
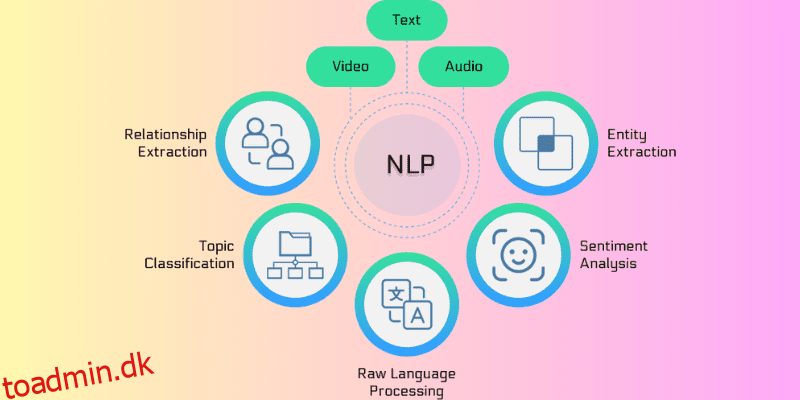
Menneskelige sprog er svære at forstå for maskiner, da det involverer en masse akronymer, forskellige betydninger, underbetydninger, grammatiske regler, kontekst, slang og mange andre aspekter.
Men mange forretningsprocesser og operationer udnytter maskiner og kræver interaktion mellem maskiner og mennesker.
Så videnskabsmænd havde brug for en teknologi, der ville hjælpe maskinen med at afkode menneskelige sprog og gøre det nemmere for maskiner at lære dem.
Det var, når naturlig sprogbehandling eller NLP-algoritmer opstod. Det gjorde computerprogrammer i stand til at forstå forskellige menneskelige sprog, uanset om ordene er skrevet eller talt.
NLP gør brug af forskellige algoritmer til behandling af sprog. Og med introduktionen af NLP-algoritmer blev teknologien en afgørende del af Artificial Intelligence (AI) for at hjælpe med at strømline ustrukturerede data.
I denne artikel vil jeg diskutere NLP og nogle af de mest omtalte NLP-algoritmer.
Lad os begynde!
Indholdsfortegnelse
Hvad er NLP?
Natural language process (NLP) er et felt inden for datalogi, lingvistik og kunstig intelligens, der beskæftiger sig med samspillet mellem menneskeligt sprog og computere. Det hjælper med at programmere maskiner, så de kan analysere og behandle store mængder data forbundet med naturlige sprog.
Med andre ord er NLP en moderne teknologi eller mekanisme, der bruges af maskiner til at forstå, analysere og fortolke menneskeligt sprog. Det giver maskiner mulighed for at forstå tekster og menneskers talesprog. Med NLP kan maskiner udføre oversættelse, talegenkendelse, opsummering, emnesegmentering og mange andre opgaver på vegne af udviklere.
Det bedste er, at NLP udfører alt arbejdet og opgaverne i realtid ved hjælp af flere algoritmer, hvilket gør det meget mere effektivt. Det er en af de teknologier, der blander maskinlæring, deep learning og statistiske modeller med beregningssproglig-regel-baseret modellering.
NLP-algoritmer tillader computere at behandle menneskeligt sprog gennem tekster eller stemmedata og afkode dets betydning til forskellige formål. Computernes fortolkningsevne har udviklet sig så meget, at maskiner endda kan forstå de menneskelige følelser og hensigter bag en tekst. NLP kan også forudsige kommende ord eller sætninger, der kommer til en brugers sind, når de skriver eller taler.
Denne teknologi har været til stede i årtier, og med tiden er den blevet evalueret og har opnået en bedre procesnøjagtighed. NLP har sine rødder forbundet med lingvistik og hjalp endda udviklere med at skabe søgemaskiner til internettet. Efterhånden som teknologien har udviklet sig med tiden, er dens brug af NLP udvidet.
I dag finder NLP anvendelse inden for en bred vifte af områder, fra finans, søgemaskiner og business intelligence til sundhedspleje og robotteknologi. Ydermere er NLP gået dybt ind i moderne systemer; det bliver brugt til mange populære applikationer som stemmestyret GPS, kundeservice chatbots, digital assistance, tale-til-tekst-betjening og mange flere.
Hvordan virker NLP?
NLP er en dynamisk teknologi, der bruger forskellige metoder til at oversætte komplekst menneskeligt sprog til maskiner. Det bruger hovedsageligt kunstig intelligens til at behandle og oversætte skrevne eller talte ord, så de kan forstås af computere.
Ligesom mennesker har hjerner til at behandle alle input, bruger computere et specialiseret program, der hjælper dem med at behandle input til et forståeligt output. NLP opererer i to faser under konverteringen, hvor den ene er databehandling og den anden er algoritmeudvikling.
Databehandling fungerer som den første fase, hvor input tekstdata forberedes og renses, så maskinen er i stand til at analysere dem. Dataene behandles på en sådan måde, at de påpeger alle funktionerne i inputteksten og gør den velegnet til computeralgoritmer. Grundlæggende forbereder databehandlingsstadiet dataene i en form, som maskinen kan forstå.
De teknikker, der er involveret i denne fase er:
 Kilde: Amazinum
Kilde: Amazinum
- Tokenisering: Indtastningsteksten er adskilt i små former, så det er egnet til NLP at arbejde på dem.
- Stop ordfjernelse: Stopordsfjernelsesteknikken fjerner alle de velkendte ord fra teksten og omdanner dem til en form, der bevarer al information i en minimal tilstand.
- Lemmatisering og stilkelse: Lemmatisering og stemming får ord til at blive formindsket til deres rodstruktur, så det er nemt for maskiner at behandle dem.
- Orddelingsmærkning: På denne måde markeres inputordene ud fra deres navneord, adjektiver og verber, og derefter bearbejdes de.
Efter at inputdataene har gennemgået den første fase, derefter udvikler maskinen en algoritme, hvor den endelig kan behandle dem. Blandt alle de NLP-algoritmer, der bruges til at behandle de forbehandlede ord, er regelbaserede og maskinlæringsbaserede systemer meget brugt:
- Regelbaserede systemer: Her anvender systemet sproglige regler til den endelige behandling af ordene. Det er en gammel algoritme, som stadig bliver brugt i stor skala.
- Maskinlæringsbaserede systemer: Dette er en avanceret algoritme, der kombinerer neurale netværk, deep learning og maskinlæring for at bestemme sin egen regel for behandling af ord. Da den bruger statistiske metoder, bestemmer algoritmen behandlingen af ord baseret på træningsdataene, og den foretager ændringer, efterhånden som den skrider frem.
Forskellige kategorier af NLP-algoritmer
NLP-algoritmer er ML-baserede algoritmer eller instruktioner, der bruges under behandling af naturlige sprog. De beskæftiger sig med udviklingen af protokoller og modeller, der gør det muligt for en maskine at fortolke menneskelige sprog.

NLP-algoritmer kan ændre deres form i henhold til AI’ens tilgang og også de træningsdata, de er blevet fodret med. Hovedopgaven for disse algoritmer er at bruge forskellige teknikker til effektivt at omdanne forvirrende eller ustruktureret input til vidende information, som maskinen kan lære af.
Sammen med alle teknikkerne bruger NLP-algoritmer naturlige sprogprincipper for at gøre inputs bedre forståelige for maskinen. De er ansvarlige for at hjælpe maskinen med at forstå kontekstværdien af et givet input; ellers vil maskinen ikke være i stand til at udføre anmodningen.
NLP-algoritmer er adskilt i tre forskellige kernekategorier, og AI-modeller vælger en af kategorierne afhængigt af dataforskerens tilgang. Disse kategorier er:
#1. Symbolske algoritmer
Symbolske algoritmer fungerer som en af rygraden i NLP-algoritmer. Disse er ansvarlige for at analysere betydningen af hver inputtekst og derefter bruge den til at etablere et forhold mellem forskellige begreber.
Symbolske algoritmer udnytter symboler til at repræsentere viden og også forholdet mellem begreber. Da disse algoritmer bruger logik og tildeler betydninger til ord baseret på kontekst, kan du opnå høj nøjagtighed.
Vidensgrafer spiller også en afgørende rolle i at definere begreber for et inputsprog sammen med forholdet mellem disse begreber. På grund af sin evne til korrekt at definere begreberne og let forstå ordkontekster, hjælper denne algoritme med at opbygge XAI.
Men symbolske algoritmer er udfordrende at udvide et sæt regler på grund af forskellige begrænsninger.
#2. Statistiske algoritmer
Statistiske algoritmer kan gøre arbejdet let for maskiner ved at gennemgå tekster, forstå hver af dem og hente betydningen. Det er en yderst effektiv NLP-algoritme, fordi den hjælper maskiner med at lære om menneskeligt sprog ved at genkende mønstre og tendenser i rækken af inputtekster. Denne analyse hjælper maskiner med at forudsige, hvilket ord der sandsynligvis vil blive skrevet efter det aktuelle ord i realtid.
Fra talegenkendelse, sentimentanalyse og maskinoversættelse til tekstforslag bruges statistiske algoritmer til mange applikationer. Hovedårsagen bag dets udbredte brug er, at det kan fungere på store datasæt.
Desuden kan statistiske algoritmer detektere, om to sætninger i et afsnit har ens betydning, og hvilken der skal bruges. Den største ulempe ved denne algoritme er dog, at den er delvist afhængig af kompleks funktionsteknik.
#3. Hybride algoritmer
Denne type NLP-algoritme kombinerer styrken af både symbolske og statistiske algoritmer for at producere et effektivt resultat. Ved at fokusere på de vigtigste fordele og funktioner, kan det nemt ophæve den maksimale svaghed ved begge tilgange, hvilket er afgørende for høj nøjagtighed.
Der er mange måder, hvorpå begge tilgange kan udnyttes:
- Symbolsk understøttelse af maskinlæring
- Maskinlæring, der understøtter symbolsk
- Symbolsk og maskinlæring arbejder parallelt
Symbolske algoritmer kan understøtte maskinlæring ved at hjælpe den med at træne modellen på en sådan måde, at den skal anstrenge sig mindre for at lære sproget på egen hånd. Selvom maskinlæring understøtter symbolske måder, kan ML-modellen skabe et indledende regelsæt for det symbolske og skåne dataforskeren fra at bygge det manuelt.
Men når symbolsk og maskinlæring arbejder sammen, fører det til bedre resultater, da det kan sikre, at modeller forstår en specifik passage korrekt.
Bedste NLP-algoritmer
Der er adskillige NLP-algoritmer, der hjælper en computer med at efterligne menneskeligt sprog til forståelse. Her er de bedste NLP-algoritmer, du kan bruge:
#1. Emnemodellering
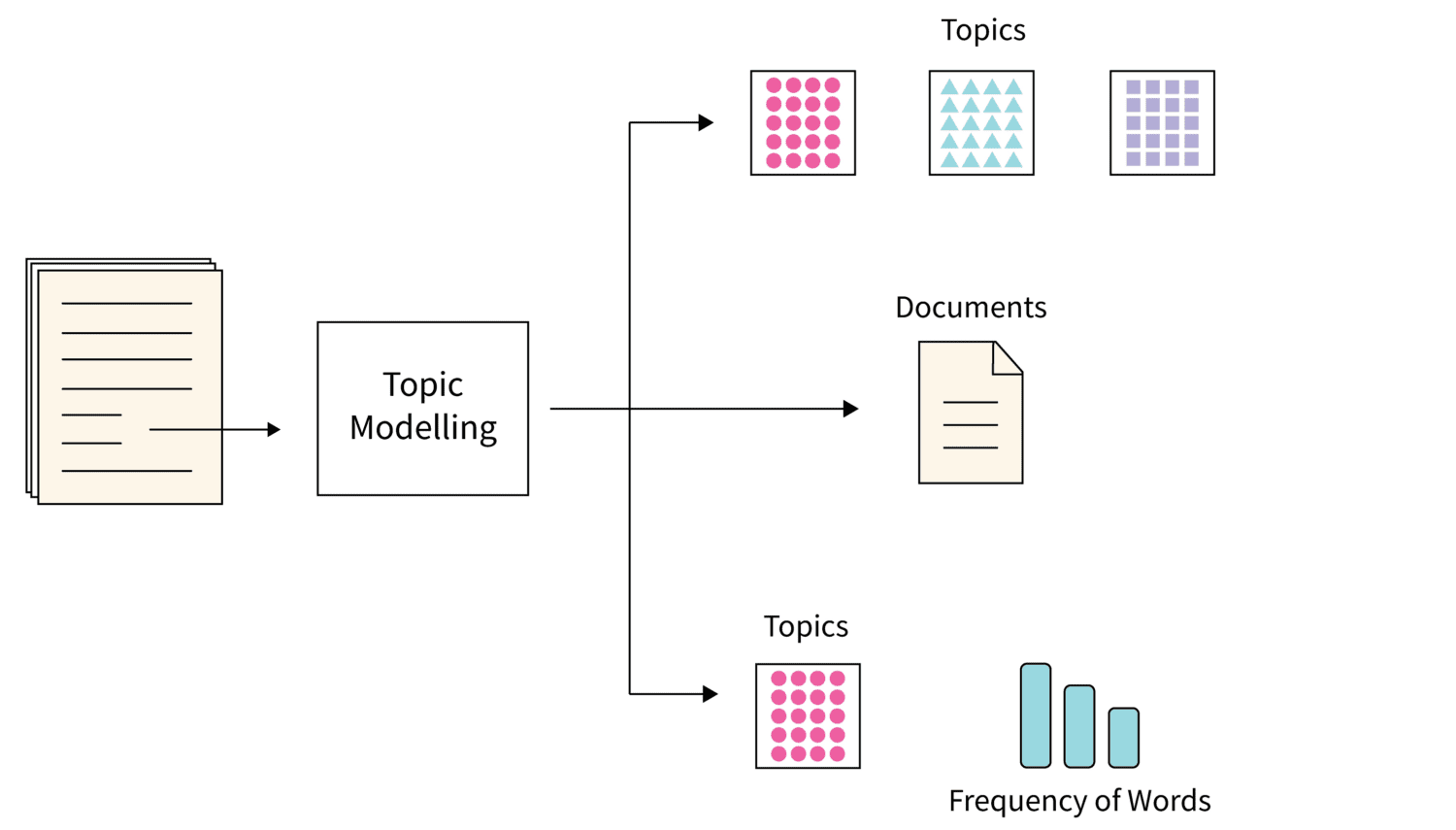 Billedkilde: Scaler
Billedkilde: Scaler
Emnemodellering er en af de algoritmer, der bruger statistiske NLP-teknikker til at finde ud af temaer eller hovedemner fra en massiv masse tekstdokumenter.
Grundlæggende hjælper det maskiner med at finde det emne, der kan bruges til at definere et bestemt tekstsæt. Da hvert korpus af tekstdokumenter har adskillige emner i sig, bruger denne algoritme enhver passende teknik til at finde ud af hvert emne ved at vurdere bestemte sæt af ordforråd.
Latent Dirichlet Allocation er et populært valg, når det kommer til at bruge den bedste teknik til emnemodellering. Det er en uovervåget ML-algoritme og hjælper med at akkumulere og organisere arkiver af en stor mængde data, hvilket ikke er muligt ved menneskelig annotering.
#2. Tekstopsummering
Det er en meget krævende NLP-teknik, hvor algoritmen opsummerer en tekst kort og det også på en flydende måde. Det er en hurtig proces, da opsummering hjælper med at udtrække al den værdifulde information uden at gå igennem hvert ord.
Opsummeringen kan gøres på to måder:
- Ekstraktionsbaseret opsummering: Det får maskinen til kun at udtrække de vigtigste ord og sætninger fra dokumentet uden at ændre originalen.
- Abstraktionsbaseret opsummering: I denne proces skabes nye ord og vendinger fra tekstdokumentet, som afbilder al information og hensigt.
#3. Sentimental analyse
Det er NLP-algoritmen, der hjælper en maskine med at forstå meningen eller hensigten bag en tekst fra brugeren. Det er meget populært og bruges i forskellige AI-modeller af virksomheder, fordi det hjælper virksomheder med at forstå, hvad kunderne synes om deres produkter eller service.
Ved at forstå hensigten med en kundes tekst- eller stemmedata på forskellige platforme, kan AI-modeller fortælle dig om en kundes følelser og hjælpe dig med at nærme dig dem i overensstemmelse hermed.
#4. Nøgleordsudtrækning
Søgeordsudtrækning er en anden populær NLP-algoritme, der hjælper med at udvinde et stort antal målrettede ord og sætninger fra et stort sæt tekstbaserede data.
Der er forskellige søgeordsudtrækningsalgoritmer tilgængelige, som inkluderer populære navne som TextRank, Term Frequency og RAKE. Nogle af algoritmerne kan bruge ekstra ord, mens nogle af dem kan hjælpe med at udtrække søgeord baseret på indholdet af en given tekst.
Hver af nøgleordsudtrækningsalgoritmerne bruger sine egne teoretiske og grundlæggende metoder. Det er gavnligt for mange organisationer, fordi det hjælper med at gemme, søge og hente indhold fra et betydeligt ustruktureret datasæt.
#5. Vidensgrafer
Når det kommer til at vælge den bedste NLP-algoritme, overvejer mange vidensgrafalgoritmer. Det er en fremragende teknik, der bruger tripler til lagring af information.
Denne algoritme er dybest set en blanding af tre ting – emne, prædikat og entitet. Men oprettelsen af en vidensgraf er ikke begrænset til én teknik; i stedet kræver det flere NLP-teknikker for at være mere effektive og detaljerede. Fagtilgangen bruges til at udtrække ordnet information fra en bunke ustrukturerede tekster.
#6. TF-IDF
TF-IDF er en statistisk NLP-algoritme, der er vigtig til at evaluere betydningen af et ord til et bestemt dokument, der tilhører en massiv samling. Denne teknik involverer multiplikation af karakteristiske værdier, som er:
- Begrebsfrekvens: Begrebet frekvensværdi giver dig det samlede antal gange, et ord kommer op i et bestemt dokument. Stopord får generelt en høj term frekvens i et dokument.
- Omvendt dokumentfrekvens: Omvendt dokumentfrekvens fremhæver på den anden side de termer, der er meget specifikke for et dokument eller ord, der forekommer mindre i et helt korpus af dokumenter.
#7. Ord Cloud
Words Cloud er en unik NLP-algoritme, der involverer teknikker til datavisualisering. I denne algoritme er de vigtige ord fremhævet, og derefter vises de i en tabel.
De væsentlige ord i dokumentet er trykt med større bogstaver, hvorimod de mindst vigtige ord vises med små skrifttyper. Nogle gange er de mindre vigtige ting ikke engang synlige på bordet.
Læringsressourcer
Bortset fra ovenstående oplysninger, hvis du vil lære mere om naturlig sprogbehandling (NLP), kan du overveje følgende kurser og bøger.
#1. Datavidenskab: Naturlig sprogbehandling i Python

Dette kursus af Udemy er højt vurderet af elever og omhyggeligt skabt af Lazy Programmer Inc. Det lærer alt om NLP og NLP algoritmer og lærer dig, hvordan du skriver sentimentanalyse. Med en samlet længde på 11 timer og 52 minutter giver dette kursus dig adgang til 88 forelæsninger.
#2. Naturlig sprogbehandling: NLP med transformere i Python
Med dette populære kursus af Udemy lærer du ikke kun om NLP med transformermodeller, men får også mulighed for at lave finjusterede transformermodeller. Dette kursus giver dig komplet dækning af NLP med dets 11,5 timers on-demand video og 5 artikler. Derudover vil du lære om vektor-bygningsteknikker og forbehandling af tekstdata til NLP.
#3. Naturlig sprogbehandling med transformere
Denne bog blev først udgivet i 2017 og havde til formål at hjælpe dataforskere og kodere med at lære om NLP. Når du begynder at læse bogen, vil du komme til at bygge og optimere transformermodeller til mange NLP-opgaver. Du får også at vide, hvordan du kan bruge transformatorer til tværsproglig overførselslæring.
#4. Praktisk naturlig sprogbehandling
Gennem denne bog har forfatterne forklaret opgaver, problemer og løsningstilgange for NLP. Denne bog lærer også om implementering og evaluering af forskellige NLP-applikationer.
Konklusion
NLP er en integreret del af den moderne AI-verden, der hjælper maskiner med at forstå menneskelige sprog og fortolke dem. NLP-algoritmer er nyttige til forskellige applikationer, fra søgemaskiner og IT til finansiering, markedsføring og mere.
Bortset fra ovenstående detaljer, har jeg også listet nogle af de bedste NLP-kurser og bøger, der vil hjælpe dig med at forbedre din viden om NLP.