

Det er relativt nemt at bygge én maskinlæringsmodel. Det er svært at skabe hundredvis eller tusindvis af modeller og gentage eksisterende modeller.
Det er nemt at fare vild i kaosset. Dette kaos forværres, når man arbejder som et team, da man nu skal holde styr på, hvad alle laver. At bringe orden i kaosset kræver, at hele teamet følger en proces og dokumenterer deres aktiviteter. Dette er essensen af MLOps.
Indholdsfortegnelse
Hvad er MLOps?
Kilde: ml-ops.org
Ifølge MLOps.org forsøger Machine Learning Operationalization at bygge en ende-til-ende Machine Learning-udviklingsproces til at designe, bygge og administrere reproducerbar, testbar og evolverbar ML-drevet software. I det væsentlige er MLOps DevOps-principper, der anvendes til Machine Learning.
Ligesom DevOps er nøgleideen med MLOps automatisering for at reducere manuelle trin og øge effektiviteten. Ligesom DevOps inkluderer MLOps både Continuous Integration (CI) og Continuous Delivery (CD). Ud over disse to inkluderer det også kontinuerlig træning (CT). Det yderligere aspekt af CT involverer genoptræning af modeller med nye data og omplacering af dem.
MLOps er derfor en ingeniørkultur, der fremmer en metodisk tilgang til udvikling af maskinlæringsmodeller og automatisering af forskellige trin i metoden. Processen involverer primært dataudtræk, analyse, forberedelse, modeltræning, evaluering, modelservering og overvågning.
Fordele ved MLOps
Generelt er fordelene ved at anvende MLOps-principper de samme som fordelene ved at have standarddriftsprocedurer. Fordelene er som følger:
- En veldefineret proces giver en køreplan over alle de afgørende skridt, der skal tages i modeludvikling. Dette sikrer, at ingen kritiske trin overses.
- Trin i processen, der kan automatiseres, kan identificeres og automatiseres. Dette reducerer mængden af gentaget arbejde og øger udviklingshastigheden. Det eliminerer også menneskelige fejl, mens det reducerer mængden af arbejde, der skal udføres.
- Det bliver nemmere at vurdere fremskridt i en models udvikling ved at vide, i hvilken fase af pipelinen modellen befinder sig.
- Det er nemmere for teams at kommunikere, da der er et fælles ordforråd for trin, der skal tages under udvikling.
- Processen kan anvendes gentagne gange til at udvikle mange modeller, hvilket giver en måde at styre kaosset på.
Så i sidste ende er MLOps’s rolle i maskinlæring at give en metodisk tilgang til modeludvikling, der kan automatiseres så meget som muligt.
Platforme til at bygge rørledninger
For at hjælpe dig med at implementere MLOps i dine pipelines, kan du bruge en af de mange platforme, vi vil diskutere her. Selvom de individuelle funktioner på disse platforme kan være forskellige, hjælper de dig i det væsentlige med at gøre følgende:
- Gem alle dine modeller sammen med deres tilknyttede modelmetadata – såsom konfigurationer, kode, nøjagtighed og eksperimenter. Det inkluderer også de forskellige versioner af dine modeller til versionskontrol.
- Gem datasætmetadata, såsom data, der blev brugt til at træne modeller.
- Overvåg modeller i produktion for at fange problemer såsom modeldrift.
- Implementer modeller til produktion.
- Byg modeller i miljøer med lav kode eller kodefri.
Lad os udforske de bedste MLOps-platforme.
MLFlow

MLFlow er måske den mest populære Machine Learning Lifecycle management platform. Det er gratis og open source. Det giver følgende funktioner:
- sporing til registrering af dine maskinlæringseksperimenter, kode, data, konfigurationer og endelige resultater;
- projekter til at pakke din kode i et format, der er let at reproducere;
- implementering til implementering af din maskinlæring;
- et register til at gemme alle dine modeller i et centralt lager
MLFlow integreres med populære maskinlæringsbiblioteker som TensorFlow og PyTorch. Den integreres også med platforme som Apache Spark, H20.asi, Google Cloud, Amazon Sage Maker, Azure Machine Learning og Databricks. Det fungerer også med forskellige cloud-udbydere såsom AWS, Google Cloud og Microsoft Azure.
Azure Machine Learning
Azure Machine Learning er en ende-til-ende maskinlæringsplatform. Den administrerer de forskellige maskinlivscyklusaktiviteter i din MLOPs pipeline. Disse aktiviteter omfatter dataforberedelse, opbygning og træning af modeller, validering og implementering af modeller og styring og overvågning af implementeringer.
Azure Machine Learning giver dig mulighed for at bygge modeller ved hjælp af din foretrukne IDE og valgte rammer, PyTorch eller TensorFlow.
Den integreres også med ONNX Runtime og Deepspeed for at optimere din træning og inferens. Dette forbedrer ydeevnen. Det udnytter AI-infrastruktur på Microsoft Azure, der kombinerer NVIDIA GPU’er og Mellanox-netværk for at hjælpe dig med at bygge maskinlæringsklynger. Med AML kan du oprette et centralt register til at gemme og dele modeller og datasæt.
Azure Machine Learning integreres med Git og GitHub Actions for at bygge arbejdsgange. Det understøtter også en hybrid eller multi-cloud opsætning. Du kan også integrere det med andre Azure-tjenester såsom Synapse Analytics, Data Lake, Databricks og Security Center.
Google Vertex AI

Google Vertex AI er en samlet data- og AI-platform. Det giver dig det værktøj, du har brug for til at bygge brugerdefinerede og fortrænede modeller. Det fungerer også som en end-to-end løsning til implementering af MLOps. For at gøre det nemmere at bruge, integreres det med BigQuery, Dataproc og Spark for problemfri dataadgang under træning.
Ud over API’en leverer Google Vertex AI et værktøjsmiljø med lav kode og kodefrit, så det kan bruges af ikke-udviklere såsom forretnings- og dataanalytikere og ingeniører. API’en gør det muligt for udviklere at integrere det med eksisterende systemer.
Google Vertex AI giver dig også mulighed for at bygge generative AI-apps ved hjælp af Generative AI Studio. Det gør implementering og administration af infrastruktur let og hurtig. De ideelle use cases for Google Vertex AI omfatter sikring af databeredskab, funktionsudvikling, træning og hyperparameterjustering, modelservering, modeljustering og -forståelse, modelovervågning og modelstyring.
Databricks

Databricks er et datasøhus, der gør dig i stand til at forberede og behandle data. Med Databricks kan du styre hele maskinlærings-livscyklussen fra eksperimentering til produktion.
Grundlæggende leverer Databricks administreret MLFlow med funktioner såsom datalogning af annonceversioner af ML-modeller, eksperimentsporing, modelvisning, et modelregistrering og sporing af annoncemetrik. Modelregistret giver dig mulighed for at gemme modeller med henblik på reproducerbarhed, og registreringsdatabasen hjælper dig med at holde styr på versioner og det stadie af livscyklussen, de befinder sig i.
Implementering af modeller ved hjælp af Dataricks kan udføres med blot et enkelt klik, og du vil have REST API-endepunkter til at bruge til at lave forudsigelser. Blandt andre modeller integreres det godt med eksisterende fortrænede generative og store sprogmodeller, såsom dem fra biblioteket med kramme ansigtstransformere.
Dataricks leverer samarbejdsbaserede Databricks-notebooks, der understøtter Python, R, SQL og Scala. Derudover forenkler det administration af infrastruktur ved at levere prækonfigurerede klynger, der er optimeret til Machine Learning-opgaver.
AWS SageMaker
AWS SageMaker er en AWS Cloud Service, der giver dig de værktøjer, du skal bruge til at udvikle, træne og implementere dine machine learning-modeller. Det primære formål med SageMaker er at automatisere det kedelige og gentagne manuelle arbejde, der er involveret i at bygge en maskinlæringsmodel.
Som et resultat giver det dig værktøjer til at bygge en produktionspipeline til dine maskinlæringsmodeller ved hjælp af forskellige AWS-tjenester, såsom Amazon EC2-instanser og Amazon S3-lagring.
SageMaker arbejder med Jupyter Notebooks installeret på en EC2-instans sammen med alle de almindelige pakker og biblioteker, der er nødvendige for at kode en Machine Learning-model. For data er SageMaker i stand til at trække data fra Amazon Simple Storage Service.
Som standard får du implementeringer af almindelige maskinlæringsalgoritmer såsom lineær regression og billedklassificering. SageMaker kommer også med en modelmonitor til at give kontinuerlig og automatisk tuning for at finde det sæt af parametre, der giver den bedste ydeevne for dine modeller. Implementeringen er også forenklet, da du nemt kan implementere din model til AWS som et sikkert HTTP-slutpunkt, som du kan overvåge med CloudWatch.
DataRobot
DataRobot er en populær MLOps-platform, der tillader styring på tværs af forskellige stadier af Machine Learning-livscyklussen, såsom dataforberedelse, ML-eksperimentering, validering og styring af modeller.
Det har værktøjer til at automatisere kørende eksperimenter med forskellige datakilder, teste tusindvis af modeller og evaluere de bedste til at implementere til produktion. Det understøtter opbygning af modeller til forskellige typer AI-modeller til løsning af problemer i tidsserier, naturlig sprogbehandling og computersyn.
Med DataRobot kan du bygge ved hjælp af out-of-the-box modeller, så du ikke behøver at skrive kode. Alternativt kan du vælge en kode-først tilgang og implementere modeller ved hjælp af tilpasset kode.
DataRobot leveres med notesbøger til at skrive og redigere koden. Alternativt kan du bruge API’et, så du kan udvikle modeller i en IDE efter eget valg. Ved at bruge GUI’en kan du spore dine modellers eksperimenter.
Kør AI

Kør AI forsøger at løse problemet med underudnyttelse af AI-infrastruktur, især GPU’er. Det løser dette problem ved at fremme synligheden af al infrastruktur og sikre, at den bliver brugt under træning.
For at udføre dette, sidder Run AI mellem din MLOps-software og firmaets hardware. Mens du besætter dette lag, køres alle træningsjob ved hjælp af Run AI. Platformen planlægger til gengæld, hvornår hvert af disse job skal køres.
Der er ingen begrænsning for, om hardwaren skal være cloud-baseret, såsom AWS og Google Cloud, on-premises eller en hybridløsning. Det giver et lag af abstraktion til Machine Learning-teams ved at fungere som en GPU-virtualiseringsplatform. Du kan køre opgaver fra Jupyter Notebook, bash-terminal eller ekstern PyCharm.
H2O.ai
H2O er en open source, distribueret maskinlæringsplatform. Det gør det muligt for teams at samarbejde og skabe et centralt lager for modeller, hvor datavidenskabsfolk kan eksperimentere og sammenligne forskellige modeller.
Som en MLOps-platform tilbyder H20 en række nøglefunktioner. For det første forenkler H2O også modelimplementering til en server som et REST-slutpunkt. Det giver forskellige implementeringsemner, såsom A/B-test, Champoion-Challenger-modeller og enkel implementering af en enkelt model.
Under træning gemmer og administrerer den data, artefakter, eksperimenter, modeller og implementeringer. Dette gør det muligt for modeller at være reproducerbare. Det muliggør også administration af tilladelser på gruppe- og brugerniveau til at styre modeller og data. Mens modellen kører, giver H2O også overvågning i realtid for modeldrift og andre operationelle målinger.
Paperspace gradient
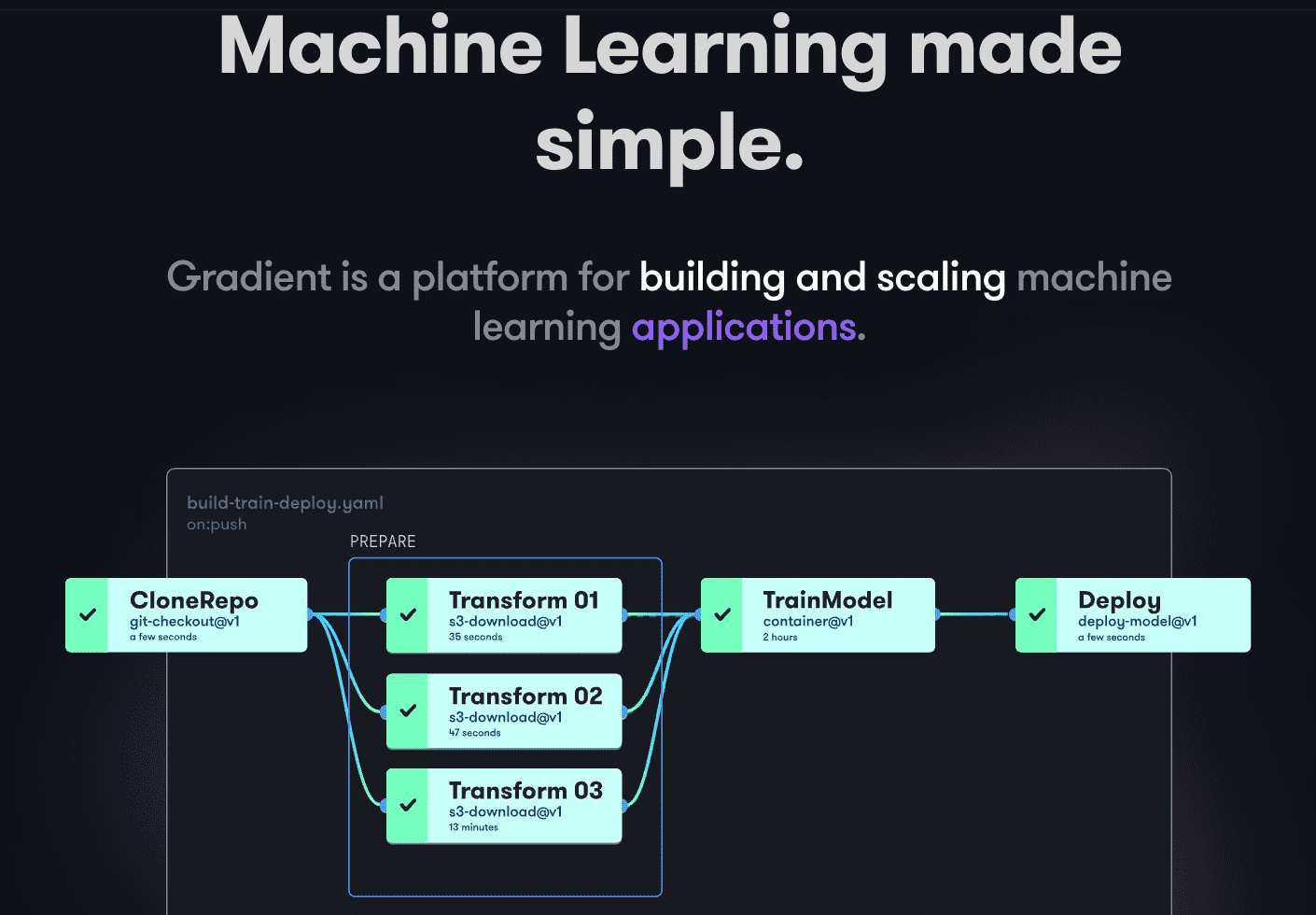
Gradient hjælper udviklere på alle stadier af Machine Learning-udviklingscyklussen. Det giver notebooks drevet af open source Jupyter til modeludvikling og træning i skyen ved hjælp af kraftfulde GPU’er. Dette giver dig mulighed for hurtigt at udforske og prototype modeller.
Implementeringspipelines kan automatiseres ved at oprette arbejdsgange. Disse arbejdsgange er defineret ved at beskrive opgaver i YAML. Brug af arbejdsgange gør oprettelse af implementeringer og visningsmodeller nemme at replikere og derfor skalerbare som et resultat.
Som helhed leverer Gradient containere, maskiner, data, modeller, metrics, logs og hemmeligheder for at hjælpe dig med at administrere forskellige stadier af Machine Learning-modellens udviklingspipeline. Dine pipelines kører på Gradiet-klynger. Disse klynger er enten på Paperspace Cloud, AWS, GCP, Azure eller andre servere. Du kan interagere med Gradient ved hjælp af CLI eller SDK programmatisk.
Afsluttende ord
MLOps er en kraftfuld og alsidig tilgang til at bygge, implementere og administrere maskinlæringsmodeller i stor skala. MLOps er let at bruge, skalerbar og sikker, hvilket gør det til et godt valg for organisationer i alle størrelser.
I denne artikel dækkede vi MLOP’er, hvorfor det er vigtigt at implementere dem, hvad der er involveret, og de forskellige populære MLOps-platforme.
Dernæst vil du måske læse vores sammenligning af Dataricks vs. Snowflake.