
Forestil dig, at du har en stor infrastruktur af forskellige slags enheder, som du skal regelmæssigt vedligeholde eller sikre, at de ikke er farlige for det omgivende miljø.
En måde at opnå dette på er ved regelmæssigt at sende folk til hvert sted for at tjekke, om alt er i orden. Dette er på en eller anden måde muligt, men det er også ret dyrt for tid og ressourcer. Og hvis infrastrukturen er stor nok, kan du måske ikke dække den hele inden for et år.
En anden måde er at automatisere denne proces og lade opgaverne i skyen verificere for dig. For at det kan ske, skal du gøre følgende:
👉 En hurtig proces til, hvordan man får billeder af enhederne. Dette kan stadig gøres af personer, da det stadig er meget hurtigere at lave bare et billede som at udføre alle enhedsbekræftelsesprocesser. Det kan også gøres ved at tage billeder fra biler eller endda droner, i hvilket tilfælde det bliver en meget hurtigere og mere automatiseret billedindsamlingsproces.
👉 Så skal du sende alle de opnåede billeder til ét dedikeret sted i skyen.
👉 I skyen har du brug for et automatiseret job for at samle billederne op og behandle dem gennem maskinlæringsmodeller, der er trænet til at genkende enhedsskader eller anomalier.
👉 Endelig skal resultaterne være synlige for påkrævede brugere, så reparation kan planlægges for enheder med problemer.
Lad os se på, hvordan vi kan opnå anomalidetektion fra billederne i AWS-skyen. Amazon har et par præbyggede maskinlæringsmodeller, som vi kan bruge til det formål.
Indholdsfortegnelse
Sådan opretter du en model til påvisning af visuel anomali
For at oprette en model til påvisning af visuel anomali skal du følge flere trin:
Trin 1: Definer klart det problem, du vil løse, og de typer af anomalier, du vil opdage. Dette vil hjælpe dig med at bestemme det passende testdatasæt, som du skal bruge for at træne modellen.
Trin 2: Indsaml et stort datasæt af billeder, der repræsenterer normale og unormale forhold. Mærk billederne for at angive, hvilke der er normale, og hvilke der indeholder anomalier.
Trin 3: Vælg en modelarkitektur, der passer til opgaven. Dette kan indebære, at du vælger en fortrænet model og finjusterer den til din specifikke brug eller laver en tilpasset model fra bunden.
Trin 4: Træn modellen ved hjælp af det forberedte datasæt og den valgte algoritme. Dette betyder at bruge overførselslæring til at udnytte forudtrænede modeller eller træne modellen fra bunden ved hjælp af teknikker som f.eks. konvolutionelle neurale netværk (CNN’er).
Sådan træner du en maskinlæringsmodel
Kilde: aws.amazon.com
Processen med at træne AWS maskinlæringsmodeller til påvisning af visuel anomali involverer typisk flere vigtige trin.
#1. Saml dataene
I begyndelsen skal du indsamle og mærke et stort datasæt af billeder, der repræsenterer både normale og unormale forhold. Jo større datasættet er, jo bedre og mere præcis kan modellen trænes. Men det indebærer også meget mere tid dedikeret til træning af modellen.
Normalt vil du gerne have omkring 1000 billeder i et testsæt for at få en god start.
#2. Forbered dataene
Billeddataene skal først forbehandles, for at maskinlæringsmodellerne kan opfange dem. Forbehandling kan betyde forskellige ting, såsom:
- Rensning af inputbillederne i separate undermapper, korrigering af metadata osv.
- Ændre størrelsen på billederne, så de opfylder modellens opløsningskrav.
- Fordeling af dem i mindre bidder af billeder for mere effektiv og parallel behandling.
#3. Vælg model
Vælg nu den rigtige model til at udføre det rigtige arbejde. Vælg enten en præ-trænet model, eller du kan oprette en brugerdefineret model, der er egnet til den visuelle anomali-detektering på modellen.
#4. Evaluer resultaterne
Når modellen behandler dit datasæt, skal du validere dets ydeevne. Du ønsker også at kontrollere, om resultaterne er tilfredsstillende i forhold til behovene. Det kan for eksempel betyde, at resultaterne er korrekte på mere end 99 % af inputdataene.
#5. Implementer modellen
Hvis du er tilfreds med resultaterne og ydeevnen, skal du implementere modellen med en specifik version i AWS-kontomiljøet, så processerne og tjenesterne kan begynde at bruge den.
#6. Overvåg og forbedre
Lad den køre gennem forskellige testjob og billeddatasæt, og vurder konstant, om de nødvendige parametre for detekteringskorrekthed stadig er på plads.
Hvis ikke, genoptræne modellen ved at inkludere de nye datasæt, hvor modellen leverede de forkerte resultater.
AWS Machine Learning modeller
Se nu på nogle konkrete modeller, du kan udnytte i Amazon-skyen.
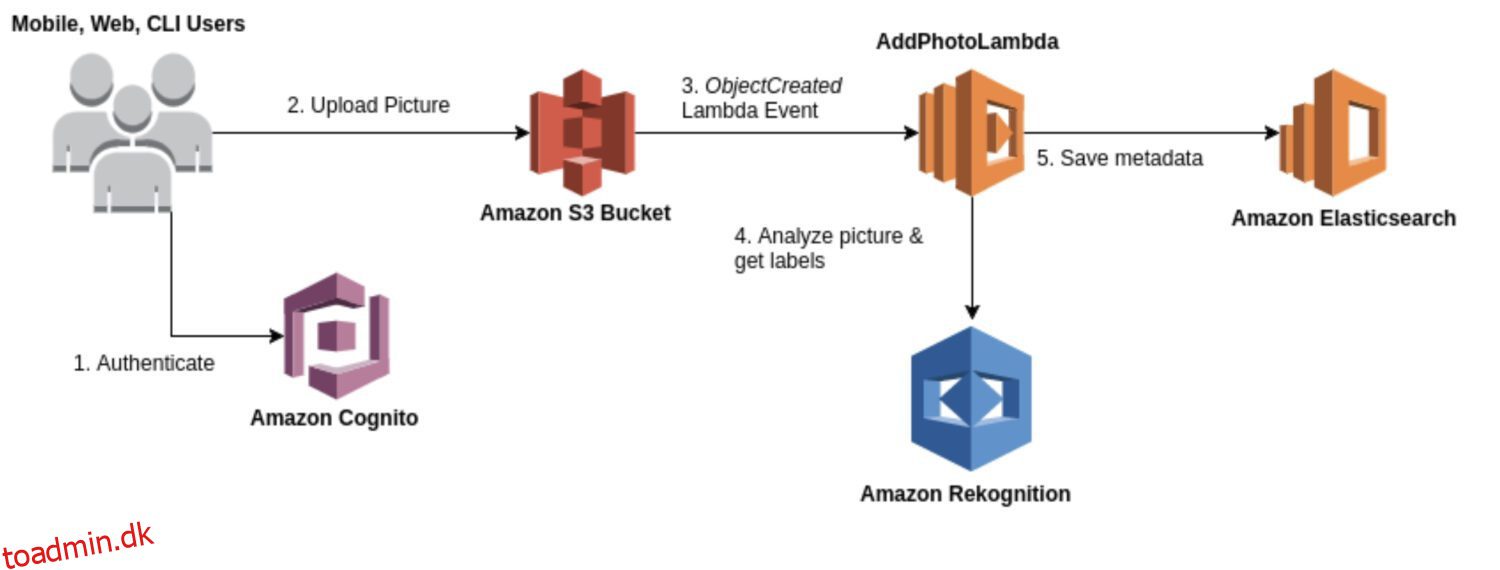
AWS-anerkendelse
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Genkendelse er en generel billed- og videoanalysetjeneste, der kan bruges til forskellige brugssager, såsom ansigtsgenkendelse, objektgenkendelse og tekstgenkendelse. Det meste af tiden vil du bruge genkendelsesmodellen til en indledende rågenerering af detektionsresultater for at danne en datasø af identificerede anomalier.
Det giver en række præbyggede modeller, du kan bruge uden træning. Rekognition leverer også realtidsanalyse af billeder og videoer med høj nøjagtighed og lav latenstid.
Her er nogle typiske tilfælde, hvor genkendelse er et godt valg til afsløring af anomalier:
- Har en generel use case til registrering af uregelmæssigheder, f.eks. at opdage uregelmæssigheder i billeder eller videoer.
- Udfør anomalidetektion i realtid.
- Integrer din anomalidetektionsmodel med AWS-tjenester som Amazon S3, Amazon Kinesis eller AWS Lambda.
Og her er nogle konkrete eksempler på anomalier, du kan opdage ved hjælp af genkendelse:
- Anomalier i ansigter, såsom opdagelse af ansigtsudtryk eller følelser uden for normalområdet.
- Manglende eller malplacerede objekter i en scene.
- Fejlstavede ord eller usædvanlige tekstmønstre.
- Usædvanlige lysforhold eller uventede genstande i en scene.
- Upassende eller stødende indhold i billeder eller videoer.
- Pludselige ændringer i bevægelse eller uventede bevægelsesmønstre.
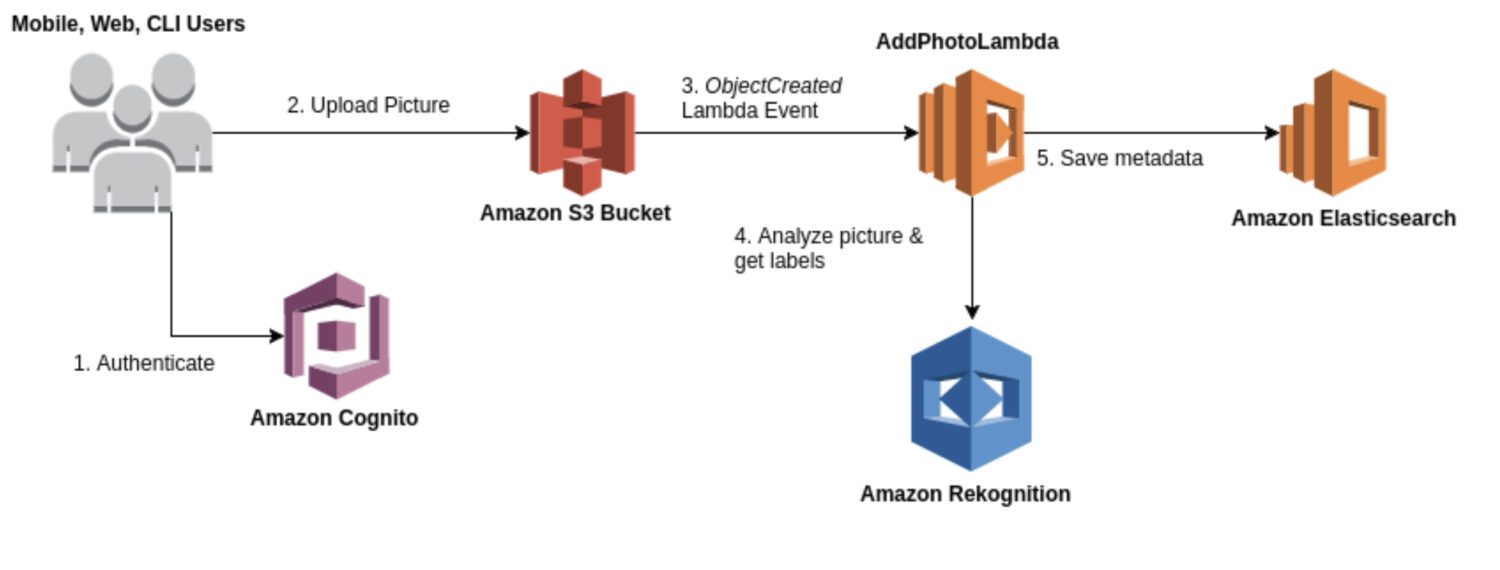
AWS Lookout for Vision
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Lookout for Vision er en model, der er specielt designet til anomalidetektion i industrielle processer, såsom fremstillings- og produktionslinjer. Det kræver typisk en tilpasset kodeforbehandling og efterbehandling af et billede eller en konkret udskæring af billedet, normalt udført ved hjælp af et Python-programmeringssprog. Det meste af tiden har den specialiseret sig i nogle helt særlige problemer på billedet.
Det kræver brugerdefineret træning på et datasæt af normale og unormale billeder for at skabe en brugerdefineret model til registrering af anomalier. Det er ikke så realtidsfokuseret; snarere er den designet til batchbehandling af billeder med fokus på nøjagtighed og præcision.
Her er nogle typiske brugstilfælde, hvor Lookout for Vision er et godt valg, hvis du har brug for at opdage:
- Defekter i fremstillede produkter eller identifikation af udstyrsfejl i en produktionslinje.
- Et stort datasæt af billeder eller andre data.
- Anomali i realtid i en industriel proces.
- Anomali integreret med andre AWS-tjenester, såsom Amazon S3 eller AWS IoT.
Og her er nogle konkrete eksempler på anomalier, som du kan opdage ved hjælp af Lookout for Vision:
- Defekter i fremstillede produkter, såsom ridser, buler eller andre ufuldkommenheder, kan påvirke produktets kvalitet.
- Udstyrsfejl i en produktionslinje, såsom opdagelse af ødelagte eller defekte maskiner, der kan forårsage forsinkelser eller sikkerhedsrisici.
- Kvalitetskontrolproblemer i en produktionslinje omfatter detektering af produkter, der ikke opfylder de påkrævede specifikationer eller tolerancer.
- Sikkerhedsrisici i en produktionslinje omfatter opdagelse af genstande eller materialer, der kan udgøre en risiko for arbejdere eller udstyr.
- Anomalier i en produktionsproces, såsom at opdage uventede ændringer i strømmen af materialer eller produkter gennem produktionslinjen.
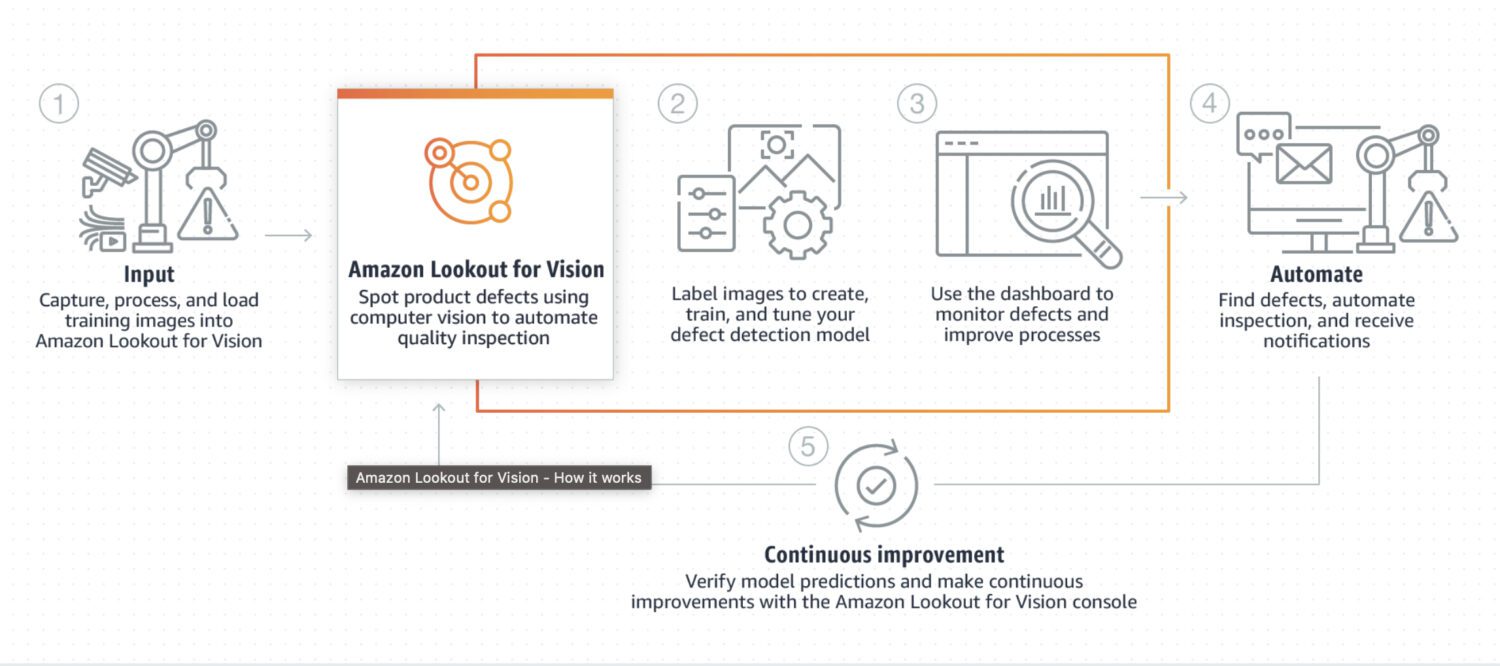
AWS Sagemaker
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Sagemaker er en fuldt administreret platform til at bygge, træne og implementere tilpassede maskinlæringsmodeller.
Det er en meget mere robust løsning. Faktisk giver det en måde at forbinde og udføre flere flertrinsprocesser i én kæde af job, der følger efter hinanden, ligesom AWS Step Functions kan gøre.
Men da Sagemaker bruger ad-hoc EC2-instanser til sin behandling, er der ingen grænse på 15 minutter for enkeltjob-behandling, som i tilfældet med AWS lambda-funktioner i AWS Step Functions.
Du kan også lave automatisk modeltuning med Sagemaker, hvilket bestemt er en funktion, der gør den til en iøjnefaldende mulighed. Endelig kan Sagemaker ubesværet implementere modellen i et produktionsmiljø.
Her er nogle typiske tilfælde, hvor SageMaker er et godt valg til afsløring af anomalier:
- En specifik use case, der ikke er dækket af præbyggede modeller eller API’er, og hvis du skal bygge en skræddersyet model til dine specifikke behov.
- Hvis du har et stort datasæt af billeder eller andre data. Forudbyggede modeller kræver en vis forbehandling i sådanne tilfælde, men Sagemaker kan klare det uden.
- Hvis du har brug for at udføre uregelmæssig registrering i realtid.
- Hvis du har brug for at integrere din model med andre AWS-tjenester, såsom Amazon S3, Amazon Kinesis eller AWS Lambda.
Og her er nogle typiske anomalidetektioner, som Sagemaker er i stand til at udføre:
- Opdagelse af svindel i finansielle transaktioner, for eksempel usædvanlige forbrugsmønstre eller transaktioner uden for det normale interval.
- Cybersikkerhed i netværkstrafik, som usædvanlige mønstre for dataoverførsel eller uventede forbindelser til eksterne servere.
- Medicinsk diagnose i medicinske billeder, såsom påvisning af tumorer.
- Uregelmæssigheder i udstyrets ydeevne, såsom registrering af ændringer i vibrationer eller temperatur.
- Kvalitetskontrol i fremstillingsprocesser, såsom at opdage fejl i produkter eller identificere afvigelser fra de forventede kvalitetsstandarder.
- Usædvanlige mønstre for energiforbrug.
Sådan inkorporeres modellerne i serverløs arkitektur
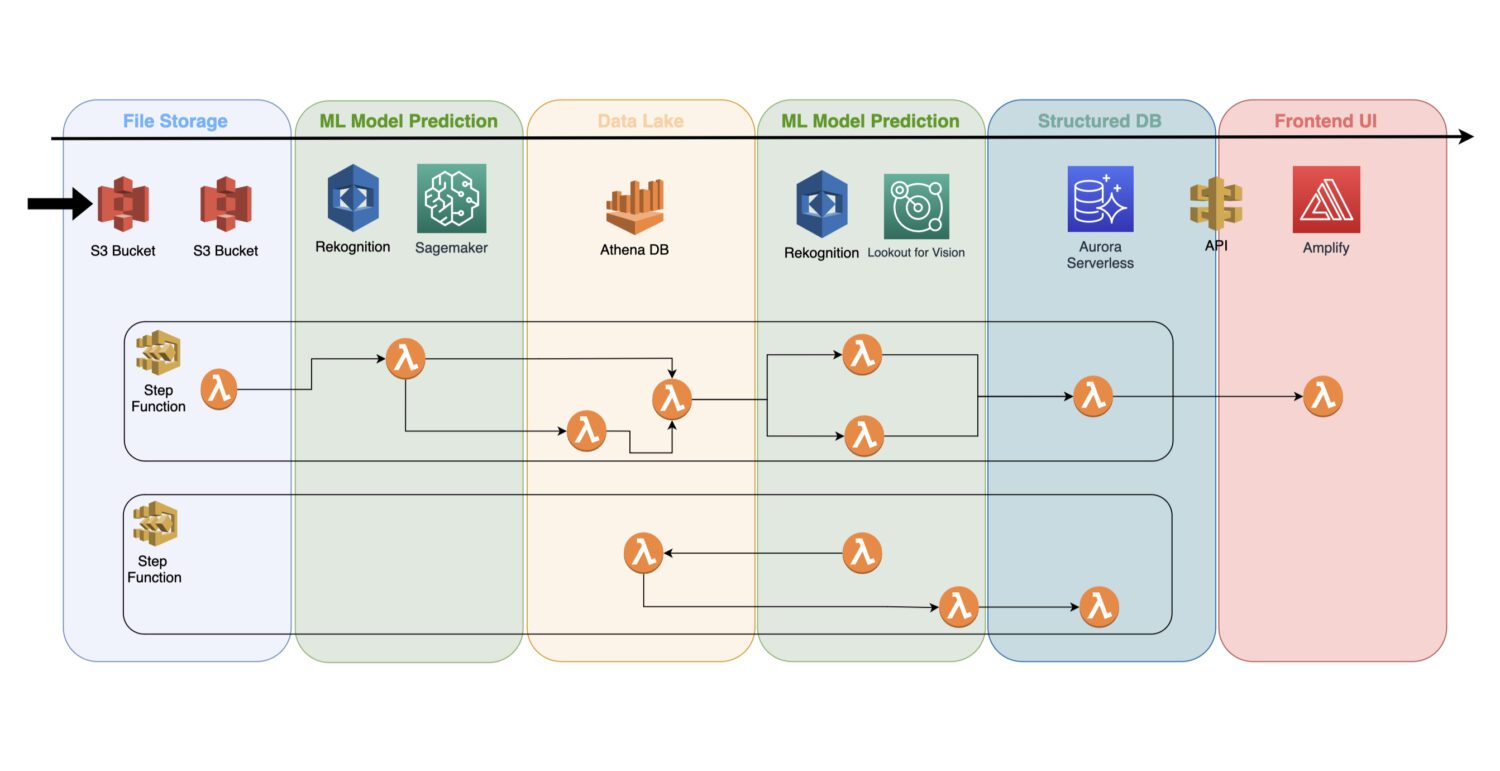
En trænet maskinlæringsmodel er en cloud-tjeneste, der ikke bruger nogen klyngeservere i baggrunden; det kan således nemt inkluderes i en eksisterende serverløs arkitektur.
Automatisering sker via AWS lambda-funktioner, forbundet til et job med flere trin i en AWS Step Functions-tjeneste.
Typisk har du brug for indledende opdagelse lige efter at have indsamlet billederne og deres forbehandling på S3-bøtten. Det er her, du vil generere atomare anomali-detektion på inputbillederne og gemme resultaterne i en datasø, for eksempel repræsenteret af Athena-databasen.
I nogle tilfælde er denne indledende detektion ikke nok til din konkrete brugssag. Du har muligvis brug for en anden, mere detaljeret registrering. For eksempel kan den indledende (f.eks. Genkendelse) model registrere et eller andet problem på enheden, men det er ikke muligt pålideligt at identificere, hvilken slags problem det er.
Til det har du måske brug for en anden model med andre muligheder. I et sådant tilfælde kan du køre den anden model (f.eks. Lookout for Vision) på den delmængde af billeder, hvor den oprindelige model identificerede problemet.
Dette er også en god måde at spare nogle omkostninger på, da du ikke behøver at køre den anden model på et helt sæt billeder. I stedet kører du det kun på den meningsfulde delmængde.
AWS Lambda-funktioner vil dække al sådan behandling ved hjælp af Python- eller Javascript-kode indeni. Det er kun op til karakteren af processerne og hvor mange AWS lambda-funktioner du skal inkludere i et flow. 15-minutters grænsen for den maksimale varighed af et AWS lambda-opkald vil bestemme, hvor mange trin en sådan proces skal indeholde.
Afsluttende ord
At arbejde med cloud machine learning-modeller er et meget interessant job. Hvis du ser på det fra et perspektiv af færdigheder og teknologier, vil du finde ud af, at du skal have et team med en lang række kompetencer.
Teamet skal forstå, hvordan man træner en model, hvad enten den er færdigbygget eller skabt fra bunden. Det betyder, at en masse matematik eller algebra er involveret i at balancere resultaternes pålidelighed og ydeevne.
Du har også brug for nogle avancerede Python- eller Javascript-kodningsfærdigheder, database- og SQL-færdigheder. Og når alt indholdsarbejdet er udført, har du brug for DevOps-færdigheder for at tilslutte det til en pipeline, der vil gøre det til et automatiseret job, der er klar til implementering og udførelse.
At definere anomalien og træne modellen er én ting. Men det er en udfordring at integrere det hele i ét funktionelt team, der kan behandle resultaterne af modellerne og gemme dataene på en effektiv og automatiseret måde for at betjene dem til slutbrugerne.
Tjek derefter alt om ansigtsgenkendelse for virksomheder.