
ETL står for Extract, Transform og Load. ETL-værktøjer udtrækker data fra forskellige kilder og transformerer dem til et mellemformat, der passer til målsystemer eller datamodelkravene. Og endelig indlæser de data i en måldatabase, datavarehus eller endda datasø.
Jeg husker tider fra 15 til 20 år tilbage, hvor udtrykket ETL var noget, som kun få forstod, hvad det er. Da forskellige brugerdefinerede batchjob havde deres højdepunkt på den lokale hardware.
Mange projekter lavede en form for ETL. Selvom de ikke vidste det, skulle de kalde det ETL. I løbet af den tid, når jeg forklarede et design, der involverede ETL-processer, og jeg ringede til dem og beskrev dem på den måde, lignede det næsten en anden verdensteknologi, noget meget sjældent.
Men i dag er tingene anderledes. Migration til skyen er topprioritet. Og ETL-værktøjer er den meget strategiske del af arkitekturen i de fleste projekter.
I sidste ende betyder at migrere til skyen at tage data fra den lokale kilde og transformere dem til cloud-databaser i en form, der er så kompatibel som muligt med cloud-arkitekturen. Præcis opgaven med ETL-værktøjet.
Indholdsfortegnelse
Historien om ETL og hvordan det forbinder til nutiden
Kilde: aws.amazon.com
ETL’s hovedfunktioner var altid de samme.
ETL-værktøjer udtrækker data fra forskellige kilder (det være sig databaser, flade filer, webtjenester eller på det seneste cloud-baserede applikationer).
Det betød normalt at tage filer på Unix-filsystemet som input og forbehandling, behandling og efterbehandling.
Du kunne se det genanvendelige mønster af mappenavne som:
- Input
- Produktion
- Fejl
- Arkiv
Under disse mapper eksisterede også en anden undermappestruktur, hovedsagelig baseret på datoer.
Dette var bare standardmetoden til at behandle indgående data og forberede dem til indlæsning i en slags database.
I dag er der ingen Unix-filsystemer (ikke på samme måde som før) – måske endda ingen filer. Nu er der API’er – applikationsprogrammeringsgrænseflader. Det kan du, men du behøver ikke at have en fil som inputformat.
Det hele kan gemmes i cachehukommelsen. Det kan stadig være en fil. Uanset hvad det er, skal det følge et eller andet struktureret format. I de fleste tilfælde betyder dette JSON- eller XML-format. I nogle tilfælde vil det gamle gode Comma-separated-value-format (CSV) også gøre det.
Du definerer inputformatet. Om processen også vil involvere at oprette historikken for inputfiler er udelukkende op til dig. Det er ikke længere et standardtrin.
Transformation
ETL-værktøjer omdanner de udtrukne data til et passende format til analyse. Dette omfatter datarensning, datavalidering, databerigelse og dataaggregering.
Som det plejede at være tilfældet, gennemgik dataene en kompleks brugerdefineret logik af Pro-C- eller PL/SQL-proceduremæssige datainddelinger, datatransformation og datamålskemalagringstrin. Det var en tilsvarende obligatorisk standardproces, som det var at adskille de indgående filer i undermapper baseret på det stadium, filen blev behandlet.
Hvorfor var det så naturligt, hvis det også var grundlæggende forkert på samme tid? Ved direkte at transformere de indgående data uden permanent lagring mistede du den største fordel ved rådata – uforanderlighed. Projekter smed bare det væk uden nogen chance for genopbygning.
Nå, gæt hvad. I dag, jo mindre transformation af rådata du udfører, jo bedre. For den første datalagring i systemet, dvs. Det kan være det næste skridt vil være nogle alvorlige dataændringer og datamodeltransformation, helt sikkert. Men du ønsker at have lagret de rå data i så meget uændret og atomær struktur som muligt. Et stort skift fra de lokale tider, hvis du spørger mig.
belastning
ETL-værktøjer indlæser de transformerede data til en måldatabase eller et datavarehus. Dette omfatter oprettelse af tabeller, definition af relationer og indlæsning af data i de relevante felter.
Indlæsningstrinnet er sandsynligvis det eneste, der følger det samme mønster i evigheder. Den eneste forskel er en måldatabase. Hvor det tidligere var Oracle det meste af tiden, kan det nu være hvad der er tilgængeligt i AWS-skyen.
ETL i dagens cloudmiljø
Hvis du planlægger at bringe dine data fra on-premise til (AWS) cloud, har du brug for et ETL-værktøj. Den går ikke uden, og derfor blev denne del af skyarkitekturen nok den vigtigste brik i puslespillet. Hvis dette trin er forkert, vil alt andet efterfølgende følge og dele den samme lugt overalt.
Og selvom der er mange konkurrencer, vil jeg nu fokusere på de tre, jeg har mest personlig erfaring med:
- Data Migration Service (DMS) – en indbygget service fra AWS.
- Informatica ETL – formentlig den vigtigste kommercielle aktør i ETL-verdenen, som med succes transformerer sin forretning fra on-premise til cloud.
- Matillion for AWS – en relativt ny spiller i skymiljøer. Ikke native til AWS, men native til skyen. Med intet som historie sammenlignelig med Informatica.
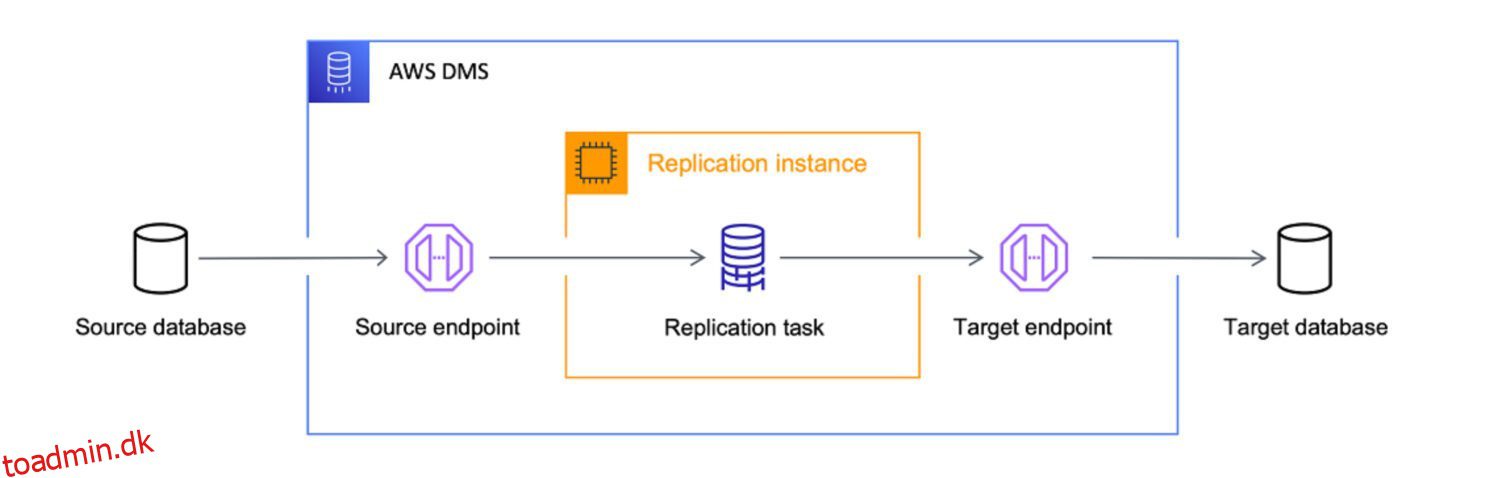
AWS DMS som ETL
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
AWS Data Migration Services (DMS) er en fuldt administreret tjeneste, der giver dig mulighed for at migrere data fra forskellige kilder til AWS. Det understøtter flere migrationsscenarier.
- Homogene migrationer (f.eks. Oracle til Amazon RDS for Oracle).
- Heterogene migrationer (f.eks. Oracle til Amazon Aurora).
DMS kan migrere data fra forskellige kilder, herunder databaser, datavarehuse og SaaS-applikationer, til forskellige mål, herunder Amazon S3, Amazon Redshift og Amazon RDS.
AWS behandler DMS-tjenesten som det ultimative værktøj til at bringe data fra enhver databasekilde ind i cloud-native mål. Mens hovedmålet med DMS kun er datakopiering til skyen, gør det også et godt stykke arbejde med at transformere dataene undervejs.
Du kan definere DMS-opgaver i JSON-format for at automatisere forskellige transformationsjob for dig, mens du kopierer dataene fra kilden til målet:
- Flet flere kildetabeller eller kolonner til en enkelt værdi.
- Opdel kildeværdien i flere målfelter.
- Erstat kildedata med en anden målværdi.
- Fjern alle unødvendige data eller opret helt nye data baseret på inputkonteksten.
Det betyder – ja, du kan helt sikkert bruge DMS som et ETL-værktøj til dit projekt. Måske vil det ikke være så sofistikeret som de andre muligheder nedenfor, men det vil gøre jobbet, hvis du definerer målet klart på forhånd.
Egnethedsfaktor
Selvom DMS giver nogle ETL-funktioner, handler det primært om datamigreringsscenarier. Der er dog nogle scenarier, hvor det kan være bedre at bruge DMS i stedet for ETL-værktøjer som Informatica eller Matillion:
Matillion ETL
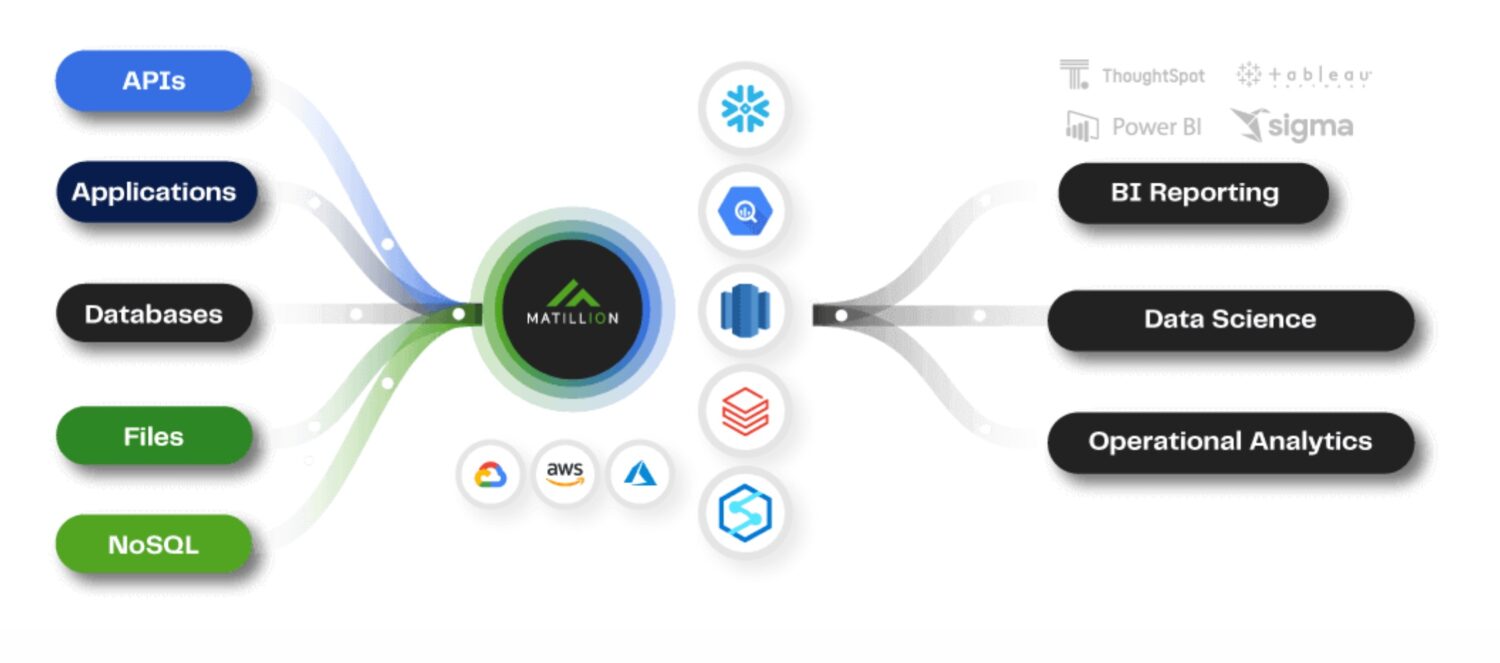 Kilde: matillion.com
Kilde: matillion.com
er en cloud-native løsning, og du kan bruge den til at integrere data fra forskellige kilder, herunder databaser, SaaS-applikationer og filsystemer. Det tilbyder en visuel grænseflade til at bygge ETL-pipelines og understøtter forskellige AWS-tjenester, herunder Amazon S3, Amazon Redshift og Amazon RDS.
Matillion er nem at bruge og kan være et godt valg for organisationer, der er nye til ETL-værktøjer eller med mindre komplekse dataintegrationsbehov.
På den anden side er Matillion en slags tabula rasa. Den har nogle foruddefinerede potentielle funktioner, men du skal tilpasse den for at bringe den ud i livet. Du kan ikke forvente, at Matillion gør jobbet for dig ud af boksen, selvom kapaciteten er der per definition.
Matillion beskrev også ofte sig selv som ELT frem for et ETL-værktøj. Det betyder, at det er mere naturligt for Matillion at udføre en belastning før transformationen.
Egnethedsfaktor
Med andre ord er Matillion kun mere effektiv til at transformere dataene, når de allerede er lagret i databasen end før. Hovedårsagen til det er den brugerdefinerede scripting-forpligtelse, der allerede er nævnt. Da al den specielle funktionalitet skal kodes først, vil effektiviteten i høj grad afhænge af effektiviteten af den brugerdefinerede kode.
Det er kun naturligt at forvente, at dette vil blive bedre håndteret i måldatabasesystemet og kun efterlade en simpel 1:1 indlæsningsopgave på Matillion – meget færre muligheder for at ødelægge den med tilpasset kode her.
Selvom Matillion tilbyder en række funktioner til dataintegration, tilbyder den muligvis ikke det samme niveau af datakvalitet og styringsfunktioner som nogle andre ETL-værktøjer.
Matillion kan skalere op eller ned baseret på organisationens behov, men det er måske ikke så effektivt til at håndtere meget store mængder data. Den parallelle behandling er ret begrænset. I denne henseende er Informatica helt sikkert et bedre valg, fordi det på samme tid er mere avanceret og funktionsrigt.
For mange organisationer kan Matillion for AWS dog give tilstrækkelig skalerbarhed og parallel behandlingskapacitet til at opfylde deres behov.
Informatik ETL
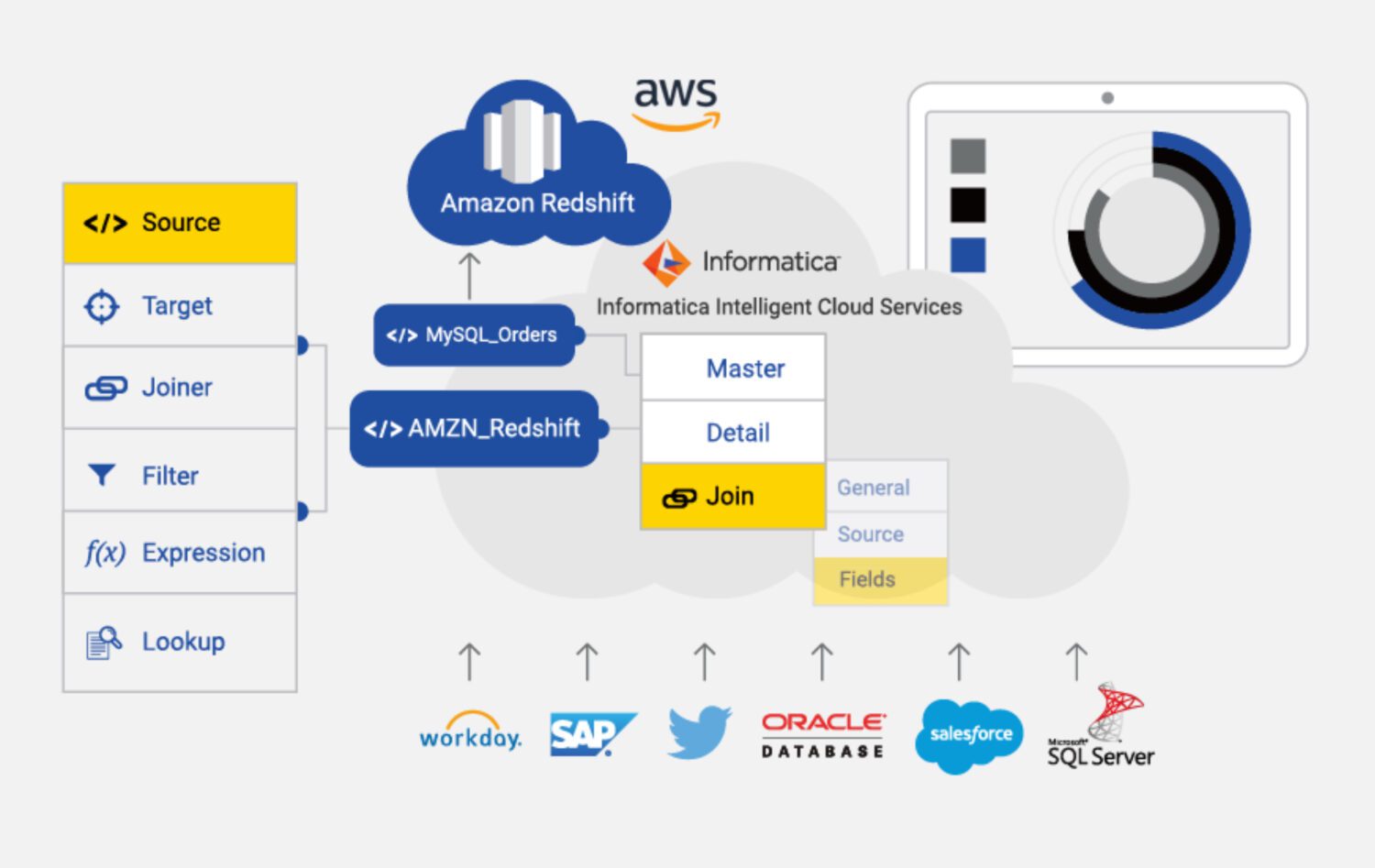 Kilde: informatica.com
Kilde: informatica.com
Informatica til AWS er et cloud-baseret ETL-værktøj designet til at hjælpe med at integrere og administrere data på tværs af forskellige kilder og mål i AWS. Det er en fuldt administreret tjeneste, der giver en række funktioner og muligheder til dataintegration, herunder dataprofilering, datakvalitet og datastyring.
Nogle af de vigtigste egenskaber ved Informatica for AWS inkluderer:
Egnethedsfaktor
Det er klart, at Informatica er det mest funktionsrige ETL-værktøj på listen. Det kan dog være dyrere og mere komplekst at bruge end nogle af de andre ETL-værktøjer, der er tilgængelige i AWS.
Informatica kan være dyrt, især for små og mellemstore organisationer. Prismodellen er baseret på forbrug, hvilket betyder, at organisationer muligvis skal betale mere, efterhånden som deres forbrug stiger.
Det kan også være komplekst at konfigurere og konfigurere, især for dem, der er nye til ETL-værktøjer. Dette kan kræve en betydelig investering i tid og ressourcer.
Det fører os også til noget, vi kan kalde en “kompleks læringskurve”. Dette kan være en ulempe for dem, der har brug for at integrere data hurtigt eller har begrænsede ressourcer at afsætte til træning og onboarding.
Desuden er Informatica muligvis ikke så effektiv til at integrere data fra ikke-AWS-kilder. I denne henseende kunne DMS eller Matillion være en bedre mulighed.
Endelig er Informatica i høj grad et lukket system. Der er kun en begrænset mulighed for at tilpasse det til projektets specifikke behov. Du skal bare leve med den opsætning, den giver ud af boksen. Det begrænser altså fleksibiliteten af løsningerne på en eller anden måde.
Afsluttende ord
Som det sker i mange andre tilfælde, er der ingen løsning, der passer til alle, selv sådan noget som ETL-værktøjet i AWS.
Du kan vælge den mest komplekse, funktionsrige og dyre løsning med Informatica. Men det giver mening at gøre det meste, hvis:
- Projektet er ret stort, og du er sikker på, at hele den fremtidige løsning og datakilder også forbinder Informatica.
- Du har råd til at medbringe et team af dygtige Informatica-udviklere og konfiguratorer.
- Du kan sætte pris på det robuste supportteam bag dig og er god til at betale for det.
Hvis noget ovenfra er slukket, kan du måske give det et skud til Matillion:
- Hvis projektets behov generelt ikke er så komplekse.
- Hvis du har brug for at inkludere nogle meget tilpassede trin i behandlingen, er fleksibilitet et nøglekrav.
- Hvis du ikke har noget imod at bygge de fleste funktioner fra bunden sammen med holdet.
For alt, der er endnu mindre kompliceret, er det oplagte valg DMS for AWS som en indbygget service, som sandsynligvis kan tjene dit formål godt.
Tjek derefter datatransformationsværktøjer for at administrere dine data bedre.