

En disaster recovery plan er en fornemste foranstaltning, som en organisation skal have, før en usædvanlig begivenhed rammer dem.
I IT-branchen starter det med at skabe et formelt dokument, der indeholder planer, handlinger og procedurer for håndtering af katastrofen og dens eftervirkninger.
Katastrofe er en begivenhed, der kommer pludseligt uden forudgående varsel og kan være af forskellige typer. Og når det lander, står enkeltpersoner og organisationer over for vanskeligheder af mange slags, herunder økonomiske problemer og brugeroplevelse.
Hvis der sker et angreb, skal du være klar til at minimere virkningerne og genoprette dine operationer hurtigere. Det er her, at udarbejdelse af en praktisk katastrofe genopretningsplan vil hjælpe dig med at tilbageholde eller forhindre katastrofen. Du kan også reducere dets eftervirkninger med hensyn til brugeroplevelse, omkostninger og nedetid.
Derudover skal du holde dine planer, mennesker, strategier, udstyr og systemer klar for at få alt tilbage i aktion. Men for dette skal du forstå katastrofeopsving i dybden.
I denne artikel vil jeg diskutere dette i detaljer sammen med vigtige terminologier for gendannelse af katastrofer, så du kan kæmpe modigt tilbage og komme stærkere ud under sådanne ugunstige forhold.
Lad os begynde!
Indholdsfortegnelse
Hvad er en katastrofe?
En katastrofe er en uforudset begivenhed, der kan ske overalt, inklusive IT-branchen. Det opstår enten naturligt eller af mennesker og kan forstyrre en virksomheds drift og forstyrre strukturen i infrastrukturen.
Som følge heraf påvirkes en organisation og dens kunder, leverandører, medarbejdere og partnere. Det lægger pres på organisationen med hensyn til økonomi, branchens omdømme, kundetillid og sikkerhedsomkreds.
Derfor skal du være klar på forhånd til at overvinde et sådant scenario. Til dette skal du gendanne hver operation og data øjeblikkeligt. I enkle ord skal du forberede din organisation på at gendanne alt på det kortest mulige interval for dine kunder.
Katastrofer er af mange typer, såsom cyberangreb, sabotage, terrorangreb, ransomware eller fysiske trusler, orkaner, jordskælv, brande, oversvømmelser, industriulykker, strømafbrydelser og meget mere.
Hvad mener du med Disaster Recovery?

Disaster recovery er processen med at genvinde normal drift efter at have lidt af en katastrofe. Det indebærer genoptagelse af adgang til hardware, software, udstyr, forbindelse, netværk, strøm og data. Du skal opstille regler og procedurer i en dokumenteret proces for at forberede din organisation før en katastrofe.
Men hvis din organisations faciliteter ødelægges, skal du udvide nogle af aktiviteterne ved at arbejde med kommunikation, transport, indkøb, arbejdssteder og meget mere.
Hvorfor er en katastrofegenopretningsplan vigtig?
At udarbejde en perfekt plan for at komme sig efter en katastrofe, enten naturlig eller menneskeskabt, er afgørende for enhver it-industri. Sørg for, at du har den rigtige medarbejder og værktøjer på det rigtige sted for at udføre planen problemfrit.
Lad os dykke dybere ned i, hvorfor disaster recovery er afgørende.
Begræns skader
En katastrofe er uforudsigelig. Ingen ved, hvornår det kommer og går. Men du forbereder dig på forhånd for at kontrollere skaden på din infrastruktur.
For eksempel kan du i oversvømmelsestruede områder placere dine væsentlige dokumenter og typer udstyr på øverste etage for at undgå skader.
Tilsvarende skal du sikkerhedskopiere dine væsentlige data, før cyberangreb kan bryde data eller stjæle dem.
Gendannelsestjenester
Hvis du udarbejder en solid plan for at komme dig efter katastrofen, er det hurtigt og nemt at genoprette alle tjenester til deres normale form. Det betyder, at du på kort tid kan genvinde næsten alle de store aktiver og tjenester.
Minimer afbrydelse
Du kan ikke vide, hvad der vil ske i morgen eller i næste trin af en operation. Men med en perfekt genopretningsplan behøver du ikke bekymre dig meget om konsekvenserne. Din infrastruktur kan fortsætte driften med minimal afbrydelse.
Træning og forberedelse

En it-infrastruktur består af mange medarbejdere, der arbejder under tag. Alle skal have kendskab til genopretningen for straks at handle efter behov og forventet i tilfælde af en nødsituation.
Korrekt forberedelse vil også sænke stressniveauet for alle, der er tilknyttet din organisation. Ydermere kan du træne dine medarbejdere i at tage nødvendige handlinger, hvis der opstår en uventet hændelse.
Disaster Recovery Terminologier
Lad os starte med terminologierne for at forstå disaster recovery fra et nærmere blik.
RTO
Recovery Time Objective (RTO) er den tid, som en organisation sætter i henhold til virksomhedens art for at tolerere katastrofer uden at påvirke økonomisk vækst.
Mens du indstiller RTO’en, skal en virksomhed kontrollere de nedetider, der kan påvirke din organisation på mange måder. Det bruges til at studere levedygtige strategier for at fortsætte din forretningsdrift, selv efter en katastrofe. Når kunder står over for forstyrrelser i applikationen, spørger de, hvor lang tid det vil tage en app at vende tilbage til handlingen. Svaret er RTO for enhver organisation.
Eksempel: Antag, at du er en online transaktionsvirksomhed som PayPal eller Pioneer, der står over for uforudsigelige begivenheder. I dette tilfælde vil din RTO være hurtig nok til at genoprette operationen.
Med andre ord sætter en virksomhed sin RTO til en time eller to for at undgå konsekvenser i form af økonomi eller data.
RPO
Recovery Point Objectives (RPO) er det datatab, som en it-infrastruktur kan håndtere med hensyn til tid og mængde af information.
Forvirrende?
Tag et eksempel på en database, der registrerer transaktioner i en bank, herunder overførsler, planlægning, betalinger og mere. Når en katastrofe sker, gendannes databasen i realtid. Forskellen mellem databasen på katastrofetidspunktet og databasegendannelsen efter en katastrofe er nul i dette tilfælde.
For nogle virksomheder er det acceptabelt at tage omkring 24 timer at gendanne alle oplysningerne fra sikkerhedskopien, men det kan nogle gange være katastrofalt. Det er vigtigt at indstille din infrastruktur i overensstemmelse med RPO-kravene. Dette inkluderer forbedring af frekvensen af sikkerhedskopier, tilføjelse af en standby-database til din arkitektur og mere.
Failover
Tænk på en situation, hvor du rejser langt. Pludselig fik du et fladt dæk af en eller anden uventet årsag. Du takker for det tilgængelige reservedæk i dit køretøj og værktøjerne til at skifte det defekte dæk.
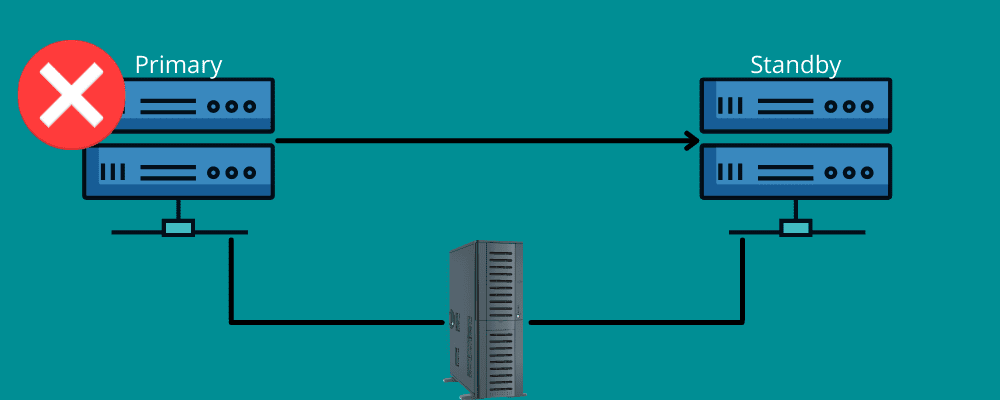
Failover fungerer på samme måde.
Det betyder, at du har brug for en backup-forbindelse under katastrofen. I en nøddeskal betyder failover at have netværk og systemer, som du kan bruge på tidspunktet for en katastrofe til at skifte dine oplysninger til gendannelsessystemet.
Failover sikrer, at alle dine tjenester kører problemfrit, selvom der er infrastruktur- eller hardwarefejl. På denne måde kan du forhindre din organisation i at miste data og omsætning og undgå serviceforstyrrelser for dine slutbrugere.
Du kan enten indstille det manuelt eller lade det fungere automatisk for at flytte dataene til standby-serveren.
Failback
IT-fejlback er en simpel operation, hvor den oprindelige produktion går tilbage til sit oprindelige sted (system), efter at en katastrofe er håndteret. Under angrebet følger virksomheder en failover-operation, på grund af hvilken alle arbejdsbelastninger overføres til en VM-replika eller et backup-system.
Du kan dog ikke bare springe det næste trin af at vende tilbage. Når du gendanner alt og kommer i gang igen, skal du overføre alle arbejdsbelastningerne til deres originale VM’er eller systemer. Denne overordnede proces med at returnere arbejdsbelastningerne til den oprindelige arbejdsplads eller det oprindelige system er kendt som failback. Det betyder, at du kommer “tilbage” efter angrebet.
Failback bruges også til planlagt vedligeholdelse af en virksomhed. Det er rigtigt, at failback altid opstår efter failover. Med andre ord er failover det første trin, og failback er det andet trin i gendannelse af væsentlige data. Det kan sættes op mellem sky til sky, lokalt til lokalt, lokalt til sky eller en hvilken som helst kombination fra disse.
DR
Disaster Recovery (DR) er den proces, hvor du har forudbyggede planer for at genoprette dine aktiver inden for tidsrammen.
DR giver en organisation mulighed for at reagere hurtigt og gendanne hver enkelt tjeneste fra en uventet hændelse. Den giver også formel dokumentation, der indeholder instruktioner om at træffe øjeblikkelige foranstaltninger i tilfælde af uforudsete hændelser.
BCP
Business Continuity Plan (BCP) er en af de mest acceptable katastrofegenopretningsplaner, der tillader it-infrastruktur at lave strategier for at håndtere it-forstyrrelser på servere, mobile enheder, personlige computere og netværk.
BCP adskiller sig lidt fra katastrofegendannelse, da det hjælper en organisation med at planlægge at genetablere virksomhedssoftware og produktivitet for at imødekomme vigtige forretningsbehov.
Her opretter en virksomhed et genopretningssystem for at overvinde potentielle trusler, såsom cyberangreb eller naturkatastrofer. Det er designet til at sikre aktiver og sikre, at alle tjenester vil være tilbage i aktion hurtigt efter strejken.
BCM

Business Continuity Management (BCM) er en risikostyringsproces, der er specielt designet til at fungere som et skjold mod trusler mod forretningsprocesser. BCM er det næste trin i BCP, hvor det validerer genopretningsplanerne for at sikre, at alle i virksomheden reagerer på planen øjeblikkeligt og genskaber alle de væsentlige ting.
BCM fungerer som en ledelsesramme til at identificere infrastrukturrisici, når den står over for eksterne og/eller interne trusler. Det sikrer også, at rammen fungerer effektivt ved hjælp af regelmæssige tests for at øge forudsigeligheden, reducere risikoen og tilpasse planen for fremtidige angreb.
BIA
Business Impact Analysis (BIA) er processen med at analysere en virksomheds overlevelsesrate ved at identificere afgørende systemer, operationer og processer. Den fortæller om effekten af en katastrofe på din organisation på grund af afbrydelsen i din drift.
BIA forudsiger konsekvenserne, før et angreb rent faktisk sker, for at indsamle nøgleoplysninger, der kan hjælpe med at skabe effektive genopretningsstrategier. Den identificerer også de involverede omkostninger på grund af fejlene, såsom udskiftningsomkostninger for udstyr, tab af pengestrømme, overskud, lønninger og mere.
Når du opretter en BIA-rapport, skal du overveje de afgørende processer, der er involveret i din virksomhed, virkningen af forstyrrelser på forskellige områder, acceptabel varighed, tolerable områder, økonomiske omkostninger og mere.
Ring til træ
Et opkaldstræ er en proces til at sammensætte en liste over medarbejdere, der skal tilkaldes under en nødsituation. Det er en procedure, der følger en trælignende struktur.
For eksempel, under en katastrofe, vil en person kontakte en lille gruppe medlemmer med en presserende besked, disse medarbejdere ringer hver gruppe separat. På denne måde vil hele personalet blive informeret under truslen og starte deres tildelte job for at genoprette hver funktion og proces i tide. Det er nemt at lave en liste, men at implementere den i realtid skaber forvirring.
Du skal udføre regelmæssige opkaldsaktiviteter for at forberede alle nødhjælpsmedarbejdere til at forblive opmærksomme. Regelmæssig testning kan også hjælpe med at identificere ændrede eller manglende tal, der kan påvirke ydeevnen alvorligt.
Et opkaldstræ indeholder information, der skal bruges under en nødsituation til at levere instruktioner. Det kan også gøres manuelt, men folk bruger automatisering til at accelerere processen og underrette medlemmerne i nutidens digitale verden.
Kommandocenter/Kontrolcenter
Det er en virtuel eller fysisk facilitet, der er specielt forberedt til at give kommando eller kontrol over genopretningsplanerne under en krise. Det kommunikerer med teamet for at styre systemerne og funktionerne under katastrofen.
Traditionelt afhænger infrastrukturen af, at kommandocentralen håndterer kriser uden nogen ordentlig tilgang. I dag har organisationer designet deres kontrolcenter perfekt, hvilket vender den umiddelbare reaktion til kernekompetence.
Når først den fornemmer en katastrofe, kører kommandocentralen hurtigt mod genopretningsfasen. Desuden fungerer det som rapporteringspunkt i tilfælde af tjenester, presse, leverancer og meget mere. Det samler også mennesker fra flere discipliner under sådanne scenarier.
Hændelsesrespons

Hændelsesreaktion er en type reaktion, der gives for at håndtere et angreb. Det sker ved hjælp af de rigtige procedurer og personale for at bevare netværks- og datasikkerheden effektivt på det rigtige tidspunkt.
Hvis en organisation har en hændelsesplan forud for den uventede hændelse, kan den sikre sine data mod trusler i realtid. Hændelsesberedskabsspecialisterne er altid opmærksomme på problemerne og handler naturligt under en hændelse. De træffer visse foranstaltninger for at undgå sikkerhedsbrud og sikrer, at de ikke springer et eneste trin over under gendannelse efter katastrofe.
I begyndelsen skal du bestemme de kritiske data og gemme dem i skyen eller en hvilken som helst fjernplacering for at sikre sikkerheden. Håndter aktuelle infrastrukturbehov og udviklende cybertrusler ved at opdatere hændelsesplaner regelmæssigt.
Backup
Backup-løsninger hjælper en it-infrastruktur med at vedligeholde kopier af data og opbevare dem sikkert på det rigtige tidspunkt. Hvis du står over for korruption af databasen, utilsigtet sletning af alle data eller ethvert andet problem, skal du være klar med sikkerhedskopien for at gendanne dataene øjeblikkeligt og fortsætte med tjenesterne.

Det indebærer at kopiere filerne og gemme dem på et sikkert sted for nemt at få adgang til alle data efter en usædvanlig begivenhed. Det vil hjælpe, hvis du sikkerhedskopierer dine data flere steder for at sikre, at du kan gendanne dem, selvom et websted fejler.
Modstandsdygtighed
Samfunds, staters, organisationers og enkeltpersoners evne til at modstå eller modstå en katastrofe uden at kompromittere tjenesterne og systemerne er kendt som katastrofemodstandsdygtighed.
En organisation skal være forberedt på at tilbageholde en stor mængde stress på grund af farerne. Sørg for, at du har evnerne til at minimere dine tab med bedre planlægning i stedet for at vente på, at nogen kommer og redder dig. Dette vil hjælpe dig med at imødekomme katastroferne og effektivt genoprette din it-infrastruktur.
Her er hovedmålet at bevare og genoprette de væsentlige funktioner og strukturer på det rigtige tidspunkt, når det er nødvendigt. For at blive en katastrofebestandig organisation skal du forberede dig på forhånd og have evnen til at forudse risici, tilpasse dig ændringer, dele og lære, integrere forskellige sektorer og styre risikoniveauer.
SLA

Service Level Agreement (SLA) er en katastrofeplan, hvor du for slutbrugerne nævner den tid, du kan tage på at genoprette tjenester under en nødsituation.
SLA sikrer kunderne, at deres data er sikre og ikke kompromitteret eller delt med tredjeparter. Det er det eneste kontaktpunkt med slutbrugerproblemerne.
Enhver it-infrastruktur giver sikkerhed om SLA til sine kunder. Så sørg for at kommunikere med dine slutbrugere på forhånd.
SPOF
A Single Point of Failure (SPOF) er et stykke udstyr, en person, ressource eller applikation, som mange andre systemer eller applikationer er forbundet til.
Hvis et sådant stykke udstyr eller ressource går ned, går alle de væsentlige dele, der er forbundet til systemet, ned med det. Dermed vil hele processen og forretningsdriften blive påvirket.
Derfor skal du have en strategi til at håndtere et sådant problem for at holde din organisation kørende. Den allerførste ting, du kan gøre, er at identificere det enkelte stykke udstyr eller system, der kan påvirke mere. Kør derefter en forretningskonsekvensanalyse og få en risikovurderingsscore for at være opmærksom på de scener, der vil ske. Grav ind og find dem før begivenheden.
Når du har listet alle SPOF’erne, skal du klassificere dem i henhold til gendannelsesprocessen. Sæt hver enkelt SPOF i tre forskellige kategorier:
- Gendan nemt og direkte med mindre tid og budget.
- Gendannelse ville være vanskelig, men en pålidelig proces kunne udvikles til at genoprette.
- Der kan ikke gøres noget for at komme sig, når først det går ned.
Du kan handle i overensstemmelse hermed baseret på kategorien.
Systemgendannelse
Under hardwarefejl skal du køre en gendannelsesproces for at hente det bestemte system eller server til dets oprindelige form. Og for at gendanne hele systemet skal du være klar med gendannelseskrav, sikkerhedskopier, firmwarekompatibilitet og hardwarekompatibilitet.
Systemgendannelse er en proces, der nulstiller maskinen til dens tidligere indstillinger eller den samme tilstand, som den var, da den var ny. Hvis du gør dette, vil alle virusinfektioner slettes på grund af installeret software eller programmer i dit system.
Denne proces omfatter genopretningsplanlægning af en it-infrastruktur, der sætter og følger visse procedurer for at sikre datatilgængelighed mod menneskeskabte eller naturlige forstyrrelser.
Systemgendannelse
Systemgendannelse er et gendannelsesværktøj, der giver dig mulighed for at gendanne visse filer og oplysninger til deres tidligere tilstand på det rigtige tidspunkt.
Med systemgendannelse kan du gendanne registreringsdatabasenøgler, installerede programmer, drivere, systemfiler og mere tilbage til dens tidligere version. Dette fungerer som en livredder i mange katastrofer.
Testplan
Det refererer til et dokument, der gemmer information om en teststrategi, estimater, ressourcer, deadlines, målsætninger og tidsplaner. Det fungerer som en plan, der kører tests for at sikre hardware- og softwaresikkerhed.
Dette inkluderer forskellige tests i henhold til de procedurer og trin, der er planlagt til at håndtere katastrofeeftervirkninger. Udfør de regelmæssige tests for at forberede dig selv og din organisation på ikke at springe et eneste trin over i løbet af handlingen. På den måde kan en it-infrastruktur forstå manglerne og være klar til kampen.
Konklusion
Ingen ved, hvornår en katastrofe vil ske. Derfor er ordentlige sikkerheds- og sikkerhedsforanstaltninger afgørende for enhver virksomhed.
Disaster recovery terminologier hjælper dig med at forstå, hvordan du reagerer på angreb og katastrofer. Det vil også hjælpe dig med at forberede dig på forhånd, så du kan beskytte din infrastruktur under en uventet begivenhed. Du vil være i stand til at skabe en effektiv katastrofegendannelsesstrategi i realtid for at spare millioner af dollars og tilbageholde kundernes tillid.