
Lær alt, hvad du behøver at vide om undersøgende dataanalyse, en kritisk proces, der bruges til at opdage tendenser og mønstre og opsummere datasæt ved hjælp af statistiske opsummeringer og grafiske repræsentationer.
Som ethvert projekt er et datavidenskabsprojekt en lang proces, der kræver tid, god tilrettelæggelse og omhyggelig respekt for flere trin. Udforskende dataanalyse (EDA) er et af de vigtigste trin i denne proces.
Derfor vil vi i denne artikel kort se nærmere på, hvad eksplorativ dataanalyse er, og hvordan du kan udføre det med R!
Indholdsfortegnelse
Hvad er Exploratory Data Analysis?
Udforskende dataanalyse undersøger og studerer karakteristikaene for et datasæt, før det indsendes til en ansøgning, uanset om det udelukkende er forretningsmæssig, statistisk eller maskinlæring.
Denne opsummering af informationens art og dens vigtigste særegenheder er normalt lavet ved hjælp af visuelle metoder, såsom grafiske repræsentationer og tabeller. Praksis udføres på forhånd netop for at vurdere potentialet i disse data, som vil få en mere kompleks behandling i fremtiden.
EDA tillader derfor:
- Formuler hypoteser for brugen af disse oplysninger;
- Udforsk skjulte detaljer i datastrukturen;
- Identificer manglende værdier, afvigelser eller unormal adfærd;
- Opdag tendenser og relevante variabler som helhed;
- Kassér irrelevante variabler eller variabler korreleret med andre;
- Bestem den formelle modellering, der skal bruges.
Hvad er forskellen mellem beskrivende og undersøgende dataanalyse?
Der er to typer dataanalyse, deskriptiv analyse og eksplorativ dataanalyse, som går hånd i hånd, på trods af at de har forskellige mål.
Mens den første fokuserer på at beskrive adfærden af variabler, for eksempel middelværdi, median, tilstand osv.
Den eksplorative analyse har til formål at identificere sammenhænge mellem variabler, uddrage foreløbige indsigter og lede modelleringen til de mest almindelige maskinlæringsparadigmer: klassifikation, regression og klyngedannelse.
Til fælles kan begge beskæftige sig med grafisk repræsentation; dog er det kun eksplorativ analyse, der søger at bringe handlingsdygtige indsigter, det vil sige indsigter, der fremkalder handling hos beslutningstageren.
Endelig, mens eksplorativ dataanalyse søger at løse problemer og bringe løsninger, der vil guide modelleringstrinene, sigter beskrivende analyse, som navnet antyder, kun på at producere en detaljeret beskrivelse af det pågældende datasæt.
Beskrivende analyseUdforskende dataanalyse Analyserer adfærd Analyserer adfærd og forhold Giver et resumé Fører til specifikation og handlinger Organiserer data i tabeller og grafer Organiserer data i tabeller og graferHar ikke væsentlig forklaringsevneHar en betydelig forklaringsevne
Nogle praktiske anvendelsestilfælde af EDA
#1. Digital markedsføring
Digital Marketing har udviklet sig fra en kreativ proces til en datadrevet proces. Marketingorganisationer bruger undersøgende dataanalyse til at bestemme resultaterne af kampagner eller bestræbelser og til at vejlede forbrugerinvesteringer og målretningsbeslutninger.
Demografiske undersøgelser, kundesegmentering og andre teknikker giver marketingfolk mulighed for at bruge store mængder forbrugerkøb, undersøgelser og paneldata til at forstå og kommunikere strategimarkedsføring.
Web-udforskende analyser giver marketingfolk mulighed for at indsamle oplysninger på sessionsniveau om interaktioner på et websted. Google Analytics er et eksempel på et gratis og populært analyseværktøj, som marketingfolk bruger til dette formål.
Udforskende teknikker, der ofte bruges i markedsføring, omfatter modellering af marketingmix, pris- og salgsfremmende analyser, salgsoptimering og undersøgende kundeanalyse, f.eks. segmentering.
#2. Udforskende porteføljeanalyse
En almindelig anvendelse af eksplorativ dataanalyse er eksplorativ porteføljeanalyse. En bank eller et lånebureau har en samling konti af varierende værdi og risiko.
Konti kan variere afhængigt af indehaverens sociale status (rig, middelklasse, fattig osv.), geografisk placering, nettoformue og mange andre faktorer. Långiver skal balancere afkastet på lånet med risikoen for misligholdelse for hvert lån. Spørgsmålet bliver så, hvordan man værdisætter porteføljen som helhed.
Det laveste risikolån kan være til meget velhavende mennesker, men der er et meget begrænset antal velhavende mennesker. På den anden side kan mange fattige låne ud, men med større risiko.
Den udforskende dataanalyseløsning kan kombinere tidsserieanalyse med mange andre problemer for at beslutte, hvornår man skal låne penge til disse forskellige segmenter af låntagere eller udlånssatsen. Medlemmer af et porteføljesegment opkræves renter for at dække tab blandt medlemmer af dette segment.
#3. Udforskende risikoanalyse
Forudsigelsesmodeller i banksektoren er ved at blive udviklet for at give sikkerhed for risikoscore for individuelle kunder. Kreditscore er designet til at forudsige en persons kriminelle adfærd og bruges i vid udstrækning til at vurdere hver ansøgers kreditværdighed.
Derudover udføres risikoanalyser i den videnskabelige verden og forsikringsbranchen. Det er også meget udbredt i finansielle institutioner såsom online betalingsgateway-virksomheder til at analysere, om en transaktion er ægte eller svigagtig.
Til dette formål bruger de kundens transaktionshistorik. Det er mere almindeligt brugt ved kreditkortkøb; når der er en pludselig stigning i klienttransaktionsvolumen, modtager klienten et bekræftelsesopkald, hvis han påbegyndte transaktionen. Det hjælper også med at reducere tab på grund af sådanne omstændigheder.
Udforskende dataanalyse med R
Den første ting, du skal bruge for at udføre EDA med R, er at downloade R base og R Studio (IDE), efterfulgt af installation og indlæsning af følgende pakker:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
Til denne vejledning vil vi bruge et økonomidatasæt, der er indbygget med R og giver årlige økonomiske indikatordata for den amerikanske økonomi, og ændrer dets navn til econ for enkelhedens skyld:
econ <- ggplot2::economics
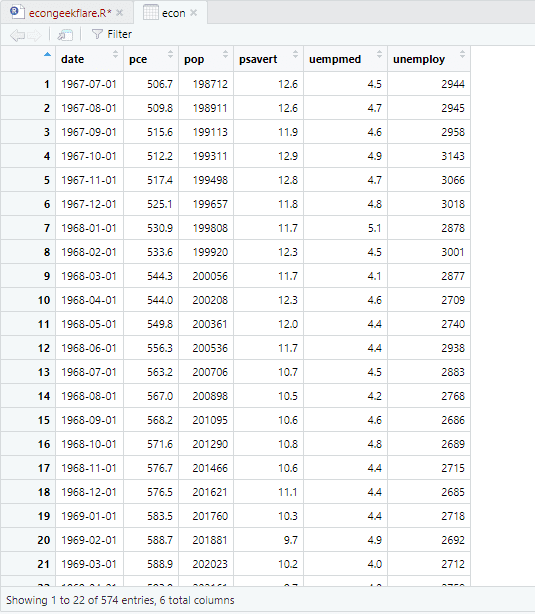
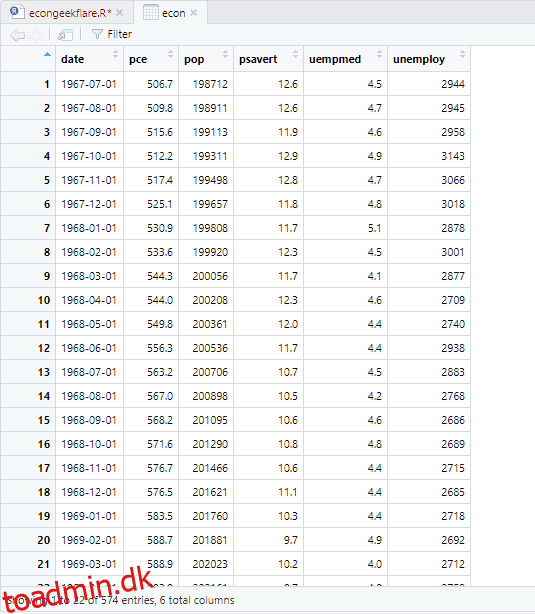
Til at udføre den beskrivende analyse vil vi bruge skimr-pakken, som beregner disse statistikker på en enkel og velpræsenteret måde:
#Descriptive Analysis skimr::skim(econ)

Du kan også bruge opsummeringsfunktionen til beskrivende analyse:
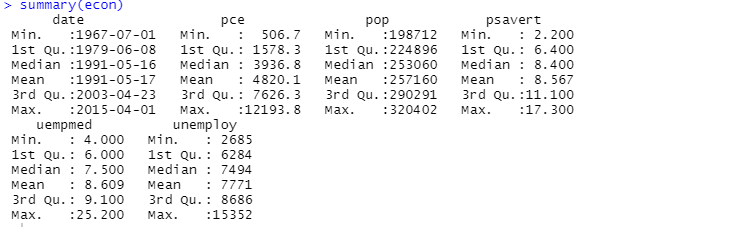
Her viser den beskrivende analyse 547 rækker og 6 kolonner i datasættet. Minimumsværdien er for 1967-07-01, og maksimumværdien er for 2015-04-01. På samme måde viser den også middelværdien og standardafvigelsen.
Nu har du en grundlæggende idé om, hvad der er inde i econ-datasættet. Lad os plotte et histogram af variablen uempmed for bedre at se på dataene:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
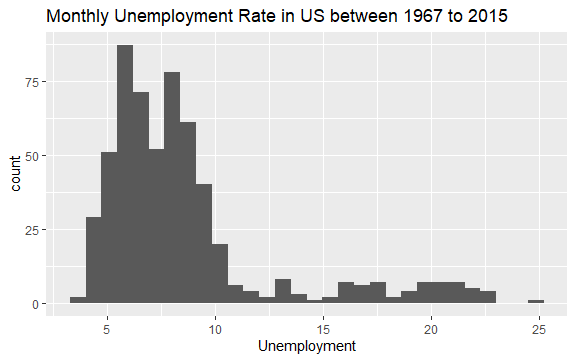
Fordelingen af histogrammet viser, at det har en aflang hale til højre; det vil sige, at der muligvis er et par observationer af denne variabel med mere “ekstreme” værdier. Spørgsmålet opstår: i hvilken periode fandt disse værdier sted, og hvad er trenden for variablen?
Den mest direkte måde at identificere trenden for en variabel på er gennem en linjegraf. Nedenfor genererer vi en linjegraf og tilføjer en udjævningslinje:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
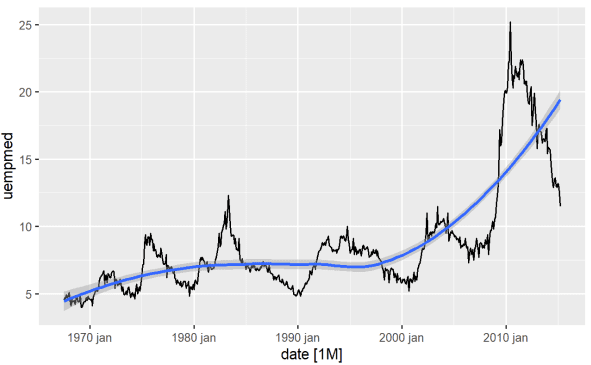
Ved hjælp af denne graf kan vi identificere, at der i den seneste periode, i de sidste observationer fra 2010, er en tendens til en stigning i arbejdsløsheden, der overgår historien observeret i tidligere årtier.
En anden vigtig pointe, især i økonometriske modelleringssammenhænge, er seriens stationaritet; det vil sige, er middelværdien og variansen konstant over tid?
Når disse antagelser ikke er sande i en variabel, siger vi, at serien har en enhedsrod (ikke-stationær), så de stød, som variablen udsættes for, genererer en permanent effekt.
Det ser ud til at have været tilfældet for den pågældende variabel, varigheden af ledigheden. Vi har set, at variablens udsving har ændret sig betydeligt, hvilket har stærke implikationer relateret til økonomiske teorier, der omhandler cyklusser. Men med afvigelse fra teorien, hvordan kontrollerer vi praktisk om variablen er stationær?
Prognosepakken har en fremragende funktion, der gør det muligt at anvende tests, såsom ADF, KPSS og andre, som allerede returnerer antallet af forskelle, der er nødvendige for, at serien er stationær:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Her viser p-værdien større end 0,05, at dataene er ikke-stationære.
Et andet vigtigt spørgsmål i tidsserier er identifikation af mulige korrelationer (det lineære forhold) mellem seriens forsinkede værdier. ACF- og PACF-korrelogrammerne hjælper med at identificere det.
Da serien ikke har sæsonbestemthed, men har en vis tendens, har de initiale autokorrelationer en tendens til at være store og positive, fordi observationerne tæt på i tid også er tæt på værdien.
Således har autokorrelationsfunktionen (ACF) i en trendtidsserie en tendens til at have positive værdier, der langsomt falder, efterhånden som forsinkelserne stiger.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
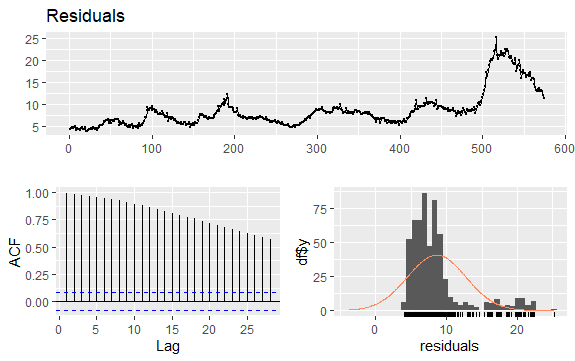
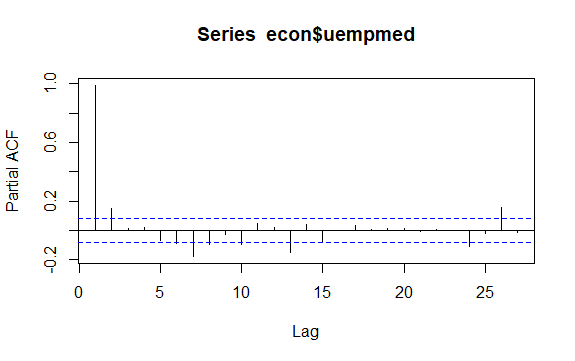
Konklusion
Når vi får fingrene i data, der er mere eller mindre rene, det vil sige allerede rensede, fristes vi straks til at dykke ned i modelkonstruktionsfasen for at tegne de første resultater. Du er nødt til at modstå denne fristelse og begynde at lave undersøgende dataanalyse, som er enkel, men alligevel hjælper os med at få kraftfuld indsigt i dataene.
Du kan også udforske nogle af de bedste ressourcer til at lære statistik for Data Science.