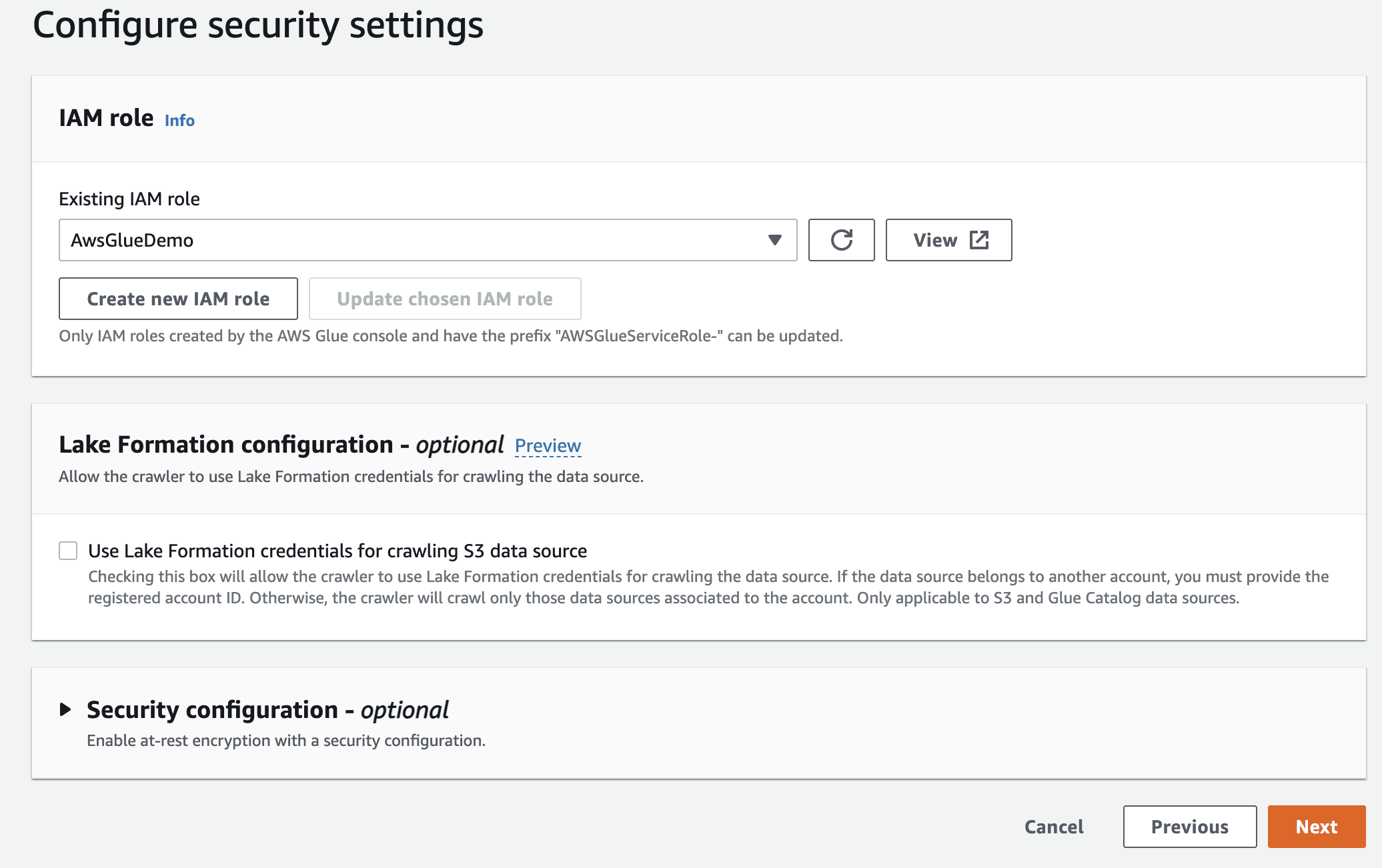
Vælg derefter IaM-rollen for AWS Glue, som du oprettede i begyndelsen.
Til sidst, i outputtet, vælg gluedb, du har oprettet.
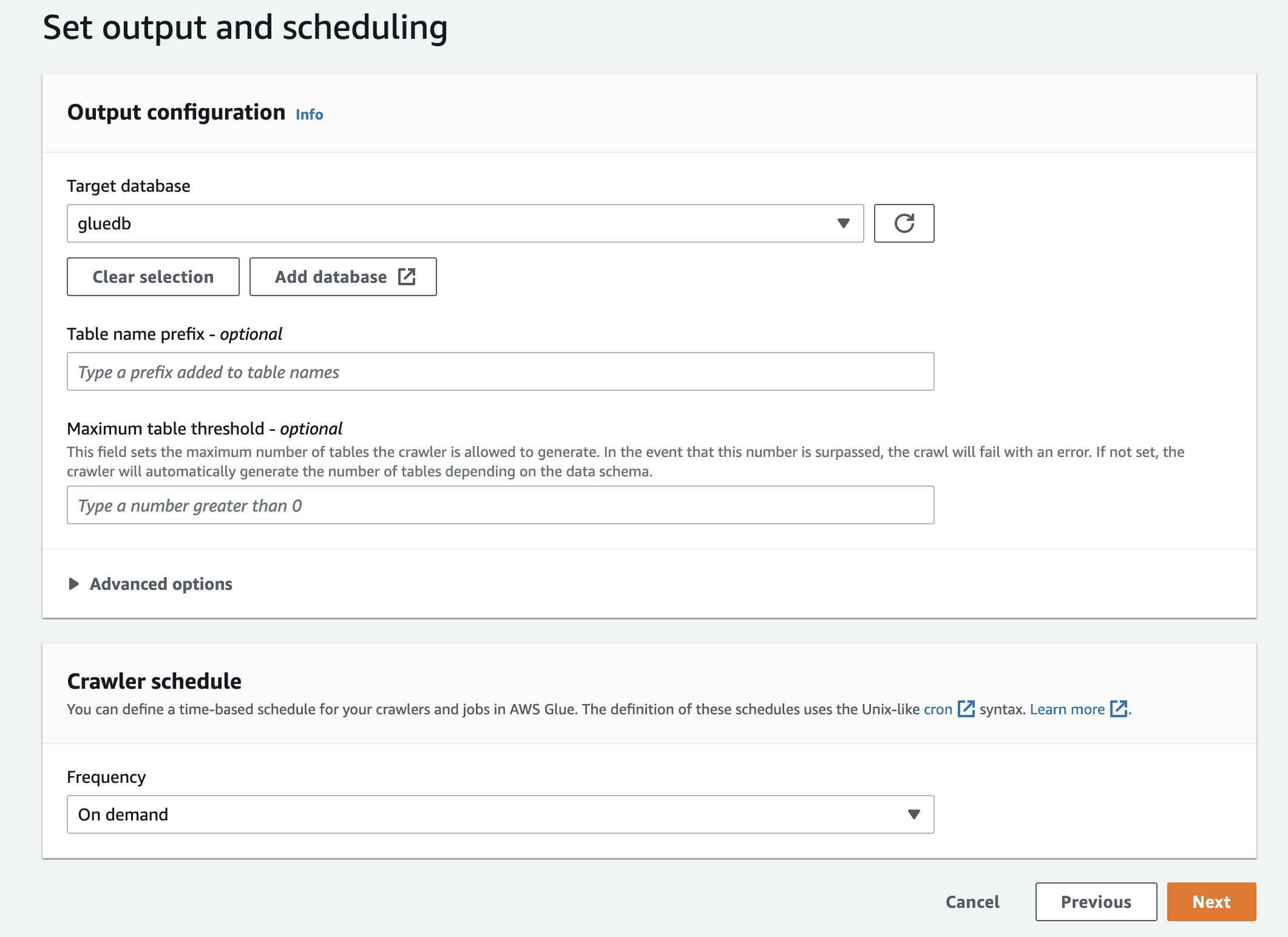
Gennemgå alle indstillingerne, og opret webcrawleren.
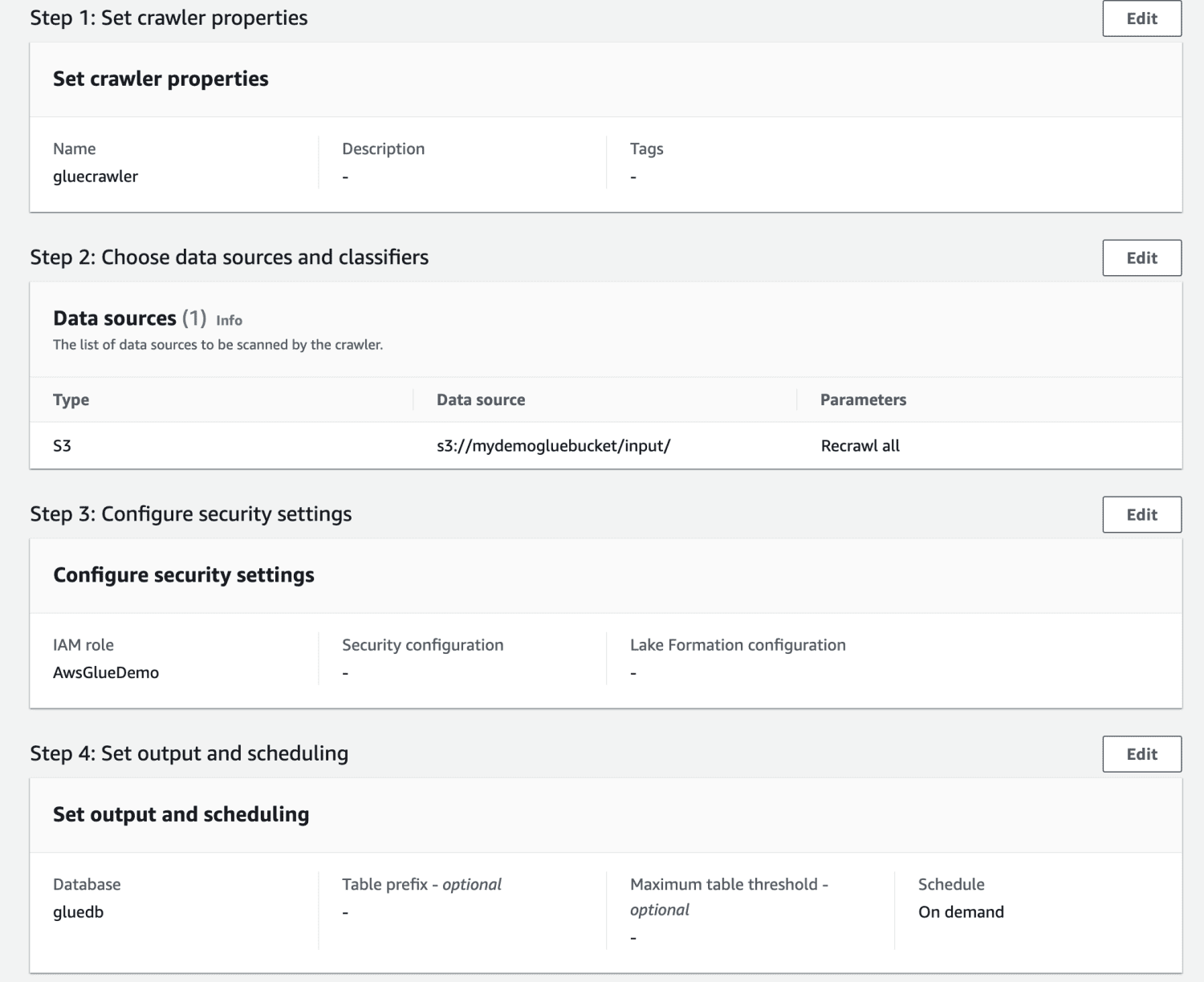
Når webcrawleren er oprettet, skal du vælge den og klikke på Kør. Efter noget tid vil du få status klar.
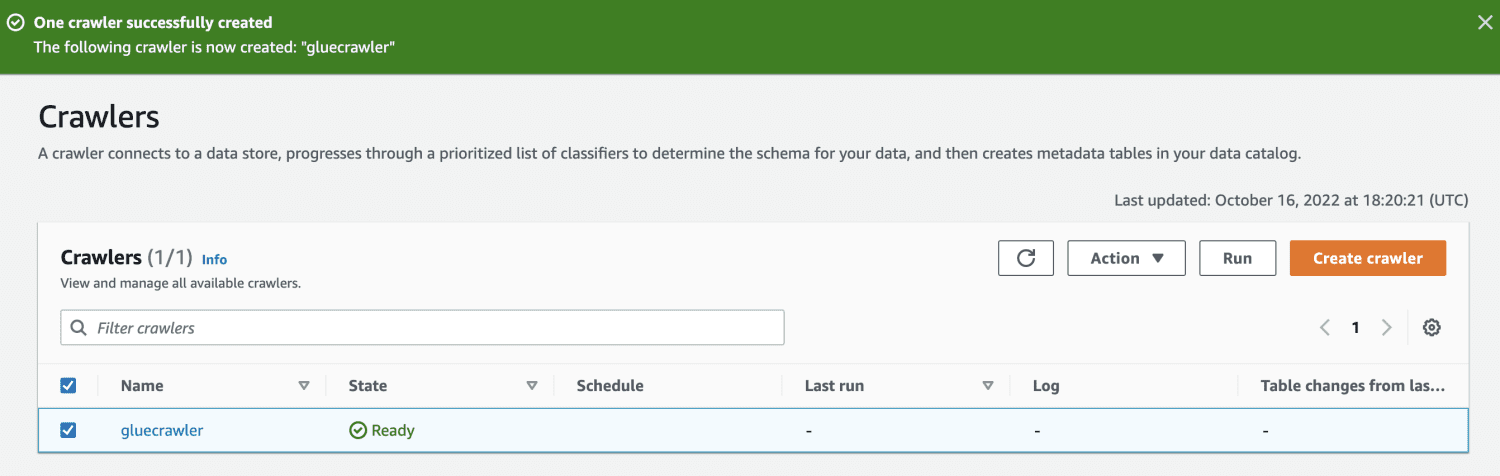
Ved at køre crawleren får databasen en tabel med alle data fra CSV-filen.
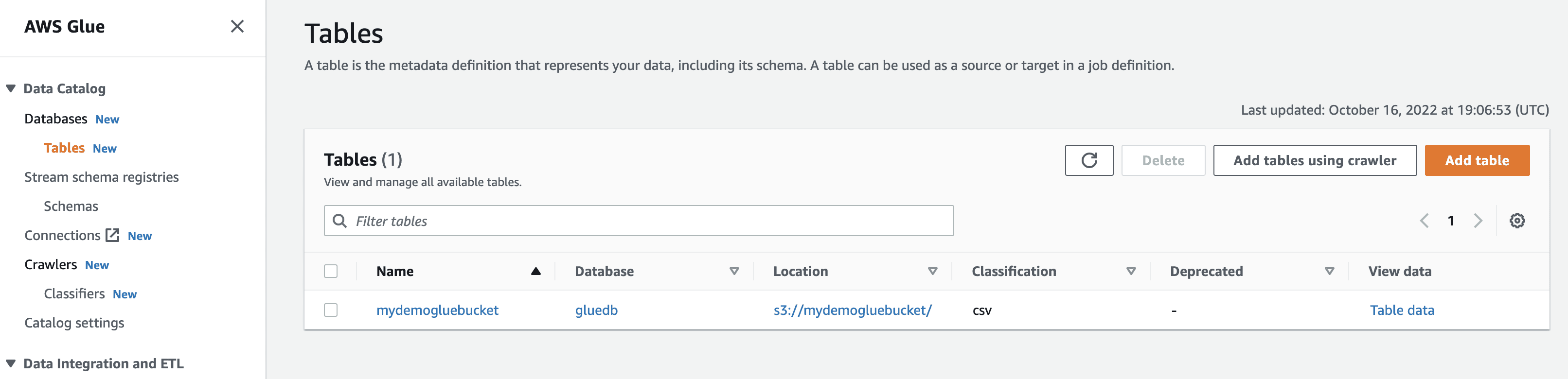
Når du klikker på se data, vil du blive ført til Amazon Athena (forespørgselseditor). Når du kører forespørgslen, kan du se tabeldataene.
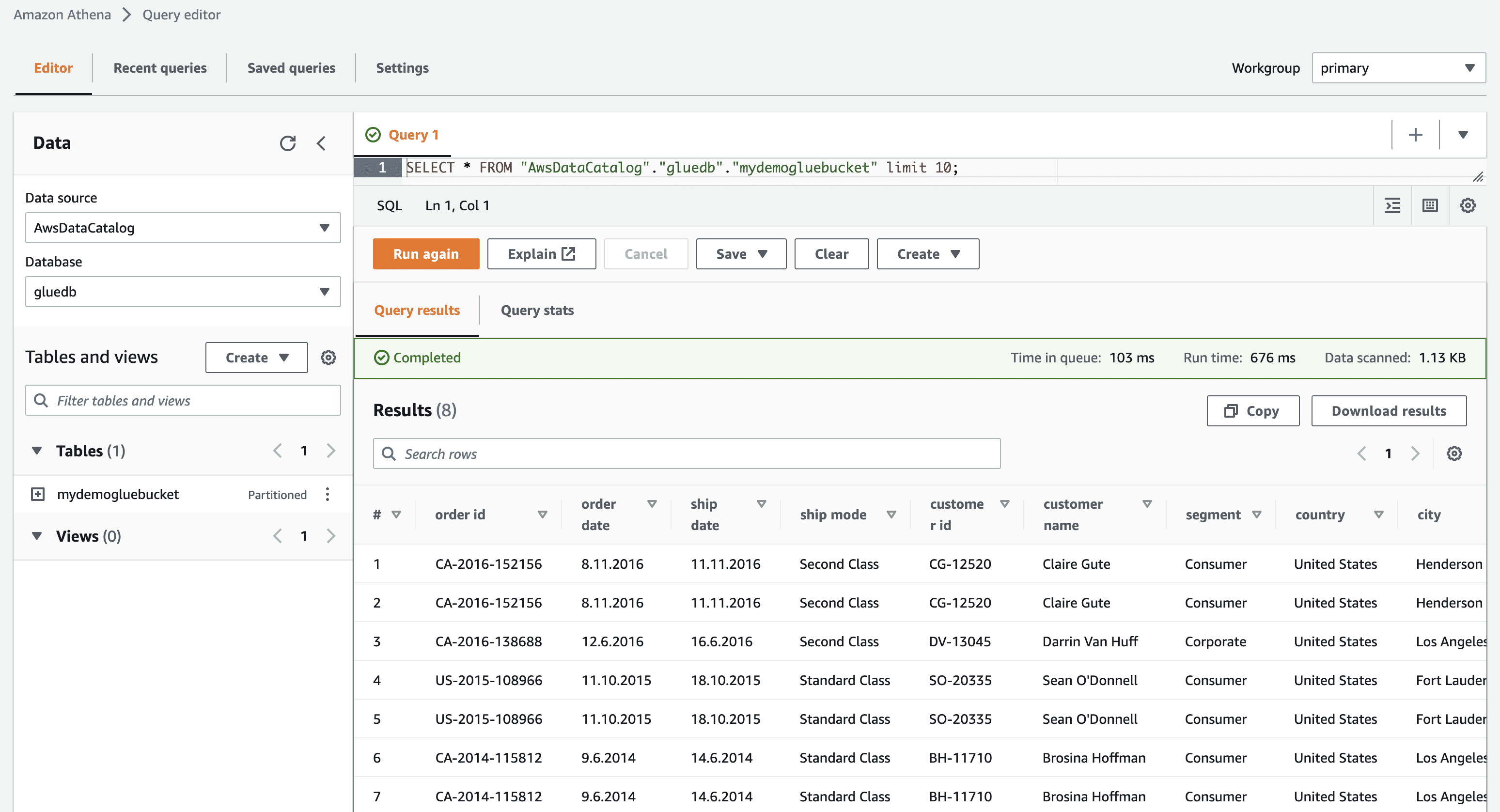
Nu kan du med succes bruge denne AWS Glue-crawler i ethvert ETL-job.
Hvad er AWS Glue Databrew?
AWS Glue DataBrew giver brugerne mulighed for at normalisere og rydde op i data uden at skrive nogen kode. DataBrew kan reducere den tid, der kræves til at forberede data til maskinlæring og analyse med så meget som 80 procent sammenlignet med specialudviklet dataforberedelse.
Der er over 250 forudlavede datatransformationer, der kan bruges til at automatisere dataforberedelsesopgaver såsom at bortfiltrere anomalier, korrigere ugyldige værdier og konvertere data til standardformater.
DataBrew gør det nemmere for dataforskere, forretningsanalytikere og ingeniører at samarbejde om at udtrække indsigt fra rådata. DataBrew er serverløs, så du behøver ikke at administrere infrastruktur eller oprette klynger for at udforske og transformere rådata til en værdi af terabytes.
DataBrew-funktioner til virksomheder
Visualiseret dataforberedelse
DataBrew er en anderledes måde at se data på, der typisk ses i kolonnebaserede databaser som alfanumeriske tal. DataBrew visualiserer alle indlæste datakilder for at hjælpe dig med at forstå datarelationerne og hierarkiet.
250+ dataforberedelsesautomatiseringer
Dataforskere forventes at følge en række gentagelige, isolerede arbejdsgange som en del af deres job. Disse arbejdsgange og processer er blevet modelleret af AWS som sprog- og dataagnostiske modulmoduler. Dette bibliotek indeholder handlinger, der kan bruges af slutbrugere.
Dataafstamning
I lighed med revisionslogfiler, der bruges til at spore kundeaktivitet i et it-netværks it-netværk, giver datalinje dig mulighed for at spore datatransformationsaktiviteterne i AWS DataBrew. Disse oplysninger omfatter datakilden, de anvendte transformationer og dataoutputtet, inklusive målplaceringen.
Datakortlægning
Databrew giver dig mulighed for at finde matchende felter i to datakilder. Når matchende felter er blevet identificeret, kan de indlæses i et skema.
AWS Glue DataBrew: Fordele
Nedenfor er funktionerne i AWS Glue DataBrew:
- Lavere adgangsbarriere til dataforberedelse
- Automatiseret dataprofilgenerering
- Automatiser 250+ dataforberedelsesprocesser
- Intelligente præskriptive forslag
Alternativer til AWS Lim
Luftstrøm
Airflow hører til Workflow Manager-sektionen af en teknologisk stak. Det er et open source-værktøj, der understøtter GitHub-stjerner, GitHub-gafler og andre funktioner. Airflow giver dig mulighed for at oprette arbejdsgange ved hjælp af dirigerede acykliske diagrammer (DAG’er). Airflow scheduler udfører dine opgaver ved hjælp af en række arbejdere og følger de specificerede afhængigheder.
Matillion

Matillion ETL, et ETL/ELT-værktøj, blev designet eksplicit til cloud-databaseplatforme som Amazon Redshift og Google BigQuery. Det er en moderne browserbaseret brugerflade med kraftfulde push-down ETL/ELT-funktioner. Du kan være i gang på få minutter med en hurtig opsætning.
Søm
Stitch er en open source ETL-tjeneste, der forbinder flere datakilder og replikerer data til foretrukne destinationer. Det er meget nemt at bruge, da du ikke behøver nogen kodningsviden for at flytte data mellem kilder og destinationer i Stitch. Den er nem at bruge, har en venlig GUI, og den er hurtig.
Stitch giver dig ikke mulighed for at vælge et færdiglavet dashboard i modsætning til andre ETL-værktøjer. I stedet skal du integrere dine data i de åbne datavarehuse, som du vælger som destination. Det kan være svært at navigere i opgørelserne.
Alteryx

Alteryx er en analytisk automatiseringsplatform, der hjælper med forberedelse og blanding af dataindsamling. Disse data kan bruges til at fremskynde processer og give forretningsindsigt. Fordi det er et træk-og-slip-værktøj, behøver du ingen programmeringsviden. Alteryx er et godt sted at gå hen for at få råd og svar fra branchefolk.
Konklusion
Så det handlede om AWS Glue, som er en cloud-baseret løsning, der giver dig mulighed for at arbejde med ETL-pipelines. For at opsummere består AWS Glue-brugerinteraktionsprocessen af tre faser. For at oprette et datakatalog skal du først bruge datacrawlere. Dernæst opretter du den ETL-kode, der kræves af AWS-datapipelinen. Til sidst oprettes ETL-skemaet. Jeg håber denne blog gav dig et godt overblik over Amazon Glue.
Du kan også udforske de bedste tips til at sikre AWS S3-lagring.