
Nå, statistik fra Forbes siger, at op til 90% af verdens organisationer bruger Big Data-analyse til at oprette deres investeringsrapporter.
Med den stigende popularitet af Big Data er der følgelig en stigning i Hadoop jobmuligheder mere end før.
Derfor, for at hjælpe dig med at få den Hadoop-ekspertrolle, kan du bruge disse interviewspørgsmål og -svar, vi har samlet til dig i denne artikel, for at hjælpe dig med at komme igennem dit interview.
Måske vil det motivere dig til at bestå det interview, at kende de fakta som løninterval, der gør Hadoop- og Big Data-roller lukrative? 🤔
- Ifølge indeed.com tjener en amerikansk-baseret Big Data Hadoop-udvikler en gennemsnitsløn på $144.000.
- Ifølge itjobswatch.co.uk er en Big Data Hadoop-udviklers gennemsnitlige løn £66.750.
- I Indien oplyser indeed.com-kilden, at de ville tjene en gennemsnitlig løn på 16.00.000 INR.
Indbringende, synes du ikke? Lad os nu hoppe ind for at lære om Hadoop.
Indholdsfortegnelse
Hvad er Hadoop?
Hadoop er en populær ramme skrevet i Java, der bruger programmeringsmodeller til at behandle, lagre og analysere store datasæt.
Som standard tillader dets design opskalering fra enkelte servere til flere maskiner, der tilbyder lokal beregning og lagring. Derudover gør dens evne til at opdage og håndtere applikationslagsfejl, hvilket resulterer i meget tilgængelige tjenester, Hadoop ret pålidelig.
Lad os springe direkte ind i de ofte stillede Hadoop-interviewspørgsmål og deres korrekte svar.
Hadoops interviewspørgsmål og svar
Hvad er lagerenheden i Hadoop?
Svar: Hadoops lagerenhed kaldes Hadoop Distributed File System (HDFS).
Hvordan er Network Attached Storage forskellig fra Hadoop Distributed File System?
Svar: HDFS, som er Hadoops primære lager, er et distribueret filsystem, der gemmer massive filer ved hjælp af råvarehardware. På den anden side er NAS en datalagringsserver på filniveau, der giver heterogene klientgrupper adgang til dataene.
Mens datalagring i NAS er på dedikeret hardware, distribuerer HDFS datablokkene på tværs af alle maskiner i Hadoop-klyngen.
NAS bruger avancerede lagringsenheder, hvilket er temmelig dyrt, mens den råvarehardware, der bruges i HDFS, er omkostningseffektiv.
NAS gemmer data fra beregninger separat og gør det derfor uegnet til MapReduce. Tværtimod gør HDFS’ design det muligt at arbejde med MapReduce-rammerne. Beregninger flytter til dataene i MapReduce-rammerne i stedet for data til beregninger.
Forklar MapReduce i Hadoop og Shuffling
Svar: MapReduce henviser til to forskellige opgaver, som Hadoop-programmer udfører for at muliggøre stor skalerbarhed på tværs af hundreder til tusindvis af servere i en Hadoop-klynge. Blanding overfører på den anden side kortoutput fra Mappers til den nødvendige Reducer i MapReduce.
Giv et indblik i Apache Pig Architecture
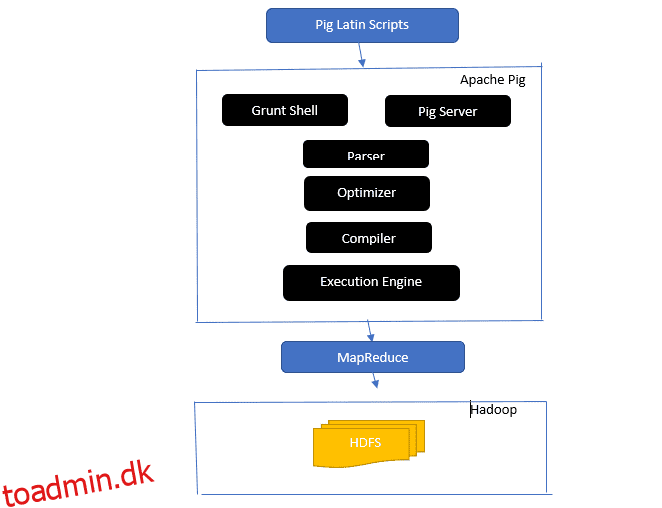
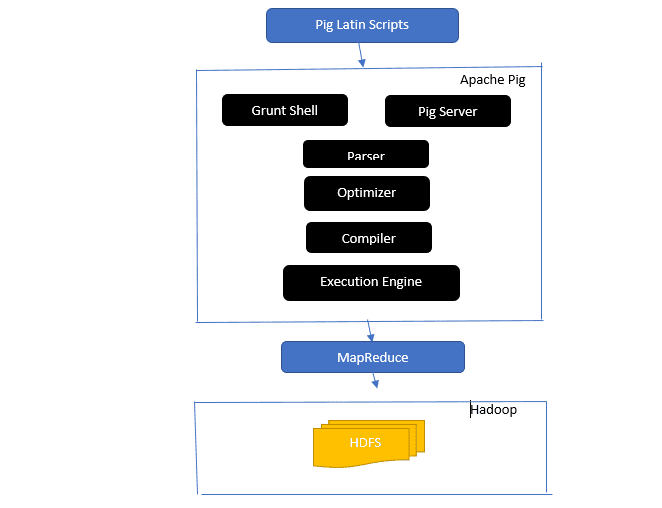 Apache-grisearkitekturen
Apache-grisearkitekturen
Svar: Apache Pig-arkitektur har en Pig Latin-fortolker, der behandler og analyserer store datasæt ved hjælp af Pig Latin-scripts.
Apache pig består også af sæt af datasæt, hvorpå datahandlinger som join, load, filter, sort og group udføres.
Det latinske svinesprog bruger udførelsesmekanismer som Grant-skaller, UDF’er og indlejret til at skrive Pig-scripts, der udfører nødvendige opgaver.
Pig gør programmørers arbejde lettere ved at konvertere disse skrevne scripts til Map-Reduce job-serier.
Apache Pig-arkitekturkomponenter inkluderer:
- Parser – Den håndterer Pig Scripts ved at kontrollere scriptets syntaks og udføre typekontrol. Parserens output repræsenterer Pig Latins udsagn og logiske operatorer og kaldes DAG (directed acyclic graph).
- Optimizer – Optimizeren implementerer logiske optimeringer som projektion og pushdown på DAG.
- Compiler – Kompilerer den optimerede logiske plan fra optimeringsværktøjet til en række MapReduce-job.
- Execution Engine – Det er her den endelige udførelse af MapReduce-jobbene til det ønskede output finder sted.
- Udførelsestilstand – Udførelsestilstandene i Apache pig inkluderer hovedsageligt lokal og Map Reduce.
Svar: Metastore-tjenesten i Local Metastore kører i samme JVM som Hive, men forbinder til en database, der kører i en separat proces på den samme eller en ekstern maskine. På den anden side kører Metastore i Remote Metastore i sin JVM adskilt fra Hive-tjenesten JVM.
Hvad er de fem V’er af Big Data?
Svar: Disse fem V’er står for Big Datas hovedkarakteristika. De omfatter:
- Værdi: Big data søger at give betydelige fordele fra et højt investeringsafkast (ROI) til en organisation, der bruger big data i sin datadrift. Big data bringer denne værdi fra deres indsigtsopdagelse og mønstergenkendelse, hvilket resulterer i stærkere kunderelationer og mere effektiv drift, blandt andre fordele.
- Variation: Dette repræsenterer heterogeniteten af typen af indsamlede datatyper. De forskellige formater omfatter CSV, videoer, lyd osv.
- Volumen: Dette definerer den betydelige mængde og størrelse af data, der administreres og analyseres af en organisation. Disse data viser eksponentiel vækst.
- Hastighed: Dette er den eksponentielle hastighed for datavækst.
- Sandhed: Sandhed refererer til, hvor “usikre” eller “unøjagtige” tilgængelige data skyldes, at data er ufuldstændige eller inkonsistente.
Forklar forskellige datatyper af griselatin.
Svar: Datatyperne i Pig Latin inkluderer atomare datatyper og komplekse datatyper.
Atomiske datatyper er de grundlæggende datatyper, der bruges på alle andre sprog. De omfatter følgende:
- Int – Denne datatype definerer et 32-bit heltal med fortegn. Eksempel: 13
- Lang – Lang definerer et 64-bit heltal. Eksempel: 10L
- Float – Definerer et 32-bit flydende punkt med fortegn. Eksempel: 2,5F
- Dobbelt – Definerer et 64-bit flydende komma med fortegn. Eksempel: 23.4
- Boolean – Definerer en boolesk værdi. Det inkluderer: Sandt/False
- Datetime – Definerer en dato-tidsværdi. Eksempel: 1980-01-01T00:00.00.000+00:00
Komplekse datatyper omfatter:
- Kort- Kort refererer til et sæt nøgleværdipar. Eksempel: [‘color’#’yellow’, ‘number’#3]
- Taske – Det er en samling af et sæt tupler, og den bruger ‘{}’-symbolet. Eksempel: {(Henry, 32), (Kiti, 47)}
- Tuple – En tuple definerer et ordnet sæt felter. Eksempel: (Alder, 33)
Hvad er Apache Oozie og Apache ZooKeeper?
Svar: Apache Oozie er en Hadoop-planlægger med ansvar for at planlægge og binde Hadoop-job sammen som et enkelt logisk arbejde.
Apache Zookeeper, på den anden side, koordinerer med forskellige tjenester i et distribueret miljø. Det sparer udviklerne tid ved blot at afsløre simple tjenester som synkronisering, gruppering, konfigurationsvedligeholdelse og navngivning. Apache Zookeeper yder også hyldestøtte til kø- og ledervalg.
Hvad er rollen for Combiner, RecordReader og Partitioner i en MapReduce-operation?
Svar: Kombineren fungerer som en mini-reduktion. Den modtager og arbejder på data fra kortopgaver og sender derefter dataens output til reduceringsfasen.
RecordHeader kommunikerer med InputSplit og konverterer dataene til nøgleværdi-par, så mapperen kan læse passende.
Partitioneren er ansvarlig for at bestemme antallet af reducerede opgaver, der kræves for at opsummere data og bekræfte, hvordan combiner-output sendes til reducer. Partitioneren styrer også nøglepartitionering af de mellemliggende kortudgange.
Nævn forskellige leverandørspecifikke distributioner af Hadoop.
Svar: De forskellige leverandører, der udvider Hadoop-funktionerne, omfatter:
- IBM Open platform.
- Cloudera CDH Hadoop Distribution
- MapR Hadoop Distribution
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- Microsoft Azures HDInsight – Cloud-baseret Hadoop-distribution.
Hvorfor er HDFS fejltolerant?
Svar: HDFS replikerer data på forskellige DataNodes, hvilket gør det fejltolerant. Lagring af data i forskellige noder tillader hentning fra andre noder, når en tilstand går ned.
Skel mellem en føderation og høj tilgængelighed.
Svar: HDFS Federation tilbyder fejltolerance, der tillader kontinuerlig dataflow i én node, når en anden går ned. På den anden side vil høj tilgængelighed kræve, at to separate maskiner konfigurerer den aktive NameNode og den sekundære NameNode på den første og anden maskine separat.
Federation kan have et ubegrænset antal urelaterede navnenoder, mens der i høj tilgængelighed kun er to relaterede navnenoder, aktive og standby, som arbejder kontinuerligt, tilgængelige.
NameNodes i føderationen deler en metadatapulje, hvor hver NameNode har sin dedikerede pulje. I High Availability kører de aktive NameNodes dog hver enkelt ad gangen, mens standby NameNodes forbliver inaktive og kun opdaterer deres metadata lejlighedsvis.
Hvordan finder man status for blokke og filsystemtilstand?
Svar: Du bruger kommandoen hdfs fsck / på både rodbrugerniveau og en individuel mappe til at kontrollere HDFS-filsystemets sundhedsstatus.
HDFS fsck kommando i brug:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Kommandoens beskrivelse:
- -filer: Udskriv de filer, du tjekker.
- –placeringer: Udskriver alle blokkes placeringer under kontrol.
Kommando til at kontrollere status for blokkene:
hdfs fsck <path> -files -blocks
: Begynder kontrollerne fra stien, der passeres her. - – blokke: Den udskriver filblokkene under kontrol
Hvornår bruger du kommandoerne rmadmin-refreshNodes og dfsadmin-refreshNodes?
Svar: Disse to kommandoer er nyttige til at opdatere nodeinformation enten under idriftsættelse eller når node idriftsættelse er færdig.
Kommandoen dfsadmin-refreshNodes kører HDFS-klienten og opdaterer NameNodes nodekonfiguration. Kommandoen rmadmin-refreshNodes udfører på den anden side ResourceManagerens administrative opgaver.
Hvad er et kontrolpunkt?
Svar: Checkpoint er en operation, der fusionerer filsystemets sidste ændringer med det seneste FSImage, så redigeringslogfilerne forbliver små nok til at fremskynde processen med at starte en NameNode. Checkpoint forekommer i den sekundære navnenod.
Hvorfor bruger vi HDFS til applikationer med store datasæt?
Svar: HDFS giver en DataNode- og NameNode-arkitektur, som implementerer et distribueret filsystem.
Disse to arkitekturer giver højtydende adgang til data over meget skalerbare klynger af Hadoop. Dens NameNode gemmer filsystemets metadata i RAM, hvilket resulterer i, at mængden af hukommelse begrænser antallet af HDFS-filsystemfiler.
Hvad gør ‘jps’-kommandoen?
Svar: Kommandoen Java Virtual Machine Process Status (JPS) kontrollerer, om specifikke Hadoop-dæmoner, inklusive NodeManager, DataNode, NameNode og ResourceManager, kører eller ej. Denne kommando er påkrævet for at køre fra roden for at kontrollere driftsnoder i værten.
Hvad er ‘Spekulativ henrettelse’ i Hadoop?
Svar: Dette er en proces, hvor masterknuden i Hadoop, i stedet for at rette opdagede langsomme opgaver, starter en anden forekomst af den samme opgave som en backup-opgave (spekulativ opgave) på en anden node. Spekulativ udførelse sparer en masse tid, især i et miljø med intensiv arbejdsbelastning.
Nævn de tre tilstande, som Hadoop kan køre i.
Svar: De tre primære noder, som Hadoop kører på, inkluderer:
- Standalone Node er standardtilstanden, der kører Hadoop-tjenesterne ved hjælp af det lokale filsystem og en enkelt Java-proces.
- Pseudo-distribueret Node udfører alle Hadoop-tjenester ved hjælp af en enkelt ode Hadoop-implementering.
- Fuldt distribueret Node kører Hadoop master- og slavetjenester ved hjælp af separate noder.
Hvad er en UDF?
Svar: UDF (User Defined Functions) lader dig kode dine brugerdefinerede funktioner, som du kan bruge til at behandle kolonneværdier under en Impala-forespørgsel.
Hvad er DistCp?
Svar: DistCp eller Distributed Copy, kort fortalt, er et nyttigt værktøj til stor inter- eller intra-cluster-kopiering af data. Ved hjælp af MapReduce implementerer DistCp effektivt den distribuerede kopi af en stor mængde data, blandt andre opgaver som fejlhåndtering, gendannelse og rapportering.
Svar: Hive metastore er en tjeneste, der gemmer Apache Hive-metadata for Hive-tabellerne i en relationel database som MySQL. Det giver metastore service API, der giver cent adgang til metadataene.
Definer RDD.
Svar: RDD, som står for Resilient Distributed Datasets, er Sparks datastruktur og en uforanderlig distribueret samling af dine dataelementer, der beregner på de forskellige klynge noder.
Hvordan kan indfødte biblioteker inkluderes i YARN-job?
Svar: Du kan implementere dette ved enten at bruge -Djava.library. stimulighed på kommandoen eller ved at indstille LD+LIBRARY_PATH i .bashrc-filen ved at bruge følgende format:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Forklar ‘WAL’ i HBase.
Svar: Write Ahead Log (WAL) er en gendannelsesprotokol, der registrerer MemStore-dataændringer i HBase til det filbaserede lager. WAL gendanner disse data, hvis RegionalServeren går ned, eller før MemStore tømmes.
Er GARN en erstatning for Hadoop MapReduce?
Svar: Nej, YARN er ikke en Hadoop MapReduce-erstatning. I stedet understøtter en kraftfuld teknologi kaldet Hadoop 2.0 eller MapReduce 2 MapReduce.
Hvad er forskellen mellem ORDER BY og SORT BY i HIVE?
Svar: Mens begge kommandoer henter data på en sorteret måde i Hive, kan resultater fra brug af SORT BY kun være delvist sorteret.
Derudover kræver SORT BY en reducering for at bestille rækkerne. Disse reducerere, der kræves til det endelige output, kan også være flere. I dette tilfælde kan det endelige output være delvist bestilt.
På den anden side kræver ORDER BY kun én reducer for en samlet ordre i output. Du kan også bruge søgeordet LIMIT, der reducerer den samlede sorteringstid.
Hvad er forskellen mellem Spark og Hadoop?
Svar: Mens både Hadoop og Spark er distribuerede behandlingsrammer, er deres vigtigste forskel deres behandling. Hvor Hadoop er effektiv til batchbehandling, er Spark effektiv til databehandling i realtid.
Derudover læser og skriver Hadoop hovedsageligt filer til HDFS, mens Spark bruger Resilient Distributed Dataset-konceptet til at behandle data i RAM.
Baseret på deres latency er Hadoop en høj-latency computing framework uden en interaktiv tilstand til at behandle data, mens Spark er en low-latency computing framework, der behandler data interaktivt.
Sammenlign Sqoop og Flume.
Svar: Sqoop og Flume er Hadoop-værktøjer, der samler data indsamlet fra forskellige kilder og indlæser dataene i HDFS.
- Sqoop(SQL-to-Hadoop) udtrækker strukturerede data fra databaser, herunder Teradata, MySQL, Oracle osv., mens Flume er nyttig til at udtrække ustrukturerede data fra databasekilder og indlæse dem i HDFS.
- Med hensyn til drevne begivenheder er Flume begivenhedsdrevet, mens Sqoop ikke er drevet af begivenheder.
- Sqoop bruger en connector-baseret arkitektur, hvor connectors ved, hvordan de forbinder til en anden datakilde. Flume bruger en agent-baseret arkitektur, hvor koden skrevet er den agent, der er ansvarlig for at hente dataene.
- På grund af Flumes distribuerede natur kan den nemt indsamle og aggregere data. Sqoop er nyttig til parallel dataoverførsel, hvilket resulterer i, at outputtet er i flere filer.
Forklar BloomMapFile.
Svar: BloomMapFile er en klasse, der udvider MapFile-klassen og bruger dynamiske bloom-filtre, der giver en hurtig medlemskabstest for nøgler.
Liste over forskellen mellem HiveQL og PigLatin.
Svar: Mens HiveQL er et deklarativt sprog, der ligner SQL, er PigLatin et proceduremæssigt dataflowsprog på højt niveau.
Hvad er datarensning?
Svar: Datarensning er en afgørende proces til at slippe af med eller rette identificerede datafejl, som omfatter ukorrekte, ufuldstændige, korrupte, duplikerede og forkert formaterede data i et datasæt.
Denne proces har til formål at forbedre kvaliteten af data og give mere nøjagtige, konsistente og pålidelige oplysninger, der er nødvendige for effektiv beslutningstagning i en organisation.
Konklusion💃
Med de nuværende store data- og Hadoop-jobmuligheder vil du måske gerne forbedre dine chancer for at komme ind. Denne artikels Hadoop-interviewspørgsmål og -svar vil hjælpe dig med at klare det kommende interview.
Dernæst kan du tjekke gode ressourcer til at lære Big Data og Hadoop.
Held og lykke! 👍