
Lad os finde ud af, hvordan du kan holde din produktion pålidelig ved hjælp af Chaos Engineering-værktøjer.
Chaos engineering er en disciplin, hvor du eksperimenterer med dit system eller applikation for at afsløre dets svagheder og kapacitetssvigt. Disse er noget, du ikke troede kunne ske, mens du oprettede det. Så du ville forårsage nogle fejl med vilje på dit system for at vise dets svagheder for at gøre rettelserne og gøre dit system og din applikation mere modstandsdygtig.
Mange populære organisationer som Netflix, LinkedIn og Facebook udfører kaosteknik for bedre at forstå deres mikroservicearkitektur og distribuerede systemer. Det hjælper med at finde nye problemer hurtigere end reelle brugerklager og træffe de nødvendige foranstaltninger for at rette dem. Det er sådan, disse organisationer kan betjene millioner af brugere, øge deres produktivitet og spare millioner af dollars 🤑.
Fordele ved Chaos Engineering:
- Kontroller tab på omsætning ved at finde kritiske problemer
- Reduktion i system- eller applikationsfejl
- Bedre brugeroplevelse med færre forstyrrelser og høj servicetilgængelighed
- Det hjælper dig med at lære om systemet og få selvtillid.
Hvor sikker er du på din produktionspålidelighed? Er det rigtigt katastrofesikkert?
Lad os finde ud af det ved hjælp af følgende populære kaostestværktøjer.
Indholdsfortegnelse
Kaos Mesh
Kaos Mesh er en kaos-ingeniørstyringsløsning, der injicerer fejl i hvert lag af et Kubernetes-system. Dette inkluderer pods, netværket, system I/O og kernen. Chaos Mesh kan automatisk dræbe Kubernetes pods og simulere latenser. Det kan forstyrre pod-to-pod-kommunikation og simulere læse-/skrivefejl. Det kan planlægge regler for eksperimenterne og definere deres omfang. Disse eksperimenter er specificeret ved hjælp af YAML-filer.
Chaos Mesh har et dashboard til at se analyser af eksperimenter. Den kører oven på Kubernetes og understøtter størstedelen af cloud-platformen. Det er open source og blev for nylig accepteret som et CNCF-sandkasseprojekt. Ved at bruge kaos-tekniske principper kan du tilføje Chaos Mesh til din DevOps-arbejdsgang for at bygge modstandsdygtige applikationer.
Chaos Engineering funktioner:
- Kan nemt implementeres på Kubernetes-klynger uden ændringer i implementeringslogikken
- Der kræves ingen unikke afhængigheder til implementering
- Definerer kaosobjekter ved hjælp af CustomResourceDefinitions (CRD)
- Giver et dashboard til at spore alle eksperimenterne
Kaos ToolKit er et open source og enkelt værktøj til Chaos Engineering Experiment Automation.
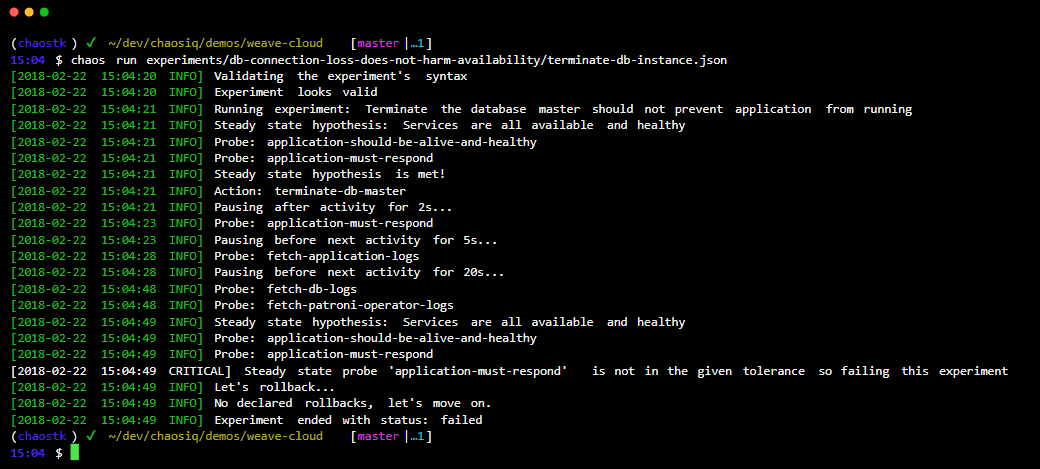
Du integrerer Chaos ToolKit med dit system ved hjælp af et sæt drivere eller plugins, det understøtter AWS, Google Cloud, Slack, Prometheus osv.
Chaos ToolKit funktioner:
- Giver deklarativ Open API til at skabe kaoseksperimenter uafhængigt af en leverandør eller teknologi
- Kan nemt indlejres i CICD pipelines til automatisering
- Yder kommerciel og virksomhedssupport også gennem KaosIQ
ChaosKube
Som du kan gætte ved navnet, er det for Kubernetes.
Chaoskube er et open source kaosværktøj, der med jævne mellemrum dræber tilfældige pods i Kubernetes-klyngen. Det hjælper dig med at forstå, hvordan dit system vil reagere, når poden fejler. Som standard dræber den en pod i ethvert navneområde hvert 10. minut. Du kan filtrere målpods i Chaoskube ved hjælp af navnerum, etiketter, annoteringer osv. Det kan nemt installeres ved hjælp af Chaoskube.

Kaos abe
Kaos abe er et værktøj, der bruges til at kontrollere skysystemernes modstandsdygtighed ved med vilje at skabe fejl, så disse systemer kan forstå deres reaktion. Netflix skabte den for at teste dens AWS-infrastrukturs robusthed og gendannelsesevne. Den fik navnet Chaos Monkey, fordi den skaber ødelæggelse som en vild og bevæbnet abe for at teste fejlene.
Det var også Chaos Monkey, som fødte den nye ingeniørpraksis Chaos Engineering. Den blev skabt ud fra princippet om, at det er bedre at fejle gentagne gange for at undgå pludselige væsentlige fejl.
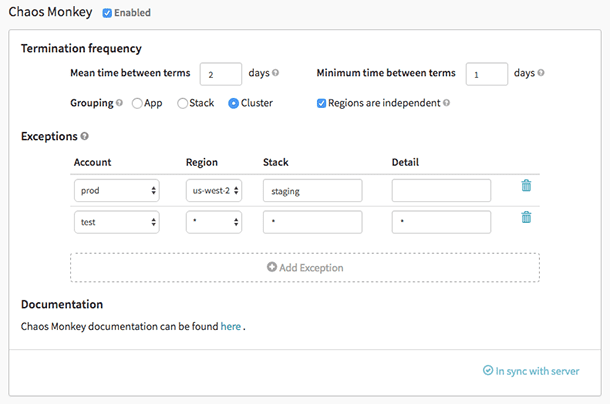
Chaos Monkey funktioner:
- Det hjælper dig med at forberede dig på tilfældige instansfejl.
- Tilskynder til redundans for uventede fejl
- Bruger Spinnaker til at aktivere cross-cloud-kompatibilitet
- Giver konfigurerbar tidsplan til at simulere fejl
- Integreret med govendor at tilføje nye afhængigheder til kaos abe
Simmy
Simmy er et kaosværktøj til fejlinjektion, der integreres med Polly-resilience-projektet til .NET. Det giver dig mulighed for at skabe kaos-injektion politikker gennem Polly, hvor du udfører dine koder. Det tilbyder forskellige politikker såsom undtagelsespolitik for at injicere undtagelser i systemet, adfærdspolitik til at injicere enhver ny adfærd osv. Disse politikker er designet til at injicere adfærden tilfældigt.
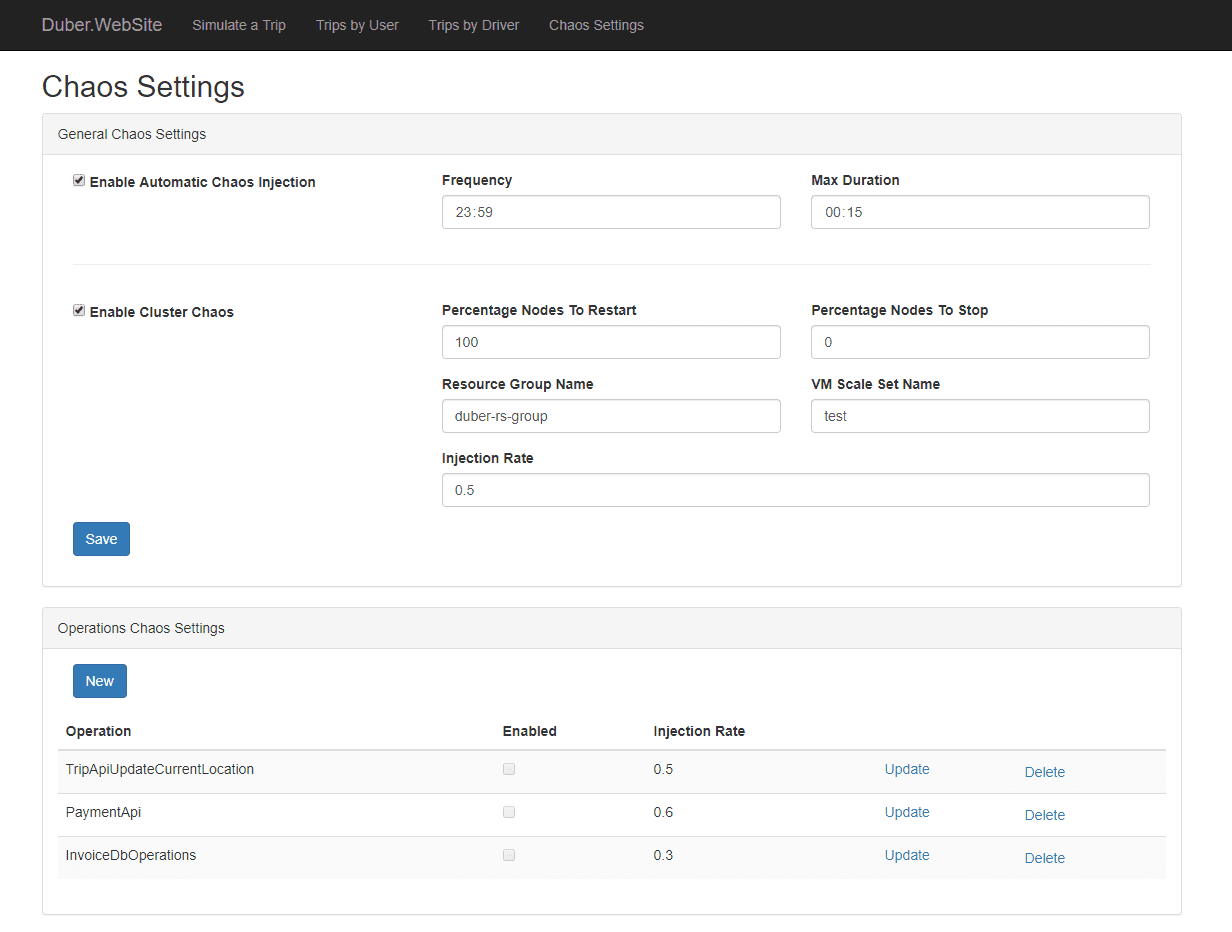
Simmy funktioner:
- Giver Monkey-politikker eller Chaos-politikker for at injicere kaos
- Let at teste eventuelle afhængighedsfejl
- Det hjælper med at vende tilbage til arbejdsmodellen hurtigt og styrer sprængningsradius.
- Den er klar til produktion.
- Det kan også definere fejl baseret på eksterne faktorer (for eksempel fejl på grund af global konfiguration)
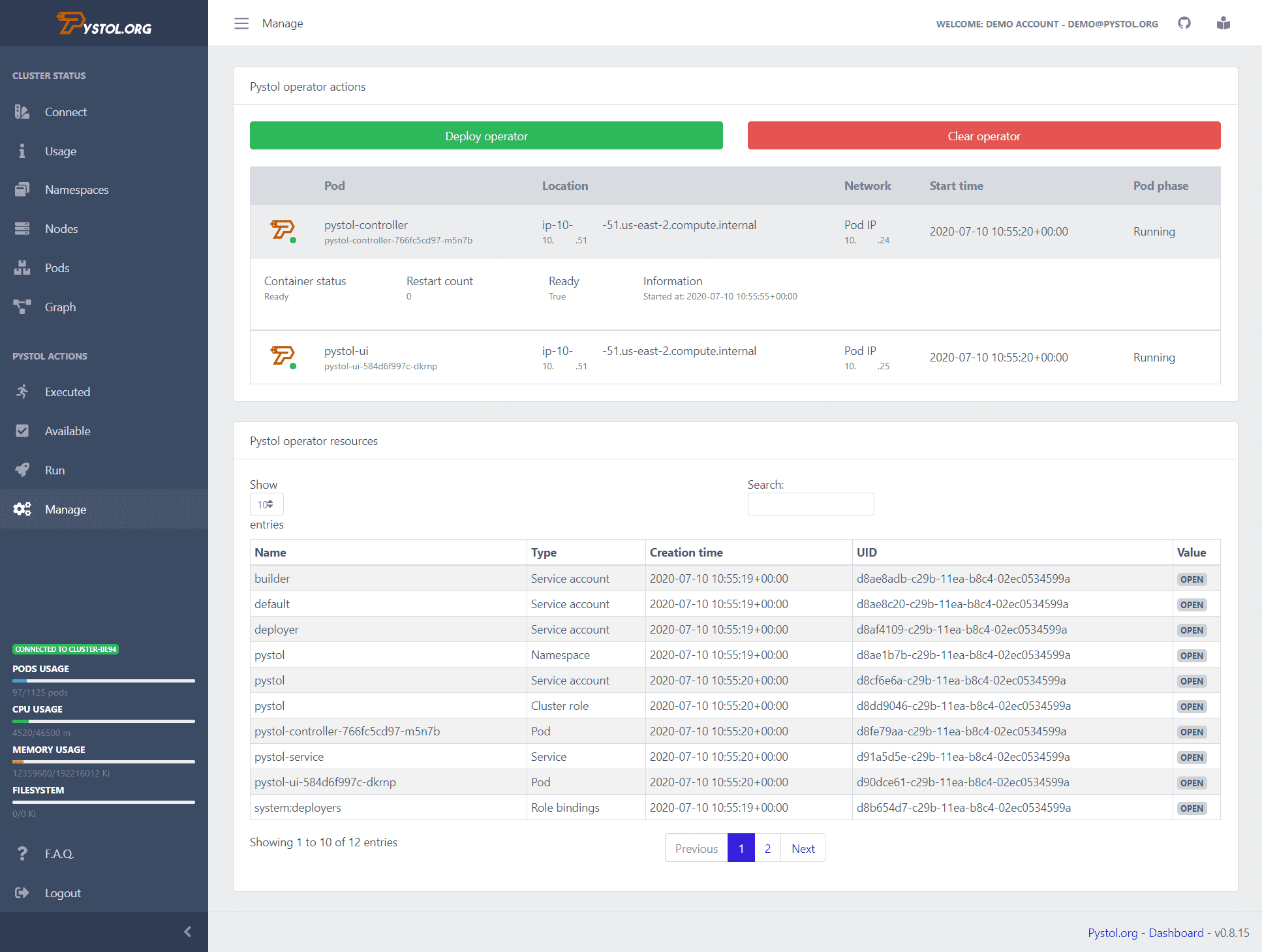
Pystol
Pystol er et værktøj, der bruges til at injicere defekte injektioner i cloud-native miljøer. Den ser begivenheder i ETCD gennem Kubernetes-operatører. Når en fejlinjektionshandling udføres, opretter operatørerne pods og kører nogle Ansible-samlinger. Så udviklere behøver ikke skrive deres egne handlinger for at udføre.
Pystol giver færdige handlinger til at teste systemet. Alligevel, hvis en udvikler ønsker at oprette en ny handling, kan det gøres ved hjælp af GoLang og Python.
Det giver et kontinuerligt integrations-dashboard for at give en oversigt over alle joboperationerne. Du kan køre Pystol lokalt eller implementere det i en container ved hjælp af dets docker-image. Pystol har to grænseflader, den ene er Web UI, og den anden er gennem CLI. Naturligvis er Web UI en bedre mulighed.
Muxy
Muxy er en proxy til at teste dine modstandsdygtighed og fejltolerancemønstre for distribuerede systemfejl i den virkelige verden. Det kan manipulere med transportniveau (lag 4), TCP-sessionsniveau (lag 5) og HTTP-protokolniveau (lag 7).
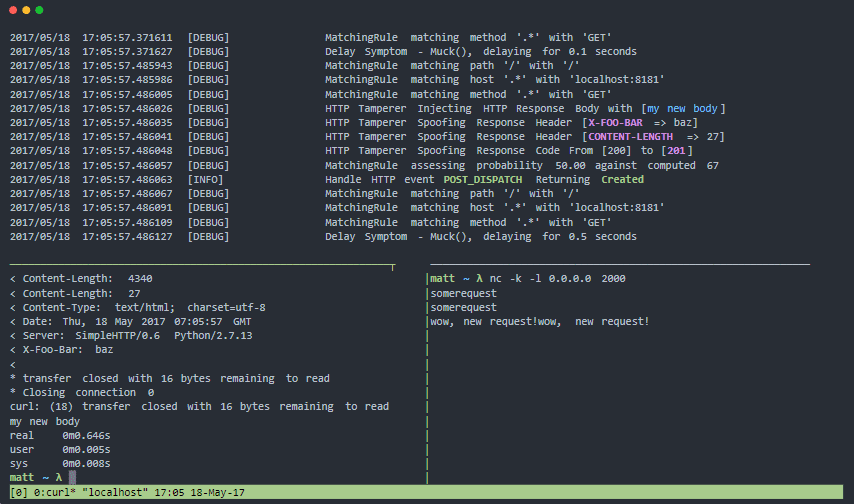
Muxy funktioner:
- Modulær arkitektur og let udvidelse
- Har officiel havnemandscontainer
- Nem at installere, ingen afhængigheder påkrævet.
- Ideel til kontinuerlig test af modstandsdygtighed
- Simulerer netværksforbindelsesproblemer for distribuerede systemer og mobile enheder
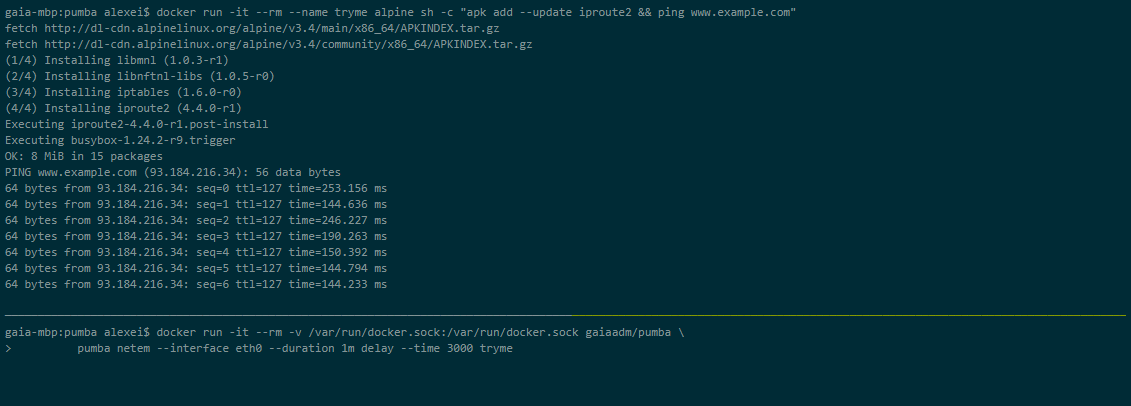
Pumba
Pumba er et kommandolinjeværktøj, der udfører kaostest for docker-containere. Med Pumba crasher du med vilje applikationens docker-containere for at se, hvordan systemet reagerer. Du kan også udføre stresstest på containerressourcerne såsom CPU, hukommelse, filsystem, input/output osv.
Du kan også køre Pumba på en Kubernetes-klynge. Du skal bruge DaemonSets til at implementere Pumba på Kubernetes noder. Du kan bruge flere Pumba-beholdere til at køre flere Pumba-kommandoer i det samme DaemonSet.
ChaosBlade
ChaosBlade er et open source-værktøj til at injicere eksperimenter i systemerne fra Alibaba. Den tester alle de fejl, Alibaba har stået over for i de sidste ti år og anvender bedste praksis for at undgå dem. Det følger kaos-tekniske principper for at kontrollere fejltolerancen for distribuerede systemer.
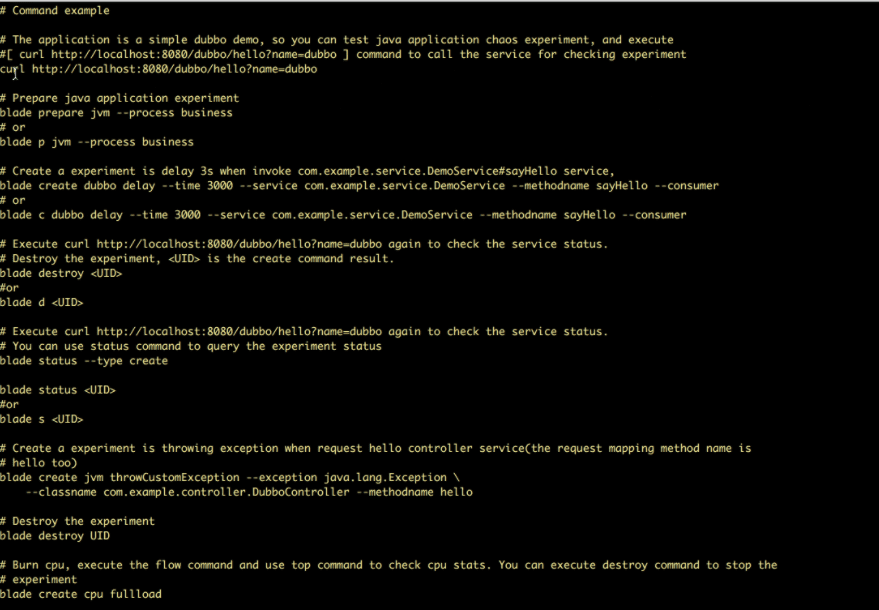
ChaosBlade funktioner:
- Giver eksperimentelle scenarier for flere ressourcer såsom CPU, netværk, hukommelse, disk osv.
- Leverer eksperimentelle scenarier for noder, netværk og pods på Kubernetes-platformen
- Giver brugervenlige CLI-kommandoer til at udføre eksperimenter
Lakmus
Lakmus følger cloud-native kaos engineering principper. Lakmusværktøjets mission er at levere en komplet ramme til at finde svagheder i dine Kubernetes-systemer og dine kørende applikationer på Kubernetes.
Den har en kaos-operatør og CRD’erne (CustomResourceDefinitions) omkring det, hvilket tillader plug-and-play-kapacitet. Det handler om at sætte din kaoslogik ind i et docker-billede, kaste det ind i en lakmusramme og få dem orkestreret ved hjælp af CRD’erne.

Lakmus funktioner:
- Hjælper ingeniører og udviklere af webstedspålidelighed med at finde svagheder i Kubernetes-systemet
- Giver klar til brug generiske eksperimenter
- Giver Chaos API til styring af kaos workflow
- Litmus SDK understøtter Go, Python og Ansible til at oprette dine egne eksperimenter.
Gremlin
Gremlin hjælper ingeniører med at bygge mere robust software. Det giver en platform til at køre kaos-tekniske eksperimenter sikkert, sikkert og ligetil.

Du kan eftertænksomt injicere fejl i værter eller containere med gremlin, uanset hvor de er, uanset om det er den offentlige sky eller dit eget datacenter.
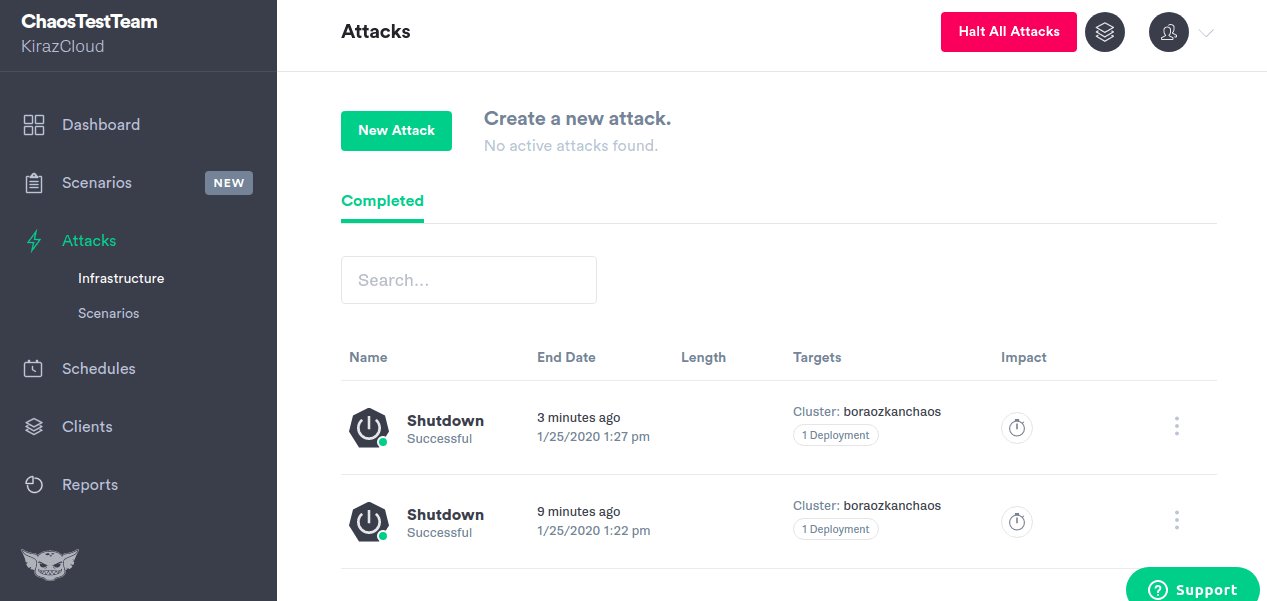
Gremlin funktioner:
- Installerer letvægtsmiddel på dine værter eller beholdere for at injicere fejl
- Giver 10+ forskellige infrastrukturangrebstilstande
- State gremlins lader dig manipulere systemtiden, lukke eller genstarte værter og dræbe processorer.
- Netværksgremlins kan injicere latens for at introducere pakketab eller droppe trafikken.
- Gremlins Alfi-biblioteksangreb kan konfigureres, startes og stoppes via webappen. API eller CLI
- Giver dig mulighed for at målrette den eksplosionsradius, du vil angribe præcist
- Giver dig mulighed for at stoppe alle angreb og rulle systemet tilbage til en stabil tilstand
Steadybit
Steadybit har til formål at reducere nedetiden proaktivt og giver synlighed i systemproblemer. Du kan køre dette værktøj lokalt på din infrastruktur eller cloud as a service (SaaS).
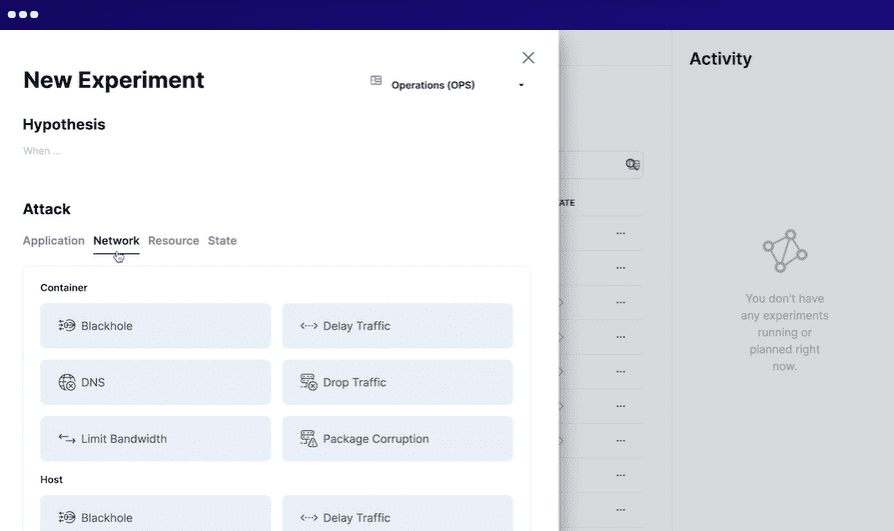
For at bruge Steadybit definerer du situationen, simulerer eksperimenterne, udfører de simulerede eksperimenter på produktionen og automatiserer alle eksperimenterne. Det kører intelligente agenter på dit system for at opdage potentielle problemer og svagheder. Den integreres let med flere systemer.
Konklusion
Gå videre og vær modig nok til at anvende kaos-tekniske principper og teste din produktion med de ovennævnte værktøjer. Disse værktøjer vil hjælpe dig med at finde flere uidentificerede svagheder i dit system, og det vil hjælpe dig med at gøre dit system mere modstandsdygtigt.