

Linux uniq-kommandoen pisker gennem dine tekstfiler på udkig efter unikke eller duplikerede linjer. I denne guide dækker vi dens alsidighed og funktioner, samt hvordan du kan få mest muligt ud af dette smarte værktøj.
Indholdsfortegnelse
Find matchende tekstlinjer på Linux
Den unikke kommando er hurtig, fleksibel og god til, hvad den gør. Men ligesom mange Linux-kommandoer har den et par særheder – hvilket er fint, så længe du kender til dem. Hvis du tager springet uden en smule insiderviden, kan du godt stå og klø dig i hovedet over resultaterne. Vi vil påpege disse særheder, mens vi går.
Uniq-kommandoen er perfekt til dem i den målbevidste, designet-til-at-gøre-en-ting-og-gøre-det-godt-lejren. Derfor er den også særdeles velegnet til at arbejde med pipes og spille sin rolle i kommandopipelines. En af dens hyppigste samarbejdspartnere er sortering, fordi uniq skal have sorteret input, som der skal arbejdes på.
Lad os fyre den op!
Kører uniq uden indstillinger
Vi har en tekstfil, der indeholder teksten til Robert Johnsons sang Jeg tror, jeg vil støve min kost. Lad os se, hvad der er unikt ved det.
Vi skriver følgende for at overføre output til mindre:
uniq dust-my-broom.txt | less

Vi får hele sangen, inklusive duplikerede linjer, på mindre:
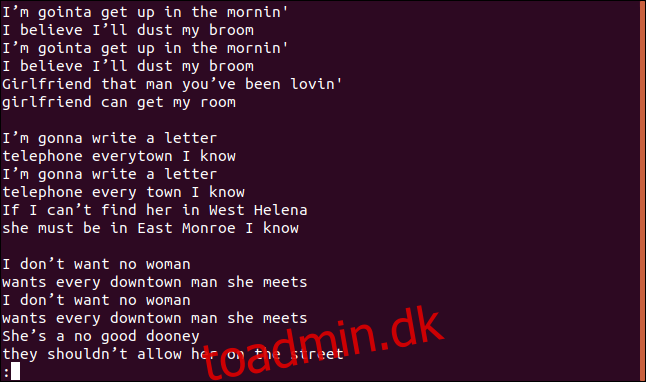
Det ser ikke ud til at være hverken de unikke linjer eller de duplikerede linjer.
Rigtigt – for dette er det første særpræg. Hvis du kører uniq uden indstillinger, opfører det sig, som om du brugte muligheden -u (unikke linjer). Dette fortæller uniq kun at udskrive de unikke linjer fra filen. Grunden til, at du ser duplikerede linjer, er fordi, for at uniq kan betragte en linje som en dublet, skal den støde op til dens duplikat, hvilket er her sortering kommer ind.
Når vi sorterer filen, grupperer den de duplikerede linjer, og uniq behandler dem som dubletter. Vi vil bruge sorter på filen, overføre det sorterede output til uniq og derefter overføre det endelige output til mindre.
For at gøre det skriver vi følgende:
sort dust-my-broom.txt | uniq | less

En sorteret liste over linjer vises i mindre.
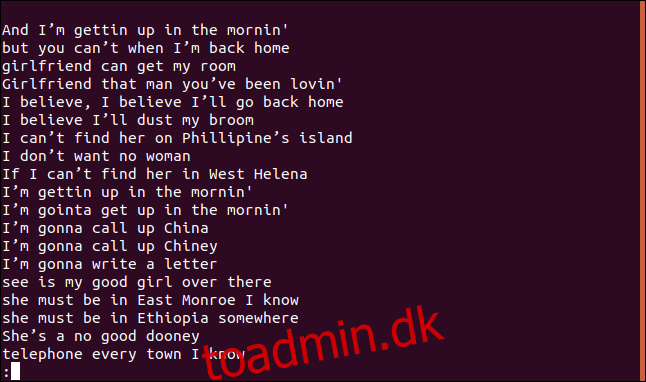
Linjen, “I believe I’ll dust my broom,” optræder bestemt i sangen mere end én gang. Faktisk gentages det to gange inden for de første fire linjer af sangen.
Så hvorfor vises det på en liste over unikke linjer? For første gang en linje vises i filen, er den unik; kun de efterfølgende poster er dubletter. Du kan tænke på det som en liste over den første forekomst af hver unik linje.
Lad os bruge sorter igen og omdirigere outputtet til en ny fil. På denne måde behøver vi ikke bruge sortering i hver kommando.
Vi skriver følgende kommando:
sort dust-my-broom.txt > sorted.txt
 sorted.txt” kommando i et terminalvindue.’ width=”646″ højde=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
sorted.txt” kommando i et terminalvindue.’ width=”646″ højde=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Nu har vi en forudsorteret fil at arbejde med.
Optælling af dubletter
Du kan bruge indstillingen -c (tæl) til at udskrive det antal gange, hver linje vises i en fil.
Skriv følgende kommando:
uniq -c sorted.txt | less

Hver linje begynder med det antal gange, den linje vises i filen. Du vil dog bemærke, at den første linje er tom. Dette fortæller dig, at der er fem tomme linjer i filen.
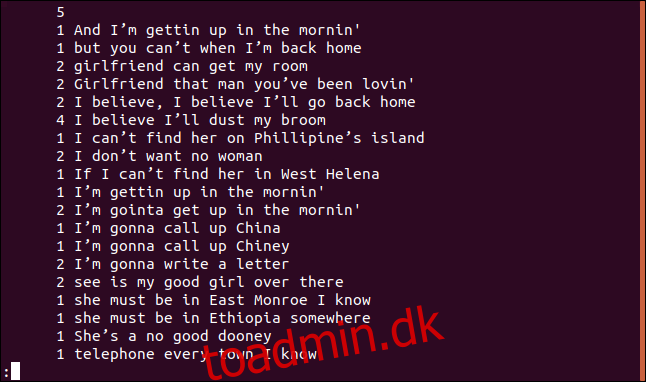
Hvis du vil have output sorteret i numerisk rækkefølge, kan du føre output fra uniq til sortering. I vores eksempel vil vi bruge mulighederne -r (omvendt) og -n (numerisk sortering) og overføre resultaterne til mindre.
Vi skriver følgende:
uniq -c sorted.txt | sort -rn | less

Listen er sorteret i faldende rækkefølge baseret på hyppigheden af hver linjes udseende.
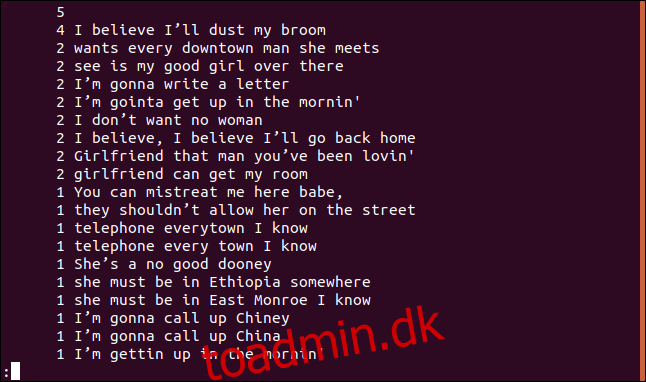
Liste kun duplikerede linjer
Hvis du kun vil se de linjer, der gentages i en fil, kan du bruge -d (gentaget) mulighed. Uanset hvor mange gange en linje duplikeres i en fil, er den kun opført én gang.
For at bruge denne mulighed skriver vi følgende:
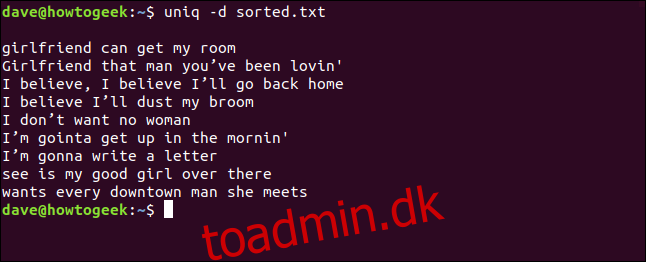
uniq -d sorted.txt

De duplikerede linjer er opført for os. Du vil bemærke den tomme linje øverst, hvilket betyder, at filen indeholder duplikerede tomme linjer – det er ikke et mellemrum efterladt af uniq til kosmetisk at udligne fortegnelsen.
Vi kan også kombinere -d (gentaget) og -c (tæl) mulighederne og sende output gennem sortering. Dette giver os en sorteret liste over de linjer, der vises mindst to gange.
Indtast følgende for at bruge denne mulighed:
uniq -d -c sorted.txt | sort -rn
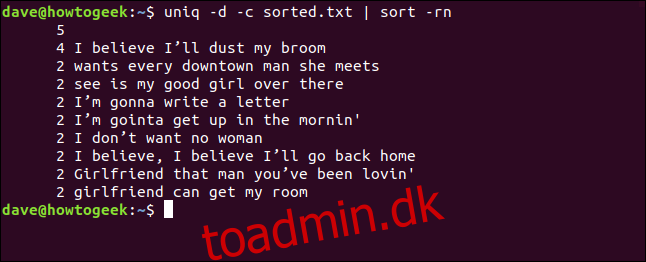
Liste over alle duplikerede linjer
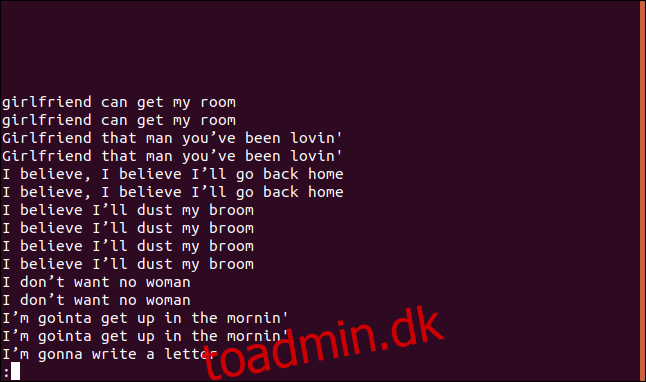
Hvis du vil se en liste over hver duplikeret linje, samt en indtastning for hver gang en linje vises i filen, kan du bruge -D (alle duplikerede linjer) mulighed.
For at bruge denne mulighed skal du skrive følgende:
uniq -D sorted.txt | less

Listen indeholder en post for hver duplikeret linje.
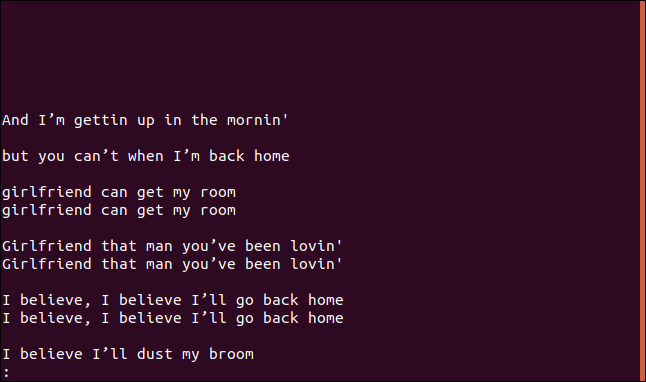
Hvis du bruger indstillingen –gruppe, udskriver den hver duplikeret linje med en tom linje enten før (prepend) eller efter hver gruppe (tilføj), eller både før og efter (begge) hver gruppe.
Vi bruger append som vores modifikator, så vi skriver følgende:
uniq --group=append sorted.txt | less

Grupperne er adskilt af tomme linjer for at gøre dem nemmere at læse.
Kontrol af et bestemt antal tegn
Som standard kontrollerer uniq hele længden af hver linje. Hvis du vil begrænse kontrollen til et bestemt antal tegn, kan du dog bruge -w (check chars) muligheden.
I dette eksempel gentager vi den sidste kommando, men begrænser sammenligningerne til de første tre tegn. For at gøre det, skriver vi følgende kommando:
uniq -w 3 --group=append sorted.txt | less

De resultater og grupperinger, vi modtager, er ret forskellige.
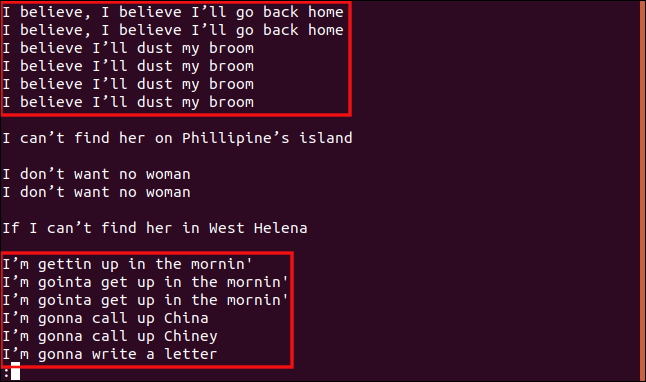
Alle linjer, der starter med “I b”, er grupperet sammen, fordi disse dele af linjerne er identiske, så de anses for at være dubletter.
Ligeledes behandles alle linjer, der starter med “Jeg er”, som dubletter, selvom resten af teksten er anderledes.
Ignorerer et bestemt antal tegn
Der er nogle tilfælde, hvor det kan være fordelagtigt at springe et vist antal tegn over i begyndelsen af hver linje, f.eks. når linjer i en fil er nummereret. Eller lad os sige, at du har brug for uniq for at hoppe over et tidsstempel og begynde at kontrollere linjerne fra tegn seks i stedet for fra det første tegn.
Nedenfor er en version af vores sorterede fil med nummererede linjer.
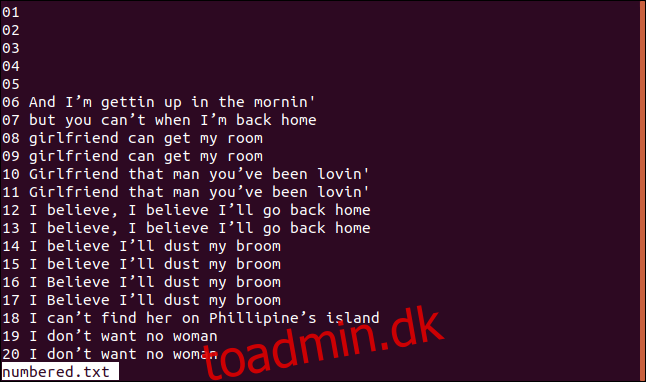
Hvis vi ønsker, at uniq skal starte sine sammenligningstjek ved tegn tre, kan vi bruge -s (spring tegn over) ved at skrive følgende:
uniq -s 3 -d -c numbered.txt
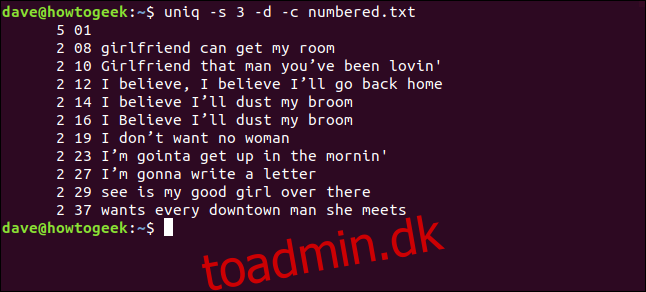
Linjerne detekteres som dubletter og tælles korrekt. Bemærk, at de viste linjenumre er dem for den første forekomst af hver dublet.
Du kan også springe felter over (en række tegn og et mellemrum) i stedet for tegn. Vi bruger muligheden -f (felter) til at fortælle uniq, hvilke felter der skal ignoreres.
Vi skriver følgende for at bede uniq om at ignorere det første felt:
uniq -f 1 -d -c numbered.txt
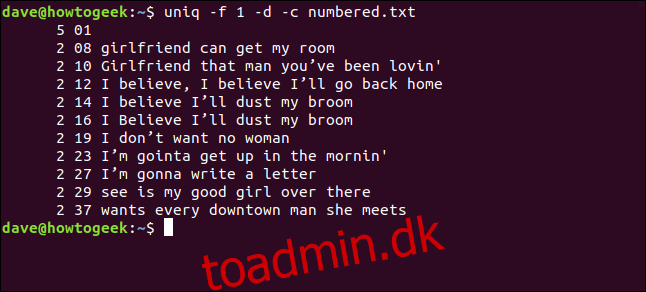
Vi får de samme resultater, som vi fik, da vi fortalte uniq at springe tre tegn over i starten af hver linje.
Ignorerer sag
Som standard skelner uniq mellem store og små bogstaver. Hvis det samme bogstav vises med låg og med små bogstaver, anser uniq linjerne for at være forskellige.
Tjek for eksempel outputtet fra følgende kommando:
uniq -d -c sorted.txt | sort -rn
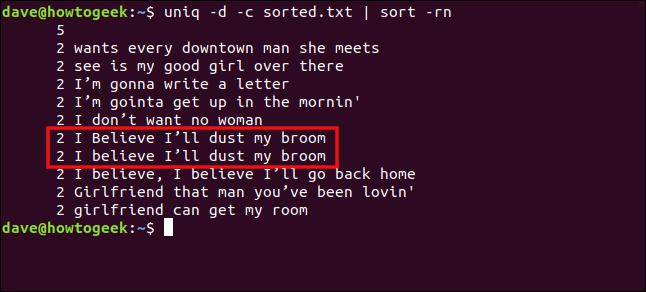
Linjerne “I Believe I’ll dust my broom” og “I believe I’ll dust my broom” behandles ikke som dubletter på grund af forskellen i kasus på “B” i “believe”.
Hvis vi inkluderer muligheden -i (ignorer store og små bogstaver), vil disse linjer dog blive behandlet som dubletter. Vi skriver følgende:
uniq -d -c -i sorted.txt | sort -rn
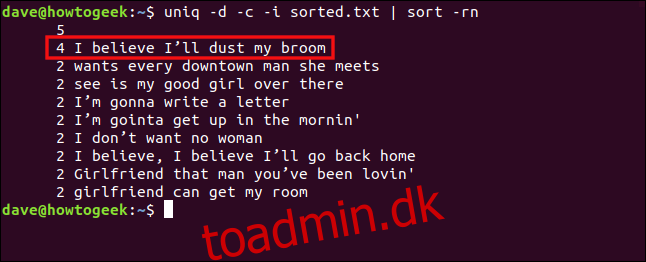
Linjerne behandles nu som dubletter og grupperes sammen.
Linux stiller et væld af specielle hjælpeprogrammer til din rådighed. Som mange af dem er uniq ikke et værktøj, du vil bruge hver dag.
Det er derfor en stor del af at blive dygtig til Linux er at huske, hvilket værktøj der løser dit nuværende problem, og hvor du kan finde det igen. Hvis du øver dig, er du dog godt på vej.
Eller du kan altid bare søge How-To Geek – vi har sandsynligvis en artikel om det.