
For år siden, da lokale Unix-servere med store filsystemer var en ting, byggede virksomheder omfattende mappestyringsregler og strategier til at administrere adgangsrettigheder til forskellige mapper for forskellige mennesker.
Normalt betjener en organisations platform forskellige grupper af brugere med helt forskellige interesser, begrænsninger på fortrolighedsniveau eller indholdsdefinitioner. I tilfælde af globale organisationer kan dette endda betyde at adskille indhold baseret på placering, så dybest set, mellem brugere, der tilhører forskellige lande.
Yderligere typiske eksempler kan omfatte:
- dataadskillelse mellem udviklings-, test- og produktionsmiljøer
- salgsindhold, der ikke er tilgængeligt for et bredt publikum
- landespecifikt lovgivningsmæssigt indhold, der ikke kan ses eller tilgås fra en anden region
- projektrelateret indhold, hvor “ledelsesdata” kun skal udleveres til en begrænset gruppe mennesker mv.
Der er en potentielt uendelig liste over sådanne eksempler. Pointen er, at der altid er en form for behov for at orkestrere adgangsrettigheder til filer og data mellem alle de brugere, som platformen giver adgang til.
I tilfælde af on-premise løsninger var dette en rutineopgave. Administratoren af filsystemet satte bare nogle regler op, brugte et valgfrit værktøj, og så blev folk kortlagt i brugergrupper, og brugergrupper blev kortlagt til en liste over mapper eller monteringspunkter, de skal have adgang til. Undervejs blev adgangsniveauet defineret som skrivebeskyttet eller læse- og skriveadgang.
Når man ser på AWS cloud-platforme, er det oplagt at forvente, at folk har lignende krav til indholdsadgangsbegrænsninger. Løsningen på dette problem må imidlertid være en anden. Filer er ikke længere modstandsdygtige på Unix-servere, men i skyen (og potentielt tilgængelige ikke kun for hele organisationen, men endda hele verden), og indholdet er ikke gemt i mapper, men i S3-bøtter.

Nedenfor er beskrevet et alternativ til at nærme sig dette problem. Det er bygget på den oplevelse i den virkelige verden, jeg havde, mens jeg designede sådanne løsninger til et konkret projekt.
Indholdsfortegnelse
Enkel, men meget manuel tilgang
En måde at løse dette problem på uden automatisering er relativt ligetil og enkel:
- Opret en ny bøtte for hver enkelt gruppe mennesker.
- Tildel adgangsrettigheder til bucket, så kun denne specifikke gruppe kan få adgang til S3 bucket.
Dette er bestemt muligt, hvis kravet er at gå med en meget enkel og hurtig løsning. Der er dog nogle grænser, man skal være opmærksom på.
Som standard kan der kun oprettes op til 100 S3-bøtter under én AWS-konto. Denne grænse kan udvides til 1000 ved at indsende en servicegrænseforhøjelse til AWS-billetten. Hvis disse grænser ikke er noget, din særlige implementeringssag ville være bekymret over, så kan du lade hver af dine særskilte domænebrugere operere på en separat S3-spand og kalde det en dag.
Problemerne kan opstå, hvis der er nogle grupper af mennesker med tværgående ansvar eller blot nogle mennesker, der har brug for adgang til indholdet af flere domæner på samme tid. For eksempel:
- Dataanalytikere evaluerer dataindholdet for flere forskellige områder, regioner osv.
- Testteamet delte tjenester, der betjener forskellige udviklingsteams.
- Rapportering af brugere, der har behov for at opbygge dashboard-analyse oven på forskellige lande i samme region.
Som du måske forestiller dig, kan denne liste igen vokse så meget, som du kan forestille dig, og organisationers behov kan generere alle slags use cases.
Jo mere kompleks denne liste bliver, jo mere kompleks orkestrering af adgangsrettigheder vil være nødvendig for at give alle disse forskellige grupper forskellige adgangsrettigheder til forskellige S3-bøtter i organisationen. Der vil være behov for yderligere værktøjer, og måske vil endda en dedikeret ressource (administrator) være nødt til at vedligeholde adgangsrettighedslisterne og opdatere dem, når der anmodes om en ændring (hvilket vil være meget ofte, især hvis organisationen er stor).
Så hvordan opnår man det samme på en mere organiseret og automatiseret måde?
Hvis bucket-per-domæne-tilgangen ikke virker, vil enhver anden løsning ende med delte buckets for flere brugergrupper. I sådanne tilfælde er det nødvendigt at bygge hele logikken med at tildele adgangsrettigheder i et eller andet område, som er nemt at ændre eller opdatere dynamisk.
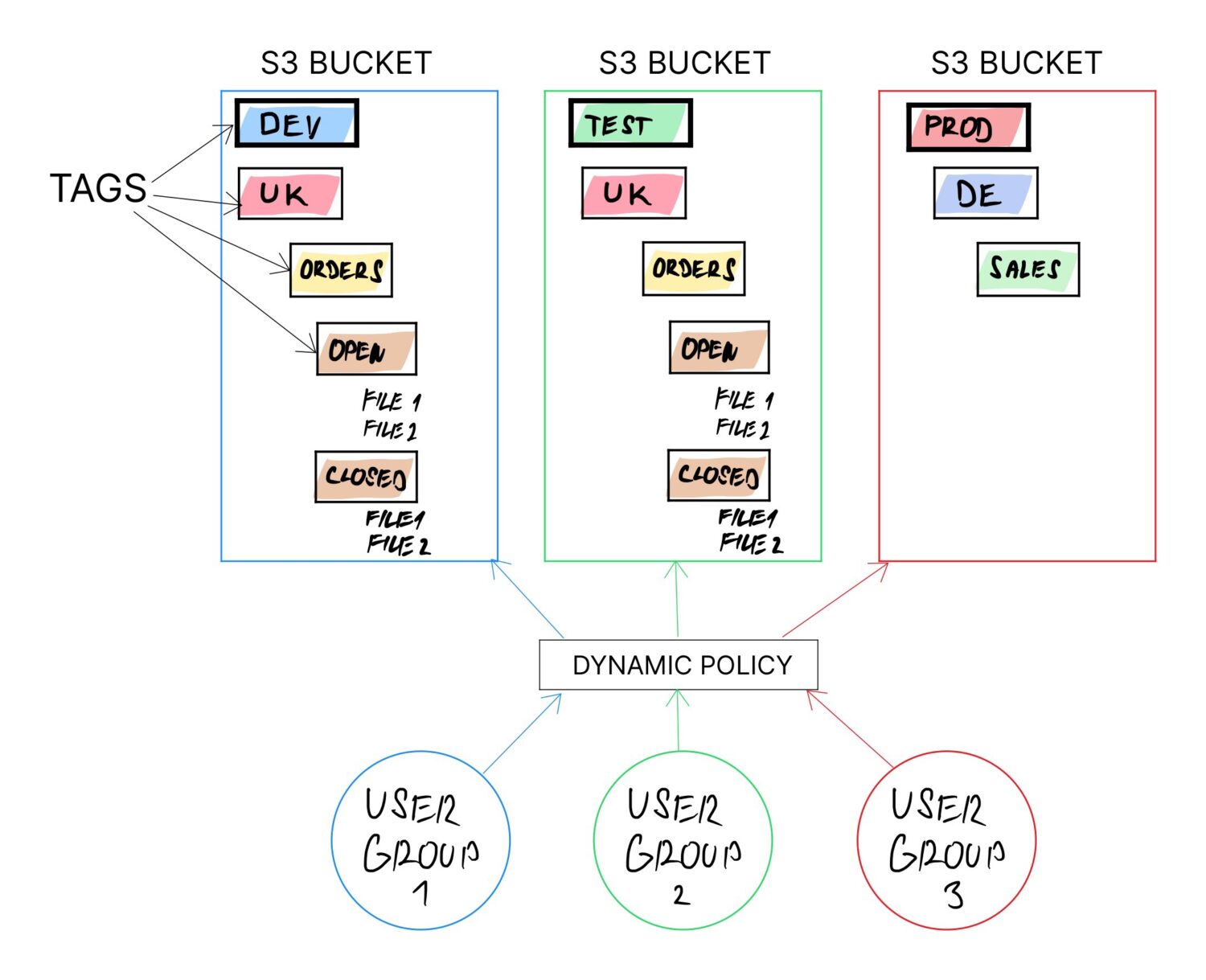
En af måderne, hvordan man opnår det, er ved at bruge Tags på S3-bøtterne. Det anbefales at bruge taggene under alle omstændigheder (om ikke for andet end for at muliggøre lettere faktureringskategorisering). Taget kan dog ændres når som helst i fremtiden for en hvilken som helst spand.
Hvis hele logikken er bygget ud fra bucket-tags og resten bag er konfiguration afhængig af tag-værdierne, er den dynamiske egenskab sikret, da man kan omdefinere formålet med bucket blot ved at opdatere tag-værdierne.
Hvilken slags tags skal man bruge for at få dette til at fungere?
Dette afhænger af din konkrete use case. For eksempel:
- Det kan være nødvendigt at adskille spande efter miljøtype. Så i så fald skal et af tagnavnene være noget som “ENV” og med mulige værdier “DEV”, “TEST”, “PROD” osv.
- Måske vil du adskille holdet ud fra landet. I så fald vil et andet tag være “COUNTRY” og værdi et eller andet landenavn.
- Eller du vil måske adskille brugerne baseret på den funktionelle afdeling, de tilhører, som forretningsanalytikere, datavarehusbrugere, dataforskere osv. Så du opretter et tag med navnet “USER_TYPE” og den respektive værdi.
- En anden mulighed kunne være, at du eksplicit vil definere en fast mappestruktur for specifikke brugergrupper, som de skal bruge (for ikke at skabe deres eget rod af mapper og fare vild der over tid). Det kan du gøre igen med tags, hvor du kan angive flere arbejdsmapper som: “data/import”, “data/behandlet”, “data/fejl” osv.
Ideelt set ønsker du at definere tags, så de logisk kan kombineres og få dem til at danne en hel mappestruktur på bøtten.
For eksempel kan du kombinere følgende tags fra eksemplerne ovenfor for at konstruere en dedikeret mappestruktur til forskellige typer brugere fra forskellige lande med foruddefinerede importmapper, som de forventes at bruge:
- /
/ / /
Bare ved at ændre
Dette vil muliggøre brugen af den samme spand for mange forskellige brugere. Buckets understøtter ikke eksplicit mapper, men de understøtter “labels”. Disse etiketter fungerer som undermapper i sidste ende, fordi brugerne skal gennemgå en række etiketter for at nå deres data (ligesom de ville gøre med undermapper).
Efter at have defineret tags i en eller anden brugbar form, er næste trin at bygge S3-bucket-politikker, der ville bruge tags.
Hvis politikkerne bruger tagnavnene, opretter du noget, der kaldes “dynamiske politikker”. Dette betyder dybest set, at din politik vil opføre sig anderledes for buckets med forskellige tagværdier, som politikken henviser til i form eller pladsholdere.
Dette trin involverer naturligvis en vis tilpasset kodning af de dynamiske politikker, men du kan forenkle dette trin ved hjælp af Amazon AWS policy editor-værktøjet, som vil guide dig gennem processen.
I selve politikken vil du gerne kode konkrete adgangsrettigheder, der skal anvendes på bucket og adgangsniveauet for sådanne rettigheder (læse, skrive). Logikken vil læse tags på buckets og vil opbygge mappestrukturen på bucket (opretter etiketter baseret på tags). Baseret på de konkrete værdier af taggene vil undermapperne blive oprettet, og nødvendige adgangsrettigheder vil blive tildelt langs linjen.
Det gode ved sådan en dynamisk politik er, at du kun kan oprette én dynamisk politik og derefter tildele den samme dynamiske politik til mange buckets. Denne politik vil opføre sig anderledes for buckets med forskellige tagværdier, men den vil altid være sammen med din forventning om en bucket med sådanne tagværdier.
Det er en virkelig effektiv måde at administrere tildelinger af adgangsrettigheder på en organiseret, centraliseret måde for et stort antal buckets, hvor det er forventningen, at hver bucket vil følge nogle skabelonstrukturer, som er aftalt på forhånd og vil blive brugt af dine brugere indenfor hele organisationen.
Automatiser onboarding af nye enheder
Efter at have defineret dynamiske politikker og tildelt dem til de eksisterende buckets, kan brugerne begynde at bruge de samme buckets uden risiko for, at brugere fra forskellige grupper ikke får adgang til indhold (gemt på samme bucket) placeret under en mappestruktur, hvor de ikke har adgang.
For nogle brugergrupper med bredere adgang vil det også være nemt at nå ud efter dataene, fordi det hele vil blive gemt i den samme bøtte.
Det sidste trin er at gøre onboarding af nye brugere, nye buckets og endda nye tags så enkelt som muligt. Dette førte til en anden brugerdefineret kodning, som dog ikke behøver at være alt for kompleks, forudsat at din onboarding-proces har nogle meget klare regler, der kan indkapsles med enkel, ligetil algoritmelogik (i det mindste kan du på denne måde bevise, at din processen har en vis logik, og det er ikke gjort på den alt for kaotiske måde).
Dette kan være så simpelt som at oprette et script, der kan eksekveres af AWS CLI-kommando med parametre, der er nødvendige for at kunne integrere en ny enhed på platformen. Det kan endda være en række CLI-scripts, der kan eksekveres i en bestemt rækkefølge, som for eksempel:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - etc.
Du forstår pointen. 😃
Et professionelt tip 👨💻
Der er et Pro Tip, hvis du vil, som nemt kan påføres oven på ovenstående.
De dynamiske politikker kan udnyttes ikke kun til at tildele adgangsrettigheder til mappeplaceringer, men også til at tildele servicerettigheder til buckets og brugergrupper automatisk!
Det eneste, der kræves, er at udvide listen over tags på buckets og derefter tilføje dynamiske politikadgangsrettigheder for at bruge specifikke tjenester til konkrete grupper af brugere.
For eksempel kan der være en gruppe brugere, der også har brug for adgang til den specifikke databaseklyngeserver. Dette kan utvivlsomt opnås ved dynamiske politikker, der udnytter bucket-opgaver, i højere grad hvis adgangen til tjenesterne er drevet af en rollebaseret tilgang. Du skal blot tilføje en del til den dynamiske politikkode, der behandler tags vedrørende databaseklyngespecifikationen og tildeler politikadgangsrettighederne til den pågældende DB-klynge og brugergruppe direkte.
På denne måde vil onboarding af en ny brugergruppe kunne eksekveres blot ved denne enkelte dynamiske politik. Da den er dynamisk, kan den samme politik desuden genbruges til onboarding af mange forskellige brugergrupper (forventes at følge den samme skabelon, men ikke nødvendigvis de samme tjenester).
Du kan også tage et kig på disse AWS S3-kommandoer til at administrere buckets og data.