
Opbygning af et automatiseret softwaresystem betød opsætning af flere servere med dedikeret CPU-konfiguration, hukommelse, lagring og andre ressourcer i mange år. Dernæst blev der dannet et team af administratorer til at administrere disse systemer. Derefter overtog udviklingsteamet infrastrukturen og begyndte at skabe processer, der forbinder serverne.
Denne proces kan være kompliceret, fordi den involverer mange forskellige grupper, der arbejder sammen mod et fælles mål. Disse interessekonflikter kan så være et problem.
Det kan også være ret dyrt. Dette kræver, at du har administratorer på din lønliste. Servere, som kører kontinuerligt, bruger ressourcer, selvom de ikke bliver brugt.
For at bevare den bedste ydeevne over tid har du brug for en automatisk skaleringsløsning, der automatisk skalerer serverressourcerne.
Cloud-platformen har én fordel: den giver dig mulighed for at skabe en ende-til-ende-arkitektur uden behov for opsætning af serverklynge. Fra et administrationsperspektiv er der ikke noget at fastholde.
Dette er en omkostningseffektiv mulighed for startups og minimumslevedygtige produktfaser (MVP) i projekter. Det er et godt udgangspunkt, hvis det er svært at forudsige fremtidige produktionsbelastninger og brugeraktivitet. Det er her, det kan være udfordrende at bestemme konfigurationen af klyngeservere.
Automatiseringen af processer gennem serverløse cloud-tjenester er det, der får serverløs arkitektur til at skille sig ud. Det forbinder tjenester og producerer resultater, der ligner traditionelle klyngeservere.
Dette er et eksempel på at bygge en sådan arkitektur ved kun at bruge native AWS-tjenester.
Indholdsfortegnelse
Afhentning af tjenesterne Serverless Flow
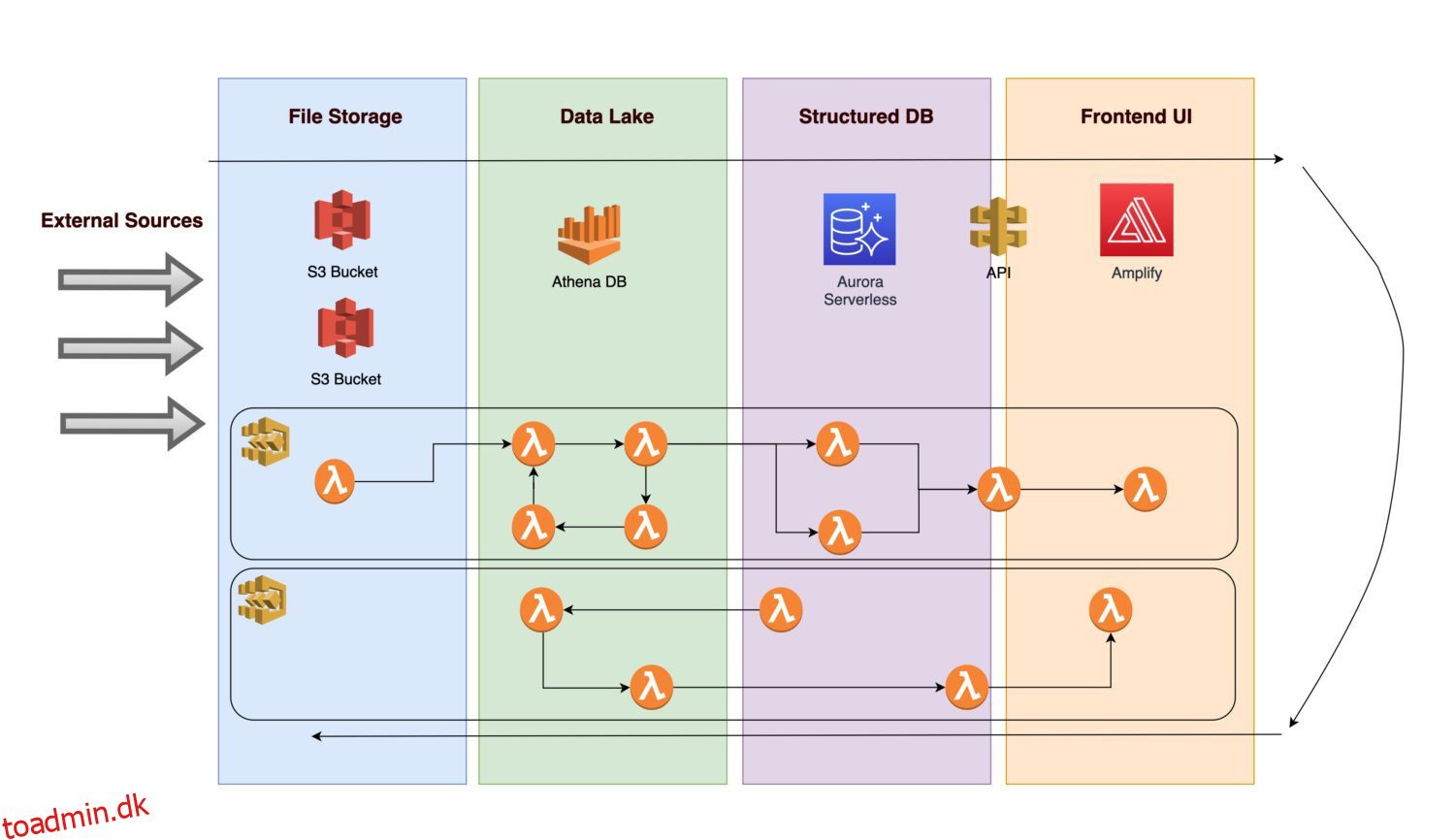
Forestil dig, at du gerne vil skabe en platform til at samle forskellige data og billeder (eller fotos) af nogle konkrete aktivers infrastruktur (dette kan være et hvilket som helst produktions- eller forsyningsaktiv).
- For at muliggøre fremtidige analyser, er det nødvendigt, at de indgående data først indlæses.
- Efter anvendelse af forretningsregler gemmer en back-end-procedure de beregnede output som normaliseret information i en relationel database.
- En applikationsfrontend, der viser normaliserede rene data, giver brugerne mulighed for at se resultaterne.
Lad os undersøge, hvilke komponenter arkitektur kunne omfatte.
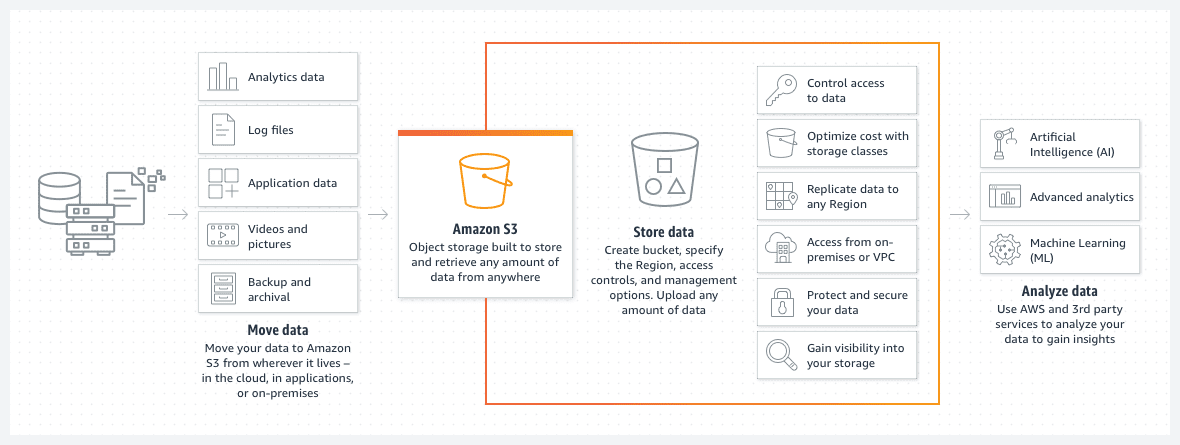
AWS S3 skovle
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Amazon S3 buckets er en fantastisk måde at gemme filer eller billeder i AWS-skyen. Prisen for opbevaring på S3-spanden er bemærkelsesværdig lav. Desuden sænker introduktionen af en S3 skovllivscykluspolitik denne pris yderligere.
En sådan politik vil automatisk flytte ældre filer til forskellige klasser af S3-bøtter, såsom et arkiv eller dyb arkivadgang. Klasserne adskiller sig da også med hastigheden af adgangstid, men for gamle data vil dette være mindre af et problem. Det tjener hovedsageligt til at få adgang til de arkiverede data i tilfælde af en presserende hændelse snarere end til standarddriftsbehov.
- Du kan organisere dine data i undermapper.
- Du bør indstille passende tilladelsesbegrænsninger.
- Tilføj tags til buckets for at gøre dem nemme at identificere og til mulig brug inden for dynamiske S3 bucket-politikker.
- Spanden er serverløs af design. Det er simpelthen en lagerplads til dine data.
En S3-spand er serverløs af design. Det er simpelthen en lagerplads til dine data.
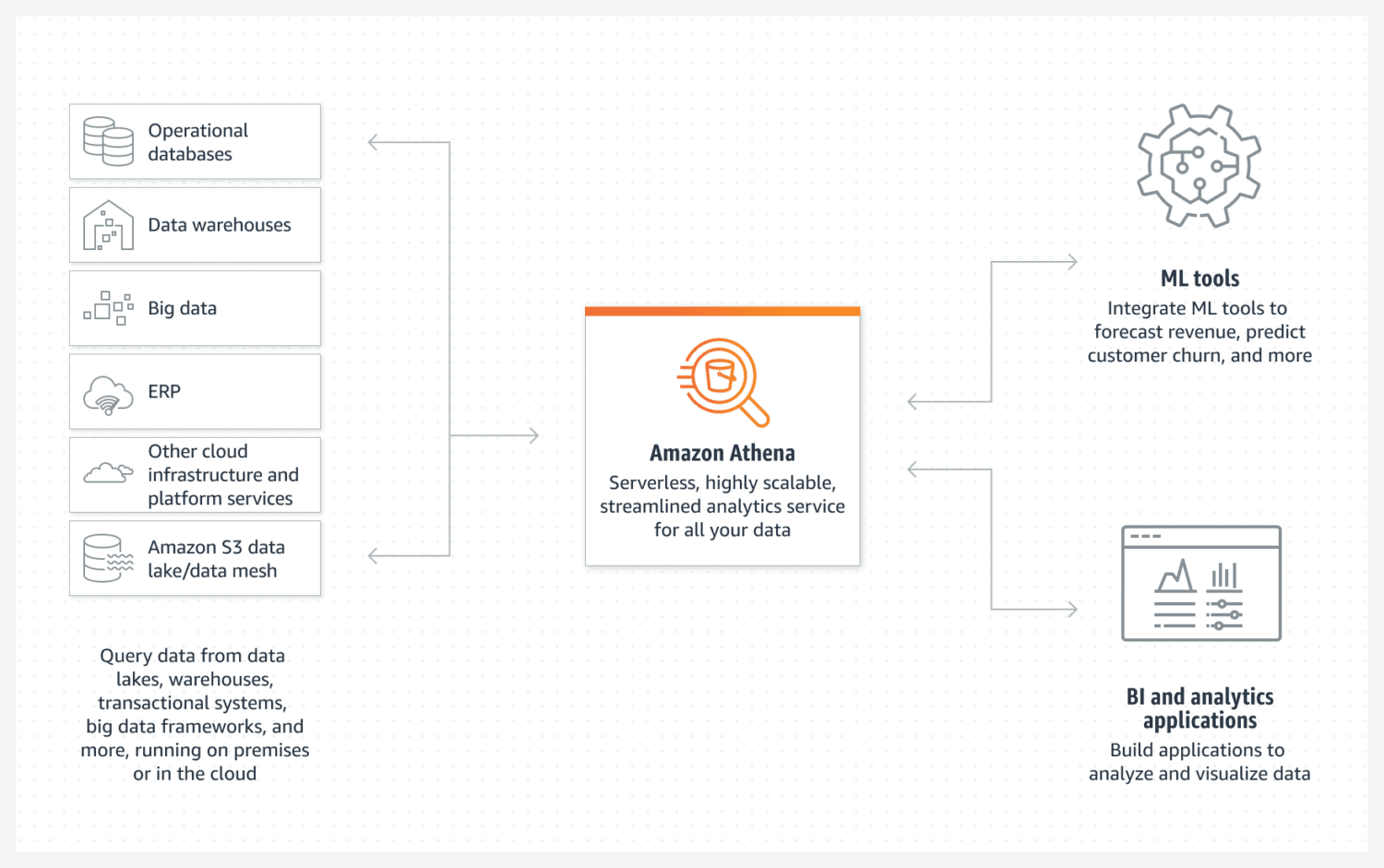
AWS Athena-database
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Athena gør det nemt at oprette en AWS grundlæggende datasø. Det er en database uden servere, der bruger en S3 bucket til at gemme sine data. Dataorganisering vedligeholdes af strukturerede filformater såsom parket eller CSV-filer (kommaseparerede værdier). S3-bøtten rummer filerne, og Athena henviser til dem, når processer vælger data fra databasen.
Bare vær opmærksom på, at Athena ikke understøtter forskellige funktionaliteter, der ellers anses for at være en standard, for eksempel opdateringserklæringer. Det er derfor, du skal se på Athena som en meget enkel mulighed.
Det understøtter dog indeksering og partitionering. Den kan også meget nemt skalere horisontalt, da dette er lige så komplekst som at tilføje nye skovle til infrastrukturen. For enkel, men funktionel oprettelse af datasøer, kan dette stadig være tilstrækkeligt i de fleste tilfælde.
For god ydeevne er det afgørende at vælge det bedste datadesign med fokus på fremtidig brug. Det er vigtigt at være meget klar over den måde, du ønsker at udvælge data på. Det er svært at genskabe tabeller senere, når de allerede er eksisterende og fyldt med masser af data.
Athena DB er et godt valg og passer godt til dit mål, hvis du ønsker at skabe en enkel og uforanderlig datapulje, der er let at skalere horisontalt over tid.
AWS Aurora-database
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Athena DB udmærker sig ved at gemme ukurerede data. Sådan vil du trods alt gemme dit originale indhold for at maksimere dets fremtidige genbrug. Det er dog langsomt at levere udvalgte resultater til en frontend-app.
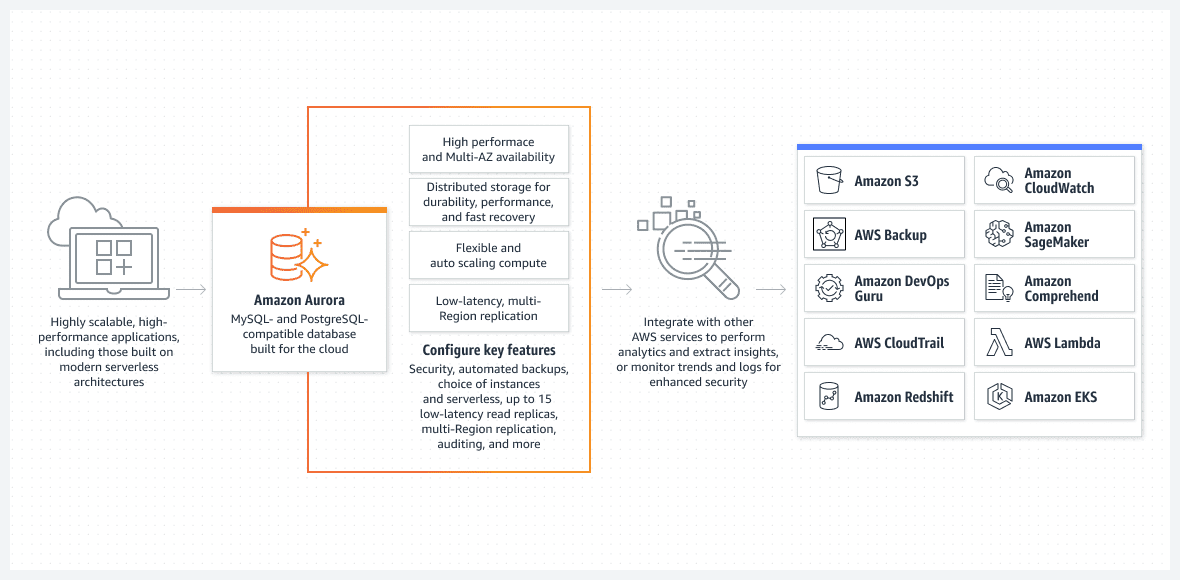
En af de bedste muligheder, hovedsageligt set ud fra et perspektiv med nem at udføre opsætning, er Aurora-databasen, der kører i serverløs tilstand.
Aurora er langt fra en grundlæggende database. Det er en af de mest avancerede native relationelle databaseløsninger i AWS. Det er også en meget kompleks native relationel databaseløsning, der forbedres med hver udgivelse.
Aurora er unik, fordi den kan køre i serverløs tilstand, hvilket gør, at den skiller sig ud fra andre relationelle tjenester. Sådan fungerer tilstanden:
- For at konfigurere Aurora-klyngen skal du bruge AWS-konsollen. Du skal angive standard CPU- og RAM-niveauer samt det maksimale interval for automatisk skaleringsfunktionalitet. Dette vil påvirke den ydeevne, som Aurora-klyngen dynamisk kan tilføje eller fjerne. Baseret på den aktuelle udnyttelse af databasen beslutter AWS sig for at skalere op eller ned.
- Aurora-klyngen starter ikke, medmindre brugeren eller processen starter en reel anmodning. For eksempel når den planlagte batchbehandling starter. Eller hvis applikationen udfører et back-end API-kald for at hente data fra en database. Databasen åbnes automatisk og forbliver aktiv i en forudbestemt tid, efter at anmodningsprocesserne er afsluttet.
- Aurora-klyngen vil automatisk lukke ned, hvis der ikke er mere arbejde i databasen.
For at understrege det endnu en gang, kører serverløs Aurora DB kun, når den skal udføre rigtigt arbejde. Den automatisk opstartede klynge vil igen lukke ned, hvis den ikke behandler noget arbejde. Det faktiske arbejde er, hvad du betaler for og ikke din ledige tid.
Den serverløse Aurora administreres fuldt ud af AWS og kræver ikke en administrator.
AWS Amplify
Amplify tilbyder en serverløs platform til hurtig implementering af frontend-applikationer lavet med JavaScript- og React-biblioteker. Der er ingen grund til at konfigurere klyngeservere. Brug AWS-konsollen til at implementere koden direkte, eller brug en automatiseret DevOps-pipeline.
Du kan kalde back-end API’er for at nå data, der er gemt i databaser. Disse opkald giver dig adgang til de faktiske data i frontend-applikationen. Den primære optimering af ydeevnen på back-end bør udføres af teamet. Du kan endda reducere muligheden for langsom respons i brugergrænsefladen yderligere, hvis du designer effektive udvalgte sætninger direkte i API-kaldene.
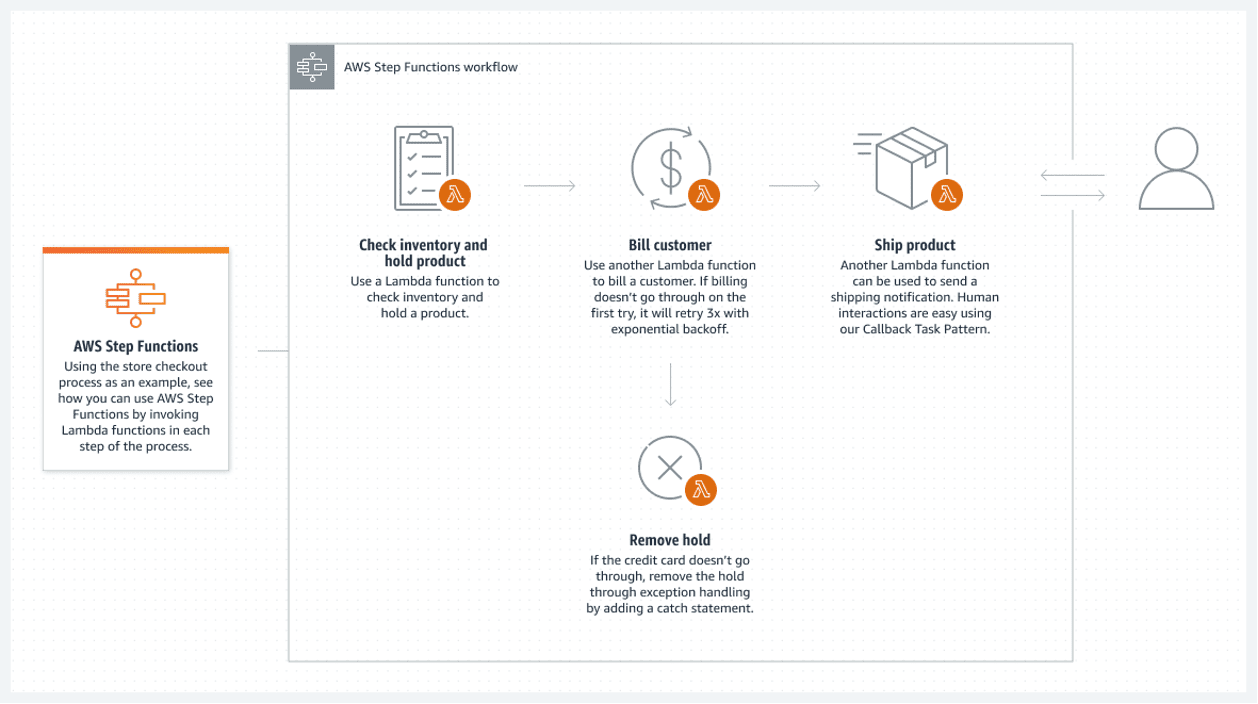
AWS-trinfunktioner
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Selvom alle større komponenter i et system er serverløse, garanterer dette ikke en fuldstændig serverløs arkitektur. Dette er kun muligt, hvis alle batch-processer mellem komponenterne er serverløse.
AWS Step-funktioner giver den bedste løsning på AWS-skyen. En tilsluttet liste over AWS Lambda-funktioner udgør trinfunktionen. Disse funktioner skaber et flowdiagram, der har klare start- og sluttilstande. En lambda-funktion, normalt skrevet i Python- eller Node JS-sprog, er en eksekverbar kodebit, der behandler alt, hvad der er nødvendigt.
Det følgende er et eksempel på, hvordan du kan udføre en trinfunktion:
Dette serverløse flow har en stor ulempe: hver lambda-funktion kan maksimalt køre i 15 minutter. Derfor kan opsplitning af flowet i mindre lambda-funktioner gøre dette mindre problematisk.
Det er muligt at kalde flere lambda-funktioner samtidigt i et trin, hvilket grundlæggende betyder at parallelisere et trin med flere lambdaer, der udføres samtidigt. Vent bare på, at al parallel lambdabehandling er færdig, før du fortsætter. Fortsæt derefter til næste lambdabehandling.
Afsluttende ord
Serverløs arkitektur giver en unik mulighed for at skabe en cloud-platform, der dækker hele systemlandskabet. Denne platform er horisontalt skalerbar og har lave driftsomkostninger, mens den gør det.
Det er den perfekte løsning til projekter med begrænset budget. Det er en fremragende udforskningsmulighed, typisk når ingen kender virkeligheden af produktionsbelastningen. Dette er især vigtigt, når du har indført alle brugere. Det er muligt for projektteams stadig at få et samlet overblik over, hvordan systemet fungerer. Du kan få alle disse fordele og stadig ingen grund til at acceptere kompromiser.
Denne dækning vil ikke være tilstrækkelig i alle tilfælde, især dem, der involverer højt CPU-forbrug. AWS-skyen udvikler sig dog konstant med hensyn til serverløse use cases. Det er normalt en god ide at foretage en grundig research, før du beslutter dig for den serverløse mulighed for dit næste AWS-skyprojekt.
Tjek derefter de bedste serverløse databaser til moderne applikationer.