
Database-sharding er en teknik til at opnå horisontal skalerbarhed i store systemer.
Næsten alle systemer i den virkelige verden består af en databaseserver, der modtager en masse læseanmodninger og en ikke ubetydelig mængde skriveanmodninger. Dette kan overbelaste serveren og hæmme systemets ydeevne.
For at afbøde sådanne påvirkninger og forbedre ydeevnen af et system er der tilgange som databasereplikering og databasesharding. I denne vejledning vil vi først udforske teknikker til at forbedre systemets ydeevne, herunder:
- Opskalering af databaseserveren
- Database replikering
- Vandret opdeling
Efter at have diskuteret disse teknikker, vil vi fortsætte med at lære, hvordan databasesharding fungerer og også se på fordelene og begrænsningerne ved denne tilgang.
Lad os begynde!
Indholdsfortegnelse
Teknikker til at forbedre systemets ydeevne
Lad os starte med at diskutere teknikker til at forbedre systemets ydeevne, når der er flaskehalse på grund af databaseserveren:
#1. Opskalering af databaseserveren
Opskalering af databaseserverforekomsten kan virke som en ligetil tilgang til at forbedre systemets ydeevne. Dette inkluderer forbedring af processorkraft, tilføjelse af mere RAM og lignende.
Denne teknik kommer dog med følgende begrænsning. Vi kan ikke have en server med uendelig lager- og processorkraft. Og ud over en vis grænse får vi faldende afkast.
#2. Databasereplikering
Når databaseserverforekomsten overbelastning opstår på grund af indgående anmodninger, kan vi overveje databasereplikering.
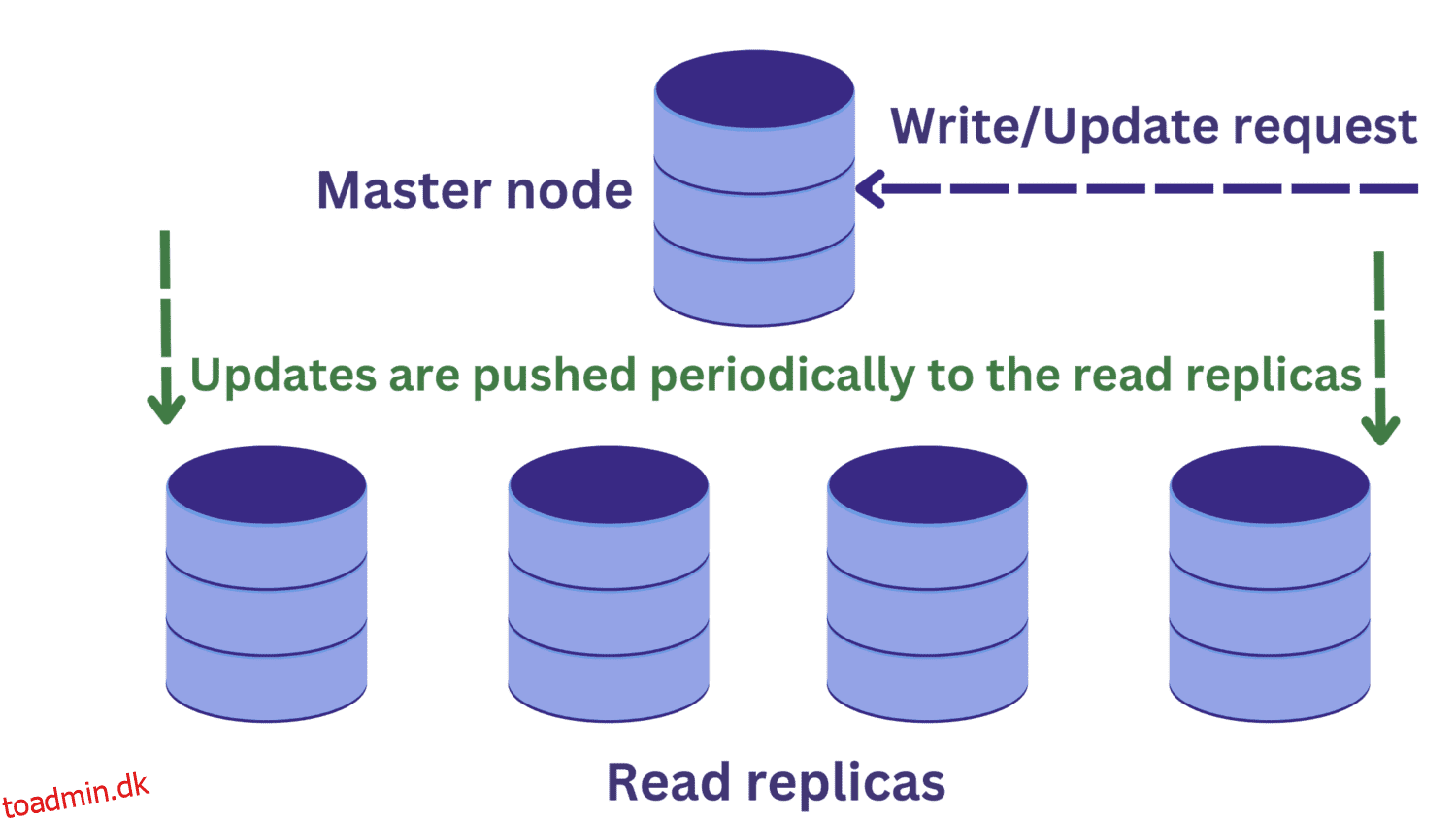
Under databasereplikering har vi én masterknude, der typisk modtager skriveanmodninger. Der er flere læste replikaer.
Dette forbedrer tilgængeligheden og mindsker systemoverbelastning. Vi kan nu behandle flere forespørgsler parallelt, da læseanmodningerne kan dirigeres til en af læsereplikaerne.
Men dette introducerer et andet problem. Skriveanmodninger til masterknudepunktet kan ændre dataene, og disse opdateringer udbredes med jævne mellemrum til læsereplikaerne.
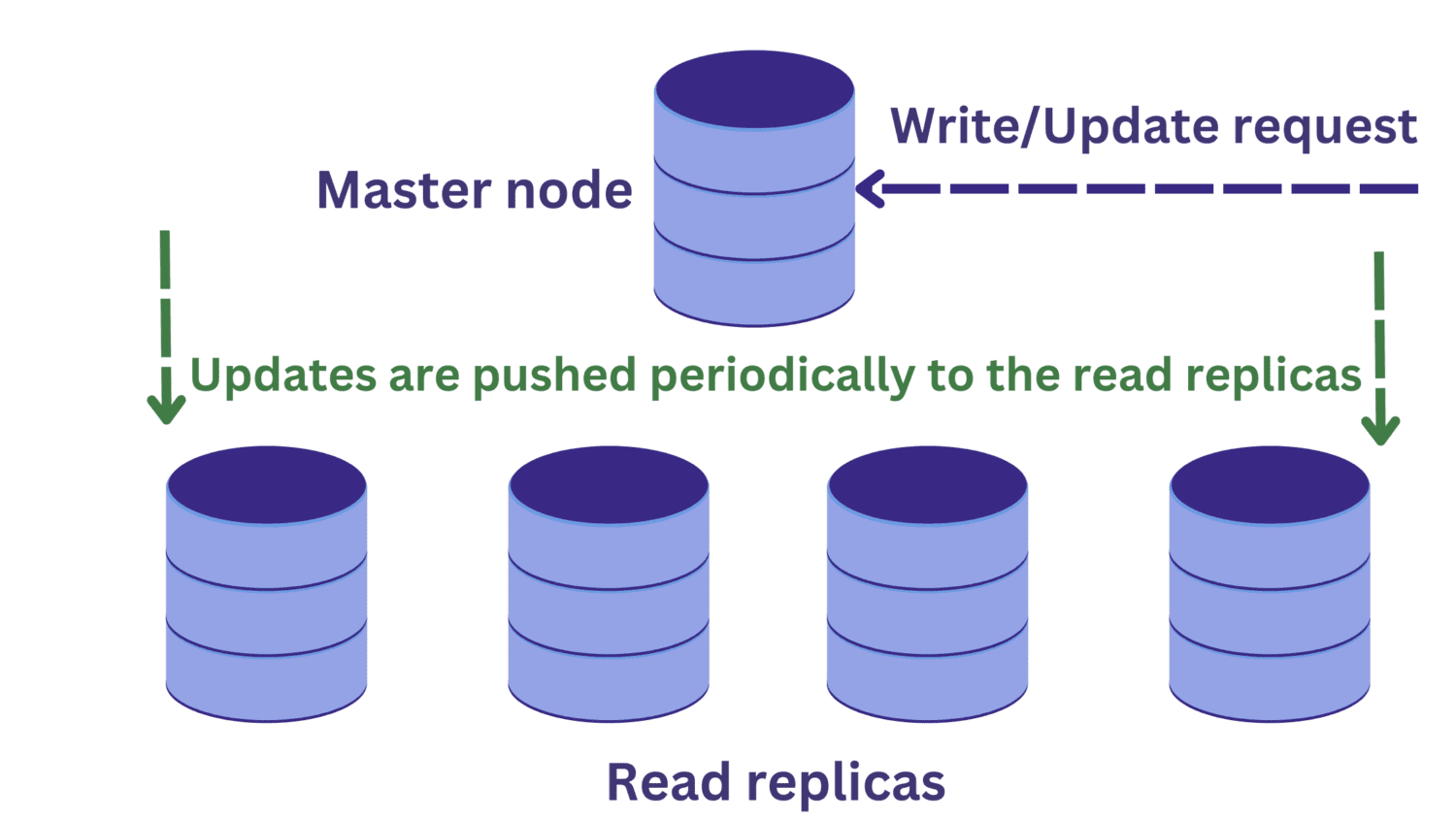
Antag, at der er en læseanmodning til en af læsereplikaerne, samtidig med at en skriveoperation er i gang på masterknudepunktet.
Ændringerne i masterknuden vil endnu ikke have spredt sig til de læste replikaer. I dette tilfælde kan vi læse forældede data, hvilket ikke er ønskeligt.
#3. Vandret opdeling
Vandret partitionering er en anden teknik til at optimere systemets ydeevne. Vi kan have en enkelt stor tabel med milliarder af rækker (såsom en tabel over kunder og transaktionsdata).
Læseoperationerne fra en sådan databasetabel er langsommere. Men ved at bruge horisontal partitionering er den enkelte store tabel nu opdelt i flere partitioner (eller mindre tabeller), som vi kan læse fra. Relationelle databaser såsom PostgreSQL understøtter indbygget partitionering.
Alle partitionerne er dog stadig inde i en enkelt databaseserverinstans. Den eneste forskel er, at vi nu kan læse fra partitionerne i stedet for den enkelte store tabel.
Derfor, når der er en stigning i antallet af indgående anmodninger, er serveren muligvis ikke i stand til at understøtte den øgede efterspørgsel.
Hvordan fungerer databasedeling?
Nu hvor vi har diskuteret tilgangene til at forbedre systemets ydeevne og deres begrænsninger, lad os forstå, hvordan databasesharding fungerer.
Ved sharding opdeler vi den enkelte store database i flere mindre databaser, der hver kører på en databaseserverinstans. Hver sådan mindre database kaldes et skår. Og hvert shard indeholder en unik delmængde af dataene.
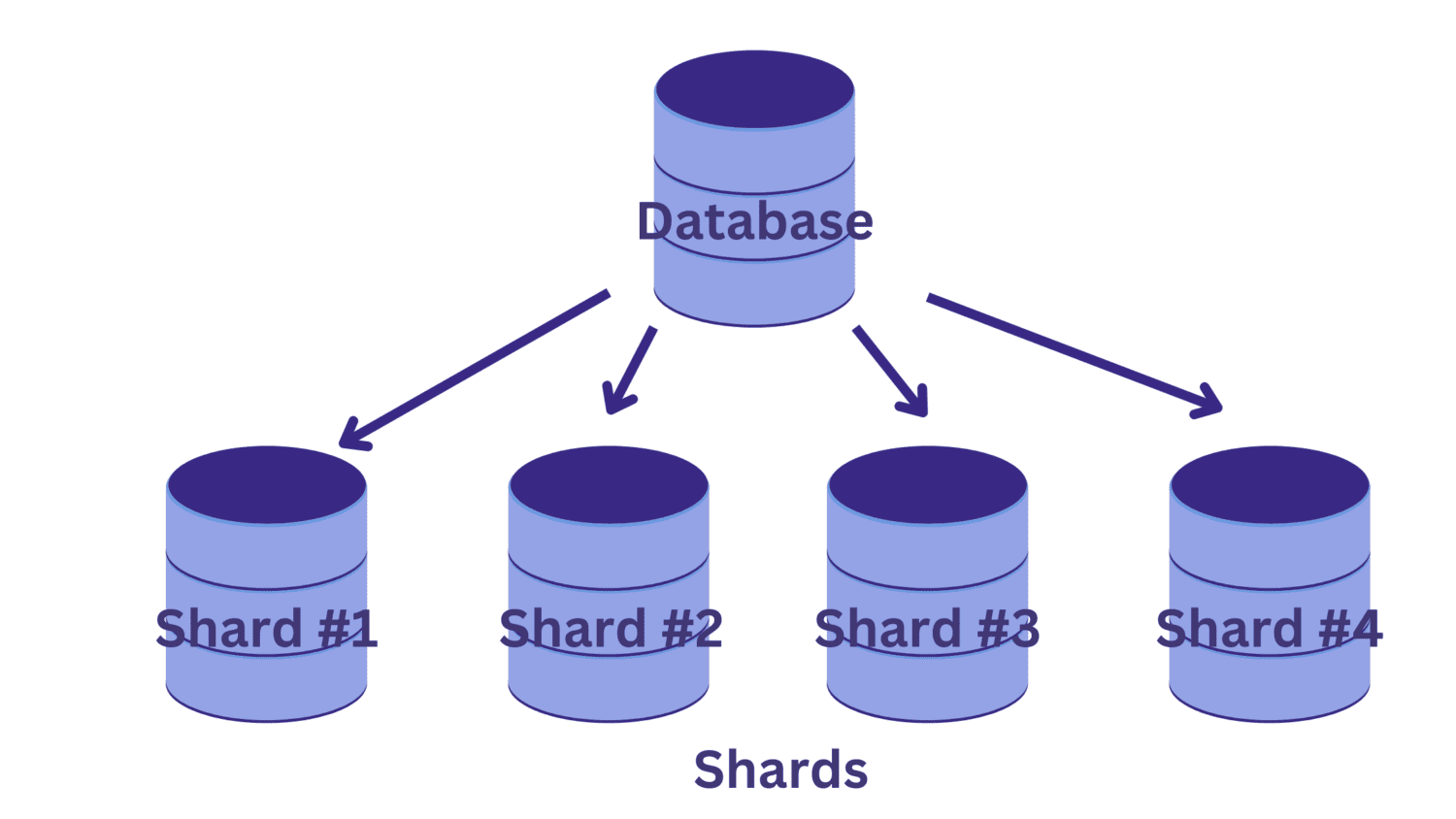
Men hvordan opdeler vi databasen i shards? Og hvordan bestemmer vi, hvilken af rækkerne der går ind i hvilken af skårene?
🔑 Indtast sønderdelingsnøglen.
Forstå Sharding Key
Lad os forstå rollen som skæringsnøglen.
Sønderdelingsnøglen, som normalt er en kolonne (eller en kombination af kolonner) i databasetabellen, skal vælges således, at fordelingen af data er jævn på tværs af flere shards. For vi ønsker ikke, at et bestemt skær skal være meget større end de andre skærver.
I en database, der gemmer data om kunder og transaktioner, er customer_ID en god kandidat til sharding-nøglen.
Når vi har besluttet os for sharding-nøglen, kan vi komme med en hashing-funktion, der bestemmer, hvilken af rækkerne der går ind i hvilken af shards.
I dette eksempel skal vi sige, at vi skal opdele databasen i fem shards (shard #0 til shard #4) ved at bruge customer_ID som sharding-nøgle. I dette tilfælde er en simpel hashfunktion kunde_ID % 5.
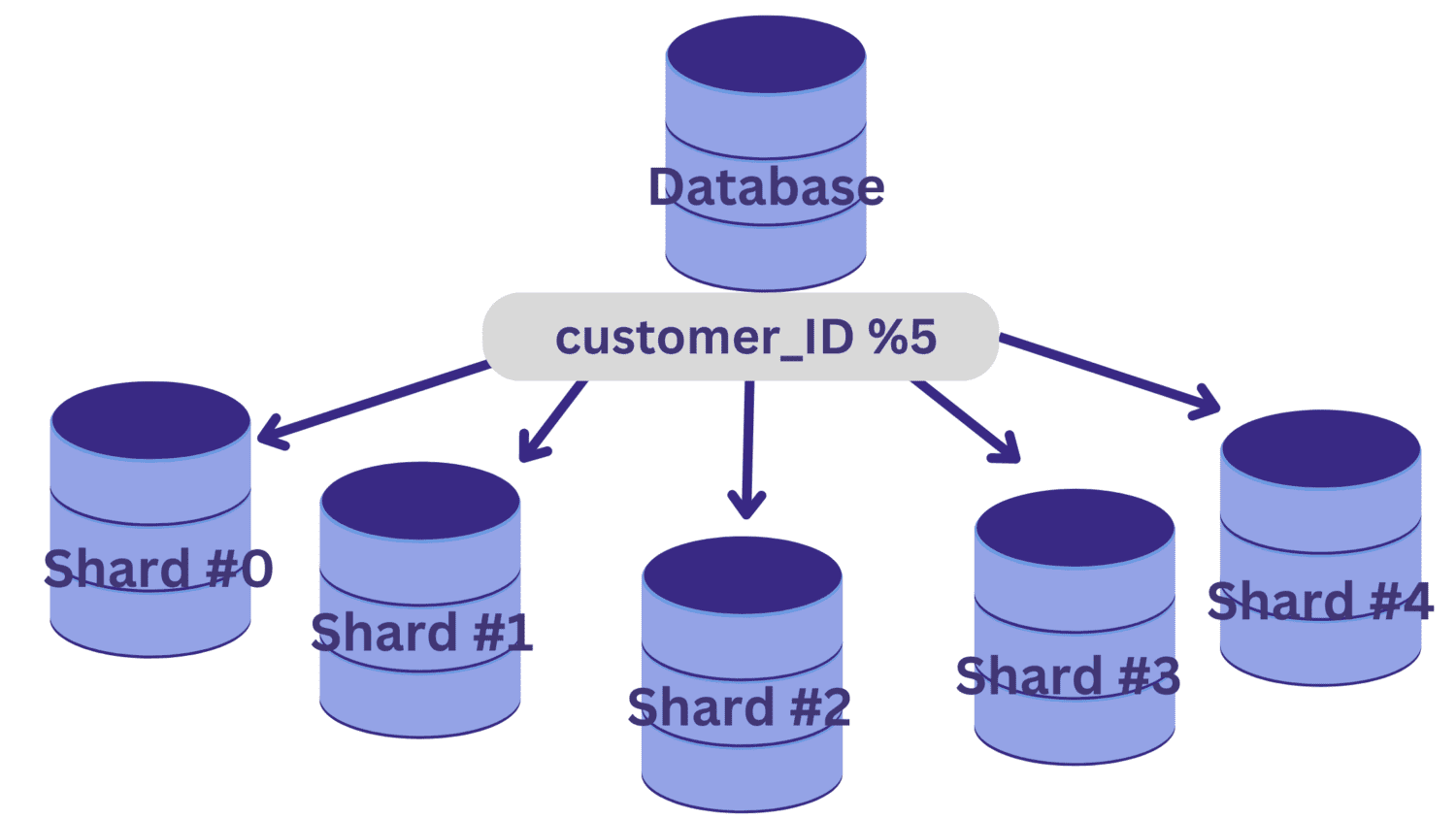
Alle customer_ID-værdier, der efterlader en rest på nul, når de divideres med 5, vil blive knyttet til shard #0. Og customer_ID-værdier, der efterlader resterne 1 til 4, vil blive knyttet til henholdsvis shard #1 til shard #4.
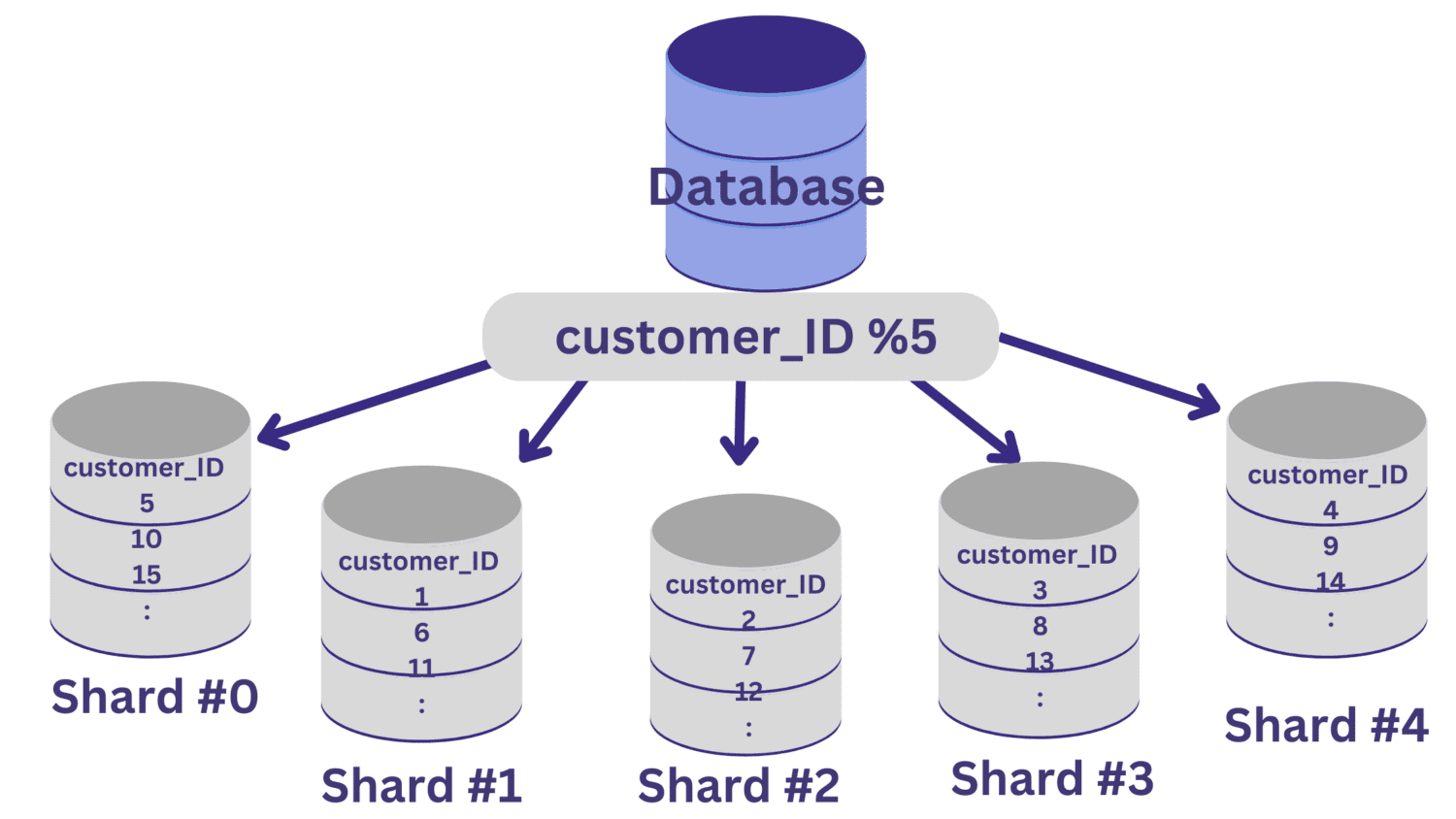
Efter at databasesharding er implementeret på denne måde, er det vigtigt at have et routinglag, der dirigerer de indkommende anmodninger til det korrekte databaseshard.
Fordele ved Database Sharing
Her er nogle af fordelene ved databaseskæring:
#1. Høj skalerbarhed
Det er altid muligt at dele en større database i flere mindre shards. Så databasesharding giver os mulighed for at skalere ud horisontalt.
#2. Høj tilgængelighed
Når der er en enkelt databaseserverinstans, der håndterer alle de indkommende anmodninger, har vi et enkelt fejlpunkt. Hvis databaseserveren er nede, er hele applikationen nede.
Med database sharding er sandsynligheden for, at alle database shards er nede på et givet øjeblik, relativt lav. Derfor, hvis et bestemt shard er nede, vil vi ikke være i stand til at behandle læseanmodninger til det shard. Men de andre shards kan stadig behandle de indkommende anmodninger. Dette resulterer i høj tilgængelighed og øget fejltolerance.
Begrænsninger af databasedeling
Lad os nu gennemgå nogle af begrænsningerne ved databaseskæring:
#1. Kompleksitet
Selvom sharding har fordele med hensyn til skalerbarhed og fejltolerance, introducerer det kompleksitet til systemet.
Fra kortlægning af poster til partitioner til implementering af routinglaget til at dirigere forespørgsler til de respektive shards, er der betydelig kompleksitet involveret i sharding af databaser.
#2. Omskæring
En anden begrænsning ved skæring er behovet for omskæring.
Selvom vi bruger hashing-funktion til at få en jævn fordeling af dataposter, er det muligt, at et af shards er meget større end de andre shards, og det kan blive udtømt hurtigere. I dette tilfælde skal vi tage højde for omdeling (eller omfordeling), og det kommer med betydelige omkostninger.
#3. Kørsel af komplekse forespørgsler
Når du skal køre forespørgsler til analyse, der involverer joinforbindelser, skal du bruge poster fra flere shards i modsætning til en enkelt database. Så dette kan være en udfordring, når du skal køre for mange analytiske forespørgsler. Du kan komme uden om dette ved at denormalisere databaser, men det kræver stadig en indsats!
Konklusion
Lad os afslutte diskussionen med et resumé af, hvad vi har lært.
Opskalering af hardwaren er ikke altid optimal. Så det anbefales ikke at styrke serverforekomsten. Vi gennemgik også teknikker som databasereplikering og horisontal partitionering og deres begrænsninger.
Derefter lærte vi, hvordan databasesharding fungerer ved at opdele en stor database i mindre og nemme at administrere shards. Vi diskuterede, hvordan sharding-nøglen bør vælges omhyggeligt for at få lige partitioner og behovet for et routing-lag til at dirigere de indkommende anmodninger til den korrekte database shard.
Database-sharding har fordele såsom høj tilgængelighed og skalerbarhed. Nogle af ulemperne omfatter kompleksiteten ved at opsætte sharding og resharding, når et eller flere shards bliver opbrugt.
Så du kan overveje sharding, når du mener, at fordelene opvejer kompleksiteten, som sharding introducerer. Tjek derefter sammenligningen af de forskellige AWS relationelle databaser.