
Regression og klassificering er to af de mest grundlæggende og betydningsfulde områder inden for maskinlæring.
Det kan være svært at skelne mellem regression og klassifikationsalgoritmer, når du lige er i gang med maskinlæring. At forstå, hvordan disse algoritmer fungerer, og hvornår de skal bruges, kan være afgørende for at foretage præcise forudsigelser og effektive beslutninger.
Lad os først se om maskinlæring.
Indholdsfortegnelse
Hvad er Machine learning?
Machine learning er en metode til at lære computere at lære og træffe beslutninger uden at være eksplicit programmeret. Det involverer træning af en computermodel på et datasæt, hvilket giver modellen mulighed for at foretage forudsigelser eller beslutninger baseret på mønstre og relationer i dataene.
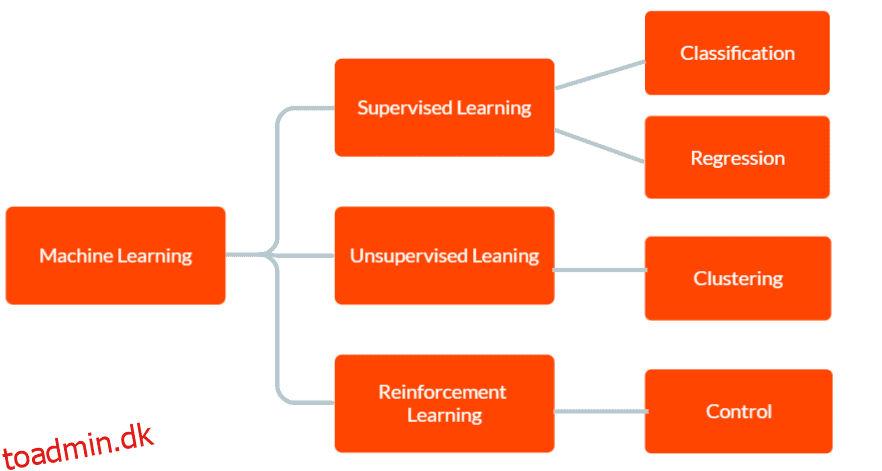
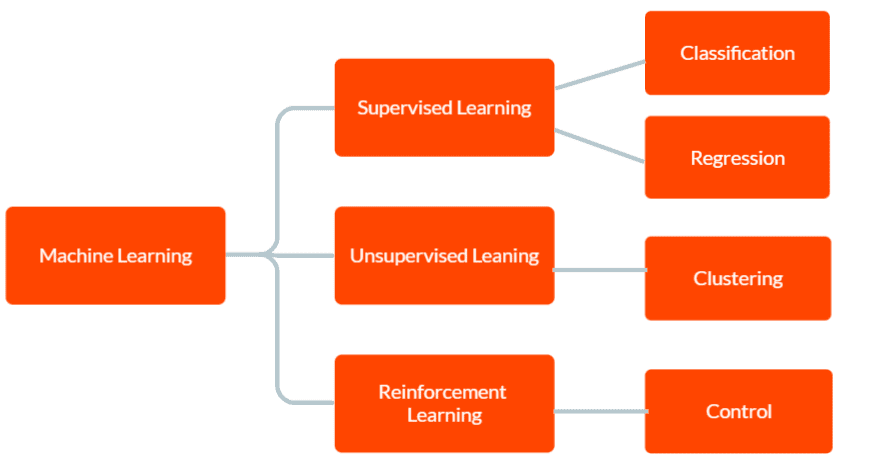
Der er tre hovedtyper af maskinlæring: overvåget læring, uovervåget læring og forstærkende læring.
I Supervised learning forsynes modellen med mærkede træningsdata, herunder inputdata og det tilsvarende korrekte output. Målet er, at modellen skal lave forudsigelser om output for nye, usete data baseret på de mønstre, den har lært fra træningsdataene.
I Unsupervised learning får modellen ikke mærket træningsdata. I stedet er det overladt til selvstændigt at opdage mønstre og sammenhænge i dataene. Dette kan bruges til at identificere grupper eller klynger i dataene eller til at finde anomalier eller usædvanlige mønstre.
Og i Reinforcement Learning lærer en agent at interagere med sit miljø for at maksimere en belønning. Det involverer træning af en model til at træffe beslutninger baseret på den feedback, den modtager fra omgivelserne.
Maskinlæring bruges i forskellige applikationer, herunder billed- og talegenkendelse, naturlig sprogbehandling, svindeldetektion og selvkørende biler. Det har potentialet til at automatisere mange opgaver og forbedre beslutningstagningen i forskellige brancher.
Denne artikel fokuserer hovedsageligt på klassifikations- og regressionsbegreber, som hører under overvåget maskinlæring. Lad os komme igang!
Klassifikation i Machine Learning

Klassificering er en maskinlæringsteknik, der involverer træning af en model til at tildele en klasseetiket til et givet input. Det er en superviseret læringsopgave, hvilket betyder, at modellen trænes på et mærket datasæt, der indeholder eksempler på inputdata og de tilsvarende klasseetiketter.
Modellen har til formål at lære forholdet mellem inputdata og klasseetiketterne for at forudsige klasseetiketten for nyt, uset input.
Der er mange forskellige algoritmer, der kan bruges til klassificering, herunder logistisk regression, beslutningstræer og støttevektormaskiner. Valget af algoritme vil afhænge af dataenes karakteristika og modellens ønskede ydeevne.
Nogle almindelige klassifikationsapplikationer omfatter spam-detektion, sentimentanalyse og svindeldetektion. I hvert af disse tilfælde kan inputdata omfatte tekst, numeriske værdier eller en kombination af begge. Klasseetiketterne kan være binære (f.eks. spam eller ej spam) eller multi-class (f.eks. positiv, neutral, negativ følelse).
Overvej for eksempel et datasæt med kundeanmeldelser af et produkt. Inputdataene kan være teksten i anmeldelsen, og klasseetiketten kan være en vurdering (f.eks. positiv, neutral, negativ). Modellen vil blive trænet på et datasæt af mærkede anmeldelser og derefter være i stand til at forudsige vurderingen af en ny anmeldelse, som den ikke havde set før.
ML klassifikationsalgoritmetyper
Der er flere typer klassifikationsalgoritmer i maskinlæring:
Logistisk regression
Dette er en lineær model, der bruges til binær klassifikation. Det bruges til at forudsige sandsynligheden for, at en bestemt begivenhed indtræffer. Målet med logistisk regression er at finde de bedste koefficienter (vægte), der minimerer fejlen mellem den forudsagte sandsynlighed og det observerede udfald.
Dette gøres ved at bruge en optimeringsalgoritme, såsom gradient descent, til at justere koefficienterne, indtil modellen passer bedst muligt til træningsdataene.
Beslutningstræer
Disse er trælignende modeller, der træffer beslutninger baseret på funktionsværdier. De kan bruges til både binær og multi-klasse klassificering. Beslutningstræer har flere fordele, herunder deres enkelhed og interoperabilitet.
De er også hurtige til at træne og lave forudsigelser, og de kan håndtere både numeriske og kategoriske data. De kan dog være tilbøjelige til at overmontere, især hvis træet er dybt og har mange grene.
Tilfældig skovklassifikation
Random Forest Classification er en ensemblemetode, der kombinerer forudsigelserne fra flere beslutningstræer for at lave en mere præcis og stabil forudsigelse. Det er mindre tilbøjeligt til overfitting end et enkelt beslutningstræ, fordi de enkelte træers forudsigelser er gennemsnittet, hvilket reducerer variansen i modellen.
AdaBoost
Dette er en boostningsalgoritme, der adaptivt ændrer vægten af forkert klassificerede eksempler i træningssættet. Det bruges ofte til binær klassificering.
Naive Bayes
Naive Bayes er baseret på Bayes’ teorem, som er en måde at opdatere sandsynligheden for en begivenhed baseret på nye beviser. Det er en probabilistisk klassificering, der ofte bruges til tekstklassificering og spamfiltrering.
K-Nærmeste Nabo
K-Nearest Neighbours (KNN) bruges til klassifikations- og regressionsopgaver. Det er en ikke-parametrisk metode, der klassificerer et datapunkt baseret på klassen af dets nærmeste naboer. KNN har flere fordele, blandt andet dets enkelthed og det faktum, at det er nemt at implementere. Det kan også håndtere både numeriske og kategoriske data, og det gør ingen antagelser om den underliggende datafordeling.
Gradient Boosting
Disse er ensembler af svage elever, der trænes sekventielt, hvor hver model forsøger at rette op på fejlene i den tidligere model. De kan bruges til både klassificering og regression.
Regression i Machine Learning
I maskinlæring er regression en type overvåget læring, hvor målet er at forudsige ac-afhængig variabel baseret på en eller flere input-funktioner (også kaldet prædiktorer eller uafhængige variabler).
Regressionsalgoritmer bruges til at modellere forholdet mellem input og output og lave forudsigelser baseret på dette forhold. Regression kan bruges til både kontinuerte og kategorisk afhængige variable.
Generelt er målet med regression at bygge en model, der nøjagtigt kan forudsige outputtet baseret på inputfunktionerne og at forstå det underliggende forhold mellem inputfunktionerne og outputtet.
Regressionsanalyse bruges på forskellige områder, herunder økonomi, finans, marketing og psykologi, til at forstå og forudsige sammenhængen mellem forskellige variabler. Det er et grundlæggende værktøj i dataanalyse og maskinlæring og bruges til at lave forudsigelser, identificere tendenser og forstå de underliggende mekanismer, der driver dataene.
For eksempel kan målet i en simpel lineær regressionsmodel være at forudsige prisen på et hus baseret på dets størrelse, placering og andre funktioner. Husets størrelse og dets placering ville være de uafhængige variable, og husets pris ville være den afhængige variabel.
Modellen vil blive trænet på inputdata, der inkluderer størrelsen og placeringen af flere huse, sammen med deres tilsvarende priser. Når modellen er trænet, kan den bruges til at lave forudsigelser om prisen på et hus, givet dets størrelse og beliggenhed.
Typer af ML-regressionsalgoritmer
Regressionsalgoritmer er tilgængelige i forskellige former, og brugen af hver algoritme afhænger af antallet af parametre, såsom typen af attributværdi, trendlinjens mønster og antallet af uafhængige variable. Regressionsteknikker, der ofte bruges, omfatter:
Lineær regression
Denne simple lineære model bruges til at forudsige en kontinuerlig værdi baseret på et sæt funktioner. Det bruges til at modellere forholdet mellem funktionerne og målvariablen ved at tilpasse en linje til dataene.
Polynomisk regression
Dette er en ikke-lineær model, der bruges til at tilpasse en kurve til dataene. Det bruges til at modellere forhold mellem funktionerne og målvariablen, når forholdet ikke er lineært. Den er baseret på ideen om at tilføje højere ordens termer til den lineære model for at fange ikke-lineære sammenhænge mellem de afhængige og uafhængige variable.
Ridge regression
Dette er en lineær model, der adresserer overfitting i lineær regression. Det er en regulariseret version af lineær regression, der tilføjer et strafled til omkostningsfunktionen for at reducere kompleksiteten af modellen.
Understøtte vektorregression
Ligesom SVM’er er Support Vector Regression en lineær model, der forsøger at passe til dataene ved at finde det hyperplan, der maksimerer marginen mellem de afhængige og uafhængige variable.
Men i modsætning til SVM’er, som bruges til klassificering, bruges SVR til regressionsopgaver, hvor målet er at forudsige en kontinuerlig værdi frem for en klasseetiket.
Lasso regression
Dette er en anden regulariseret lineær model, der bruges til at forhindre overtilpasning i lineær regression. Det tilføjer et strafled til omkostningsfunktionen baseret på koefficienternes absolutte værdi.
Bayesiansk lineær regression
Bayesiansk lineær regression er en probabilistisk tilgang til lineær regression baseret på Bayes’ teorem, som er en måde at opdatere sandsynligheden for en begivenhed baseret på nye beviser.
Denne regressionsmodel har til formål at estimere den posteriore fordeling af modelparametrene givet dataene. Dette gøres ved at definere en forudgående fordeling over parametrene og derefter bruge Bayes’ sætning til at opdatere fordelingen baseret på de observerede data.
Regression vs. Klassifikation
Regression og klassifikation er to typer overvåget læring, hvilket betyder, at de bruges til at forudsige et output baseret på et sæt inputfunktioner. Der er dog nogle vigtige forskelle mellem de to:
RegressionClassificationDefinitionEn type overvåget læring, der forudsiger en kontinuert værdiEn type overvåget læring, der forudsiger en kategorisk værdiOutputtypeContinuousDiscreteEvaluation metricsMean squared error (MSE), root mean squared error (RMSE)Nøjagtighed, præcision, genkaldelse, F1-scoreAlgorithms,Nline,Lasso,Regression Decision TreeLogistisk regression, SVM, Naive Bayes, KNN, Decision TreeModelkompleksitetMindre komplekse modellerMere komplekse modellerAntagelserLineært forhold mellem funktioner og målIngen specifikke antagelser om forholdet mellem funktioner og målKlasse-ubalanceIkke relevantDet kan være et problemOutliersKan påvirke modellens præstationerIkke vigtighedFunktioner er normalt et problem. er ikke rangeret efter vigtighedEksempelapplikationer Forudsigelse af priser, temperaturer, mængder Forudsige om e-mail-spam, forudsigelse af kundeafgang
Læringsressourcer
Det kan være udfordrende at vælge de bedste onlineressourcer til at forstå maskinlæringskoncepter. Vi har undersøgt de populære kurser leveret af pålidelige platforme for at præsentere dig for vores anbefalinger til de bedste ML-kurser om regression og klassificering.
#1. Machine Learning Classification Bootcamp i Python
Dette er et kursus, der tilbydes på Udemy-platformen. Det dækker en række klassifikationsalgoritmer og -teknikker, herunder beslutningstræer og logistisk regression, og understøtter vektormaskiner.

Du kan også lære om emner som overfitting, bias-variance tradeoff og modelevaluering. Kurset bruger Python-biblioteker såsom sci-kit-learn og pandaer til at implementere og evaluere maskinlæringsmodeller. Så grundlæggende pythonviden er påkrævet for at komme i gang med dette kursus.
#2. Machine Learning Regression Masterclass i Python
I dette Udemy-kursus dækker træneren det grundlæggende og underliggende teori om forskellige regressionsalgoritmer, herunder lineær regression, polynomiel regression og Lasso & Ridge-regressionsteknikker.
Ved afslutningen af dette kursus vil du være i stand til at implementere regressionsalgoritmer og vurdere ydeevnen af trænede Machine learning-modeller ved hjælp af forskellige Key Performance Indicators.
Afslutter
Maskinlæringsalgoritmer kan være meget nyttige i mange applikationer, og de kan hjælpe med at automatisere og strømline mange processer. ML-algoritmer bruger statistiske teknikker til at lære mønstre i data og foretage forudsigelser eller beslutninger baseret på disse mønstre.
De kan trænes på store mængder data og kan bruges til at udføre opgaver, som ville være svære eller tidskrævende for mennesker at udføre manuelt.
Hver ML-algoritme har sine styrker og svagheder, og valget af algoritme afhænger af arten af data og opgavens krav. Det er vigtigt at vælge den passende algoritme eller kombination af algoritmer til det specifikke problem, du forsøger at løse.
Det er vigtigt at vælge den rigtige type algoritme til dit problem, da brug af den forkerte type algoritme kan føre til dårlig ydeevne og unøjagtige forudsigelser. Hvis du er i tvivl om, hvilken algoritme du skal bruge, kan det være nyttigt at prøve både regressions- og klassifikationsalgoritmer og sammenligne deres ydeevne på dit datasæt.
Jeg håber, at du fandt denne artikel nyttig til at lære regression vs. klassificering i maskinlæring. Du kan også være interesseret i at lære om de bedste Machine Learning-modeller.