
Nutidens virksomheder er datacentrerede. Virksomheder er ved at finde måder til effektivt at mine og analysere data fra forskellige kilder og forbedre virksomhedens indtægter og overskud.
Men hvad er det sikreste sted at opbevare og integrere data fra flere kilder og få mest muligt ud af det?
Både datasøer og datavarehuse er populære måder at håndtere store mængder big data på. Forskellene mellem dem ligger i, hvordan organisationer indtager, opbevarer og bruger dataene. Læs videre for at vide mere.
Indholdsfortegnelse
Hvad er en Data Lake?
En datasø refererer til et centralt lager, hvor data indtaget fra flere kilder – i ethvert format (struktureret eller ustruktureret) – gemmes som modtaget. Det er som en pulje af rådata, hvis formål er ukendt endnu. Virksomheder gemmer normalt data, der potentielt kan være nyttige til fremtidig analyse i en datasø.
Nøglefunktioner ved en datasø:
- Den indeholder en blanding af nyttige og ikke-nyttige data og har derfor brug for meget lagerplads.
- Gemmer både realtids- og batchdata – for eksempel kan du gemme realtidsdata fra IoT-enheder, sociale medier eller cloud-applikationer og batchdata fra databaser eller datafiler.
- Har en flad arkitektur.
- Da dataene ikke behandles, før de er nødvendige til analyse, skal de styres og vedligeholdes godt; ellers kan det blive til datasumpe.
Så hvordan kan vi hente data hurtigt fra et så stort og tilsyneladende rodet lagerlager? Nå, en datasø bruger metadata-tags og identifikatorer til dette formål!
Hvad er et datavarehus?
Et mere organiseret og struktureret lager – et datavarehus indeholder data, der er klar til analyse. Strukturerede, semistrukturerede eller ustrukturerede data fra flere kilder indtages, integreres, renses, sorteres, transformeres og gøres egnede til brug.
Datavarehuset indeholder store mængder tidligere og nuværende data. Normalt behandles data til et specifikt forretningsproblem (analyse). Sådanne oplysninger forespørges af Business Intelligence (BI)-systemer til analyse, rapportering og indsigt.
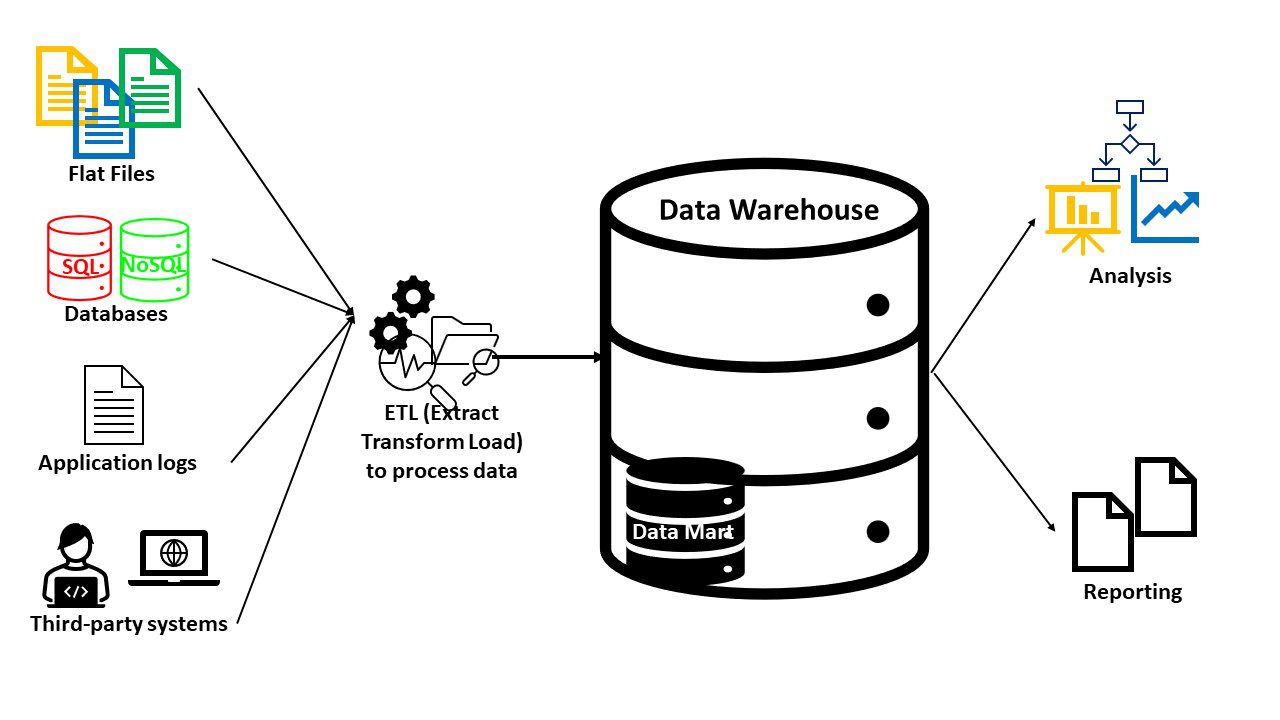
Datavarehuse består typisk af følgende:
- En database (SQL eller NoSQL) til at gemme og administrere data
- Datatransformation og analyseværktøjer til at forberede data
- BI-værktøjer til datamining, statistisk analyse, rapportering og visualisering
Da datavarehuse tjener et bestemt formål, har du altid relevante data. Du kan også bruge yderligere værktøjer i datavarehuse til at imødekomme avancerede funktioner som kunstig intelligens og rumlige eller grafiske funktioner. Datavarehuse oprettet til et specifikt domæne kaldes data marts.
Vigtigste forskelle mellem Data Lakes og Data Warehouses
For at gentage det, vi læste ovenfor, indeholder datasøen rådata, hvis formål ikke er defineret. Derimod indeholder et datavarehus data, der er klar til analyse og allerede er i sin bedste form.
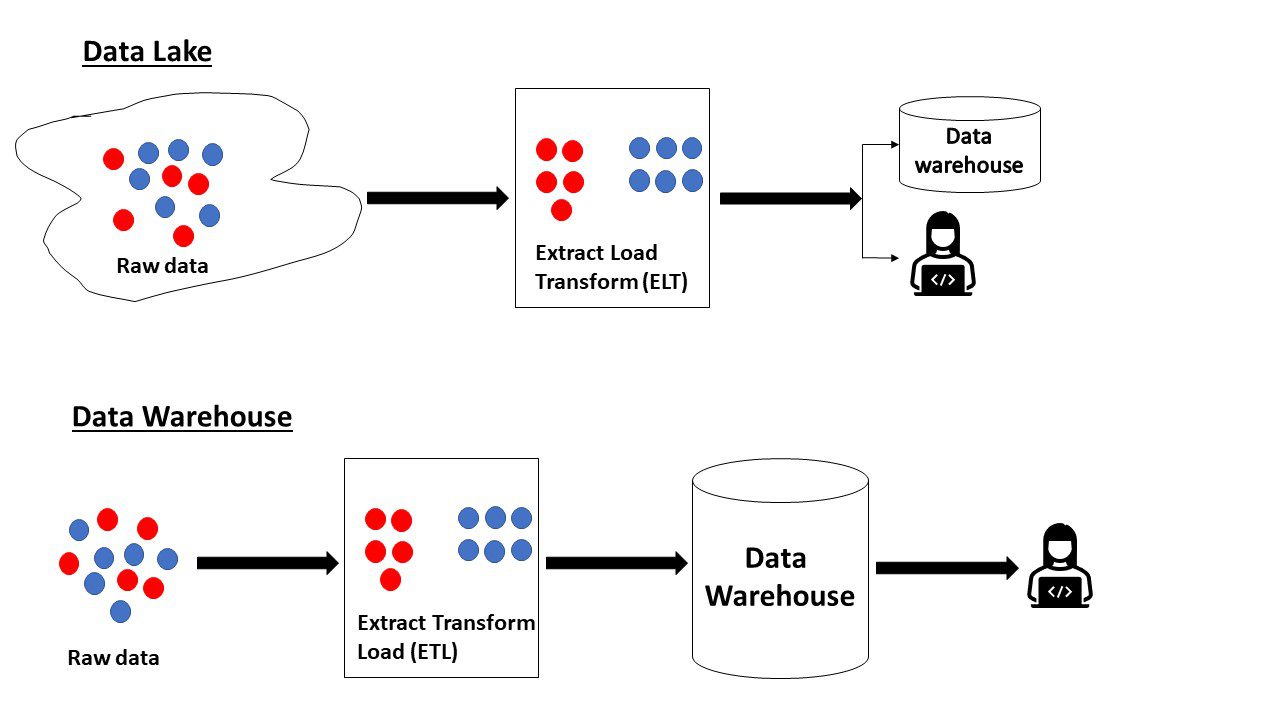 Datasø vs. Datavarehus
Datasø vs. Datavarehus
Nogle forskelle mellem en datasø og et datavarehus er:
Data LakeData WarehouseRå eller behandlede data i ethvert format indtages fra flere kilder.Data hentes fra flere kilder til analyse og rapportering. Det er struktureretSkema oprettes i farten efter behov (skema-på-læs)Foruddefineret skema under skrivning til lageret (Schema-on-write)Nye data kan nemt tilføjes Data er klar efter behandling, så enhver ny ændring kræver mere tid og indsats.Data skal opdateres og styres for at være relevanteData er allerede i sin bedste form, så det kræver ikke specifik vedligeholdelseDen består af enorme mængder big data (petabytes)Data er normalt mindre end i datasøen (terabyte). Datavarehus kan indeholde operationelle data for en hel organisation, analytiske data eller data, der er relevante for et bestemt domæne, der bruges af datavidenskabsmænd til forskellige formål, såsom streaminganalyse, kunstig intelligens, forudsigende analyser og mange brugssager. Bruges af forretningsanalytikere til transaktionsbehandling ( OLTP), operationel analyse (OLAP), rapportering, oprettelse af visualiseringer Data kan lagres og arkiveres i en længere periode for at blive analyseret til enhver tid. Data skal ofte renses for at rumme de nyeste data. Opbevaring er billigt. Opbevaring og behandling er dyrt og tid. -forbrugende, bør derfor planlægges omhyggeligt. Dataforskere kan udvikle nye problemer og løsninger ved at se på dataene. Dataomfanget er begrænset til et specifikt forretningsproblem. Da data ikke er organiseret på en bestemt måde, både relationel og ikke- relationelle databaser kan bruges til at gemme data. Datavarehuse bruger typisk relationelle databaser, fordi dataene skal være i en del kulært format.
Use Cases til Data Lake og Data Warehouse
Det er nemt at tænke på en datasø som et mere bekvemt valg, fordi den er mere skalerbar, fleksibel og lommevenlig. Et datavarehus kan dog være en god idé, når du har brug for mere relevante og strukturerede data til specifik analyse.
Nogle use cases for data lake er som nedenfor:
#1. Supply chain og ledelse
Den enorme mængde big data i datasøer hjælper med forudsigelige analyser til transport og logistik. Ved hjælp af historiske og aktuelle data kan virksomheder planlægge deres daglige drift problemfrit, inspicere lagerbevægelser i realtid og optimere omkostningerne.
#2. Sundhedspleje
Datasøen har al tidligere og nuværende information om patienter. Dette er nyttigt i forskning, at finde mønstre, give bedre og forudgående behandling af sygdomme, automatisere diagnostik og få de mest opdaterede detaljer om en patients helbred.
#3. Streaming af data og IoT
Datasøer kan kontinuerligt modtage streamingdata, der sendes til analytics-pipelines, for løbende rapportering og detektering af usædvanlige aktiviteter og bevægelser. Dette er muligt på grund af datasøens evne til at indsamle (nær) realtidsdata.
Nogle use cases for datavarehuset er:
#1. Finansiere
En virksomheds økonomiske oplysninger kan være mere velegnede til et datavarehus. Medarbejdere kan nemt få adgang til organiseret og struktureret information i form af diagrammer og rapporter for at styre økonomiprocesserne, håndtere risici og træffe strategiske beslutninger.
#2. Markedsføring og kundesegmentering
Data warehouse opretter en enkelt kilde til ‘sandhed’ eller korrekte data om kunder indsamlet fra flere kilder. Virksomheder kan analysere disse data for at forstå kundeadfærd, tilbyde skræddersyede rabatter, segmentere kunder baseret på deres præferencer og generere flere kundeemner.
#3. Virksomhedens dashboards og rapporter
Mange virksomheder bruger CRM- og ERP-datavarehuse til at trække data om eksterne og interne kunder. Dataene er altid relevante og kan have tillid til at skabe enhver form for rapport og visualisering.
#4. Migrering af data fra ældre systemer
Ved at bruge ETL-funktionerne i datavarehuse kan virksomheder nemt transformere ældre systemdata til et mere anvendeligt format, som nye systemer kan analysere. Dette vil hjælpe organisationer med at få indsigt i historiske tendenser og træffe nøjagtige forretningsbeslutninger.
Eksempler på Data Lake-værktøjer
Nogle af de bedste datasø-udbydere er:
- Microsoft Azure – Azure kan gemme og analysere petabytes af data. Azure letter nem fejlfinding og optimering af big data-programmer.
- Google Cloud – Google cloud tilbyder omkostningseffektiv indtagelse, lagring og analyse af enorme mængder big data af enhver type. Det integreres også med analyseværktøjer som Apache Spark, BigQuery og andre analyseacceleratorer.
- MongoDB Atlas – Atlas data lake er en fuldt administreret data lake butik. Det giver omkostningseffektive måder at gemme data i stor skala på og kan køre højtydende forespørgsler, der bruger mindre computerkraft, hvilket sparer tid og omkostninger.
- Amazon S3 – AWS-skyen giver de nødvendige værktøjer til at bygge en fleksibel, sikker og omkostningseffektiv datasø. Den har en interaktiv konsol til at administrere datasø-brugere og kontrollere adgang til brugere.
Eksempler på Data Warehouse-værktøjer
Nogle af de bedste udbydere af datavarehusløsninger er:
- SAP – SAP data warehouse giver brugere semantisk adgang til rige data fra flere kilder. Virksomheder kan sikkert dele indsigt og modeller, fremskynde beslutningstagning og sikkert kombinere eksterne og interne data.
- ClicData – ClicDatas smarte og integrerede datavarehus sikrer dataintegritet, kvalitet og nem rapportering. ClicData tilbyder både planlægningssystemer og realtids-API’er, så du til enhver tid kan få opdaterede data.
- Amazon rødforskydning – Et af de mest udbredte datavarehuse, Redshift bruger SQL til at analysere alle typer data, der findes i forskellige databaser, søer eller andre varehuse. Det giver en god balance mellem omkostninger og ydeevne.
- IBM Db2 lager – IBM leverer in-house, cloud og integrerede data warehousing løsninger. Den integrerer også maskinlærings- og kunstig intelligensværktøjer til dybere dataanalyse og deler en fælles SQL-motor til at strømline forespørgsler.
- Oracle Cloud Data warehouse – Oracle bruger en database i hukommelsen og tilbyder grafiske, maskinlærings- og rumlige muligheder for at dykke dybt ned i data for hurtigere, men rigere dataanalyse.
Afsluttende ord
Både datasøer og datavarehuse har deres egne fordele og ideelle use cases. Mens datasøer er mere skalerbare og fleksible, har datavarehuse altid pålidelige og strukturerede oplysninger. Data Lake-implementering er relativt ny, hvorimod data warehouse er et etableret koncept, der bruges af mange organisationer til effektivt at administrere deres interne og eksterne data.