
Gør dig klar til at vide alt om den næste generations fremtid for databaser, dvs. serverløse databaser!
Enhver database, der overholder kerneprincipperne for serverløs computing, er en serverløs database. Serverløs database blev skabt til arbejdsbelastninger, der er uforudsigelige og kan ændre sig hurtigt.
Serverløs betyder ikke, at der ikke er behov for servere. Det betyder, at de underliggende servere ikke er forpligtet til at blive administreret, klargjort eller betalt af dig.
Du betaler for de ressourcer, du bruger baseret på deres CPU- og RAM-kapacitet og hvor aktive de er.
Indholdsfortegnelse
Sådan fungerer en serverløs database
Den serverløse databasemodel er afhængig af adskillelse af behandling og lagring. Du skal oprette et slutpunkt og indstille minimums- og maksimumskapaciteten.
Billedkredit: Simform
Derefter kan du sende forespørgsler til slutpunktet. Denne proxy fungerer som et link til et stort antal databaseressourcer. Dette gør det muligt for dine forbindelser at forblive intakte, selv skaleringsoperationer finder sted bag kulisserne.
At adskille lagring fra behandling har en anden fordel. Det er muligt at nedskalere til nul behandling, og du skal kun betale for opbevaring. Skalering kan udføres på kun 5 sekunder, afhængigt af applikationen. Du har også adgang til en pulje af “varme” ressourcer klar til at hjælpe dig med dine behov.
Serverløs database: Fordele

Omkostningseffektivitet
Et fast antal servere er dyrere end en serverløs database og tager længere tid at købe. Det kan være billigere end at oprette en autoskaleringsgruppe, og det er også mere omkostningseffektivt, fordi bin-pakningen af maskinressourcer gør det mere effektivt.
Dette omfatter licensering, installation, vedligeholdelse, support og patching. Du bliver kun opkrævet for den tid og hukommelse, du bruger til at køre din kode.
Automatiseret skalerbarhed
Udviklere behøver ikke at konfigurere eller opsætte autoskaleringspolitikker eller -systemer for at opnå serverløs skalering baseret på arbejdsbelastning. Alt dette falder på skuldrene af cloud-udbyderen, som skal opfylde de faktiske krav med de passende ydeevner.
Hurtige implementeringer og opdateringer
Serverløs infrastruktur eliminerer behovet for at uploade kode til servere og konfigurere backend-indstillinger for at lave en fungerende applikation. Det er nemt for udviklere at uploade små stykker kode og derefter frigive et nyt produkt. Udviklere kan uploade begge koder på én gang og én funktion ad gangen.
Dette gør det nemt at opdatere, patche, rette eller tilføje nye funktioner hurtigt til en app. Udviklere kan foretage små ændringer i en applikation i stedet for at opdatere hele applikationen.
Højere produktivitet
Du vil få mere ud af dit serverløse system, hvis du bruger mindre tid på det, gør mindre indsats på områder, hvor interaktion er påkrævet, og hyrer et team af fagfolk, der har den optimale størrelse til at opnå bedre resultater.
Serverløs database: Ulemper
Koldstartsproblemer
Håndtering af koldstart er et af de vigtigste og mest udfordrende aspekter på dette felt. En serverløs database, der ikke bliver brugt, vil simpelthen være inaktiv for at spare ressourcer og forhindre unødvendig ydeevne.
Systemet “vågner op” og har brug for tid til at genstarte alle dets processer. Du kan opleve forsinkelser og langsomme svartider, hvis du er den første person, der rører ved systemet ved dets koldstart.
Svært ved at teste og fejlfinde applikationer
Den serverløse model byder på en anden udfordring. Det er svært at replikere et serverløst miljø for at teste og overvåge kodeydelsen, før den går live. Dette skyldes til dels det faktum, at udviklere ikke har adgang til cloud-udbyderens backend-tjenester.
For at debugge komplekse systemer i dybden og effektivt kan du ikke bruge en profiler eller en debugger. Du har mulighed for at prøve tredjepartsværktøjer, der i stigende grad er tilgængelige på markedet.
Mere overvågning
Serverløse løsninger kræver, at du lægger større vægt på overvågning og påpegning af ydeevneproblemer eller overforbrug af ressourcer. Det skyldes i høj grad, at cloud-løsninger sjældent er open source.
Sælger Lock-in
Når du migrerer til en anden udbyder, kan det give problemer at vælge en serverløs model. Dette skyldes, at hver udbyder har forskellige arbejdsgange og funktioner.
Funktioner i serverløs database
Serverløse databaser tilbyder nogle af de mest spændende funktioner, såsom:
#1. Multi-lejer arkitektur
Serverløse databaser giver fordelen ved at kunne bruge en enkelt puljeressource, der kan bruges til flere projekter i din organisation. Dette er et stort plus for udviklerne, da de ikke behøver at oprette applikationsspecifikke siled-datakilder.
Multi-lejer-arkitektur gør dette muligt. Udviklere kan konfigurere, konfigurere og implementere flere applikationer inden for en enkelt databaseklynge.
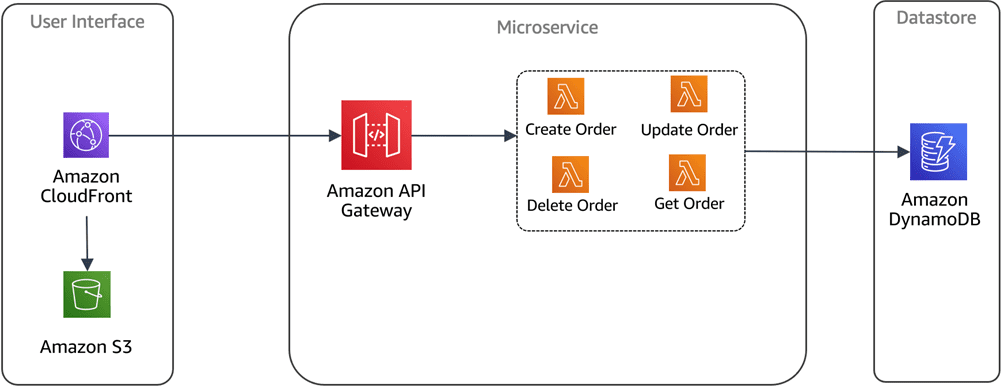 Billedkredit: AWS
Billedkredit: AWS
#2. Geo distribution
Fordi de fleste virksomheder opererer på global basis, er det vigtigt, at data er tilgængelige over hele kloden. Realtidsoplevelsen kan forbedres af nærheden til datacentre. Et fejlpunkt er også elimineret, så muligheden for en fejl er meget usandsynlig.
Serverløse databaser giver dig mulighed for at replikere flere datasæt over hele kloden uden yderligere værktøjer eller tilpasset udvikling.
#3. Lidt eller ingen manuel serveradministration
Serverløs er en forkert betegnelse. Det er en samling af servere, der er blevet abstraheret væk og er automatiseret for at gøre det nemmere for dig at administrere dem. Alle de manuelle opgaver, såsom klargøring, kapacitetsplanlægning, skalering, vedligeholdelse, opdateringer og så videre, udføres stadig bag kulisserne. De er meget nemme at bruge og kræver lidt eller ingen manuel indgriben.
#4. Forbrugsbaseret fakturering
Den serverløse database, da dens gebyrer er baseret på brug, er den mest omkostningseffektive. Opbevaring er ikke påkrævet. Du betaler kun for det, du bruger. Hvis du vil undgå budgetoverskridelser, kan du sætte en forbrugsgrænse.
Relationelle vs. ikke-relationelle serverløse databaser

De digitale tidsalderdata kan klassificeres i operationelle og analytiske data. Lad os se på et par forskellige databasemuligheder, som udviklere søger og se, hvordan de sammenligner.
De fleste virksomheder kræver OLTP (operationel) og OLAP (analytisk) systemer til at gemme deres data. De kan enten bruge en relationel eller ikke-relationel database til at understøtte deres forretningsbehov.
Relationel serverløs database
En relationel database er en databasetype, der organiserer og indsamler data i henhold til foruddefinerede relationer mellem nøgledatapunkter. Den organiserer data, så flere brugere kan finde og sortere data uden at ændre den logiske datakategorisering.
Det eliminerer dataduplikering i lagringsprocesser. Structured Query Language er applikationsprogramgrænsefladen (API) til en relationel databank.
Dette system præsenterer data i tabelformat. Denne tabel repræsenterer en enhed, såsom et produkt eller en mobilapp. Hver række er den faktiske værdi, og hver række har en unik identifikator, der er en forekomst af denne type enhed. Det er derfor, plader kaldes.
På den anden side indeholder kolonnerne dataenes attributter. De er enhedens faktiske værdi. Det er muligt at få adgang til dataene uden at skulle reorganisere databasetabellen.
NoSQL (ikke-relationel) serverløs database
Ikke-relationelle databaser (NoSQL) er mere tilbøjelige til at blive distribueret end SQL-databaser. Det kan bruges med et stort antal databaser. Virksomheder skal bruge moderne funktioner såsom NoSQL-databaser til at bygge cloud-native applikationer.
NoSQL-serverløse databaser bruges i realtidswebapps. De er enkle i designet og kan hurtigt håndtere store mængder data med horisontal skalering. Dette er ideelt til situationer, hvor skemaet er uklart, og høje indtagelseshastigheder kan være påkrævet.
NoSQL serverløse databaser er meget populære, da de gemmer store mængder data i mange former, herunder grafer, dokumenter, nøgle/værdi-par og kolonneorienterede datastrukturer. Dette gør det nemt for udviklere at ændre datastrukturen.
Hvorfor skal man bruge serverløse databaser?
Serverløse databaser er en fantastisk mulighed for små teams, der ikke har nok personale til at administrere og skalere traditionelle databaser. Serverløse databaser kræver kun lidt infrastruktur og vedligeholdelse. Det betyder, at dit team skal bruge mindre tid på at vedligeholde systemet. Det er også nemt at oprette nye tabeller og teste nye funktioner ved hjælp af en serverløs database.
Endelig omkostninger. Serverløse databaser giver dig mulighed for kun at betale for det, du bruger, uden at skulle konfigurere og finjustere omkostninger som traditionelle databaser. Serverløse databaser er fantastiske for udviklere og teams, der har brug for at skubbe nye funktioner ud hurtigt.
Brug tilfælde af serverløs database

#1. Nye applikationer
Et par minutters brug i løbet af en uge eller dag. Hvis du ejer en blog med lav trafik og kun ønsker at betale for den tid, en bruger besøger dit websted, er dette en mulighed. Du betaler per sekund for de databaseressourcer, du bruger.
#2. Elastisk ændring af størrelse til live videoudsendelse
Live videoudsendelse er muliggjort af en serverløs arkitektur. Flere publikumsmedlemmer kan interagere i scenarier med live videoudsendelse. Værten kan være forbundet til flere mikrofoner samtidigt. En vært kan forbinde flere publikummer eller venner til skærmen og derefter syntetisere billedet til ét scenarie, der præsenteres for livestream-seere.
#3. Sjældent brugte applikationer
Hvis du har en app, som du er stolt af og ikke ved, hvordan den bliver modtaget, og fordi du ikke ønsker, at appen skal fejle, er denne metode noget for dig. Du skal blot oprette et slutpunkt, og den serverløse database skaleres automatisk for at opfylde behovene i din applikation.
#4. Internet of Things (IoT)
IoT kan beskrives som et begreb, der beskriver enheder, der findes i hjemmet i dag, og som kan oprette forbindelse til internettet for at udføre forskellige funktioner. FaaS bliver i stigende grad brugt af disse enheder til at udføre deres opgaver. De sender og modtager kun data, når en hændelse udløser dem.
Virksomheder sparer penge ved ikke at skulle betale ekstra for computerkraft, som de ikke bruger. FaaS gør det muligt at skalere hurtigt og automatisk, så udviklere ikke behøver at bekymre sig om uforudsigelige brugsmønstre.
Konklusion
Disse scenarier viser, at serverløs arkitektur har mange fordele for udviklere og virksomheder. Serverløse databaser kan forbedre din computerhastighed og modstandsdygtighed og samtidig reducere tiden og omkostningerne ved skalering og ressourcer. Der er mange typer af serverløse databaser, både relationelle og ikke-relationelle. Men de har alle det samme mål: at skalere efter behov uden at tilføje administrationsbyrder og kun at reducere omkostningerne