

Video deepfakes betyder, at du ikke kan stole på alt, hvad du ser. Nu kan lyddeepfakes betyde, at du ikke længere kan stole på dine ører. Var det virkelig præsidenten, der erklærede krig mod Canada? Er det virkelig din far i telefonen, der beder om sin e-mail-adgangskode?
Tilføj endnu en eksistentiel bekymring til listen over, hvordan vores egen hybris uundgåeligt kan ødelægge os. Under Reagan-æraen var de eneste reelle teknologiske risici truslen om nuklear, kemisk og biologisk krigsførelse.
I de følgende år har vi haft muligheden for at blive besat af nanoteknologiens grå snert og globale pandemier. Nu har vi deepfakes – folk mister kontrollen over deres lighed eller stemme.
Indholdsfortegnelse
Hvad er en Audio Deepfake?
De fleste af os har set en video deepfake, hvor deep-learning algoritmer bruges til at erstatte en person med en andens lighed. De bedste er nervepirrende realistiske, og nu er det lydens tur. En lyddeepfake er, når en “klonet” stemme, der potentielt ikke kan skelnes fra den rigtige persons, bruges til at producere syntetisk lyd.
“Det er ligesom Photoshop for stemme,” sagde Zohaib Ahmed, CEO for Ligner AI, om hans firmas stemmekloningsteknologi.
Men dårlige Photoshop-job kan let afkræftes. Et sikkerhedsfirma, vi talte med, sagde, at folk normalt kun gætter, om en lyd-deepfake er ægte eller falsk med omkring 57 procent nøjagtighed – ikke bedre end en møntvending.
Derudover, fordi så mange stemmeoptagelser er af lavkvalitets telefonopkald (eller optaget på støjende steder), kan lyddeepfakes gøres endnu mere umulige at skelne. Jo dårligere lydkvaliteten er, jo sværere er det at opfange de afslørende tegn på, at en stemme ikke er ægte.
Men hvorfor skulle nogen overhovedet have brug for en Photoshop til stemmer?
Det overbevisende etui til syntetisk lyd
Der er faktisk en enorm efterspørgsel efter syntetisk lyd. Ifølge Ahmed er “ROI’et meget øjeblikkeligt.”
Dette gælder især, når det kommer til spil. Tidligere var tale den ene komponent i et spil, der var umulig at skabe on-demand. Selv i interaktive titler med scener i biografkvalitet gengivet i realtid, er verbale interaktioner med ikke-spillende karakterer altid i det væsentlige statiske.
Nu har teknologien dog indhentet. Studier har potentialet til at klone en skuespillers stemme og bruge tekst-til-tale-motorer, så karakterer kan sige hvad som helst i realtid.
Der er også mere traditionelle anvendelser inden for annoncering og teknisk og kundesupport. Her er en stemme, der lyder autentisk menneskelig og reagerer personligt og kontekstuelt uden menneskelig input, det vigtige.
Stemmekloningsvirksomheder er også begejstrede for medicinske applikationer. Selvfølgelig er stemmeerstatning ikke noget nyt inden for medicin – Stephen Hawking brugte en berømt robot-syntetiseret stemme efter at have mistet sin egen i 1985. Men moderne stemmekloning lover noget endnu bedre.
I 2008, syntetisk stemme selskab, CereProc, gav den afdøde filmkritiker, Roger Ebert, sin stemme tilbage, efter at kræften tog den væk. CereProc havde udgivet en webside, der gjorde det muligt for folk at skrive beskeder, som derefter ville blive talt med tidligere præsident George Bushs stemme.
“Ebert så det og tænkte, ‘jamen, hvis de kunne kopiere Bushs stemme, skulle de være i stand til at kopiere min’,” sagde Matthew Aylett, CereProcs videnskabelige chef. Ebert bad derefter virksomheden om at skabe en erstatningsstemme, hvilket de gjorde ved at behandle et stort bibliotek af stemmeoptagelser.
“Det var en af de første gange, nogen nogensinde havde gjort det, og det var en rigtig succes,” sagde Aylett.
I de senere år har en række virksomheder (herunder CereProc) arbejdet med ALS foreningen på Projekt Revoice at give syntetiske stemmer til dem, der lider af ALS.

Sådan fungerer syntetisk lyd
Stemmekloning har et øjeblik lige nu, og en række virksomheder er ved at udvikle værktøjer. Ligner AI og Beskriv har online demoer, alle kan prøve gratis. Du optager bare de sætninger, der vises på skærmen, og på få minutter bliver en model af din stemme oprettet.
Du kan takke AI – specifikt deep-learning algoritmer – for at være i stand til at matche optaget tale med tekst for at forstå komponentfonemerne, der udgør din stemme. Den bruger derefter de resulterende sproglige byggeklodser til at tilnærme ord, den ikke har hørt dig tale.
Den grundlæggende teknologi har eksisteret i et stykke tid, men som Aylett påpegede, krævede det noget hjælp.
“At kopiere stemme var lidt som at lave wienerbrød,” sagde han. “Det var lidt svært at gøre, og der var forskellige måder, du skulle finjustere det i hånden for at få det til at fungere.”
Udviklere havde brug for enorme mængder af optagede stemmedata for at opnå acceptable resultater. Så for et par år siden åbnede sluserne sig. Forskning inden for computersyn viste sig at være kritisk. Forskere udviklede generative adversarial networks (GAN’er), som for første gang kunne ekstrapolere og lave forudsigelser baseret på eksisterende data.
“I stedet for at en computer ser et billede af en hest og siger ‘det her er en hest’, kunne min model nu lave en hest om til en zebra,” sagde Aylett. “Så eksplosionen i talesyntese nu er takket være det akademiske arbejde fra computersyn.”
En af de største innovationer inden for stemmekloning har været den overordnede reduktion i, hvor meget rådata der er nødvendigt for at skabe en stemme. Tidligere havde systemer brug for snesevis eller endda hundredvis af timers lyd. Nu kan der imidlertid genereres kompetente stemmer fra kun få minutter af indhold.
Den eksistentielle frygt for ikke at stole på noget
Denne teknologi er sammen med atomkraft, nanoteknologi, 3D-print og CRISPR samtidig spændende og skræmmende. Der har jo allerede været tilfælde i nyhederne om, at folk er blevet narret af stemmekloner. I 2019 hævdede et firma i Storbritannien, at det var det narret af en lyddeepfake telefonopkald til at overføre penge til kriminelle.
Du behøver heller ikke gå langt for at finde overraskende overbevisende lydforfalskninger. YouTube-kanal Vokal syntese indeholder kendte mennesker, der siger ting, de aldrig har sagt, f.eks George W. Bush læser “In Da Club” af 50 Cent. Det er spot on.
Andre steder på YouTube kan du høre en flok eks-præsidenter, bl.a Obama, Clinton og Reagan, rapper NWA. Musikken og baggrundslydene hjælper med at skjule noget af det åbenlyse robotiske fejl, men selv i denne uperfekte tilstand er potentialet indlysende.
Vi eksperimenterede med værktøjerne på Ligner AI og Beskriv og skabte stemmeklon. Descript bruger en stemmekloningsmotor, der oprindeligt hed Lyrebird og var særlig imponerende. Vi var chokerede over kvaliteten. At høre din egen stemme sige ting, du ved, du aldrig har sagt, er nervepirrende.
Der er bestemt en robotkvalitet ved talen, men ved en afslappet lytning ville de fleste mennesker ikke have nogen grund til at tro, at det var falsk.
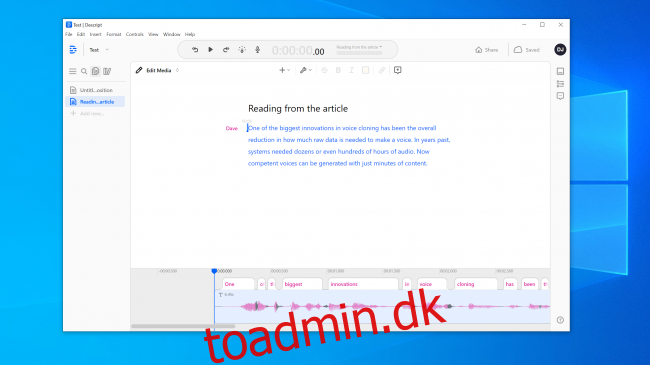
Vi havde endnu større forhåbninger til Resemble AI. Det giver dig værktøjerne til at skabe en samtale med flere stemmer og variere dialogens udtryksevne, følelser og tempo. Vi mente dog ikke, at stemmemodellen fangede de væsentlige egenskaber ved den stemme, vi brugte. Faktisk var det usandsynligt at narre nogen.
En Resemble AI-repræsentant fortalte os “de fleste mennesker er blæst bagover af resultaterne, hvis de gør det korrekt.” Vi byggede en stemmemodel to gange med lignende resultater. Så det er åbenbart ikke altid let at lave en stemmeklon, som du kan bruge til at udføre et digitalt røveri.
Alligevel føler Lyrebird (som nu er en del af Descript) grundlægger, Kundan Kumar, at vi allerede har passeret den tærskel.
“For en lille procentdel af tilfældene er det allerede der,” sagde Kumar. “Hvis jeg bruger syntetisk lyd til at ændre nogle få ord i en tale, er det allerede så godt, at du vil have svært ved at vide, hvad der har ændret sig.”
Vi kan også antage, at denne teknologi kun bliver bedre med tiden. Systemer skal bruge mindre lyd for at skabe en model, og hurtigere processorer vil være i stand til at bygge modellen i realtid. Smartere AI vil lære, hvordan man tilføjer mere overbevisende menneskelignende kadence og vægt på tale uden at have et eksempel at arbejde ud fra.
Hvilket betyder, at vi måske kryber tættere på den udbredte tilgængelighed af ubesværet stemmekloning.
Pandoras æskes etik
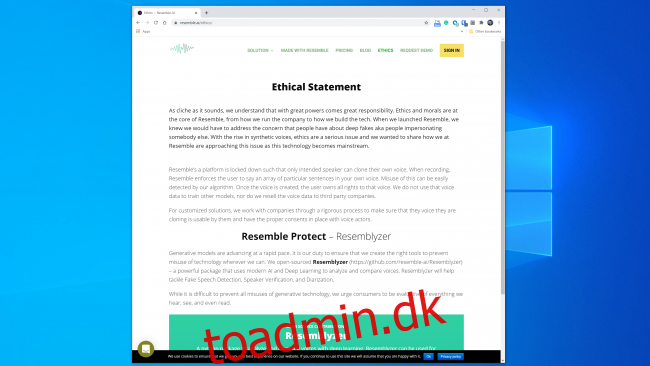
De fleste virksomheder, der arbejder i dette område, ser ud til at være klar til at håndtere teknologien på en sikker og ansvarlig måde. Resemble AI har for eksempel en hel “Etik”-sektion på sin hjemmeside, og følgende uddrag er opmuntrende:
“Vi arbejder med virksomheder gennem en streng proces for at sikre, at den stemme, de kloner, er brugbar af dem og har de rette samtykker på plads med stemmeskuespillere.”
Ligeledes sagde Kumar, at Lyrebird var bekymret over misbrug fra starten. Det er derfor nu, som en del af Descript, det kun giver folk mulighed for at klone deres egen stemme. Faktisk kræver både Resemble og Descript, at folk optager deres samples live for at forhindre stemmekloning uden samtykke.
Det er opmuntrende, at de store kommercielle aktører har pålagt nogle etiske retningslinjer. Det er dog vigtigt at huske på, at disse virksomheder ikke er gatekeepere til denne teknologi. Der findes allerede en række open source-værktøjer i naturen, som der ikke er nogen regler for. Ifølge Henry Ajder, leder af trusselsefterretning kl Deeptrace, behøver du heller ikke avanceret kodningsviden for at misbruge det.
“Meget af fremskridtene i rummet er kommet gennem samarbejde på steder som GitHub, ved hjælp af open source-implementeringer af tidligere offentliggjorte akademiske artikler,” sagde Ajder. “Det kan bruges af alle, der har moderate færdigheder i kodning.”
Sikkerhedseksperter har set alt dette før
Kriminelle har forsøgt at stjæle penge via telefon længe før stemmekloning var mulig, og sikkerhedseksperter har altid været på vagt for at opdage og forhindre det. Sikkerhedsfirma Pindrop forsøger at stoppe banksvindel ved at verificere, om en opkalder er den, han eller hun hævder at være fra lyden. Alene i 2019 hævder Pindrop at have analyseret 1,2 milliarder stemmeinteraktioner og forhindret omkring $470 millioner i svindelforsøg.
Før stemmekloning prøvede svindlere en række andre teknikker. Det enkleste var bare at ringe andre steder fra med personlige oplysninger om mærket.
“Vores akustiske signatur giver os mulighed for at fastslå, at et opkald faktisk kommer fra en Skype-telefon i Nigeria på grund af lydegenskaberne,” sagde Pindrop CEO, Vijay Balasubramaniyan. “Så kan vi sammenligne, at vide, at kunden bruger en AT&T-telefon i Atlanta.”
Nogle kriminelle har også gjort karriere ud af at bruge baggrundslyde til at smide bankrepræsentanter fra sig.
“Der er en svindler, vi kaldte Chicken Man, som altid havde haner gående i baggrunden,” sagde Balasubramaniyan. “Og der er en dame, der brugte en babygrædende i baggrunden til i det væsentlige at overbevise call center-agenterne om, at ‘hey, jeg går igennem en hård tid’ for at få sympati.”
Og så er der de mandlige kriminelle, der går efter kvinders bankkonti.
“De bruger teknologi til at øge frekvensen af deres stemme, for at lyde mere feminin,” forklarede Balasubramaniyan. Disse kan være succesfulde, men “ind imellem roder softwaren op, og de lyder som Alvin og Chipmunks.”
Selvfølgelig er stemmekloning blot den seneste udvikling i denne stadigt eskalerende krig. Sikkerhedsfirmaer har allerede fanget svindlere, der bruger syntetisk lyd i mindst ét spearfishing-angreb.
“Med det rigtige mål kan udbetalingen være massiv,” sagde Balasubramaniyan. “Så det giver mening at dedikere tiden til at skabe en syntetiseret stemme for den rigtige person.”
Kan nogen fortælle, om en stemme er falsk?

Når det kommer til at genkende, om en stemme er blevet falsk, er der både gode og dårlige nyheder. Det dårlige er, at stemmekloner bliver bedre hver dag. Deep-learning-systemer bliver smartere og laver mere autentiske stemmer, der kræver mindre lyd at skabe.
Som du kan se fra dette klip af Præsident Obama beder MC Ren om at tage stilling, er vi også allerede nået til det punkt, hvor en omhyggeligt konstrueret stemmemodel kan lyde ret overbevisende for det menneskelige øre.
Jo længere et lydklip er, jo større er sandsynligheden for, at du opdager, at der er noget galt. For kortere klip bemærker du måske ikke, at det er syntetisk – især hvis du ikke har nogen grund til at stille spørgsmålstegn ved dets legitimitet.
Jo klarere lydkvaliteten er, desto nemmere er det at bemærke tegn på en lyd-deepfake. Hvis nogen taler direkte ind i en mikrofon i studiekvalitet, vil du være i stand til at lytte tæt. Men en ringekvalitetsoptagelse af telefonopkald eller en samtale optaget på en håndholdt enhed i en støjende parkeringskælder vil være meget sværere at evaluere.
Den gode nyhed er, at selvom mennesker har problemer med at adskille ægte fra falsk, har computere ikke de samme begrænsninger. Heldigvis findes der allerede værktøjer til stemmebekræftelse. Pindrop har en, der sætter deep-learning-systemer op mod hinanden. Den bruger begge dele til at finde ud af, om en lydprøve er den person, den skal være. Den undersøger dog også, om et menneske overhovedet kan lave alle lydene i samplet.
Afhængigt af kvaliteten af lyden indeholder hvert sekund tale mellem 8.000-50.000 dataprøver, der kan analyseres.
“De ting, vi typisk leder efter, er begrænsninger på tale på grund af menneskelig evolution,” forklarede Balasubramaniyan.
For eksempel har to vokallyde en mindst mulig adskillelse fra hinanden. Dette skyldes, at det ikke er fysisk muligt at sige dem hurtigere på grund af den hastighed, hvormed musklerne i din mund og stemmebånd kan omkonfigurere sig selv.
“Når vi ser på syntetiseret lyd,” sagde Balasubramaniyan, “ser vi nogle gange ting og siger, ‘det kunne aldrig være blevet genereret af et menneske, fordi den eneste person, der kunne have genereret dette, skal have en syv fod lang hals. ”
Der er også en lydklasse kaldet “frikativer”. De dannes, når luft passerer gennem en smal indsnævring i din hals, når du udtaler bogstaver som f, s, v og z. Frikativer er især svære for deep-learning-systemer at mestre, fordi softwaren har problemer med at skelne dem fra støj.
Så, i det mindste for nu, falder software til stemmekloning over det faktum, at mennesker er poser med kød, der strømmer luft gennem huller i deres