
Dataudtræk er processen med at indsamle specifikke data fra websider. Brugere kan udtrække tekst, billeder, videoer, anmeldelser, produkter osv. Du kan udtrække data for at udføre markedsundersøgelser, sentimentanalyse, konkurrenceanalyser og aggregerede data.
Hvis du har at gøre med en lille mængde data, kan du udtrække data manuelt ved at kopiere de specifikke oplysninger fra websider til et regneark eller dokumentformat efter din smag. For eksempel, hvis du som kunde leder efter anmeldelser online for at hjælpe dig med at træffe en købsbeslutning, kan du skrotte data manuelt.
På den anden side, hvis du har med store datasæt at gøre, har du brug for en automatiseret dataudtræksteknik. Du kan oprette en in-house dataekstraktionsløsning eller bruge Proxy API eller Scraping API til sådanne opgaver.
Disse teknikker kan dog være mindre effektive, da nogle af de websteder, du målretter mod, muligvis er beskyttet af captchas. Du skal muligvis også administrere bots og proxyer. Sådanne opgaver kan tage meget af din tid og begrænse arten af det indhold, du kan udtrække.
Indholdsfortegnelse
Scraping Browser: Løsningen
Du kan overvinde alle disse udfordringer gennem Scraping Browser by Bright Data. Denne alt-i-en-browser hjælper med at indsamle data fra websteder, der er svære at skrabe. Det er en browser, der bruger en grafisk brugergrænseflade (GUI) og styres af Puppeteer eller Playwright API, hvilket gør den uopdagelig af bots.
Scraping Browser har indbyggede oplåsningsfunktioner, der automatisk håndterer alle blokke på dine vegne. Browseren åbnes på Bright Datas servere, hvilket betyder, at du ikke behøver dyr intern infrastruktur for at skrotte data til dine store projekter.
Funktioner i Bright Data Scraping Browser
- Automatisk oplåsning af websteder: Du behøver ikke at blive ved med at opdatere din browser, da denne browser justerer automatisk for at håndtere CAPTCHA-løsning, nye blokeringer, fingeraftryk og genforsøg. Scraping Browser efterligner en rigtig bruger.
- Et stort proxy-netværk: Du kan målrette mod ethvert land, du ønsker, da Scraping Browser har over 72 millioner IP’er. Du kan målrette mod byer eller endda transportører og drage fordel af klassens bedste teknologi.
- Skalerbar: Du kan åbne tusindvis af sessioner samtidigt, da denne browser bruger Bright Data-infrastrukturen til at håndtere alle anmodninger.
- Puppeteer og Playwright-kompatibel: Denne browser giver dig mulighed for at foretage API-kald og hente et vilkårligt antal browsersessioner enten ved hjælp af Puppeteer (Python) eller Playwright (Node.js).
- Sparer tid og ressourcer: I stedet for at konfigurere proxyer, tager Scraping Browser sig af alt i baggrunden. Du behøver heller ikke opsætte intern infrastruktur, da dette værktøj tager sig af alt i baggrunden.
Sådan opsætter du Scraping Browser
- Gå over til Bright Data-webstedet og klik på Scraping-browseren på fanen “Scraping Solutions”.
- Opret en konto. Du vil se to muligheder; “Start gratis prøveperiode” og “Start gratis med Google”. Lad os vælge “Start gratis prøveperiode” for nu og gå videre til næste trin. Du kan enten oprette kontoen manuelt eller bruge din Google-konto.
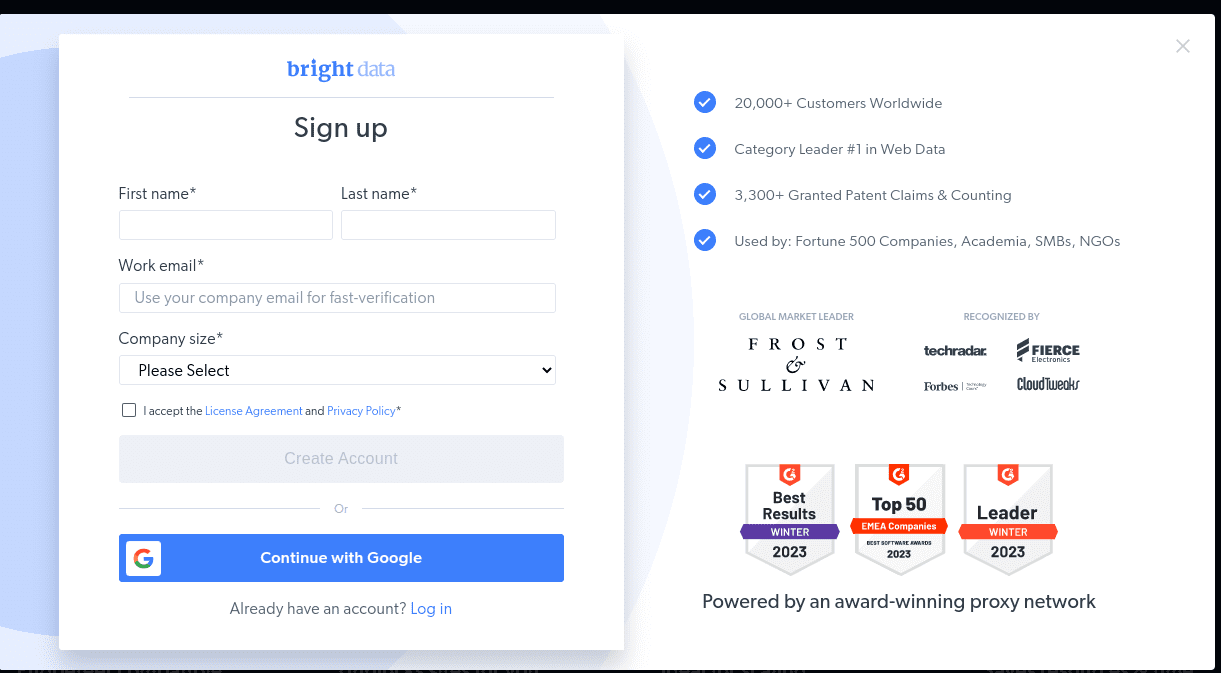
- Når din konto er oprettet, vil dashboardet præsentere flere muligheder. Vælg “Proxies & Scraping Infrastructure”.
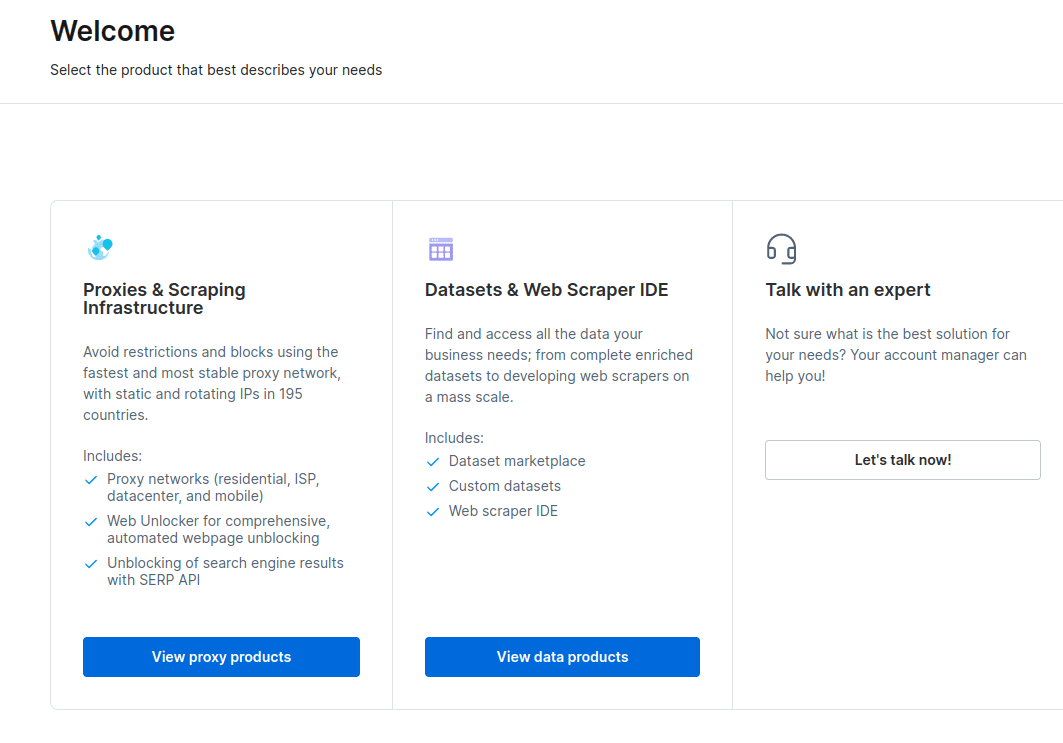
- I det nye vindue, der åbnes, skal du vælge Scraping Browser og klikke på “Kom i gang”.
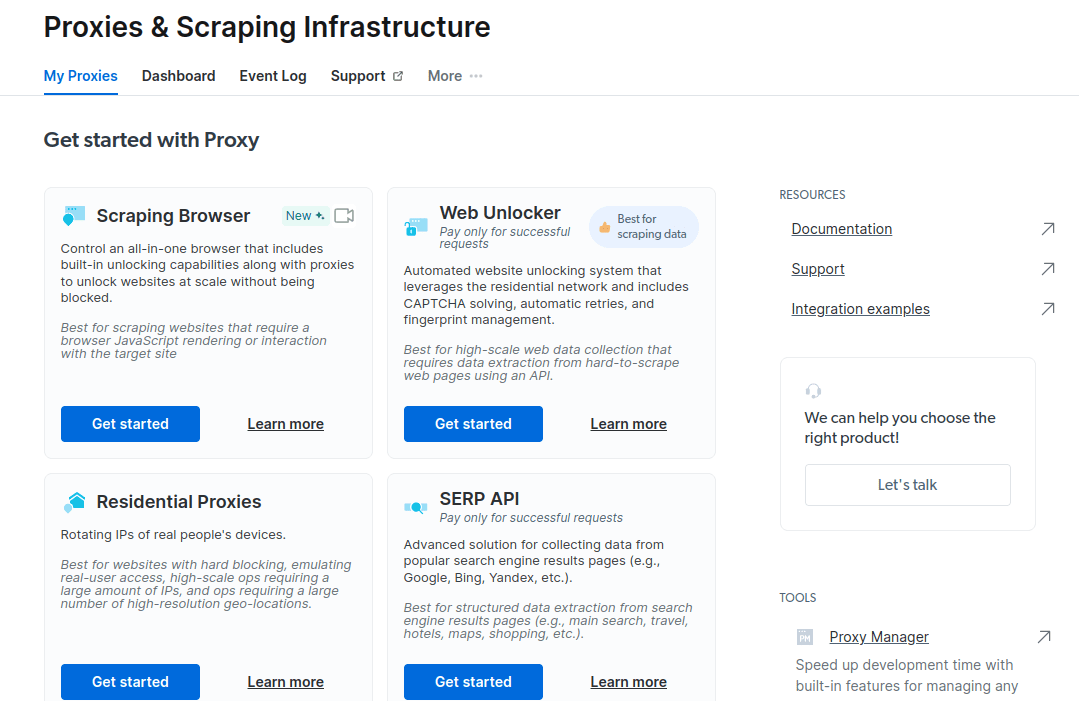
- Gem og aktiver dine konfigurationer.
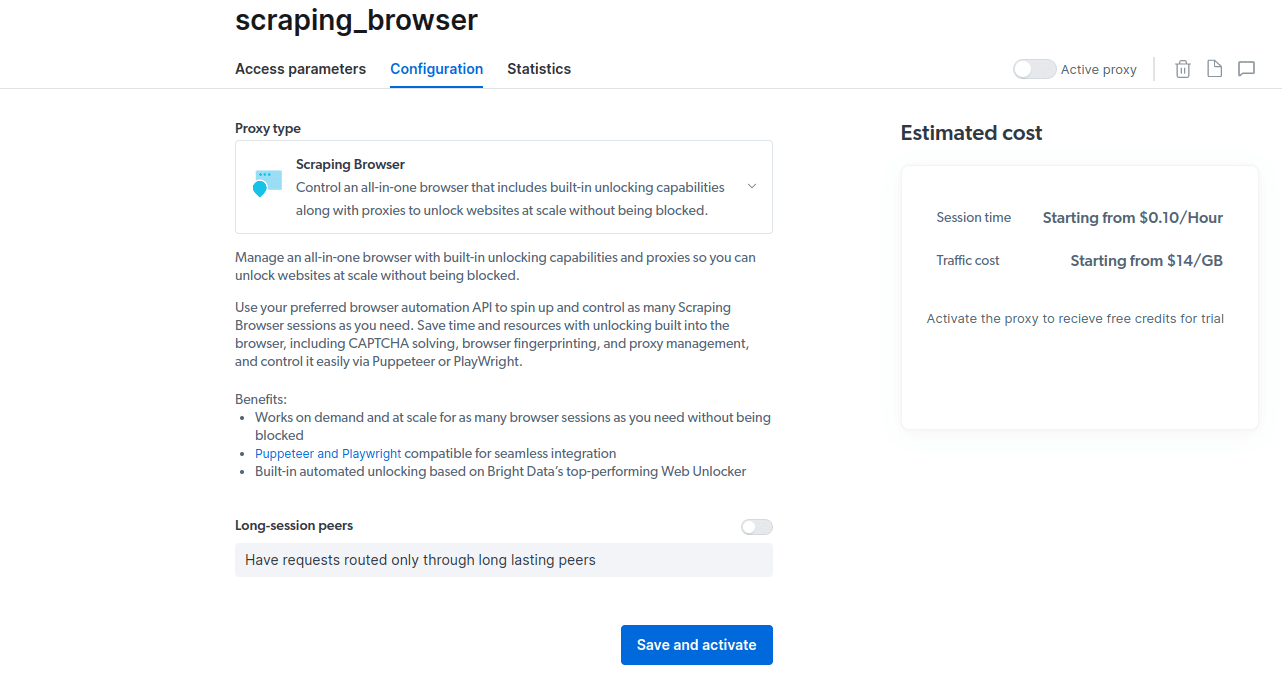
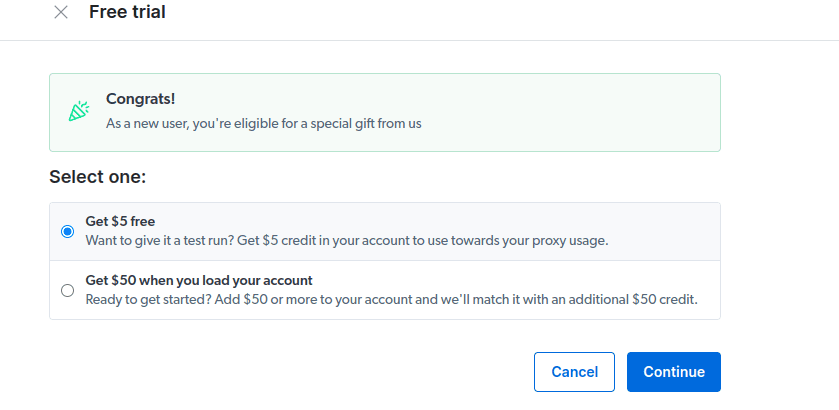
- Aktiver din gratis prøveperiode. Den første mulighed giver dig en kredit på $5, som du kan bruge til dit proxybrug. Klik på den første mulighed for at prøve dette produkt. Men hvis du er en stor bruger, kan du klikke på den anden mulighed, der giver dig $50 gratis, hvis du indlæser din konto med $50 eller mere.
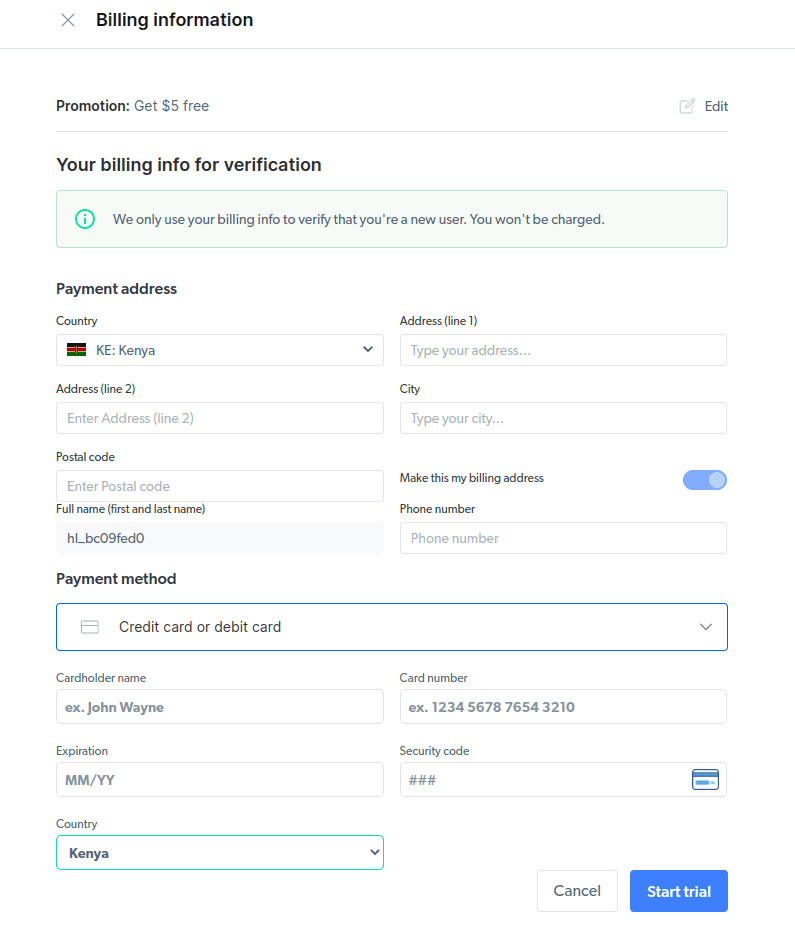
- Indtast dine faktureringsoplysninger. Bare rolig, da platformen ikke opkræver dig noget. Faktureringsoplysningerne bekræfter blot, at du er en ny bruger og ikke leder efter freebies ved at oprette flere konti.
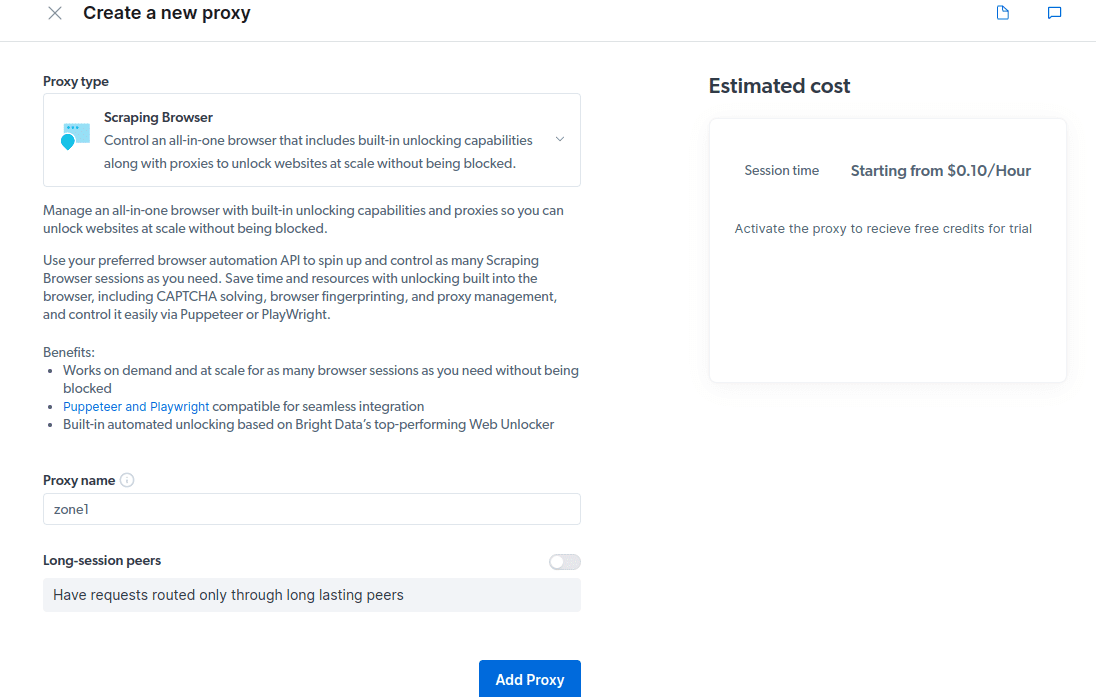
- Opret en ny proxy. Når du har gemt dine faktureringsoplysninger, kan du oprette en ny proxy. Klik på “tilføj”-ikonet og vælg Scraping Browser som din “Proxytype”. Klik på “Tilføj proxy” og gå til næste trin.
- Opret en ny “zone”. Der vises en pop, der spørger dig, om du vil oprette en ny zone; klik på “Ja” og fortsæt.
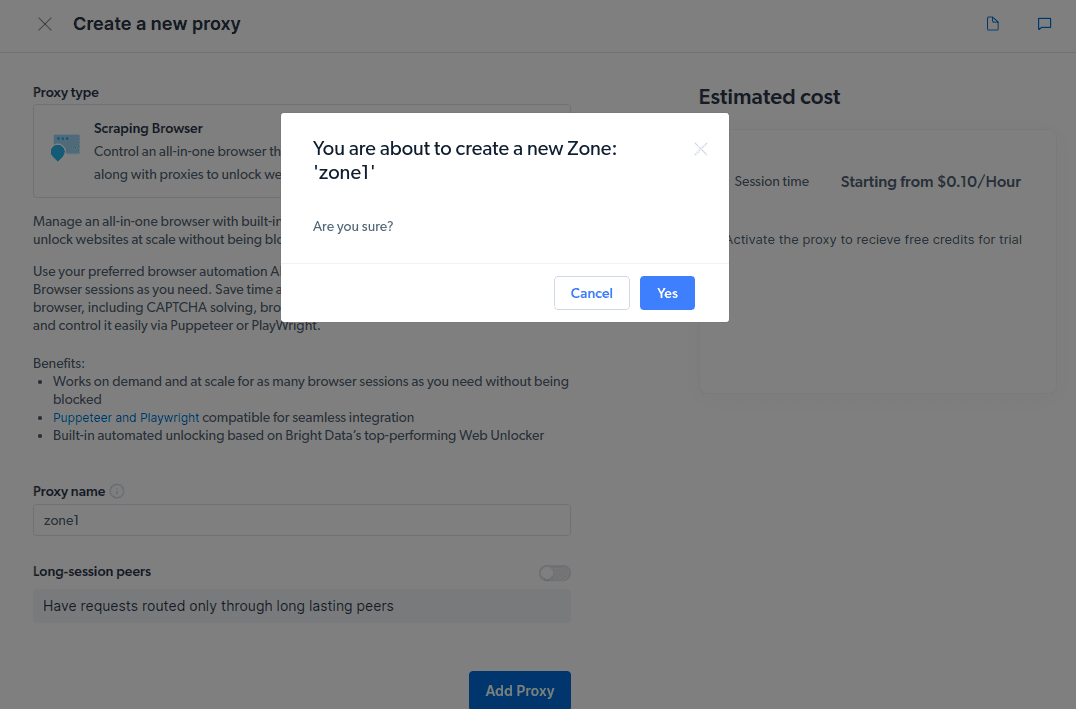
- Klik på “Tjek kode og integrationseksempler”. Du vil nu få Proxy-integrationseksempler, som du kan bruge til at skrotte data fra dit målwebsted. Du kan bruge Node.js eller Python til at udtrække data fra dit målwebsted.
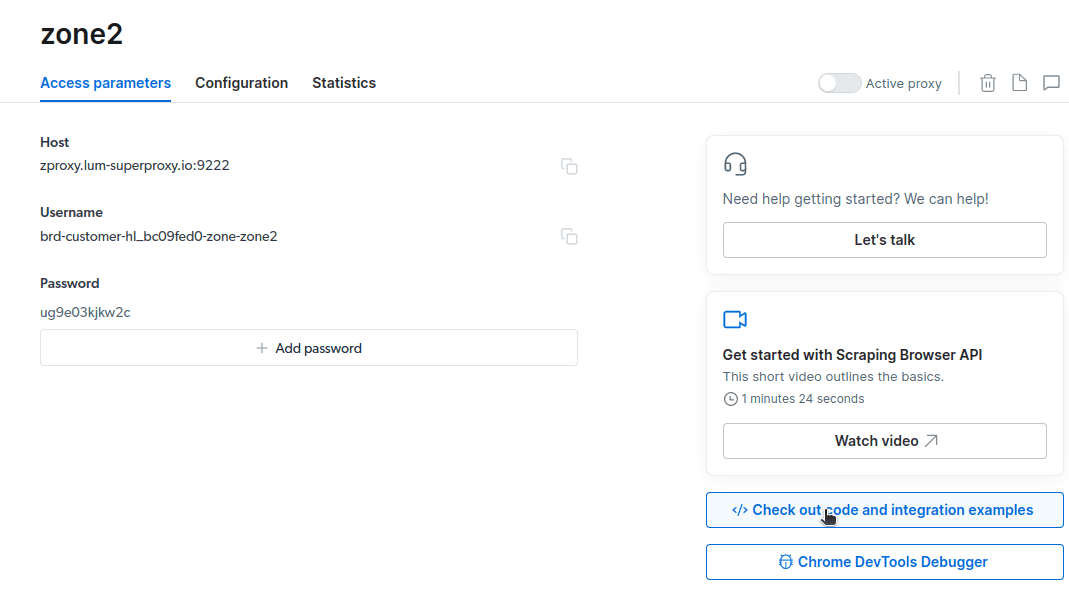
Du har nu alt hvad du behøver for at udtrække data fra en hjemmeside. Vi vil bruge vores hjemmeside, toadmin.dk.com, til at demonstrere, hvordan Scraping Browser fungerer. Til denne demonstration vil vi bruge node.js. Du kan følge med, hvis du har node.js installeret.
Følg disse trin;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Jeg vil ændre min kode på linje 10 til at være som følger;
await page.goto(‘https://toadmin.dk.com/authors/‘);
Min endelige kode bliver nu;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://toadmin.dk.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Du vil have noget lignende på din terminal
Sådan eksporteres data
Du kan bruge flere metoder til at eksportere data, afhængigt af hvordan du har tænkt dig at bruge dem. I dag kan vi eksportere dataene til en html-fil ved at ændre scriptet for at oprette en ny fil med navnet data.html i stedet for at udskrive den på konsollen.
Du kan ændre indholdet af din kode som følger;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://toadmin.dk.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Du kan nu køre koden ved hjælp af denne kommando;
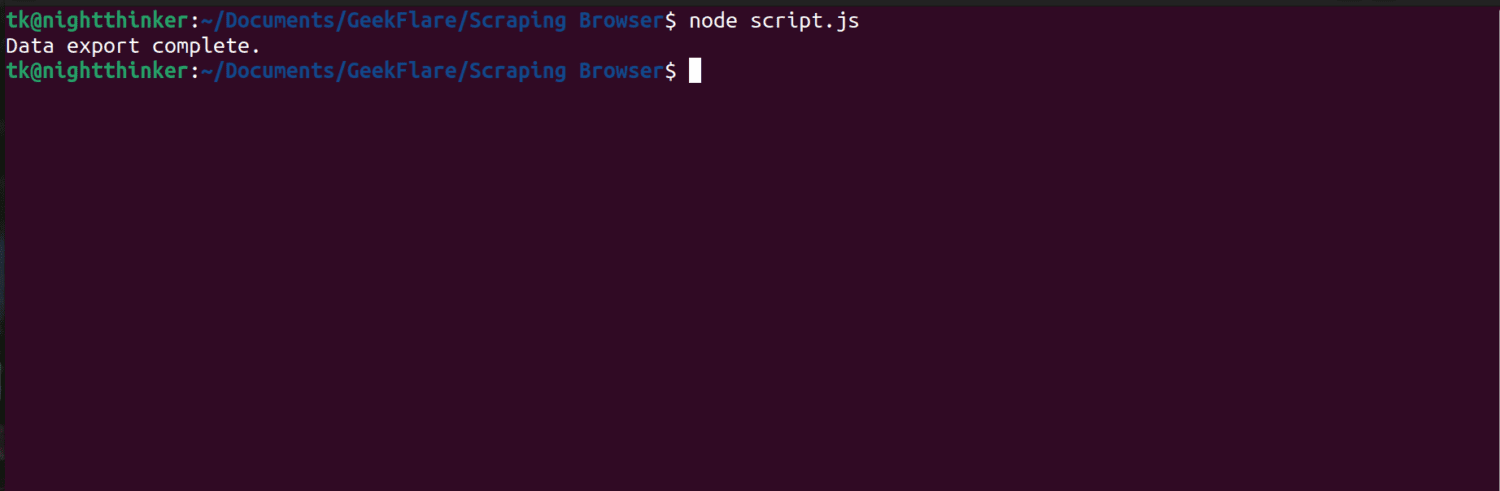
node script.js
Som du kan se på det følgende skærmbillede, viser terminalen en meddelelse, der siger “dataeksport færdig”.
Hvis vi tjekker vores projektmappe, kan vi nu se en fil ved navn data.html med tusindvis af linjer kode.
Jeg har lige ridset overfladen af, hvordan man udtrækker data ved hjælp af Scraping-browseren. Jeg kan endda indsnævre og skrotte kun forfatternes navne og deres beskrivelser ved hjælp af dette værktøj.
Hvis du vil bruge Scraping-browseren, skal du identificere de datasæt, du vil udtrække, og ændre koden i overensstemmelse hermed. Du kan udtrække tekst, billeder, videoer, metadata og links, afhængigt af det websted, du målretter mod, og HTML-filens struktur.
Ofte stillede spørgsmål
Er dataudtræk og webskrabning lovligt?
Webskrabning er et kontroversielt emne, hvor en gruppe siger, at det er umoralsk, mens andre føler, at det er okay. Lovligheden af web-skrabning vil afhænge af arten af det indhold, der skrabes, og målwebsidens politik.
Generelt betragtes det som ulovligt at skrabe data med personlige oplysninger såsom adresser og økonomiske detaljer. Før du skroter for data, skal du kontrollere, om det websted, du målretter mod, har nogen retningslinjer. Sørg altid for, at du ikke kasserer de data, der ikke er offentligt tilgængelige.
Er Scraping Browser et gratis værktøj?
Nej. Scraping Browser er en betalingstjeneste. Hvis du tilmelder dig en gratis prøveperiode, giver værktøjet dig en kredit på $5. De betalte pakker starter fra $15/GB + $0,1/time. Du kan også vælge Pay As You Go-muligheden, der starter fra $20/GB + $0,1/h.
Hvad er forskellen mellem Scraping-browsere og hovedløse browsere?
Scraping Browser er en hovedfuld browser, hvilket betyder, at den har en grafisk brugergrænseflade (GUI). På den anden side har hovedløse browsere ikke en grafisk grænseflade. Hovedløse browsere såsom Selenium bruges til at automatisere web-scraping, men er nogle gange begrænsede, da de skal håndtere CAPTCHA’er og bot-detektion.
Afslutter
Som du kan se, forenkler Scraping Browser at udtrække data fra websider. Scraping Browser er enkel at bruge sammenlignet med værktøjer som f.eks. Selen. Selv ikke-udviklere kan bruge denne browser med en fantastisk brugergrænseflade og god dokumentation. Værktøjet har afblokeringsfunktioner, der ikke er tilgængelige i andre skrotningsværktøjer, hvilket gør det effektivt for alle, der ønsker at automatisere sådanne processer.
Du kan også undersøge, hvordan du forhindrer ChatGPT-plugins i at skrabe dit webstedsindhold.