
Når man ser virksomhedens softwareudvikling fra første række i to årtier, er den ubestridelige tendens fra de sidste par år klar – at flytte databaser ind i skyen.
Jeg var allerede involveret i et par migreringsprojekter, hvor målet var at bringe den eksisterende on-premise database ind i Amazon Web Services (AWS) Cloud-databasen. Mens du fra AWS-dokumentationsmaterialerne vil lære, hvor nemt det kan være, er jeg her for at fortælle dig, at udførelsen af en sådan plan ikke altid er nem, og der er tilfælde, hvor den kan mislykkes.
I dette indlæg vil jeg dække oplevelsen i den virkelige verden for følgende tilfælde:
- Kilden: Selvom det i teorien er ligegyldigt, hvad din kilde er (du kan bruge en meget lignende tilgang til de fleste af de mest populære DB’er), var Oracle det foretrukne databasesystem i store virksomheder i mange år, og det er der mit fokus vil være.
- Målet: Ingen grund til at være specifik på denne side. Du kan vælge en hvilken som helst måldatabase i AWS, og tilgangen vil stadig passe.
- Tilstanden: Du kan have en fuld opdatering eller trinvis opdatering. En batch-dataindlæsning (kilde- og måltilstande er forsinket) eller (næsten) dataindlæsning i realtid. Begge vil blive berørt her.
- Hyppigheden: Du ønsker måske engangsmigrering efterfulgt af en fuld skift til skyen eller kræver en overgangsperiode og at have dataene opdateret på begge sider samtidigt, hvilket indebærer udvikling af daglig synkronisering mellem on-premise og AWS. Førstnævnte er enklere og giver langt mere mening, men sidstnævnte er oftere efterspurgt og har langt flere brudpunkter. Jeg vil dække begge dele her.
Indholdsfortegnelse
Problem Beskrivelse
Kravet er ofte simpelt:
Vi ønsker at begynde at udvikle tjenester inde i AWS, så kopier venligst alle vores data ind i “ABC”-databasen. Hurtigt og enkelt. Vi skal bruge dataene i AWS nu. Senere vil vi finde ud af, hvilke dele af DB-design, der skal ændres for at matche vores aktiviteter.
Inden du går videre, er der noget at overveje:
- Spring ikke for hurtigt ind i tanken om “bare kopiere, hvad vi har og håndtere det senere”. Jeg mener, ja, dette er det nemmeste du kan gøre, og det vil blive gjort hurtigt, men dette har potentialet til at skabe et så grundlæggende arkitektonisk problem, som vil være umuligt at løse senere uden seriøs omstrukturering af størstedelen af den nye cloud-platform . Forestil dig blot, at skyens økosystem er helt anderledes end det lokale. Flere nye tjenester vil blive introduceret over tid. Naturligvis vil folk begynde at bruge det samme meget forskelligt. Det er næsten aldrig en god idé at kopiere den lokale tilstand i skyen på en 1:1 måde. Det kan være i dit særlige tilfælde, men sørg for at dobbelttjekke dette.
- Sæt spørgsmålstegn ved kravet med nogle meningsfulde tvivl som:
- Hvem vil være den typiske bruger, der bruger den nye platform? Mens det er on-premise, kan det være en transaktionsbaseret virksomhedsbruger; i skyen kan det være en dataforsker eller datavarehusanalytiker, eller dataens hovedbruger kan være en tjeneste (f.eks. Databricks, Glue, maskinlæringsmodeller osv.).
- Forventes de almindelige daglige job at forblive, selv efter overgangen til skyen? Hvis ikke, hvordan forventes de at ændre sig?
- Planlægger du en væsentlig vækst af data over tid? Sandsynligvis er svaret ja, da det ofte er den vigtigste enkelt grund til at migrere ind i skyen. En ny datamodel skal være klar til det.
- Forvent, at slutbrugeren tænker over nogle generelle, forventede forespørgsler, den nye database vil modtage fra brugerne. Dette vil definere, hvor meget den eksisterende datamodel skal ændres for at forblive præstationsrelevant.
Opsætning af migreringen
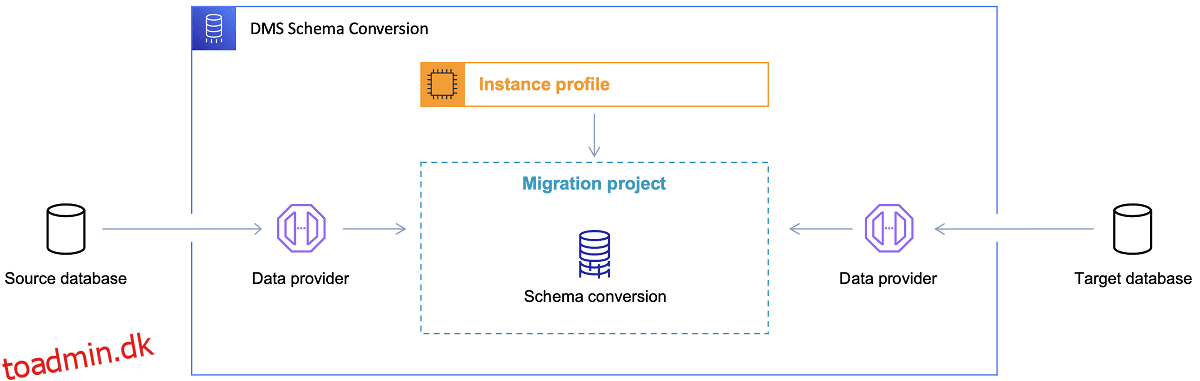
Når først måldatabasen er valgt, og datamodellen er tilfredsstillende diskuteret, er næste skridt at blive fortrolig med AWS Schema Conversion Tool. Der er flere områder, hvor dette værktøj kan tjene:
 Reference: AWS-dokumentation
Reference: AWS-dokumentation
Nu er der et par tips til brug af Schema Conversion Tool.
For det første bør det næsten aldrig være tilfældet at bruge output direkte. Jeg vil betragte det mere som referenceresultater, hvorfra du skal foretage dine justeringer baseret på din forståelse og formål med dataene og den måde, hvordan dataene vil blive brugt i skyen.
For det andet blev tabellerne tidligere sandsynligvis udvalgt af brugere, der forventede hurtige korte resultater om en konkret datadomæneentitet. Men nu kan dataene vælges til analytiske formål. For eksempel vil databaseindekser, der tidligere arbejdede i den lokale database, nu være ubrugelige og absolut ikke forbedre ydeevnen af DB-systemet relateret til denne nye brug. På samme måde vil du måske partitionere dataene anderledes på målsystemet, som det var før på kildesystemet.
Det kan også være godt at overveje at lave nogle datatransformationer under migreringsprocessen, hvilket grundlæggende betyder at ændre måldatamodellen for nogle tabeller (så de ikke længere er 1:1 kopier). Senere skal transformationsreglerne implementeres i migreringsværktøjet.
Hvis kilde- og måldatabaserne er af samme type (f.eks. Oracle on-premise vs. Oracle i AWS, PostgreSQL vs. Aurora Postgresql osv.), så er det bedst at bruge et dedikeret migreringsværktøj, som konkret database understøtter indbygget ( f.eks. eksport og import af datapumper, Oracle Goldengate osv.).
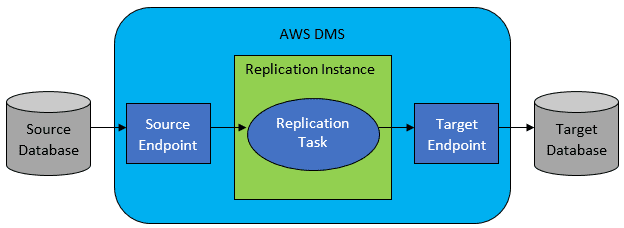
I de fleste tilfælde vil kilde- og måldatabasen dog ikke være kompatible, og så vil det oplagte værktøj være AWS Database Migration Service.
 Reference: AWS-dokumentation
Reference: AWS-dokumentation
AWS DMS tillader grundlæggende at konfigurere en liste over opgaver på tabelniveau, som vil definere:
- Hvad er den nøjagtige kilde-DB og tabel, der skal oprettes forbindelse til?
- Udsagnsspecifikationer, der vil blive brugt til at indhente data for måltabellen.
- Transformationsværktøjer (hvis nogen), der definerer, hvordan kildedataene skal kortlægges i måltabeldata (hvis ikke 1:1).
- Hvad er den nøjagtige måldatabase og tabel, som dataene skal indlæses i?
Konfigurationen af DMS-opgaver udføres i et brugervenligt format som JSON.
Nu i det enkleste scenarie er alt hvad du skal gøre at køre implementeringsscripts på måldatabasen og starte DMS-opgaven. Men der er langt mere til det.
Engangs fuld datamigrering

Det nemmeste tilfælde at udføre er, når anmodningen er at flytte hele databasen én gang ind i målskydatabasen. Så dybest set vil alt, hvad der er nødvendigt at gøre, se ud som følgende:
Hvis konfigurationen af DMS er udført godt, vil der ikke ske noget dårligt i dette scenarie. Hver enkelt kildetabel vil blive samlet op og kopieret over i AWS-måldatabasen. De eneste bekymringer vil være udførelsen af aktiviteten og sikre, at dimensioneringen er rigtig i hvert trin, så den ikke fejler på grund af utilstrækkelig lagerplads.
Inkrementel daglig synkronisering

Det er her, tingene begynder at blive komplicerede. Jeg mener, hvis verden ville være ideel, så ville den nok fungere fint hele tiden. Men verden er aldrig ideel.
DMS kan konfigureres til at fungere i to tilstande:
- Fuld belastning – standardtilstand beskrevet og brugt ovenfor. DMS-opgaverne startes enten, når du starter dem, eller når de er planlagt til at starte. Når du er færdig, er DMS-opgaverne udført.
- Skift datafangst (CDC) – i denne tilstand kører DMS-opgaven kontinuerligt. DMS scanner kildedatabasen for en ændring på tabelniveau. Hvis ændringen sker, forsøger den straks at replikere ændringen i måldatabasen baseret på konfigurationen inde i DMS-opgaven relateret til den ændrede tabel.
Når du går efter CDC, skal du træffe endnu et valg – nemlig hvordan CDC vil udtrække deltaændringerne fra kilde-DB.
#1. Oracle Redo Logs Reader
En mulighed er at vælge indbygget database-redo-log-læser fra Oracle, som CDC kan bruge til at få de ændrede data, og, baseret på de seneste ændringer, replikere de samme ændringer på måldatabasen.
Selvom dette kan se ud som et oplagt valg, hvis man beskæftiger sig med Oracle som kilde, er der en hak: Oracle redo logs-læser bruger kilde-Oracle-klyngen og påvirker derfor direkte alle de andre aktiviteter, der kører i databasen (den opretter faktisk direkte aktive sessioner i databasen).
Jo flere DMS-opgaver du har konfigureret (eller jo flere DMS-klynger parallelt), jo mere vil du sandsynligvis have brug for at opstørre Oracle-klyngen – dybest set skal du justere den vertikale skalering af din primære Oracle-databaseklynge. Dette vil helt sikkert have indflydelse på de samlede omkostninger ved løsningen, i endnu højere grad, hvis den daglige synkronisering er ved at blive ved med at være i projektet i en længere periode.
#2. AWS DMS Log Miner
I modsætning til indstillingen ovenfor er dette en indbygget AWS-løsning på det samme problem. I dette tilfælde påvirker DMS ikke kilden til Oracle DB. I stedet kopierer den Oracle-redo-logfilerne ind i DMS-klyngen og udfører al behandlingen der. Selvom det sparer Oracle-ressourcer, er det den langsommere løsning, da flere operationer er involveret. Og også, som man nemt kan antage, er den tilpassede læser til Oracle-redo-logs sandsynligvis langsommere i sit job som den indfødte læser fra Oracle.
Afhængigt af størrelsen af kildedatabasen og antallet af daglige ændringer der, kan du i bedste tilfælde ende med næsten realtids trinvis synkronisering af dataene fra den lokale Oracle-database til AWS-skydatabasen.
I andre scenarier vil det stadig ikke være i nærheden af synkronisering i realtid, men du kan prøve at komme så tæt som muligt på den accepterede forsinkelse (mellem kilde og mål) ved at justere kilde- og målklyngernes ydeevnekonfiguration og parallelitet eller eksperimentere med mængden af DMS-opgaver og deres fordeling mellem CDC-instanserne.
Og du vil måske lære, hvilke ændringer af kildetabel der understøttes af CDC (som f.eks. tilføjelse af en kolonne), fordi ikke alle mulige ændringer understøttes. I nogle tilfælde er den eneste måde at få måltabellen til at ændre sig manuelt og genstarte CDC-opgaven fra bunden (taber alle eksisterende data i måldatabasen undervejs).
Når tingene går galt, uanset hvad

Jeg lærte dette på den hårde måde, men der er et specifikt scenarie forbundet med DMS, hvor løftet om daglig replikering er svært at opnå.
DMS’et kan kun behandle gentag-loggene med en bestemt hastighed. Det er lige meget, om der er flere tilfælde af DMS, der udfører dine opgaver. Alligevel læser hver DMS-instans kun redo-logfilerne med en enkelt defineret hastighed, og hver enkelt af dem skal læse dem hele. Det er endda ligegyldigt, om du bruger Oracle redo logs eller AWS log miner. Begge har denne grænse.
Hvis kildedatabasen indeholder et stort antal ændringer inden for en dag, som Oracle-redo-logfilerne bliver virkelig store (som 500 GB+ store) hver eneste dag, vil CDC bare ikke fungere. Replikationen vil ikke være afsluttet før dagens udgang. Det vil bringe noget ubearbejdet arbejde til den næste dag, hvor et nyt sæt ændringer, der skal replikeres, allerede venter. Mængden af ubehandlede data vil kun vokse fra dag til dag.
I dette særlige tilfælde var CDC ikke en mulighed (efter mange præstationstests og forsøg, vi udførte). Den eneste måde, hvordan man sikrer, at i det mindste alle deltaændringer fra den aktuelle dag bliver replikeret på samme dag, var at gribe det an på denne måde:
- Adskil virkelig store borde, der ikke bruges så ofte, og repliker dem kun én gang om ugen (f.eks. i weekender).
- Konfigurer replikering af ikke-så-store-men-stadig-store tabeller til at blive opdelt mellem flere DMS-opgaver; en tabel blev til sidst migreret af 10 eller flere adskilte DMS-opgaver parallelt, hvilket sikrer, at dataopdelingen mellem DMS-opgaverne er adskilt (brugerdefineret kodning involveret her) og udføre dem dagligt.
- Tilføj flere (op til 4 i dette tilfælde) forekomster af DMS og del DMS-opgaverne jævnt mellem dem, hvilket betyder ikke kun efter antallet af tabeller, men også efter størrelsen.
Grundlæggende brugte vi fuld load-tilstanden af DMS til at replikere daglige data, fordi det var den eneste måde, hvorpå man kunne opnå mindst samme dag datareplikering.
Ikke en perfekt løsning, men den er der stadig, og selv efter mange år fungerer den stadig på samme måde. Så måske ikke så dårlig en løsning alligevel. 😃