
I takt med at virksomheder genererer mere og mere data, bliver den traditionelle tilgang til data warehousing stadig sværere og mere omkostningsfuld at vedligeholde. Data Vault, en relativt ny tilgang til data warehousing, tilbyder en løsning på dette problem ved at tilbyde en skalerbar, agil og omkostningseffektiv måde at håndtere store datamængder på.
I dette indlæg vil vi undersøge, hvordan Data Vaults er fremtiden for data warehousing, og hvorfor flere og flere virksomheder anvender denne tilgang. Vi vil også give læringsressourcer til dem, der ønsker at dykke dybere ned i emnet!
Indholdsfortegnelse
Hvad er Data Vault?
Data Vault er en datavarehusmodelleringsteknik, der er særligt velegnet til agile datavarehuse. Det giver en høj grad af fleksibilitet til udvidelser, en komplet tidsenhedshistorisering af dataene og tillader en stærk parallelisering af dataindlæsningsprocesserne. Dan Linstedt udviklede Data Vault-modellering i 1990’erne.
Efter den første udgivelse i 2000 fik hun større opmærksomhed i 2002 gennem en række artikler. I 2007 vandt Linstedt godkendelsen af Bill Inmon, som beskrev det som det “optimale valg” for hans Data Vault 2.0-arkitektur.
Enhver, der beskæftiger sig med begrebet agilt datavarehus, vil hurtigt ende med Data Vault. Det specielle ved teknologien er, at den er fokuseret på virksomhedernes behov, fordi den muliggør fleksible, lette tilpasninger af et datavarehus.
Data Vault 2.0 overvejer hele udviklingsprocessen og arkitekturen og består af komponenterne metode (implementering), arkitektur og model. Fordelen er, at denne tilgang tager højde for alle aspekter af business intelligence med det underliggende datavarehus under udvikling.
Data Vault-modellen tilbyder en moderne løsning til at overvinde begrænsningerne ved traditionelle datamodelleringstilgange. Med sin skalerbarhed, fleksibilitet og smidighed giver den et solidt grundlag for at bygge en dataplatform, der kan rumme kompleksiteten og mangfoldigheden af moderne datamiljøer.
Data Vaults hub-and-spoke-arkitektur og adskillelse af entiteter og attributter muliggør dataintegration og harmonisering på tværs af flere systemer og domæner, hvilket letter trinvis og agil udvikling.
En afgørende rolle for Data Vault i opbygningen af en dataplatform er at etablere en enkelt kilde til sandhed for alle data. Dens ensartede visning af data og support til indsamling og sporing af historiske dataændringer gennem satellittabeller muliggør overholdelse, revision, lovkrav og omfattende analyse og rapportering.
Data Vaults dataintegrationsmuligheder i næsten realtid via delta-indlæsning letter håndtering af store mængder data i hurtigt skiftende miljøer såsom Big Data og IoT-applikationer.
Data Vault vs. traditionelle datavarehusmodeller
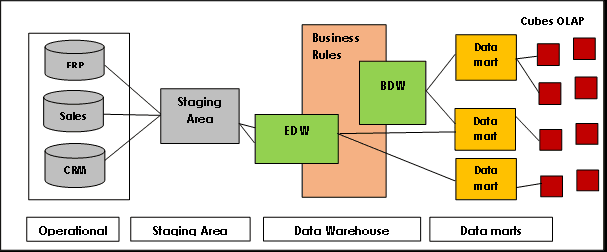
Third-Normal-Form (3NF) er en af de mest kendte traditionelle datavarehusmodeller, som ofte foretrækkes i mange store implementeringer. Dette svarer i øvrigt til ideerne fra Bill Inmon, en af ”forfædrene” til data warehouse-konceptet.
Inmon-arkitekturen er baseret på den relationelle databasemodel og eliminerer dataredundans ved at opdele datakilder i mindre tabeller, der er gemt i data marts og er forbundet med primære og fremmede nøgler. Det sikrer, at data er konsistente og nøjagtige ved at håndhæve regler for referenceintegritet.
Målet med normalformularen var at bygge en omfattende, virksomhedsdækkende datamodel for kernedatavarehuset; det har dog problemer med skalerbarhed og fleksibilitet på grund af stærkt koblede data marts, indlæsningsproblemer i næsten realtidstilstand, besværlige anmodninger og top-down design og implementering.
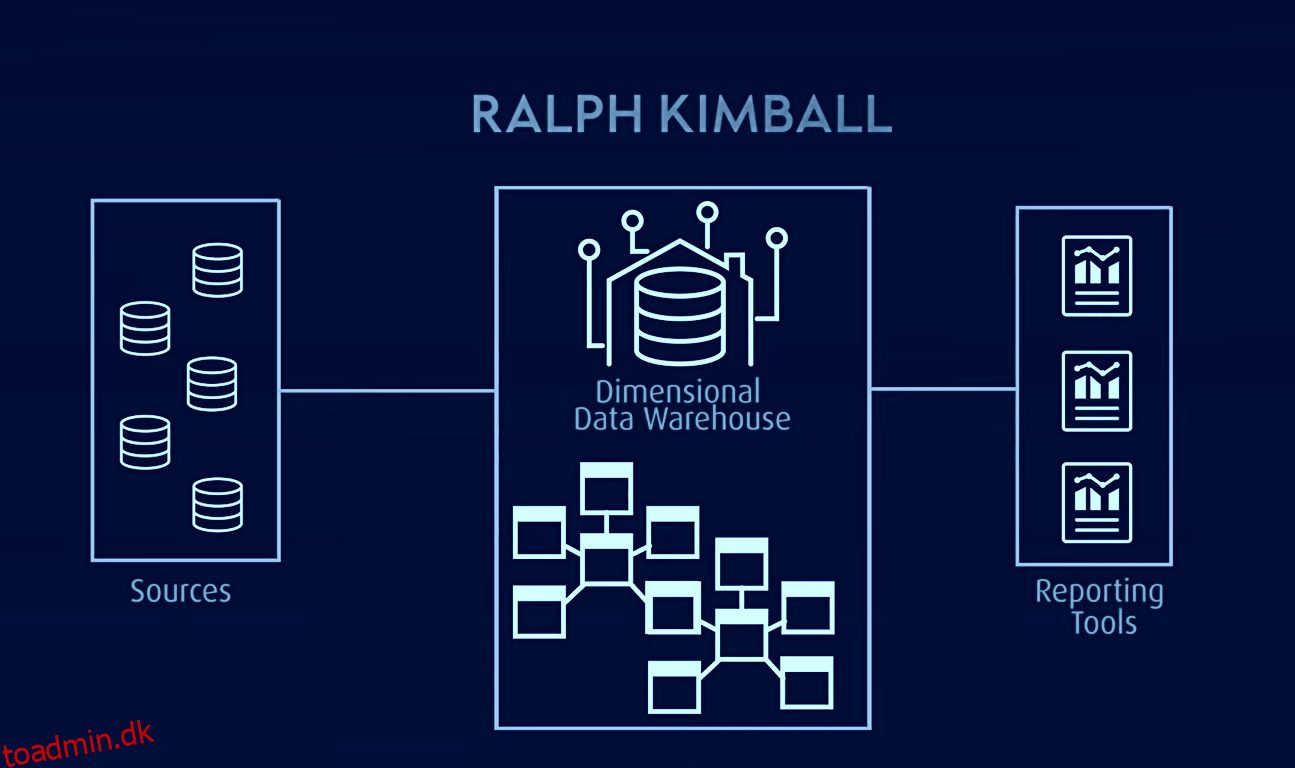
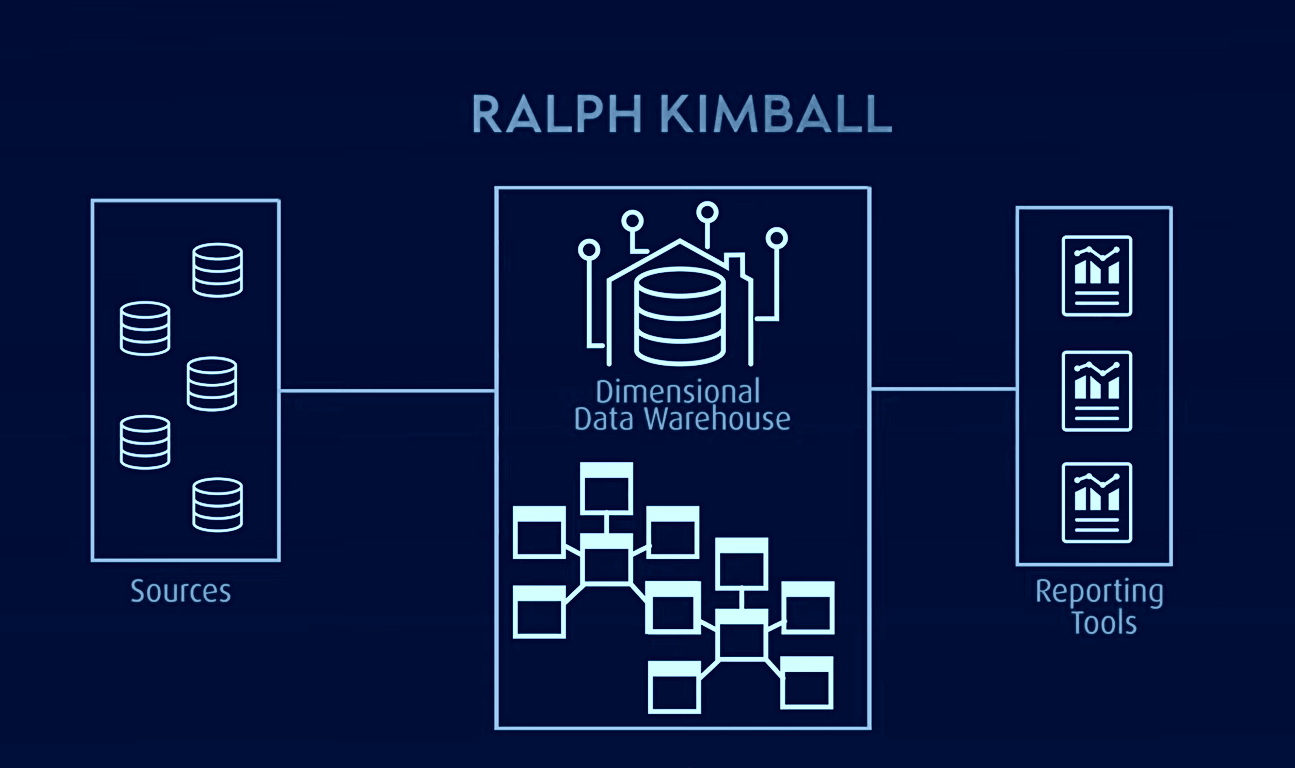
Kimbal-modellen, der bruges til OLAP (online analytical processing) og data marts, er en anden berømt datavarehusmodel, hvor faktatabeller indeholder aggregerede data og dimensionstabeller beskriver lagrede data i et stjerneskema eller snefnugskemadesign. I denne arkitektur er data organiseret i fakta- og dimensionstabeller, der er denormaliseret for at forenkle forespørgsler og analyser.
Kimbal er baseret på en dimensionel model, der er optimeret til forespørgsler og rapportering, hvilket gør den ideel til business intelligence-applikationer. Det har dog haft problemer med isolering af emneorienteret information, dataredundans, inkompatible forespørgselsstrukturer, skalerbarhedsvanskeligheder, den inkonsekvente granularitet af faktatabeller, synkroniseringsproblemer og behovet for top-down design med bottom-up implementering.
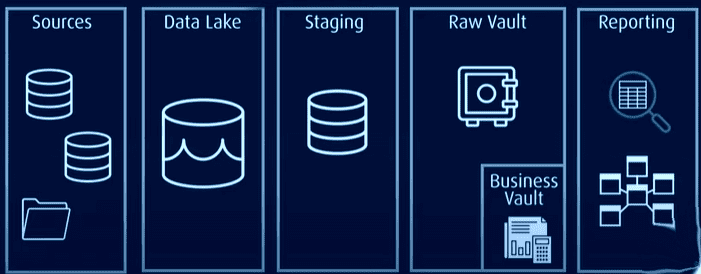
I modsætning hertil er Data vault-arkitektur en hybrid tilgang, der kombinerer aspekter af både 3NF- og Kimball-arkitekturer. Det er en model baseret på relationelle principper, datanormalisering og redundansmatematik, der repræsenterer relationer mellem entiteter forskelligt og strukturerer tabelfelter og tidsstempler forskelligt.
I denne arkitektur er alle data gemt i en rådataboks eller datasø, hvorimod de almindeligt anvendte data lagres i et normaliseret format i en forretningsboks som indeholder historiske og kontekstspecifikke data, der kan bruges til rapportering.
Data Vault løser problemerne i traditionelle modeller ved at være mere effektiv, skalerbar og fleksibel. Det giver mulighed for indlæsning i næsten realtid, bedre dataintegritet og nem udvidelse uden at påvirke eksisterende strukturer. Modellen kan også udvides uden at migrere de eksisterende tabeller.
ModelleringstilgangDatastrukturDesigntilgang3NF-modelleringstabeller i 3NFBottom-upKimbal ModelingStar Schema eller Snowflake SchemaTop-down Data VaultHub-and-SpokeBottom-up
Arkitektur af Data Vault
Data Vault har en hub-and-spoke-arkitektur og består i det væsentlige af tre lag:
Staging Layer: Indsamler de rå data fra kildesystemerne, såsom CRM eller ERP
Data Warehouse Layer: Når det er modelleret som en Data Vault-model, inkluderer dette lag:
- Raw Data Vault: gemmer de rå data.
- Business Data Vault: inkluderer harmoniserede og transformerede data baseret på forretningsregler (valgfrit).
- Metrics Vault: gemmer runtime-oplysninger (valgfrit).
- Operational Vault: gemmer de data, der flyder direkte fra operationelle systemer til datavarehuset (valgfrit.)
Data Mart Layer: Dette lag modellerer data som stjerneskema og/eller andre modelleringsteknikker. Det giver information til analyse og rapportering.
 Billedkilde: Lamia Yessad
Billedkilde: Lamia Yessad
Data Vault kræver ikke en re-arkitektur. Nye funktioner kan bygges parallelt direkte ved hjælp af koncepter og metoder fra Data Vault, og eksisterende komponenter går ikke tabt. Rammer kan gøre arbejdet væsentligt nemmere: De skaber et lag mellem datavarehuset og udvikleren og reducerer dermed kompleksiteten i implementeringen.
Komponenter af Data Vault
Under modellering opdeler Data Vault al information, der hører til objektet, i tre kategorier – i modsætning til klassisk tredje normalformsmodellering. Disse oplysninger opbevares derefter strengt adskilt fra hinanden. De funktionelle områder kan kortlægges i Data Vault i såkaldte hubs, links og satellitter:
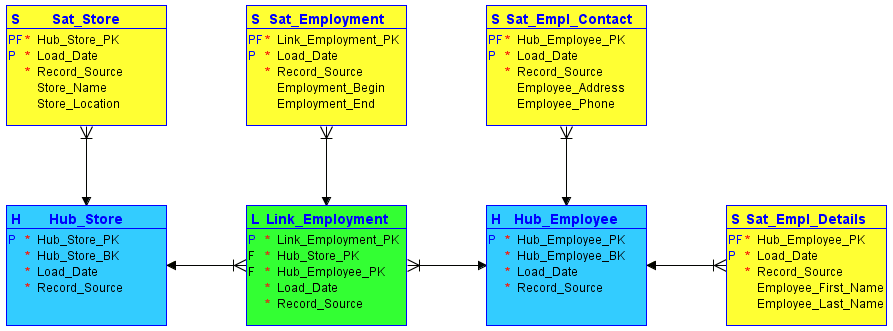
#1. Hubs
Hubs er hjertet i kerneforretningskonceptet, såsom kunde, sælger, salg eller produkt. Hub-tabellen dannes omkring forretningsnøglen (butiksnavn eller lokation), når en ny forekomst af denne forretningsnøgle først introduceres i datavarehuset.
Hubben indeholder ingen beskrivende information og ingen FK’er. Den består kun af forretningsnøglen med en lagergenereret sekvens af ID- eller hashnøgler, indlæsningsdato/tidsstempel og registreringskilde.
#2. Links
Links etablerer relationer mellem forretningsnøglerne. Hver indgang i et link modellerer nm-relationer for et vilkårligt antal hubs. Det giver databoksen mulighed for at reagere fleksibelt på ændringer i kildesystemernes forretningslogik, såsom ændringer i relationernes hjertelighed. Ligesom hub’en indeholder linket ingen beskrivende information. Den består af sekvens-id’erne for de hubs, den refererer til, et lagergenereret sekvens-id, indlæsningsdato/tidsstempel og registreringskilde.
#3. Satellitter
Satellitter indeholder den beskrivende information (kontekst) for en forretningsnøgle, der er gemt i en hub, eller en relation, der er gemt i et link. Satellitter fungerer “kun indsæt”, hvilket betyder, at hele datahistorikken er gemt i satellitten. Flere satellitter kan beskrive en enkelt forretningsnøgle (eller relation). En satellit kan dog kun beskrive én nøgle (hub eller link).
 Billedkilde: Carbidfischer
Billedkilde: Carbidfischer
Sådan bygger du en Data Vault-model
Opbygning af en Data Vault-model involverer flere trin, som hver især er afgørende for at sikre, at modellen er skalerbar, fleksibel og i stand til at opfylde virksomhedens behov:
#1. Identificer enheder og attributter
Identificer forretningsenhederne og deres tilsvarende attributter. Det indebærer at arbejde tæt sammen med virksomhedsinteressenter for at forstå deres krav og de data, de skal indsamle. Når disse enheder og attributter er blevet identificeret, skal du adskille dem i hubs, links og satellitter.
#2. Definer enhedsrelationer og opret links
Når du har identificeret entiteterne og attributterne, defineres relationerne mellem enhederne, og linkene oprettes for at repræsentere disse relationer. Hvert link er tildelt en forretningsnøgle, der identificerer forholdet mellem enhederne. Satellitterne tilføjes derefter for at fange enhedernes attributter og relationer.
#3. Etablere regler og standarder
Efter oprettelse af links bør der etableres et sæt regler og standarder for datahvælvingsmodellering for at sikre, at modellen er fleksibel og kan håndtere ændringer over tid. Disse regler og standarder bør gennemgås og opdateres regelmæssigt for at sikre, at de forbliver relevante og tilpasset virksomhedens behov.
#4. Udfyld modellen
Når modellen er blevet oprettet, skal den udfyldes med data ved hjælp af en trinvis indlæsningsmetode. Det involverer indlæsning af data i hubs, links og satellitter ved hjælp af delta-belastninger. Deltaet indlæses for at sikre, at kun de ændringer, der er foretaget i dataene, indlæses, hvilket reducerer den tid og de ressourcer, der kræves til dataintegration.
#5. Test og valider modellen
Endelig skal modellen testes og valideres for at sikre, at den opfylder forretningskravene og er skalerbar og fleksibel nok til at håndtere fremtidige ændringer. Regelmæssig vedligeholdelse og opdateringer bør udføres for at sikre, at modellen forbliver på linje med virksomhedens behov og fortsætter med at give et samlet overblik over dataene.
Data Vault læringsressourcer
Mastering Data Vault kan give værdifulde færdigheder og viden, der er meget eftertragtet i nutidens datadrevne industrier. Her er en omfattende liste over ressourcer, inklusive kurser og bøger, der kan hjælpe med at lære forviklingerne ved Data Vault:
#1. Modellering af datavarehus med Data Vault 2.0

Dette Udemy-kursus er en omfattende introduktion til Data Vault 2.0-modelleringstilgangen, Agile projektledelse og Big Data-integration. Kurset dækker det grundlæggende og grundlæggende i Data Vault 2.0, herunder dets arkitektur og lag, forretnings- og informationshvælvinger og avancerede modelleringsteknikker.
Det lærer dig, hvordan du designer en Data Vault-model fra bunden, konverterer traditionelle modeller som 3NF og dimensionelle modeller til Data Vault og forstår principperne for dimensionsmodellering i Data Vault. Kurset kræver grundlæggende kendskab til databaser og SQL fundamentals.
Med en høj vurdering på 4,4 ud af 5 og over 1.700 anmeldelser er dette bedst sælgende kursus velegnet til alle, der ønsker at bygge et stærkt fundament i Data Vault 2.0 og Big Data-integration.
#2. Data Vault-modellering forklaret med use case

Dette Udemy-kursus er rettet mod at vejlede dig i at opbygge en Data Vault Model ved hjælp af et praktisk forretningseksempel. Den fungerer som en begyndervejledning til Data Vault-modellering, der dækker nøglebegreber som de passende scenarier til brug af Data Vault-modeller, begrænsningerne ved konventionel OLAP-modellering og en systematisk tilgang til at konstruere en Data Vault-model. Kurset er tilgængeligt for personer med minimal databaseviden.
#3. Data Vault Guru: en pragmatisk guide
The Data Vault Guru af Mr. Patrick Cuba er en omfattende guide til datavault-metodologien, som giver en unik mulighed for at modellere virksomhedens datavarehus ved hjælp af automatiseringsprincipper svarende til dem, der bruges i softwarelevering.
Bogen giver et overblik over moderne arkitektur og giver derefter en grundig guide til, hvordan man leverer en fleksibel datamodel, der tilpasser sig ændringer i virksomheden, datahvælvingen.
Derudover udvider bogen datahvælvingsmetodologien ved at levere automatiseret tidslinjekorrektion, revisionsspor, metadatakontrol og integration med agile leveringsværktøjer.
#4. Opbygning af et skalerbart datavarehus med Data Vault 2.0
Denne bog giver læserne en omfattende guide til at skabe et skalerbart datavarehus fra start til slut ved hjælp af Data Vault 2.0-metoden.
Denne bog dækker alle de væsentlige aspekter af opbygningen af et skalerbart datavarehus, inklusive Data Vault-modelleringsteknikken, som er designet til at forhindre typiske datavarehusfejl.
Bogen indeholder adskillige eksempler for at hjælpe læserne med at forstå begreberne klart. Med dens praktiske indsigt og eksempler fra den virkelige verden er denne bog en vigtig ressource for alle, der er interesseret i data warehousing.
#5. Elefanten i køleskabet: Vejledte trin til Data Vault-succes
The Elephant in the Fridge af John Giles er en praktisk guidebog, der har til formål at hjælpe læsere med at opnå Data Vault-succes ved at starte med virksomheden og slutte med virksomheden.
Bogen fokuserer på vigtigheden af virksomhedsontologi og forretningskonceptmodellering og giver trin-for-trin vejledning i, hvordan man anvender disse begreber til at skabe en solid datamodel.
Gennem praktiske råd og eksempler på mønstre giver forfatteren en klar og ukompliceret forklaring af komplicerede emner, hvilket gør bogen til en fremragende guide for dem, der er nye til Data Vault.
Afsluttende ord
Data Vault repræsenterer fremtiden for data warehousing, og tilbyder virksomheder betydelige fordele med hensyn til smidighed, skalerbarhed og effektivitet. Det er særligt velegnet til virksomheder, der har brug for at indlæse store mængder data hurtigt, og dem, der ønsker at udvikle deres business intelligence-applikationer på en agil måde.
Ydermere kan virksomheder, der har en eksisterende siloarkitektur, have stor gavn af at implementere et upstream kernedatavarehus ved hjælp af Data Vault.
Du kan også være interesseret i at lære om datalinjen.