
Inden for moderne kunstig intelligens (AI) er reinforcement learning (RL) et af de fedeste forskningsemner. Udviklere af kunstig intelligens og maskinlæring (ML) fokuserer også på RL-praksis for at improvisere intelligente apps eller værktøjer, de udvikler.
Maskinlæring er princippet bag alle AI-produkter. Menneskelige udviklere bruger forskellige ML-metoder til at træne deres intelligente apps, spil osv. ML er et meget diversificeret felt, og forskellige udviklingsteams kommer med nye metoder til at træne en maskine.
En sådan lukrativ metode til ML er dyb forstærkningslæring. Her straffer du uønsket maskinadfærd og belønner ønskede handlinger fra den intelligente maskine. Eksperter mener, at denne ML-metode er bundet til at skubbe AI til at lære af sine egne erfaringer.
Fortsæt med at læse denne ultimative guide om forstærkende læringsmetoder til intelligente apps og maskiner, hvis du overvejer en karriere inden for kunstig intelligens og maskinlæring.
Indholdsfortegnelse
Hvad er forstærkningslæring i maskinlæring?
RL er undervisning i maskinlæringsmodeller til computerprogrammer. Derefter kan applikationen træffe en række beslutninger baseret på læringsmodellerne. Softwaren lærer at nå et mål i et potentielt komplekst og usikkert miljø. I denne form for maskinlæringsmodel står en AI over for et spillignende scenario.
AI-appen bruger forsøg og fejl til at opfinde en kreativ løsning på det aktuelle problem. Når AI-appen lærer de rigtige ML-modeller, instruerer den den maskine, den styrer, om at udføre nogle opgaver, som programmøren ønsker.
Baseret på den korrekte beslutning og opgaveafslutning får AI en belønning. Men hvis AI’en træffer forkerte valg, står den over for sanktioner, som at miste belønningspoint. Det ultimative mål for AI-applikationen er at akkumulere det maksimale antal belønningspoint for at vinde spillet.
Programmøren af AI-appen fastsætter spillereglerne eller belønningspolitikken. Programmøren giver også det problem, som AI skal løse. I modsætning til andre ML-modeller modtager AI-programmet ikke noget tip fra softwareprogrammøren.
AI skal finde ud af, hvordan man løser spiludfordringerne for at tjene maksimale belønninger. Appen kan bruge trial and error, tilfældige forsøg, supercomputerfærdigheder og sofistikerede tankeprocesser til at nå frem til en løsning.
Du skal udstyre AI-programmet med kraftfuld computerinfrastruktur og forbinde dets tænkesystem med forskellige parallelle og historiske gameplay. Derefter kan AI demonstrere kritisk kreativitet på højt niveau, som mennesker ikke kan forestille sig.
Populære eksempler på forstærkningslæring
#1. Besejre den bedste Human Go-spiller
AlphaGo AI fra DeepMind Technologies, et datterselskab af Google, er et af de førende eksempler på RL-baseret maskinlæring. AI’en spiller et kinesisk brætspil kaldet Go. Det er et 3.000 år gammelt spil, der fokuserer på taktik og strategier.
Programmørerne brugte RL-metoden til undervisning for AlphaGo. Den spillede tusindvis af Go-spilsessioner med mennesker og sig selv. Derefter besejrede den i 2016 verdens bedste Go-spiller Lee Se-dol i en en-mod-en kamp.
#2. Real-World Robotics
Mennesker har længe brugt robotteknologi i produktionslinjer, hvor opgaverne er forudplanlagte og gentagne. Men hvis du skal lave en generel robot til den virkelige verden, hvor handlinger ikke er planlagt på forhånd, så er det en stor udfordring.
Men forstærkende læringsaktiveret AI kunne opdage en jævn, navigerbar og kort rute mellem to lokationer.
#3. Selvkørende køretøjer
Autonome køretøjsforskere bruger i vid udstrækning RL-metoden til at lære deres AI’er til:
- Dynamisk pathing
- Baneoptimering
- Bevægelsesplanlægning som parkering og vognbaneskift
- Optimering af controllere, (elektronisk styreenhed) ECU’er, (mikrocontrollere) MCU’er mv.
- Scenariebaseret læring på motorveje
#4. Automatiserede kølesystemer

RL-baserede AI’er kan hjælpe med at minimere energiforbruget af kølesystemer i gigantiske kontorbygninger, forretningscentre, indkøbscentre og, vigtigst af alt, datacentre. AI’en indsamler data fra tusindvis af varmesensorer.
Den indsamler også data om menneskelige og maskinelle aktiviteter. Ud fra disse data kan AI forudse det fremtidige varmeproduktionspotentiale og tænder og slukker passende kølesystemer for at spare energi.
Sådan opsætter du en forstærkningslæringsmodel
Du kan opsætte en RL-model baseret på følgende metoder:
#1. Politikbaseret
Denne tilgang gør det muligt for AI-programmøren at finde den ideelle politik for maksimale belønninger. Her bruger programmøren ikke værdifunktionen. Når du har indstillet den politikbaserede metode, forsøger forstærkningslæringsagenten at anvende politikken, så de handlinger, den udfører i hvert trin, sætter AI i stand til at maksimere belønningspointene.
Der er primært to typer politikker:
#1. Deterministisk: Politikken kan producere de samme handlinger i enhver given stat.
#2. Stokastisk: De producerede handlinger bestemmes af sandsynligheden for forekomst.
#2. Værdibaseret
Den værdibaserede tilgang hjælper tværtimod programmøren med at finde den optimale værdifunktion, som er den maksimale værdi under en politik i en given stat. Når den er påført, forventer RL-agenten det langsigtede afkast i en eller flere stater under den nævnte politik.
#3. Modelbaseret
I den modelbaserede RL-tilgang skaber AI-programmøren en virtuel model for miljøet. Derefter bevæger RL-agenten sig rundt i miljøet og lærer af det.
Typer af forstærkningslæring
#1. Positiv forstærkningslæring (PRL)
Positiv læring betyder at tilføje nogle elementer for at øge sandsynligheden for, at den forventede adfærd vil ske igen. Denne indlæringsmetode påvirker RL-agentens adfærd positivt. PRL forbedrer også styrken af visse adfærd i din AI.
PRL-type for læringsforstærkning bør forberede AI til at tilpasse sig ændringer i lang tid. Men indsprøjtning af for meget positiv læring kan føre til en overbelastning af stater, der kan reducere AI’ens effektivitet.

#2. Negativ forstærkningslæring (NRL)
Når RL-algoritmen hjælper AI med at undgå eller stoppe en negativ adfærd, lærer den af den og forbedrer sine fremtidige handlinger. Det er kendt som negativ læring. Det giver kun AI en begrænset intelligens bare for at opfylde visse adfærdskrav.
Real-Life Use Cases of Reinforcement Learning
#1. Udviklere af e-handelsløsninger har bygget personlige produkter eller tjenester, der foreslår værktøjer. Du kan forbinde værktøjets API til din online shoppingside. Derefter vil AI lære af individuelle brugere og foreslå tilpassede varer og tjenester.
#2. Open-world videospil kommer med uendelige muligheder. Der er dog et AI-program bag spilprogrammet, som lærer af spillernes input og modificerer videospilkoden, så den tilpasser sig en ukendt situation.
#3. AI-baserede aktiehandels- og investeringsplatforme bruger RL-modellen til at lære af aktiernes bevægelser og globale indekser. Derfor formulerer de en sandsynlighedsmodel til at foreslå aktier til investering eller handel.
#4. Online videobiblioteker som YouTube, Metacafe, Dailymotion osv. bruger AI-bots, der er trænet på RL-modellen, til at foreslå personlige videoer til deres brugere.
Forstærkningslæring vs. Superviseret læring
Forstærkende læring sigter mod at træne AI-agenten til at træffe beslutninger sekventielt. I en nøddeskal kan du overveje, at outputtet af AI afhænger af tilstanden af det nuværende input. På samme måde vil det næste input til RL-algoritmen afhænge af outputtet fra de tidligere input.

En AI-baseret robotmaskine, der spiller et spil skak mod en menneskelig skakspiller, er et eksempel på RL-maskinlæringsmodellen.
Tværtimod, i overvåget læring træner programmøren AI-agenten til at træffe beslutninger baseret på de input, der blev givet ved starten eller enhver anden indledende input. Autonome bilkørsel AI’er, der genkender miljøobjekter, er et glimrende eksempel på overvåget læring.
Forstærkningslæring vs. Uovervåget læring
Indtil videre har du forstået, at RL-metoden presser AI-agenten til at lære af maskinlæringsmodelpolitikker. Hovedsageligt vil AI kun lave de trin, som den får maksimale belønningspoint for. RL hjælper en AI med at improvisere sig selv gennem forsøg og fejl.
På den anden side, i uovervåget læring, introducerer AI-programmøren AI-softwaren med umærkede data. ML-instruktøren fortæller heller ikke AI’en noget om datastrukturen eller hvad man skal kigge efter i dataene. Algoritmen lærer forskellige beslutninger ved at katalogisere sine egne observationer på de givne ukendte datasæt.
Forstærkende læringskurser
Nu hvor du har lært det grundlæggende, er her nogle onlinekurser til at lære avanceret forstærkningslæring. Du får også et certifikat, som du kan fremvise på LinkedIn eller andre sociale platforme:
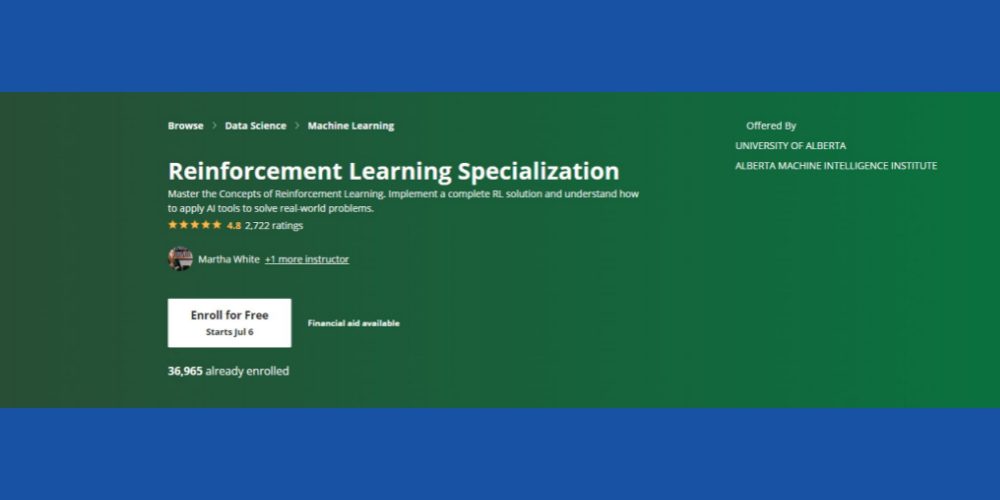
Forstærkningslæringsspecialisering: Coursera
Ønsker du at mestre kernekoncepterne for forstærkende læring med ML-kontekst? Du kan prøve dette Coursera RL kursus som er tilgængelig online og leveres med lærings- og certificeringsmulighed i eget tempo. Kurset vil være egnet for dig, hvis du medbringer følgende som baggrundsevner:
- Programmering viden i Python
- Grundlæggende statistiske begreber
- Du kan konvertere pseudokoder og algoritmer til Python-koder
- To til tre års erfaring med softwareudvikling
- Andetårs bachelorer i datalogi disciplin er også berettigede
Kurset har en rating på 4,8 stjerner, og over 36.000 studerende har allerede tilmeldt sig kurset i forskellige tidsforløb. Desuden leveres kurset med økonomisk støtte, forudsat at kandidaten opfylder visse berettigelseskriterier for Coursera.
Endelig tilbyder Alberta Machine Intelligence Institute ved University of Alberta dette kursus (ingen kredit tildelt). Kærede professorer inden for datalogi vil fungere som dine kursusinstruktører. Du opnår et Coursera-certifikat, når du har gennemført kurset.
AI Reinforcement Learning i Python: Udemy
Hvis du er til det finansielle marked eller digital markedsføring og ønsker at udvikle intelligente softwarepakker til de nævnte områder, skal du tjekke dette ud Udemy kursus om RL. Udover kerneprincipperne i RL, vil træningsindholdet også coache dig i, hvordan du udvikler RL-løsninger til online annoncering og aktiehandel.

Nogle bemærkelsesværdige emner, som kurset dækker, er:
- Et overblik over RL på højt niveau
- Dynamisk programmering
- Monet Carlo
- Tilnærmelsesmetoder
- Aktiehandelsprojekt med RL
Over 42.000 studerende har deltaget i kurset indtil videre. Online læringsressourcen har i øjeblikket en 4,6-stjernet rating, hvilket er ret imponerende. Desuden sigter kurset mod at henvende sig til et globalt studenterfællesskab, da læringsindholdet er tilgængeligt på fransk, engelsk, spansk, tysk, italiensk og portugisisk.
Deep Reinforcement Learning i Python: Udemy
Hvis du har nysgerrighed og grundlæggende viden om dyb læring og kunstig intelligens, kan du prøve denne avancerede RL kursus i Python fra Udemy. Med en bedømmelse på 4,6 stjerner fra studerende er det endnu et populært kursus at lære RL i forbindelse med AI/ML.

Kurset har 12 sektioner og dækker følgende vitale emner:
- OpenAI Gym og grundlæggende RL-teknikker
- TD Lambda
- A3C
- Theano Grundlæggende
- Grundlæggende om Tensorflow
- Python-kodning til at begynde med
Hele kurset vil kræve en engageret investering på 10 timer og 40 minutter. Udover tekster kommer den også med 79 ekspertforelæsningssessioner.
Deep Reinforcement Learning Expert: Udacity
Vil du lære avanceret maskinlæring fra verdens førende inden for AI/ML som Nvidia Deep Learning Institute og Unity? Udacity lader dig opfylde din drøm. Tjek dette ud Dyb forstærkningslæring kursus for at blive ML-ekspert.

Du skal dog komme fra en baggrund af avanceret Python, mellemstatistik, sandsynlighedsteori, TensorFlow, PyTorch og Keras.
Det vil tage flittig læring på op til 4 måneder at gennemføre kurset. Gennem hele kurset vil du lære vitale RL-algoritmer som Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) osv.
Afsluttende ord
Forstærkende læring er næste skridt i AI-udvikling. AI-udviklingsbureauer og it-virksomheder vælter ind med investeringer i denne sektor for at skabe pålidelige og pålidelige AI-træningsmetoder.
Selvom RL har avanceret meget, er der flere udviklingsområder. For eksempel deler separate RL-agenter ikke viden mellem sig. Derfor, hvis du træner en app til at køre bil, vil læreprocessen blive langsom. Fordi RL-agenter som objektdetektering, vejreferencer osv. ikke deler data.
Der er muligheder for at investere din kreativitet og ML-ekspertise i sådanne udfordringer. Tilmelding til onlinekurser vil hjælpe dig med at fremme din viden om avancerede RL-metoder og deres anvendelser i projekter i den virkelige verden.
En anden relateret læring for dig er forskellene mellem AI, Machine Learning og Deep Learning.