

Er du i tvivl om, hvordan du får pålidelige og konsistente data til dataanalyse? Implementer disse datarensningsstrategier nu!
Din forretningsbeslutning er afhængig af dataanalyseindsigt. Tilsvarende afhænger indsigten afledt af inputdatasæt af kvaliteten af kildedataene. Lav kvalitet, unøjagtig, skrald og inkonsekvent datakilde er de hårde udfordringer for datavidenskab og dataanalyseindustrien.
Derfor er eksperter kommet med løsninger. Denne løsning er datarensning. Det sparer dig for at tage datadrevne beslutninger, der vil skade virksomheden i stedet for at forbedre den.
Læs videre for at lære de bedste datarensningsstrategier, succesrige datavidenskabsmænd og analytikere bruger. Udforsk også værktøjer, der kan tilbyde rene data til øjeblikkelige datavidenskabelige projekter.
Indholdsfortegnelse
Hvad er datarensning?
Datakvalitet har fem dimensioner. At identificere og rette fejl i dine inputdata ved at følge datakvalitetspolitikkerne er kendt som datarensning.
Kvalitetsparametrene for denne femdimensionelle standard er:
#1. Fuldstændighed
Denne kvalitetskontrolparameter sikrer, at inputdataene har alle de nødvendige parametre, overskrifter, rækker, kolonner, tabeller osv. til et datavidenskabsprojekt.
#2. Nøjagtighed
En datakvalitetsindikator, der siger, at dataene er tæt på den sande værdi af inputdataene. Data kan være af sand værdi, når du følger alle de statistiske standarder for undersøgelser eller skrotning til dataindsamling.
#3. Gyldighed
Denne parameter datavidenskab, at dataene overholder de forretningsregler, som du har sat op.
#4. Ensartethed
Ensartethed bekræfter, om data indeholder ensartet indhold eller ej. For eksempel bør energiforbrugsundersøgelsesdata i USA indeholde alle enhederne som det britiske målesystem. Hvis du bruger det metriske system til bestemt indhold i den samme undersøgelse, er dataene ikke ensartede.
#5. Konsistens
Konsistens sikrer, at dataværdierne er konsistente mellem tabeller, datamodeller og datasæt. Du skal også overvåge denne parameter nøje, når du flytter data på tværs af systemer.
I en nøddeskal skal du anvende ovenstående kvalitetskontrolprocesser på rå datasæt og rense data, før du sender dem til et business intelligence-værktøj.
Vigtigheden af datarensning
Bare sådan kan du ikke drive din digitale virksomhed på en dårlig internetbåndbreddeplan; du kan ikke træffe store beslutninger, når datakvaliteten er uacceptabel. Hvis du forsøger at bruge skrald og fejlagtige data til at træffe forretningsbeslutninger, vil du se et tab af omsætning eller dårligt investeringsafkast (ROI).
Ifølge en Gartner-rapport om dårlig datakvalitet og dens konsekvenser har tænketanken fundet ud af, at det gennemsnitlige tab en virksomhed står over for er 12,9 millioner dollars. Dette er kun for at træffe beslutninger baseret på fejlagtige, forfalskede og skralddata.
Den samme rapport antyder, at brug af dårlige data på tværs af USA koster landet et svimlende årligt tab på $3 billioner.
Den endelige indsigt vil helt sikkert være skrald, hvis du fodrer BI-systemet med skralddata.
Derfor skal du rense de rå data for at undgå pengetab og træffe effektive forretningsbeslutninger fra dataanalyseprojekter.
Fordele ved datarensning
#1. Undgå monetære tab
Ved at rense inputdataene kan du redde din virksomhed fra økonomiske tab, der kan komme som en straf for manglende overholdelse eller tab af kunder.
#2. Træf store beslutninger

Data af høj kvalitet og handlingsmuligheder giver stor indsigt. Sådanne indsigter hjælper dig med at træffe fremragende forretningsbeslutninger om produktmarketing, salg, lagerstyring, prissætning osv.
#3. Få et forspring i forhold til konkurrenten
Hvis du vælger datarensning tidligere end dine konkurrenter, vil du nyde fordelene ved at blive en hurtig bevægelse i din branche.
#4. Gør projektet effektivt
En strømlinet datarensningsproces øger teammedlemmernes tillidsniveau. Da de ved, at dataene er pålidelige, kan de fokusere mere på dataanalyse.
#5. Gem ressourcer
Rensning og trimning af data reducerer størrelsen af den samlede database. Derfor rydder du databaselagerpladsen ved at fjerne skralddata.
Strategier til at rense data
Standardiser de visuelle data
Et datasæt vil indeholde adskillige typer tegn som tekster, cifre, symboler osv. Du skal anvende et ensartet tekstformat for store bogstaver på alle tekster. Sørg for, at symboler er i den rigtige kodning, som Unicode, ASCII osv.
For eksempel betyder ordet Bill med stort bogstav navnet på en person. Modsat betyder en regning eller regning en modtagelse af en transaktion; derfor er passende formatering af store bogstaver afgørende.
Fjern replikerede data
Duplikerede data forvirrer BI-systemet. Følgelig vil mønsteret blive skævt. Derfor skal du frasortere duplikerede poster fra inputdatabasen.
Dubletter kommer normalt fra menneskelige dataindtastningsprocesser. Hvis du kan automatisere rådataindtastningsprocessen, kan du udrydde datareplikeringer fra roden.
Ret uønskede outliers
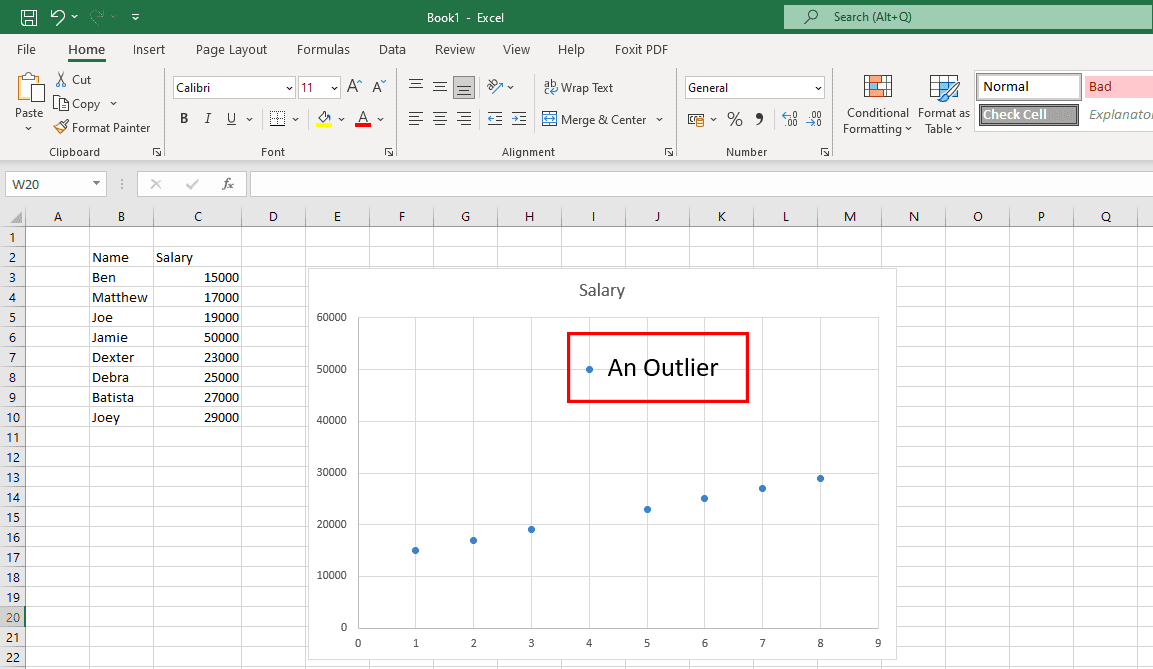
Outliers er usædvanlige datapunkter, der ikke ligger inden for datamønsteret, som vist i ovenstående graf. Ægte outliers er okay, da de hjælper dataforskerne med at opdage undersøgelsesfejl. Men hvis outliers kommer fra menneskelige fejl, så er det et problem.
Du skal placere datasættene i diagrammer eller grafer for at se efter afvigelser. Hvis du finder nogen, så undersøg kilden. Hvis kilden er en menneskelig fejl, skal du fjerne afvigende data.
Fokus på strukturelle data
Det er for det meste at finde og rette fejl i datasættene.
For eksempel indeholder et datasæt én kolonne med USD og mange kolonner med andre valutaer. Hvis dine data er for det amerikanske publikum, skal du konvertere andre valutaer til tilsvarende USD. Erstat derefter alle andre valutaer i USD.
Scan dine data
En enorm database downloadet fra et datavarehus kan indeholde tusindvis af tabeller. Du har muligvis ikke brug for alle tabellerne til dit datavidenskabsprojekt.
Derfor, efter at have fået databasen, skal du skrive et script for at lokalisere de datatabeller, du har brug for. Når du ved dette, kan du slette irrelevante tabeller og minimere størrelsen af datasættet.
Dette vil i sidste ende resultere i hurtigere datamønsteropdagelse.
Rens data på skyen
Hvis din database bruger schema-on-write-tilgangen, skal du konvertere den til schema-on-read. Dette vil muliggøre datarensning direkte på cloud-lageret og udtræk af formaterede, organiserede og klar til at analysere data.
Oversæt fremmedsprog
Hvis du kører en undersøgelse verden over, kan du forvente fremmedsprog i rådataene. Du skal oversætte rækker og kolonner, der indeholder fremmedsprog, til engelsk eller et hvilket som helst andet sprog, du foretrækker. Du kan bruge computerassisteret oversættelse (CAT) værktøjer til dette formål.
Trin-for-trin datarensning
#1. Find kritiske datafelter
Et datavarehus indeholder terabyte af databaser. Hver database kan indeholde nogle få til tusindvis af kolonner med data. Nu skal du se på projektets mål og udtrække data fra sådanne databaser i overensstemmelse hermed.
Hvis dit projekt studerer e-handelstendenser for amerikanske indbyggere, vil indsamling af data om offline detailbutikker i den samme projektmappe ikke gavne noget.
#2. Organiser data

Når du har fundet de vigtige datafelter, kolonneoverskrifter, tabeller osv. fra en database, skal du samle dem på en organiseret måde.
#3. Slet dubletter
Rådata indsamlet fra datavarehuse vil altid indeholde duplikerede poster. Du skal finde og slette disse replikaer.
#4. Fjern tomme værdier og mellemrum
Nogle kolonneoverskrifter og deres tilsvarende datafelt indeholder muligvis ingen værdier. Du skal fjerne disse kolonneoverskrifter/felter eller erstatte tomme værdier med de rigtige alfanumeriske.
#5. Udfør finformatering
Datasæt kan indeholde unødvendige mellemrum, symboler, tegn osv. Du skal formatere disse ved hjælp af formler, så det overordnede datasæt ser ensartet ud i cellestørrelse og spændvidde.
#6. Standardiser processen
Du skal oprette en SOP, som datavidenskabsteamets medlemmer kan følge og udføre deres pligt under datarensningsprocessen. Det skal indeholde følgende:
- Hyppighed af rådataindsamling
- Supervisor for rådatalagring og vedligeholdelse
- Udrensningsfrekvens
- Ren datalagring og vedligeholdelsessupervisor
Her er nogle populære datarensningsværktøjer, der kan hjælpe dig i dine datavidenskabelige projekter:
WinPure

Hvis du leder efter et program, der lader dig rense og skrubbe data præcist og hurtigt, er WinPure en pålidelig løsning. Dette brancheførende værktøj tilbyder en datarensningsfacilitet på virksomhedsniveau med uovertruffen hastighed og præcision.
Da det er designet til at betjene individuelle brugere og virksomheder, kan alle bruge det uden problemer. Softwaren bruger funktionen Advanced Data Profiling til at analysere typer, formater, integritet og værdi af data til kvalitetskontrol. Dens kraftfulde og intelligente data-matching-motor vælger perfekte matches med et minimum af falske matches.
Udover ovenstående funktioner tilbyder WinPure også fantastiske billeder til alle data, gruppekampe og ikke-kampe.
Det fungerer også som et fletteværktøj, der forbinder duplikerede poster for at generere en masterpost, der kan beholde alle aktuelle værdier. Desuden kan du bruge dette værktøj til at definere regler for valg af masterpost og fjerne alle poster med det samme.
OpenRefine
OpenRefine er et gratis og open source-værktøj, der hjælper dig med at transformere dine rodede data til et rent format, der kan bruges til webtjenester. Den bruger facetter til at rense store datasæt og opererer på filtrerede datasætvisninger.
Ved hjælp af kraftfulde heuristik kan værktøjet flette lignende værdier for at slippe af med alle uoverensstemmelser. Det tilbyder afstemningstjenester, så brugere kan matche deres datasæt med eksterne databaser. Derudover betyder brug af dette værktøj, at du kan vende tilbage til den ældre datasætversion, hvis det er nødvendigt.
Brugere kan også afspille operationshistorik på en opdateret version. Hvis du er bekymret for datasikkerhed, er OpenRefine den rigtige mulighed for dig. Det renser dine data på din maskine, så der er ingen datamigrering til skyen til dette formål.
Trifacta Designer Cloud

Selvom datarensning kan være kompleks, gør Trifacta Designer Cloud det nemmere for dig. Den bruger en ny dataforberedelsestilgang til datascrubbing, så organisationer kan få mest muligt ud af det.
Dens brugervenlige grænseflade gør det muligt for ikke-tekniske brugere at rense og skrubbe data til sofistikeret analyse. Nu kan virksomheder gøre mere med deres data ved at udnytte de ML-drevne intelligente forslag fra Trifacta Designer Cloud.
Hvad mere er, vil de skulle investere mindre tid i denne proces, mens de skal håndtere færre fejl. Det kræver, at du bruger reducerede ressourcer på at få mere ud af analysen.
Cloudingo
Er du Salesforce-bruger bekymret for kvaliteten af de indsamlede data? Brug Cloudingo til at rydde op i kundedata og har kun de nødvendige data. Denne applikation gør det nemt at administrere kundedata med funktioner som deduplikering, import og migrering.
Her kan du kontrollere registreringssammenfletning med tilpassede filtre og regler og standardisere data. Slet ubrugelige og inaktive data, opdater manglende datapunkter, og sørg for nøjagtighed i amerikanske postadresser.
Virksomheder kan også planlægge Cloudingo til at deduplikere data automatisk, så du altid kan have adgang til rene data. At holde dataene synkroniseret med Salesforce er en anden afgørende funktion ved dette værktøj. Med det kan du endda sammenligne Salesforce-data med oplysninger, der er gemt i et regneark.
ZoomInfo

ZoomInfo er en udbyder af datarensningsløsninger, der bidrager til dit teams produktivitet og effektivitet. Virksomheder kan opleve mere rentabilitet, da denne software leverer duplikeringsfri data til virksomhedens CRM og MAT’er.
Det ukomplicerer datakvalitetsstyring ved at fjerne alle de dyre duplikerede data. Brugere kan også sikre deres CRM- og MAT-perimeter ved hjælp af ZoomInfo. Det kan rense data inden for få minutter med automatisk deduplikering, matchning og normalisering.
Brugere af denne applikation kan nyde fleksibilitet og kontrol over matchende kriterier og flettede resultater. Det hjælper dig med at opbygge et omkostningseffektivt datalagringssystem ved at standardisere enhver type data.
Afsluttende ord
Du bør være bekymret for kvaliteten af inputdataene i dine datavidenskabelige projekter. Det er det grundlæggende feed for store projekter som maskinlæring (ML), neurale netværk til AI-baseret automatisering osv. Hvis feedet er defekt, så tænk på hvad der ville være resultatet af sådanne projekter.
Derfor skal din organisation vedtage en dokumenteret datarensningsstrategi og implementere den som en standard operationsprocedure (SOP). Kvaliteten af inputdata vil derfor også forbedres.
Hvis du har travlt nok med projekter, markedsføring og salg, er det bedre at overlade datarensningsdelen til eksperterne. Eksperten kan være et hvilket som helst af ovenstående datarensningsværktøjer.
Du kan også være interesseret i et serviceplan for at implementere datarensningsstrategier uden besvær.